Fernando Diaz retweeted

📸 MiniCPM-V 4.6 — one of the strongest vision models under 2B params — now runs at ~51 tok/s on iPhone 17 Pro via Apple Core AI.
🤗 huggingface.co/mlboydaisuke/…
🛠️ github.com/john-rocky/coreai…
3
13
587
ZoAina_AI retweeted

May 25
Everyone keeps chasing bigger models, while MiniCPM is out here compressing absurd capability into 1B params.
The edge AI era is going to look very different from what people expected.

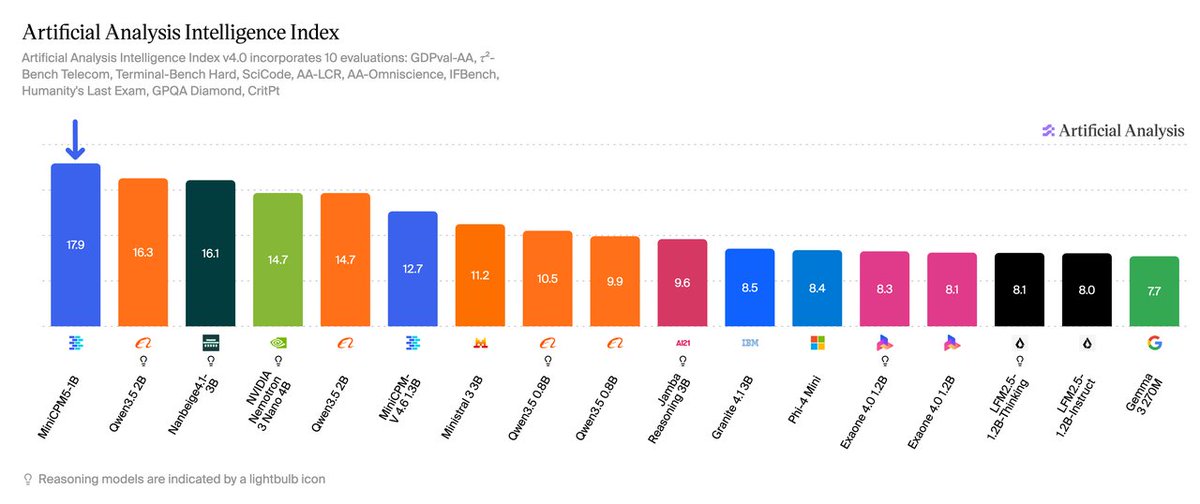
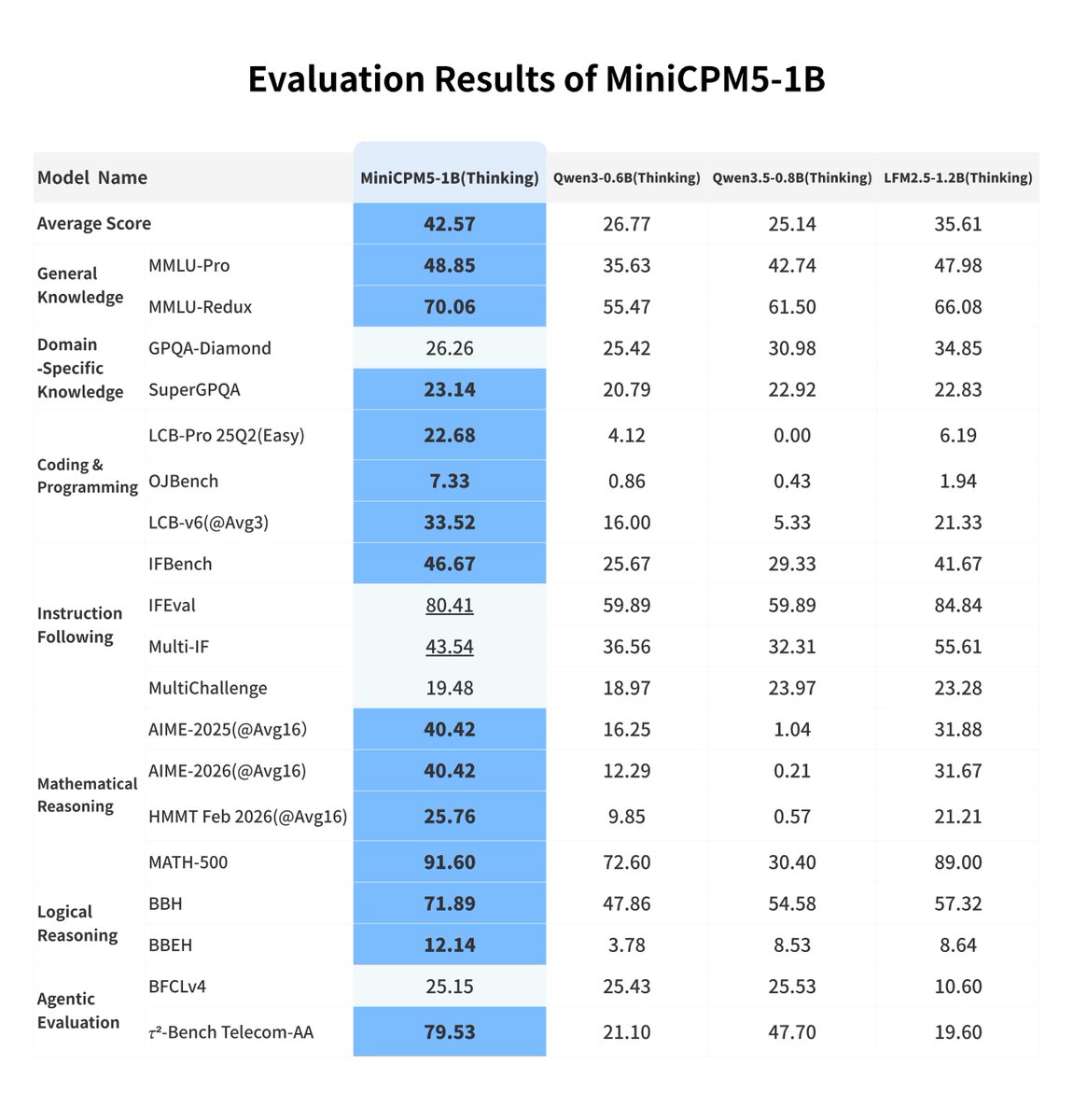
MiniCPM5-1B is now live — the strongest open‑source base model under 2B.🚀🚀
🔥 Ranks #1 on the Artificial Analysis (AA) index for small models, scoring 17.9 to beat the 2B-scale Qwen3.5-2B (16.3).
⚡ Comprehensively surpasses Qwen3.5-0.8B and LFM2.5-1.2B-Thinking in knowledge, math, coding, and tool use.
🏗️ INT4 weights = just ~0.5GB — runs on phones, browsers, laptops.
👾 Powers fully offline AI “Desktop Pet” — no cloud, no GPU cluster.
Try the model here:
🤗 Hugging Face: huggingface.openbmb.com/mode…
💻 GitHub: github.com/OpenBMB/MiniCPM
🔭 Modelscope: modelscope.cn/models/OpenBMB…


34
35
73
7,690

🧩 Type anything → an AI paints it → it becomes a real jigsaw you race against the clock, while a mascot roasts you.
Built for the @gradio × @huggingface Build Small Hackathon. @bfl_ai FLUX.2-klein MiniCPM, one Space.
🤗 huggingface.co/spaces/build-…
▶️ youtu.be/kSjLr6dC6jI
4



Most AI thinks for you. I built Iris to make you think deeper it never gives answers, it applies pressure until your fuzzy idea sharpens into one concrete next step.
Tiny MiniCPM model, 100% local. Built with Codex. #BuildSmall @huggingface
build-small-hackathon-iris-p…
18
Some questions were asked about some SA/SWE/FDE decisions deploying OffGridSchedula. Posting some of the best ones.
Why build on a fine-tuned small model instead of using a frontier API? The hard constraint was local-first, so no cloud AI calls. The model has to be edge-sized: gemma-cal, a QLoRA fine-tune of Gemma E4B, ~5 GB at 4-bit, served as a GGUF through llama.cpp. The decision to fine-tune rather than prompt a generic model wasn't about raw capability, it was about reliability of structure. The fine-tune holds 100% schema validity even with no system prompt, won't invent an event from "thanks!", and learns this product's date conventions (what "next Tuesday" resolves to). You trade general intelligence for a model that's steller at one job, that's what is needed on the edge.
Why grammar-constrained decoding instead of generating JSON and parsing it? The single most important reliability decision. Generation is constrained to a JSON Schema derived directly from our Pydantic model (json_schema=ActionPlan.model_json_schema()). The decoder can only emit tokens that keep the output a valid ActionPlan. Compare the alternative, generate free text and parse-and-repair, which is exactly where small models fall over. By constraining at the grammar level, we delete an entire class of failures: no malformed JSON, no missing fields, no hallucinated structure. The contract is enforced at decode time, not hoped for afterward.
Why a second, separate small model just for planning? The fine-tuned E4B is a specialist with natural-language-to-ActionPlan. Orchestration is a different skill, so it requires a different model: @OpenBMB 's MiniCPM (1B), on its own local llama-server. That's a clean separation of concerns, the planner decides which tools to call; the extractor does the extraction, and both stay local, both under the size cap, still zero cloud AI. It's a two-model architecture where each model does the thing it's good at.
HF Space: huggingface.co/spaces/build-…
Model: huggingface.co/build-small-h…
Traces: huggingface.co/datasets/Pare…
@Gradio @Google @OpenBMB @HuggingFace
38

THE AI RACE IS MOVING AT A TERRIFYING SPEED.
We are only halfway through 2026, and the sheer number of AI models launched is insane. If you feel like you can't keep up anymore, you aren't alone.
Just look at this massive list of every single AI model launched this year so far:
• Claude: Opus (4.6, 4.7, 4.8), Sonnet 4.6, Fable 5
• GPT: 5.3 Codex, 5.4, 5.5
• Gemini: 3.1 Pro, 3.5 Flash
• Qwen: 3-Max-Thinking, 3.6-35B, 3.7 Max, 3.7 Plus
• DeepSeek: V4-Flash, V4-Pro
• Gemma: 4, 4-12B, DiffusionGemma 26B
• Kimi: K2.5, K2.7 Code
• MiMo: V2-Pro, V2.5, V2.5-Pro
• Sarvam: 30B, 105B
• Step: 3.5-Flash, 3.7 Flash
• GLM: 5, 5.1
• MiniCPM: 5-1B, V-4.6 1.3B
• MAI: Thinking-1, Code-1-Flash
• Others: Mistral Small 4, Granite 4.1 30B, Nemotron 3 Ultra 550B, Muse Spark, Param-2, JT-35B-Flash, Ring-2.6-1T, MiniMax-M3, U2
And this doesn't even include the hundreds of open-source fine-tunes that drop every single day. The speed of innovation right now is something we have never seen before in the history of tech.
Are you even able to keep track of all these models anymore? Which one has been your favorite?
#ArtificialIntelligence #TechNews #GPT5 #ClaudeFable5 #OpenAI
175

HERE’S A LIST OF EVERY AI MODEL LAUNCHED THIS YEAR SO FAR:
• Qwen3-Max-Thinking
• Kimi K2.5
• Step-3.5-Flash
• Claude Opus 4.6
• GPT-5.3 Codex
• GLM-5
• Claude Sonnet 4.6
• Param-2
• Sarvam-105B
• Sarvam-30B
• Gemini 3.1 Pro
• GPT-5.4
• Mistral Small 4
• MiMo-V2-Pro
• Gemma 4
• GLM-5.1
• Muse Spark
• Qwen3.6-35B-A3B
• Claude Opus 4.7
• GPT-5.5
• DeepSeek-V4-Flash
• DeepSeek-V4-Pro
• MiMo-V2.5-Pro
• MiMo-V2.5
• Gemini 3.5 Flash
• Claude Opus 4.8
• Step 3.7 Flash
• GPT-5.5 Instant
• Grok 4.3
• Granite 4.1 30B
• Qwen3.7 Max
• MiniCPM5-1B
• JT-35B-Flash
• MiniCPM-V 4.6 1.3B
• Ring-2.6-1T
• MiniMax-M3
• Qwen3.7 Plus
• Gemma 4 12B
• Nemotron 3 Ultra 550B A55B
• DiffusionGemma 26B-A4B
• Kimi K2.7 Code
• Claude Fable 5
• MAI-Code-1-Flash
• MAI-Thinking-1
• U2
We’re only half way through the year..
22
11
131
42,048


Jun 13
The dates are always in the group chat. The misses happen anyway.
For the Gradio Build Small Hackathon I built OffGridSchedula. The space is a tiny, local scheduling agent built for a person who always has too many invites but not enough time to make them calendar reminders.
Paste a chat (or a screenshot of a flyer/invite) and the agentic system returns the events, a conflict check against your calendar, and a ready-to-send reply. These are all reviewed before anything is saved. Output is a local .ics, with optional @Google Calendar push.
The honest part: it's a small model doing a smalljob well. Gemma-4 E4B (≤32B, fine-tuned with QLoRA and published on the Hub), run through llama.cpp, 100% local and no cloud AI APIs.
Custom @Gradio UI, agent traces shared as a @huggingface dataset, full field notes in the repo, @Modal powering every training and eval run behind the model, and an @OpenBMB MiniCPM planner, a second local model, drives this Space's own MCP tools as a visible multi-step agent.
Try it (phone browser, no install): huggingface.co/spaces/Pareto…
Check out the fine-tuned model: huggingface.co/ParetoOptimal…
Catch the scrubbed traces dataset: huggingface.co/datasets/Pare…
56
Marina Rosa retweeted

🎭 Thousand-Token Theater
A troupe of tiny @OpenBMB MiniCPM actors improvises a one-act play you direct — live, line by line.
The twist that names it: their entire memory is capped at 1,000 tokens. As the story grows, they forget it.
Built for #BuildSmall 🍄
2
1
4
138

Jun 12
note更新。久しぶりに OCR でちょっと遊んだ。MiniCPM-V 4.5 / 4.6 で半角カナは読めるのか試したけど無理だった。
note.com/minamotomasaru/n/n6…
1
22

Jun 12
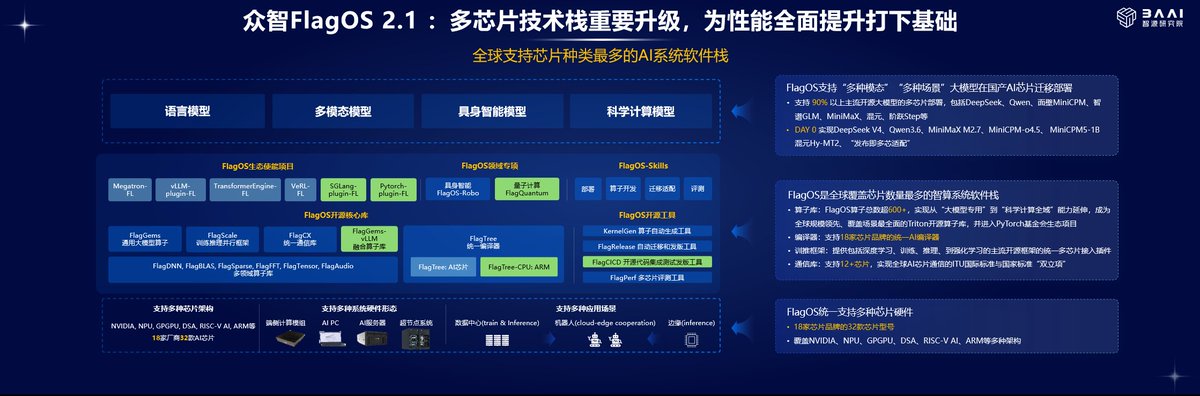
FlagOS 2.1 targets a core AI deployment bottleneck: adapting "many models" to "many chips."
BAAI says it supports multi-chip deployment for over 90% of mainstream open-source LLMs, including DeepSeek, Qwen, MiniCPM, GLM and Hunyuan.
#AIChips #ChinaTech
1
1
386

Jun 11
Two new #1 models:
• Claude Mythos Preview (proprietary) — 94.6% GPQA
• MiniCPM-SALA (open‑source) — 95.1% HumanEval
Different benchmarks, but both are SOTA in their domains. The open‑source gap on code is narrowing.
Source: llm-stats.com/leaderboards/o…
34

Jun 10
The overarching narrative today is an orchestrated flex from the Huawei Ascend ecosystem. If you want to know what the post-CUDA parallel universe looks like, the latest batch of releases hosted on the Modelers platform offers a clear blueprint. Instead of brute-forcing massive parameter counts, the focus here is strictly on hardware utilization—wringing maximum efficiency out of specialized NPU silicon.
The centerpiece of this hardware-aligned push is Qwen2.5-7B-Instruct. This isn't just another generic upload; it is a highly tuned instruction follower engineered to bridge the gap between model architecture and the Ascend AI stack. By hyper-optimizing for the hardware, it aims to deliver 13B-level reasoning in a 7B footprint. Equally notable is OpenBMB's MiniCPM-Llama3-V 2.5, which attempts the holy grail of edge AI: matching GPT-4V-class vision on accessible local hardware. While claims of GPT-4V parity are the industry's favorite marketing trope, their architectural choice to avoid simple input downscaling makes this a genuine signal in the multimodal space. For developers building production Retrieval-Augmented Generation pipelines, the embedding model is the actual bottleneck. BGE-M3-RetroMAE lands as a multilingual powerhouse designed explicitly for high-performance retrieval on Ascend, natively handling dense, sparse, and multi-vector search. On the generative front, the ecosystem just absorbed Dolphin-Mistral-Nemo 12B. This marries the unapologetic, uncensored compliance of the Dolphin dataset with a 12B Mistral-Nemo architecture, aimed squarely at developers tired of battling heavy-handed corporate alignment refusals.
The rest of the ecosystem dump reveals a fascinating trend: the abandonment of the monolithic foundation model in favor of hyper-specialized mid-weights. The 10B to 12B parameter range has become the undisputed Goldilocks zone for this hardware. China Merchants Bank deployed YiZhao-12B-Chat specifically for finance-grade enterprise tasks. Mistral-Nemo-Gutenberg-Doppel-12B-v2 abandons the standard assistant persona entirely to focus on high-quality literary prose. For regional nuance, Solar-Ko-Recovery-11B tackles the degradation of Korean linguistic depth during general pre-training, outperforming standard 7B models without the crushing inference costs of a 70B behemoth.
At the extremes, the ecosystem supports everything from the massive to the microscopic. Stockmark-100b pushes into triple digits to handle complex commercial document processing. Conversely, NuExtract-1.5-tiny is an ultra-compact 0.5B model with exactly one job: turning unstructured text into perfectly formatted JSON with zero hallucination. Add in ConvNeXt V2 Nano for edge vision and generalist updates like Yi-1.5-6B and Breeze-7B-Instruct, and the strategy is clear.
Nvidia's true moat has always been CUDA, not just the silicon. But if this wave of hardware-native, highly optimized model drops is any indication, Huawei's walled garden is actively cultivating the tools to break that dependency.




54
