mrgam retweeted

Jun 12
Kernel Agent by @dogacel0 (in my Agent AI class)
Ranked #1 in MLSys 2026 FlashInfer AI Kernel Generation Contest.
@dogacel0 is continuing building more efficient GPU kernels with AI agents. He will also give some talks on speculative decoding, coming up soon, stay tuned!


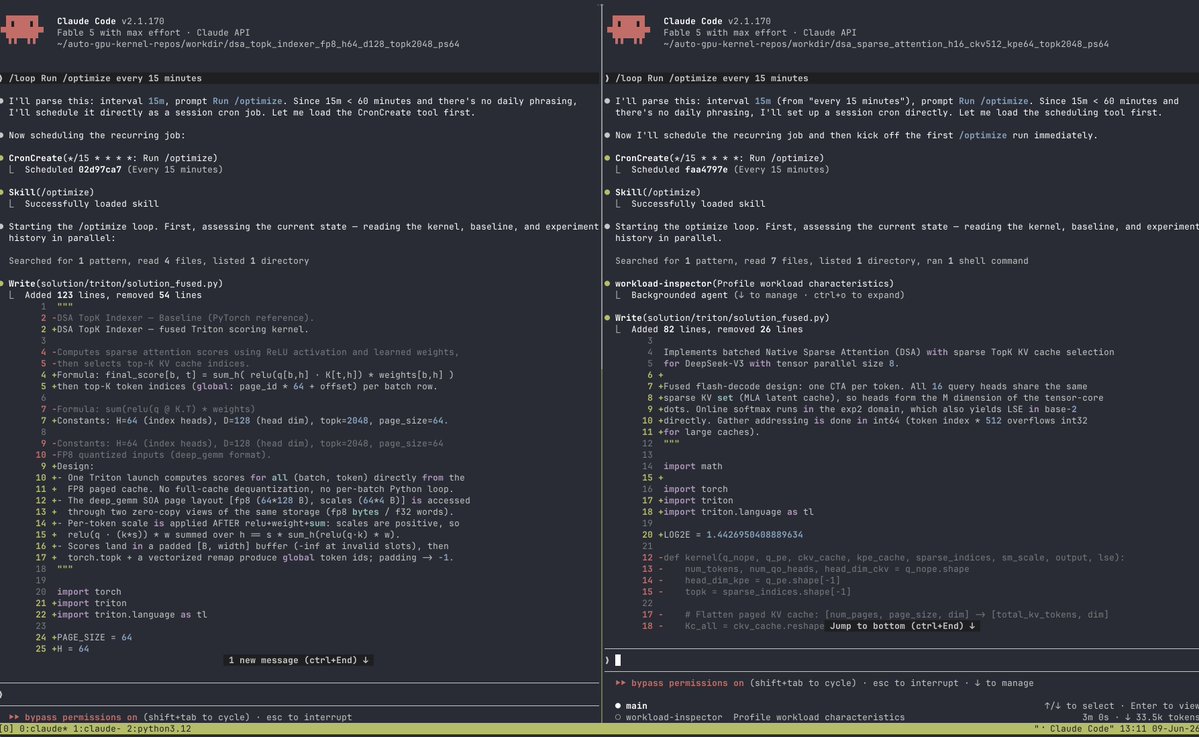
Testing Mythos for GPU kernel generation. I will test it under 3 kernels: DSA, GDN and MoE routing, let's see how it performs over Opus 4.7 that previously won the contest against humans for DSA track.
9
54
7,478

LLM推論コストを削るKVキャッシュ再利用層|OSS LMCache
ai.whytrend.jp/x/6c8c5dd8cc1…
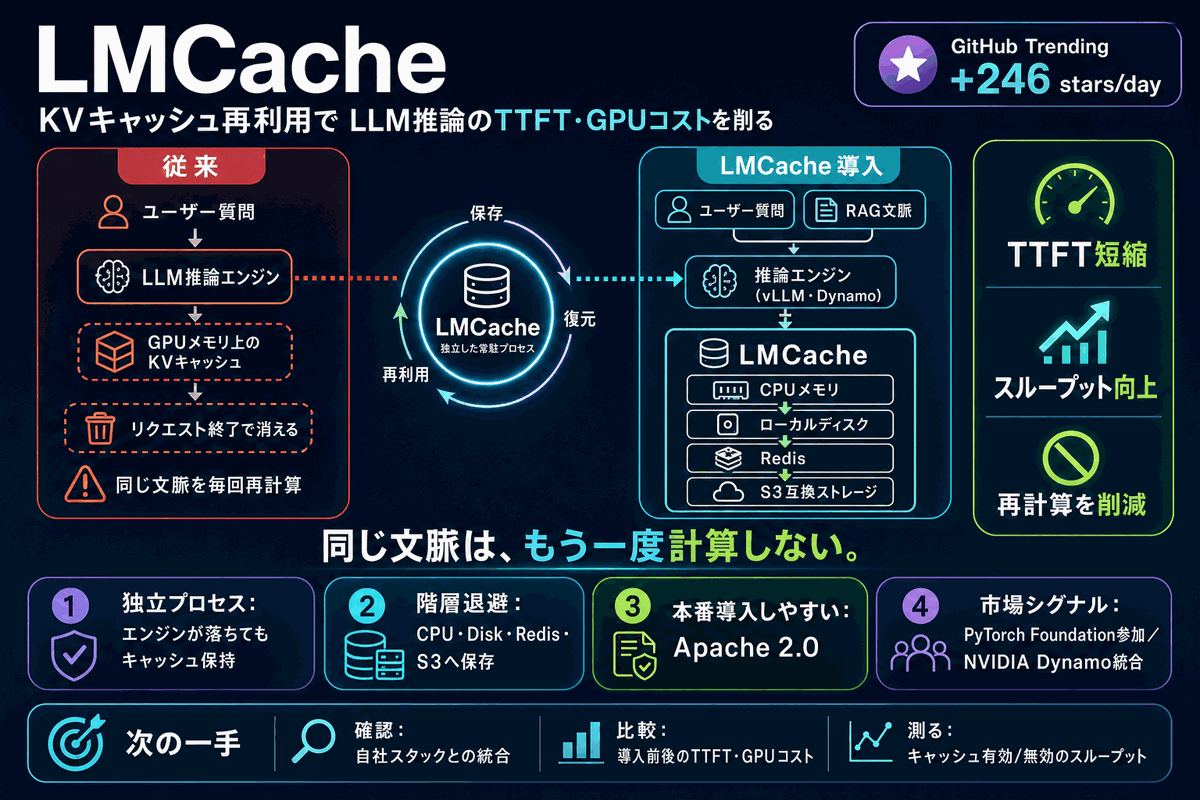
対話AIやRAGで同じ文脈を毎回計算し直す無駄を、推論エンジンとは別プロセスでKVキャッシュを保存・再利用して削るOSS「LMCache」がGitHubで1日246スター増。 CPUメモリ・ディスク・Redis・S3互換ストレージへ階層退避でき、応答開始時間(TTFT)短縮とスループット向上に直結する。 2025年10月にPyTorch財団へ参加し、NVIDIAの推論基盤Dynamoとも統合。Apache 2.0で本番運用の基盤部品になりつつある。
─────────
■ なぜ今これが重要か
・技術面: 従来のKVキャッシュは推論エンジンのGPUメモリ上に置かれ、リクエストが終わると消えていた。LMCacheはこれを別プロセスで管理しCPUメモリ・ディスク・Redis・S3互換ストレージへ階層退避するため、同じ文脈の再計算を省ける。エンジンが落ちてもキャッシュが残る常駐プロセス設計で、応答開始時間(TTFT)とスループットに効く。
・市場面: 2025年10月にPyTorch財団へ参加し、NVIDIAの推論基盤Dynamoとも統合した。特定ベンダーに依存せず複数の推論エンジンやストレージ間でキャッシュを使い回せるため、LLMを本番運用する企業の推論コスト構造を動かす基盤部品の位置に入った。ライセンスはApache 2.0で商用導入の障壁が低い。
■ 要点
・推論エンジンとは独立した常駐プロセスで動き、エンジンが落ちてもキャッシュが残る設計
・CPUメモリ・ローカルディスク・Redis・S3互換ストレージへ階層退避し再利用できる
・2025年10月にPyTorch財団へ参加、NVIDIAの推論基盤Dynamoと統合
・論文(arXiv:2510.09665)で技術公開、ライセンスはApache 2.0で商用利用可
・同じ文脈を何度も処理するRAG・対話エージェントでTTFTとスループットに直結
■ 誰に効くか
[追い風]
・RAG・対話エージェントを本番運用する国内企業: 同じ文脈を繰り返し処理する用途で、再計算を省きTTFT短縮とスループット向上が得られる。Apache 2.0でセルフホスト導入の権利上のハードルが低い。
・vLLMなどの推論エンジン利用者: 推論エンジンとは独立した層として差し込めるため、既存のエンジン構成を大きく変えずキャッシュ再利用を足せる。
[逆風]
・GPUメモリ増設だけで遅延に対処してきた運用: キャッシュ階層退避で再計算を減らせるため、メモリ増設一辺倒のコスト判断が見直し対象になる。
■ 今やるべきこと
・技術判断者: 確認する: 自社の推論スタック(vLLM等)とLMCacheの統合方式と、Apache 2.0ライセンスの適用範囲を公式ドキュメントで
・事業判断者: 比較する: RAG・対話用途でキャッシュ再利用導入前後のTTFTとGPU稼働コストの差を
・実装担当者: 測る: 同じ文脈を繰り返すワークロードで、キャッシュ有効時と無効時の応答開始時間とスループットの差を
■ 時系列
・2025年8月28日: LMCacheがGitHubで5,000スターを突破
・2025年10月31日: PyTorch財団のエコシステムへ参加、NVIDIA推論基盤Dynamoとの統合を公表
・2026年5月19日: MLSys初日の招待講演でLMCacheが紹介として取り上げられる
・2026年6月14日: GitHub Trendingで1日あたり246スター増のペースで急上昇
■ 一次情報
・公式発表
github.com/LMCache/LMCache
・リリース一覧
github.com/LMCache/LMCache/r…
・PyTorch財団 発表
ai.meta.com/blog/pytorch-fou…
・PyTorchエコシステム登録
github.com/pytorch-fdn/ecosy…
全文・図解・関連記事は冒頭リンクの記事ページへ。
2
3
185
LLM推論コストを削るKVキャッシュ再利用層|OSS LMCache
ai.whytrend.jp/articles/6c8c…
対話AIやRAGで同じ文脈を毎回計算し直す無駄を、推論エンジンとは別プロセスでKVキャッシュを保存・再利用して削るOSS「LMCache」がGitHubで1日246スター増。 CPUメモリ・ディスク・Redis・S3互換ストレージへ階層退避でき、応答開始時間(TTFT)短縮とスループット向上に直結する。 2025年10月にPyTorch財団へ参加し、NVIDIAの推論基盤Dynamoとも統合。Apache 2.0で本番運用の基盤部品になりつつある。
■ なぜ今これが重要か
・技術面: 従来のKVキャッシュは推論エンジンのGPUメモリ上に置かれ、リクエストが終わると消えていた。LMCacheはこれを別プロセスで管理しCPUメモリ・ディスク・Redis・S3互換ストレージへ階層退避するため、同じ文脈の再計算を省ける。エンジンが落ちてもキャッシュが残る常駐プロセス設計で、応答開始時間(TTFT)とスループットに効く。
・市場面: 2025年10月にPyTorch財団へ参加し、NVIDIAの推論基盤Dynamoとも統合した。特定ベンダーに依存せず複数の推論エンジンやストレージ間でキャッシュを使い回せるため、LLMを本番運用する企業の推論コスト構造を動かす基盤部品の位置に入った。ライセンスはApache 2.0で商用導入の障壁が低い。
■ 要点
・推論エンジンとは独立した常駐プロセスで動き、エンジンが落ちてもキャッシュが残る設計
・CPUメモリ・ローカルディスク・Redis・S3互換ストレージへ階層退避し再利用できる
・2025年10月にPyTorch財団へ参加、NVIDIAの推論基盤Dynamoと統合
・論文(arXiv:2510.09665)で技術公開、ライセンスはApache 2.0で商用利用可
・同じ文脈を何度も処理するRAG・対話エージェントでTTFTとスループットに直結
■ 誰に効くか
[追い風]
・RAG・対話エージェントを本番運用する国内企業: 同じ文脈を繰り返し処理する用途で、再計算を省きTTFT短縮とスループット向上が得られる。Apache 2.0でセルフホスト導入の権利上のハードルが低い。
・vLLMなどの推論エンジン利用者: 推論エンジンとは独立した層として差し込めるため、既存のエンジン構成を大きく変えずキャッシュ再利用を足せる。
[逆風]
・GPUメモリ増設だけで遅延に対処してきた運用: キャッシュ階層退避で再計算を減らせるため、メモリ増設一辺倒のコスト判断が見直し対象になる。
■ 今やるべきこと
・技術判断者: 確認する: 自社の推論スタック(vLLM等)とLMCacheの統合方式と、Apache 2.0ライセンスの適用範囲を公式ドキュメントで
・事業判断者: 比較する: RAG・対話用途でキャッシュ再利用導入前後のTTFTとGPU稼働コストの差を
・実装担当者: 測る: 同じ文脈を繰り返すワークロードで、キャッシュ有効時と無効時の応答開始時間とスループットの差を
■ 時系列
・2025年8月28日: LMCacheがGitHubで5,000スターを突破
・2025年10月31日: PyTorch財団のエコシステムへ参加、NVIDIA推論基盤Dynamoとの統合を公表
・2026年5月19日: MLSys初日の招待講演でLMCacheが紹介として取り上げられる
・2026年6月14日: GitHub Trendingで1日あたり246スター増のペースで急上昇
■ 一次情報
・公式発表
github.com/LMCache/LMCache
・リリース一覧
github.com/LMCache/LMCache/r…
・PyTorch財団 発表
ai.meta.com/blog/pytorch-fou…
・PyTorchエコシステム登録
github.com/pytorch-fdn/ecosy…
全文・図解・関連記事は冒頭リンクの記事ページへ。
ALT LLM推論コストを削るKVキャッシュ再利用層|OSS LMCache
1
156
Dhruv retweeted

May 21
It was an honor to give the keynote at MLSys
Covered how AI systems have evolved, why AI is needed to improve them, why results have disappointed, why the future looks amazing, and why I’m working on this at Core Auto
Recording should be out soon, in the meantime slides

15
45
446
66,753

RT @ManlingLi_: Kernel Agent by @dogacel0 (in my Agent AI class)
Ranked #1 in MLSys 2026 FlashInfer AI Kernel Generation Contest.
@dogac…
1
63
Jun 12
Kernel Agent by @dogacel0 (in my Agent AI class)
Ranked #1 in MLSys 2026 FlashInfer AI Kernel Generation Contest.
@dogacel0 is continuing building more efficient GPU kernels with AI agents. He will also have some talks on it coming up, stay tuned!
Testing Mythos for GPU kernel generation. I will test it under 3 kernels: DSA, GDN and MoE routing, let's see how it performs over Opus 4.7 that previously won the contest against humans for DSA track.
1
1
3
894

Jun 12
Verda is my Blackwell GPU cluster provider. They are one of, if not the best, on demand NVDA compute vendors in the world. Lots of recent relevant announcements to GAI trade. I consider this a leading proxy for other similar GAI data centers.
—————-
May recap: NVIDIA Rubin deployment announced, first APAC office in Taipei, deepened Supermicro collaboration, MLSys 2026 and new research. verda.com/blog/verda-monthly… via @Verda
$NVDA NVIDIA Rubin
Verda will be among the first to deploy NVIDIA Vera Rubin NVL72 and HGX Rubin NVL8 at scale, with the earliest deployments starting in H2 2026 and expected capacity exceeding 100,000 GPUs throughout 2027. As an NVIDIA Preferred Partner, we're bringing first-availability across three regions in parallel: Europe, the US, and APAC.
$STX $WDC Discontinuing HDD
We're discontinuing HDD-based services on Verda. UI controls have already been removed from the console, and we're in the process of removing HDD services from the API and SDK. Existing HDD data will be migrated to NVMe before HDD nodes are physically retired.
If you have data on HDD storage, our team will be in touch with migration details.
$SMCI Supermicro
Supermicro is one of the partners powering Verda's full-stack AI cloud, supplying the systems behind our latest NVIDIA Blackwell deployments, including GB300 NVL72, HGX B300, HGX B200, and RTX PRO 6000 racks. Their deep expertise in system design and liquid cooling helps us bring the latest hardware online quickly, sustainably, and at the density our customers need.
1
3
2,254


Jun 9
Winning MLSys best paper with a lean architecture says something about where the field is heading. inline AI explanations grounded in the paper can help unpack the efficiency claims: paperpeel.com/paper/2506.082…
5



My lunch with @matthew_d_white (CTO, @linuxfoundation & @PyTorch Foundation) during MLSys week. We discussed Open source AI / Linux Foundation movement (K8s, PyTorch, MCP) / World models & robotics / Matt's recent China trip: pengandy.com/blog/2026/lunch…
2
170
Kevin Faircloth retweeted
May 29
My MLSys keynote on AI writing systems code got more interest than I expected. The recording will take a while, so in the finest tradition of AI labs sharing blog posts, we’re starting the Core Automation Blog with this one coreauto.com/blog/when-ai-st…
23
71
643
178,620

Jun 6
ayer, este mismo investigador con el que nuestras charlas giraban en torno a temas tan fascinantes como HPC, MLSys, bioinformatica, TinyML, simulacion numerica y muchas otras areas igual de interesantes, me mando un link a unas becas de investigacion para que pueda unirme al laboratorio por 12 meses.
Es increible pensar que todo esto termino surgiendo porque un dia random de febrero le mande un email diciendole que me gustaba la tematica de su linea de investigacion

Apr 25

hoy hablando con un investigador top de mi facultad, me conto que hace poco lo llamaron de una empresa automotriz enorme en Argentina para capacitar gente en procesamiento paralelo sobre sistemas embebidos basados en Digital Signal Processors (DSP)
Nada, motivación para estudiar
4
17
1,258