Zymlauk retweeted

29 Mar 2023
MathWallet x MathVerse Free Giveaway!
🎁 900 MathVerse Cube NFT Whitelists
To enter:
❤️Follow @MathWallet & @MathVerseNFT & @Collectify_app
🔄RT & @ 3 friends
✅Complete: launchpad.collectify.app/#/p…
#BNB #Giveaway #NFT

27,398
163,375
163,774
1,630,122

May 27
Math loves you even when you don't love it back. Mathverse underlies and describes all reality --- it's like math heaven where you get to be all the numbers, all the primes, and all infinite space and time, yet also beyond all space and time.
2
6
944

May 18
To support this, we build VS-Bench: 800 carefully curated image pairs from MathVista, MathVerse, MathVision, and MMMU-Pro. Pairs are visually close but answer-critical details differ — so genuine re-examination should flip the answer.
1
3
227

May 3
Uh...huh?
'If we left right now, it would take them 20 years to rebuild. But, we're not leaving right now, we're gonna do it so nobody has to go back in 2 years or 5 years.'
What???
I guess this is the same Trump MathVerse as 500% off, type thing. 🤪🤪🤪
2
45


Mar 15
Introducing UmmahSync — your all-in-one Islamic life companion.
Not just another habit tracker. It’s a full platform that helps you manage your deen, health, finances, community, 3d MathVerse & interactive Quran learning — all in one place.
And it’s powered by JUNO.
1
3
75

Jan 20
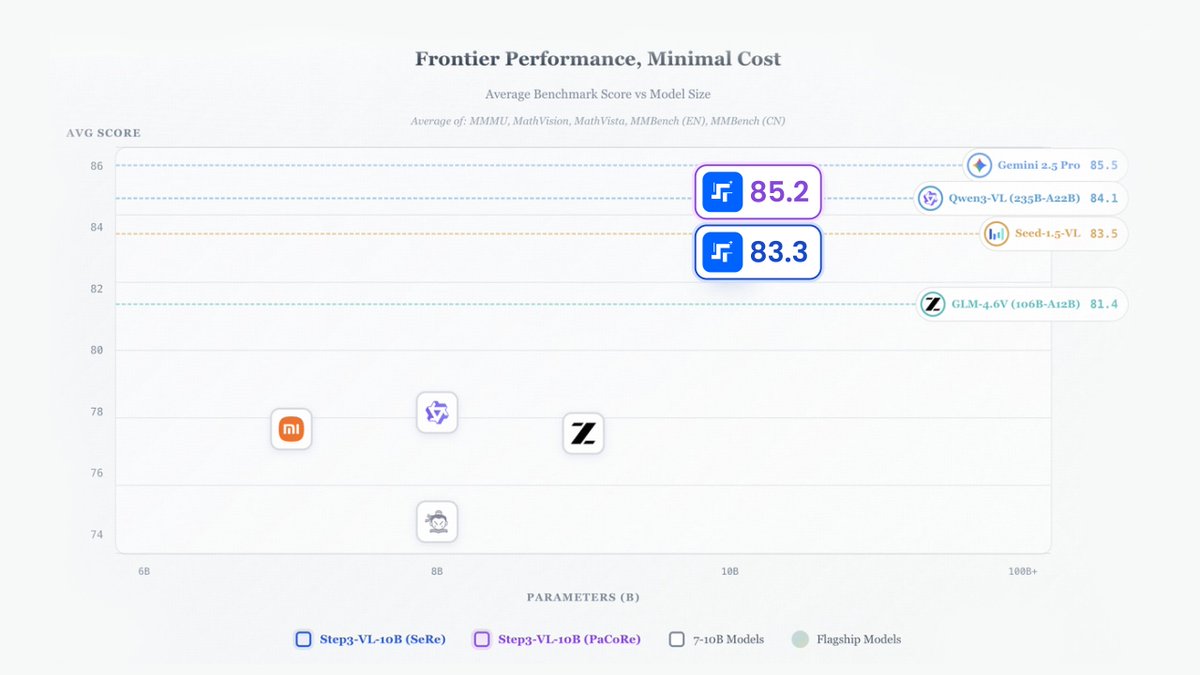
🚀10B parameters, 200B performance!
Introducing STEP3-VL-10B : our open-source SOTA vision language model.
🥊 At just 10B, it redefines efficiency by matching or exceeding the capabilities of 100B/200B-scale models.
SOTA Performance :
✅STEM/Multimodal: Outperforms GLM-4.6V (106B-A12B) and Qwen3-VL (235B-A22B) on MMMU, MathVision, MathVerse,etc.
✅Math: Near-perfect scores on AIME 24/25, achieving elite-level reasoning.
✅2D/3D Spatial Understanding: Beating same-scale models on BLINK/CVBench/OmniSpatial.
✅Coding:Dominates LiveCodeBench in real-world dynamic programming.
Key Breakthroughs:
🔹 1.2T token full-parameter pre-training.
🔹 1,400 RL iterations for superior reasoning.
🔹 Innovative PaCoRe tech for dynamic compute allocation.
💡We prove that scale isn't everything.
With high-quality targeted data and systematic post-training, a 10B model can go toe-to-toe with the industry's largest giants."
📱Complex AI reasoning is now accessible for every device.
Check out the Base & Thinking versions on HuggingFace now!
Homepage:stepfun-ai.github.io/Step3-V…
Paper:arxiv.org/abs/2601.09668
HuggingFace:huggingface.co/collections/s…
ModelScope:modelscope.cn/collections/st…
22
54
479
59,025

6 Dec 2025
This model might be the biggest jump in visual reasoning we’ve seen all year.
A team just dropped a system called OneThinker, and it basically merges every major image video task into one model that can actually think across them. Not separate heads. Not bolted-on modules. A single reasoning engine that handles:
• Image QA
• Video QA
• Captioning
• Grounding
• Tracking
• Segmentation
• Spatial temporal reasoning
All in one brain.
And the wild part?
It works across all of them at frontier-level.
Here’s what blew me away:
They built a 600k multimodal dataset that covers every fundamental visual task, then used a strong teacher model to rewrite everything with chain-of-thought reasoning. That gave them a 340k high-quality SFT dataset as the starting point.
Then they addressed the biggest problem in multi-task RL:
Different tasks have different reward structures, and normal RL collapses when you mix them.
So they created EMA-GRPO, which keeps a task-wise moving average of reward variance. That tiny idea fixes the whole instability problem — no more one task overpowering another, no more reward imbalance breaking training.
After that, the numbers went insane:
• 70.6% on MMMU
• 64.3% on MathVerse
• 84.4 R@0.5 on GOT-10k tracking
• 54.9 J&F on ReasonVOS segmentation
• State-of-the-art across 31 benchmarks
• Even early zero-shot generalization on tasks it never saw
And the unified learning effect is real.
Remove spatial grounding → tracking collapses.
Remove image QA → video QA drops.
Remove temporal grounding → multi-object tracking weakens.
Everything reinforces everything exactly how a true multimodal reasoner should behave.
The biggest flex?
It crushes long-horizon video reasoning:
79.2% on LongVideo-Reason ahead of Video-R1-7B and Qwen3-VL-8B.
This isn’t “a better VLM.”
This is the first real glimpse of a system that can watch a scene, follow it over time, understand it, explain it, and reason about it like a single coherent mind.
If Google, OpenAI, or Meta shipped this, everyone would be screaming AGI.
The era of true multimodal reasoning just took a massive step forward.

ALT Research paper front page from The Chinese University of Hong Kong titled "OneThinker: All-in-one Reasoning Model for Image and Video" with authors, diagrams and abstract.
4
8
18
3,404

5 Dec 2025
Holy shit… this model might be the closest thing we’ve seen to a true visual reasoning generalist 🤯
OneThinker isn’t another “better VQA model.” It’s a full multimodal reasoning system that handles images and videos in one brain and it actually works across 10 major visual tasks. Not with separate heads stitched together, but with a single unified reasoning pipeline.
What grabbed me was how they built it.
They didn’t just scale data. They curated a massive 600k-sample multimodal dataset covering grounding, tracking, segmentation, captioning, spatial reasoning, temporal reasoning, and complex multimodal QA. Then they used a strong teacher model to rewrite the entire thing with chain-of-thought explanations, producing a 340k CoT SFT dataset for the cold start.
After that, they hit the real bottleneck: RL breaks when your tasks have wildly different reward structures. Math rewards look nothing like tracking rewards. Detection rewards look nothing like video reasoning rewards.
Their fix is clever.
EMA-GRPO keeps a moving-average reward normalization per task, which stabilizes training across heterogeneous tasks. Standard GRPO overweights low-variance tasks. Dr.GRPO removes normalization entirely and gets dominated by sparse-reward tasks. EMA-GRPO threads the needle balanced, predictable, stable.
And the results are ridiculous:
• 70.6% on MMMU
• 64.3% on MathVerse
• 84.4 R@0.5 on GOT-10k tracking
• 54.9 J&F on ReasonVOS segmentation
• A clean sweep across 31 benchmarks, covering 10 task families
• Even zero-shot generalization on tasks it wasn’t trained on
The real story is the unified training effect. Remove spatial grounding? Tracking drops. Remove image QA? Video QA weakens. Everything reinforces everything which is exactly what multimodal reasoning is supposed to look like.
My favorite part: this thing handles long-horizon video reasoning tasks better than Video-R1 and Qwen3-VL. OneThinker scores 79.2% on LongVideo-Reason, which is insane for an 8B model juggling spatial temporal cues at once.
The paper doesn’t oversell it but the implications are obvious.
We’re inching toward a single model that can look at a scene, track it over time, describe it, answer questions about it, localize objects, segment them, and reason about events unfolding in motion without swapping architectures.
A step closer to AI that actually sees and thinks, not just classifies.

ALT Research paper front page from The Chinese University of Hong Kong titled "OneThinker: All-in-one Reasoning Model for Image and Video" with authors, diagrams and abstract.
10
19
77
9,699

11 Nov 2025
DeepEyesV2 is a leap toward true “agentic” multimodal AI.
This 7B model doesn’t just see and read—it knows when to run code, search the web, or crop images mid-reasoning, all inside a single loop. The team shows that direct RL isn’t enough: only a two-stage process—cold-start SFT with 1.2M tool-rich samples, then sparse-reward RL—teaches robust, efficient tool use.
On the new RealX-Bench (300 real-world image questions needing perception, search, and reasoning), DeepEyesV2 scores 28.3%—beating the 7B base model (22.3%) and matching much larger models (32–72B). Outperforms on MathVerse ( 7.1%, 52.7%), ChartQA (88.4%), and MMSearch ( 11.5%).
Most striking: RL cuts unnecessary tool calls by 35%, letting the model adaptively mix cropping, computation, and search as needed—moving closer to real-world, verifiable AI agents.
Get the full analysis here: yesnoerror.com/abs/2511.0527…
// alpha identified
// $YNE
1
17
39
898

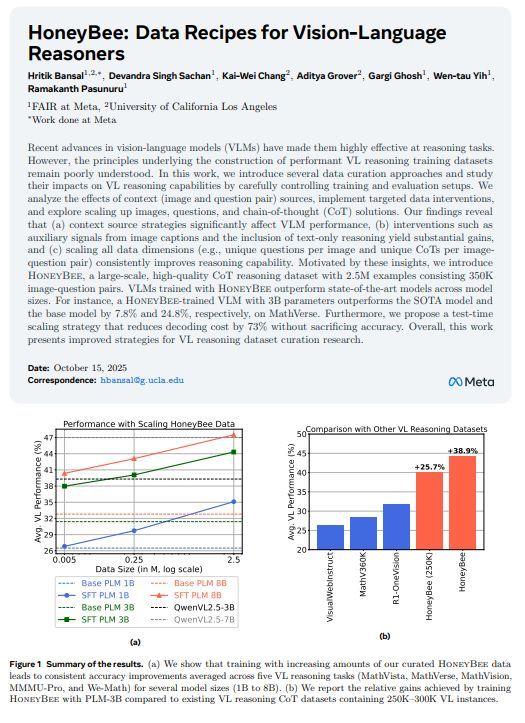
Meta FAIR and UCLA researchers have introduced HoneyBee, a large-scale, high-quality dataset designed to improve vision-language (VL) reasoning.
Through controlled experiments, they found that context source, targeted data interventions (like image captions and text-only reasoning), and scaling up examples all significantly boost VL model performance.
HoneyBee includes 2.5M chain-of-thought (CoT) reasoning samples from 350K image-question pairs, and VLMs trained on it outperform state-of-the-art models achieving 7.8% over SOTA and 24.8% over the base model on MathVerse with a 3B-parameter model.
3
20
2,751

17 Oct 2025
💡 Motivation extended
While models excel at producing very good natural images, they struggle with producing or editing STEM stuff such as structured visuals like charts, diagrams, & mathematical figures.
Generating these figures goes way beyond just aesthetic appeal -- composition planning, text rendering, and multimodal reasoning for factual fidelity. This is our primary motivation, i.e., to investigate the under-represented domain of structured visual data generation, model training, and evaluation 🫡
This is unlike the understanding literature, though, where we have several models like Refocus, Mathverse, etc. that demonstrate compelling capabilities of understanding these figures.
1
3
418

16 Oct 2025
New paper 📢 Most powerful vision-language (VL) reasoning datasets remain proprietary 🔒, hindering efforts to study their principles and develop similarly effective datasets in the open 🔓.
Thus, we introduce HoneyBee, a 2.5M-example dataset created through careful data curation. It trains VLM reasoners that outperform InternVL2.5/3-Instruct and Qwen2.5-VL-Instruct across model scales (e.g., an 8% MathVerse improvement over QwenVL at the 3B scale). 🧵👇
Work done during my internship at @AIatMeta w/ 🤝 @ramakanth1729, @Devendr06654102, @scottyih, @gargighosh, @adityagrover_, and @kaiwei_chang.
5
42
219
61,383

13 Oct 2025
Full Breakdown
Mask Network @masknetwork
Mask Network isn’t just another Web3 project it’s the
bridge between the old internet and the new one
Launched in 2018, Mask integrates Web3 features like
encrypted messaging on chain identity, crypto tipping,
NFT transfers and dApp interactions directly into
platforms like Twitter (X) without ever leaving your
feed.
Here is the full picture ⬇️
1. What It Is
Mask Network is a browser extension that layers
decentralized tools on top of existing social media.
Think:
▪️ Sending crypto directly in replies
▪️ Collecting NFTs in feed
▪️ Accessing DeFi and dApps from your timeline
▪️ Encrypted messaging & on chain identity
Their tagline says it best:
“The Portal to the New, Open Internet.”
2. Core Products
▪️ Browser Extension: Wallet integration, NFT collection, tipping, token security checks and QR backups.
▪️ $MASK Staking: Stake to earn partner tokens and ecosystem rewards.
▪️ Publishing Stack: 10K creators migrated to Paragraph, building onchain publishing rails.
▪️ Web3 Social: ENS integration, encrypted chats, metaverse events and “red packet” gifting.
3. Ecosystem & Team
▪️ Founded by @suji_yan
@TheYisiLiu
@thefireflyapp
▪️ Rooted in Hong Kong, expanding globally.
▪️ Collaborations: SpaceID, MathVerse, Binance Chain.
▪️ Backed by early Web3 investors (ITO 2021).
4. Tokenomics – $MASK
▪️ Total Supply: 100M
▪️ Use cases: governance, staking rewards, partner incentives.
▪️ Market Cap (Oct 2025): ~$300M
▪️ Staking v2 & ecosystem growth planned for late 2025.
5. Current Stats & Activity (Oct 2025)
▪️ Followers: 229,831
▪️ Browser extension: 100K installs (est. peak).
▪️ Ecosystem: 15 partnerships.
▪️ Recent focus: Paragraph publishing migration, staking incentives.
6. Why It Matters
▪️ Makes Web3 usable where people already are on X.
▪️ Lowers onboarding friction massively.
▪️ Pushes the “social layer” of crypto forward.
▪️ Empowers creators & communities to earn, tip and build onchain.
7. Road Ahead
▪️ Paragraph integration upgrades.
▪️ Staking v2 & new reward systems.
▪️ More dApp & metaverse tie ins.
▪️ Continued UX-focused social crypto tools.
If Web3 is the future of the internet, Mask Network is the door you walk through.
Install the extension, tip a frens NFT and step into the open internet.

2
2
117

26 Sep 2025
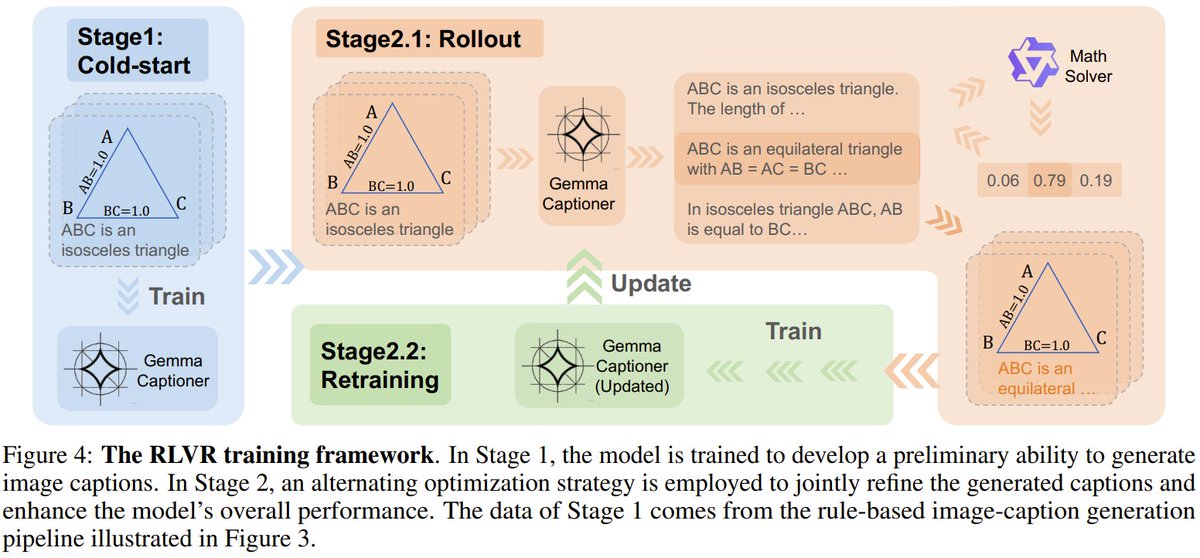
Why do multimodal LLMs still stumble on geometry problems, despite excelling elsewhere? 📐🤔
A paper tackles this by introducing RLVR (Reinforcement Learning with Verifiable Rewards) into the data pipeline.
Instead of rigid templates, RLVR refines captions for synthetic geometric images (from 50 base relations) using math-based reward signals—capturing the essence of geometric reasoning.
The result: stronger task generalization, non-trivial gains on geometry benchmarks, and even accuracy boosts on out-of-distribution tasks—from MathVista & MathVerse to broader MMMU domains like art, design, and engineering.
2
2
9
864

22 Sep 2025
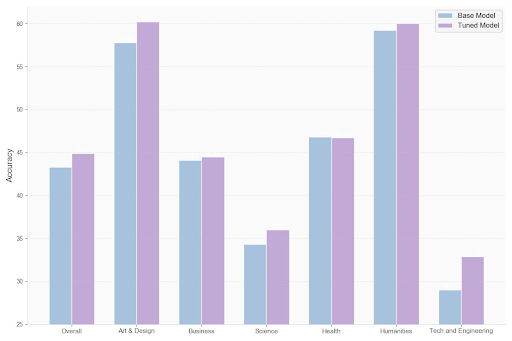
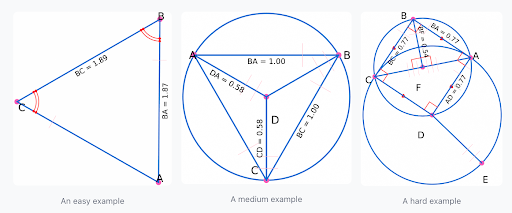
(1/5)🚨Generalizable Geometric Data Synthesis 🚨
⁉️ General multimodal reasoning can be improved via symbolically synthesized geometric data ⁉️
🔥 We open-source an image-statement aligned dataset inspired by AlphaGeometry for geometric image understanding.
📊 GeoReasoning delivers high-quality image–caption pairs that outperform previous geometric datasets on MathVerse and MathVista, with better scalability.
🌐 Generalizes beyond geometry - boosting performance in non-geometric math tasks (2.8-4.8%) and non-mathematical domains like art & engineering (2.4-3.9%).
⚡ Built from 50 basic relations, enabling unlimited complexity expansion for diverse geometry problems.
🔓Blog: machinephoenix.github.io/Geo…
🔓Paper: arxiv.org/abs/2509.15217
🔓Dataset: huggingface.co/datasets/Scal…
🔓Code: github.com/MachinePhoenix/Ge…
Amazing Collaborators: @leonard_yuexin @RenjiePi @shizhediao @wang_wenyu18522 @Howard05539786 @RickyRDWang
1
5
15
2,084

4 Sep 2025
2/
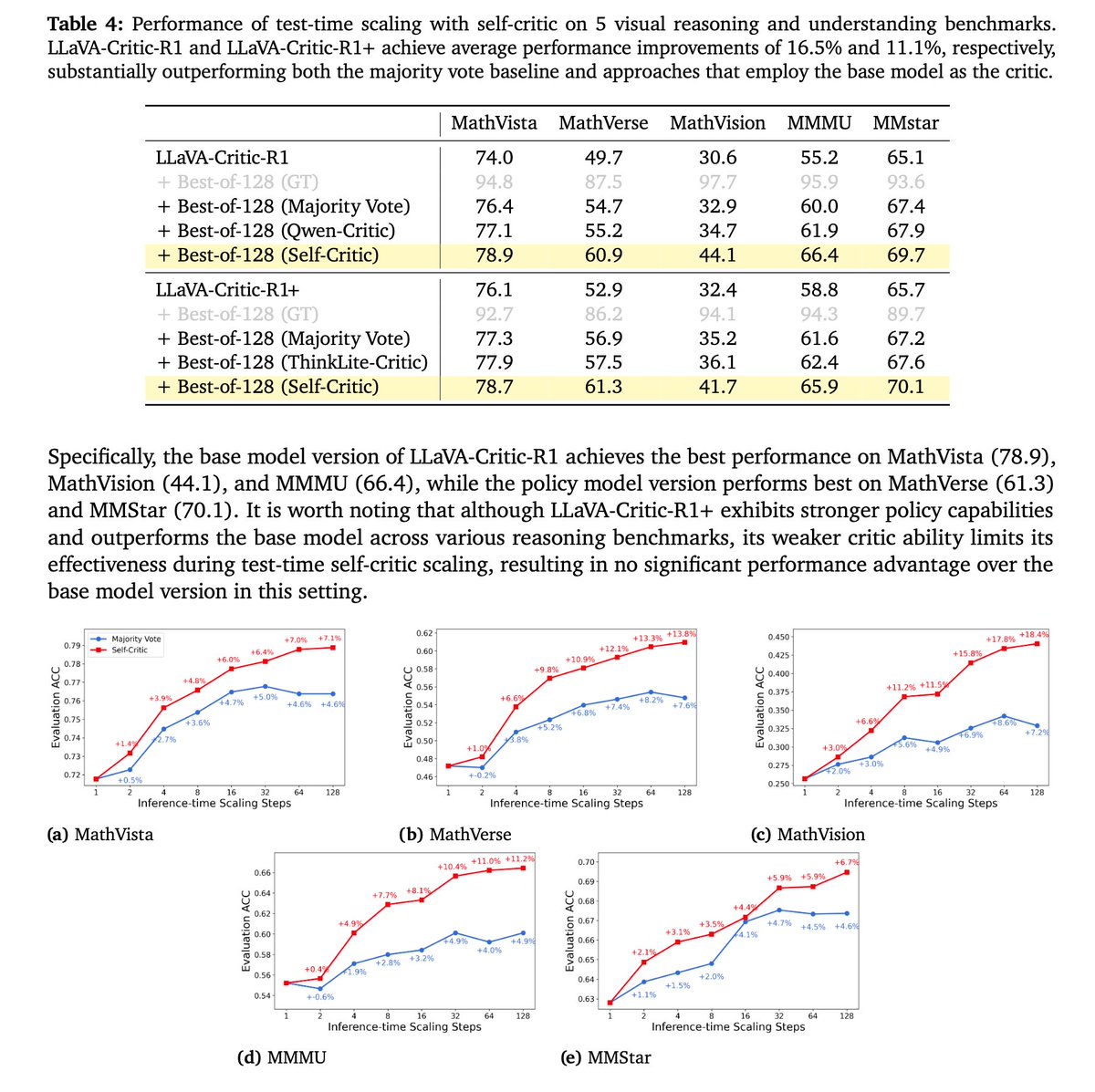
Test-time Scaling with Self-Critic
Since LLaVA-Critic-R1 unifies generation evaluation, it can judge its own outputs at test-time without external verifiers.
How it works:
1⃣LLaVA-Critic-R1 generates multiple candidate answers (e.g., 128).
2⃣The same model acts as critic to compare & select the best.
No external verifier, no extra training. Pure self-judgment.
📈 Results (Best-of-128 self-critique):
13.8% avg gain across 5 reasoning benchmarks.
Strong boosts on MMMU, MathVista, MathVision, MathVerse, MMStar.
Outperforms majority vote & base-model critics.
1
1
3
193
4 Sep 2025
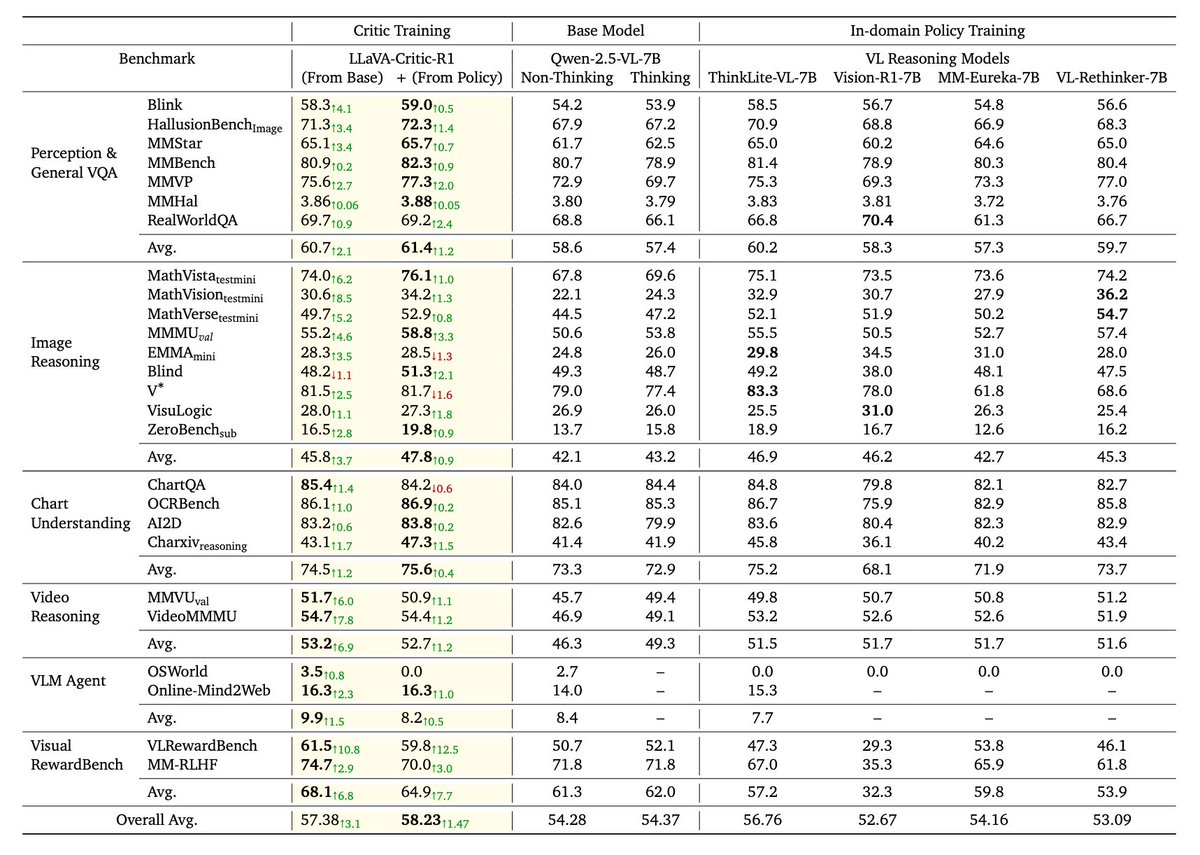
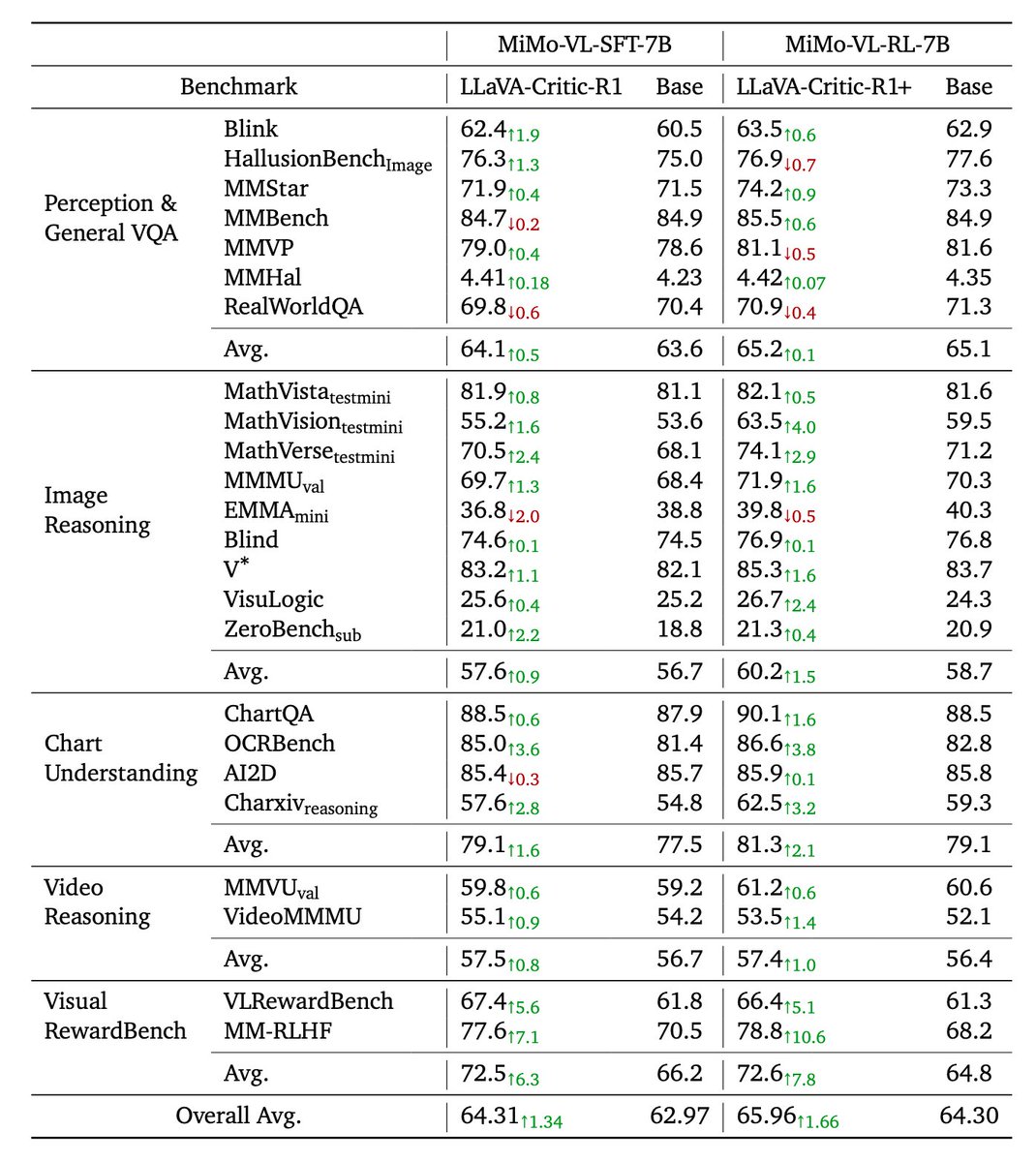
1/
We apply Critic RL training on 5 VLMs with same training data: Qwen-2.5-VL-7B, ThinkLite-VL-7B, MiMo-VL-7B-SFT-2508, MiMo-VL-7B-RL-2508, LLaMA-3.2-Vision-11B.
🎯 Result: All models show strong policy gains.
🚀 Best performer: LLaVA-Critic-R1 (MiMo-VL-7B-RL-2508 base) sets new 7B SoTA on:
MMMU: 71.9
MathVista: 82.1
MathVerse: 74.1
Charxiv: 62.5
🤔Transfer to untrained domains reveals something deeper:
🎮 GUI Agent (OSWorld): 2.7 → 3.5
🎬 Video Reasoning (MMVU): 45.7 → 51.7
📊 Chart Understanding: 1.7%
Never saw these tasks during training. The model learned meta-capabilities through judging.
🏆 Also tops visual reward benchmarks.
1
3
293

26 Aug 2025
Happy 5th Anniversary, @BNBCHAIN ! 🎉
From #MathVerse, cheers to five years of innovation, growth, and building the future of Web3 together. 🚀
Here’s to the next chapter of possibilities!🫡
#BNBDay #BNBChainTurns5 #MathVerse

1
3
6
1,507