
The AI community building the future. hf.co/careers
Joined September 2016
- Tweets 13,739
- Following 222
- Followers 704,511
- Likes 9,145
471 Photos and videos














Hugging Face retweeted

Released last week, and already more than 4M downloads on HuggingFace alone 😊
This makes Gemma 4 12B the most popular encoderfree VLM by a large margin.
In addition to being the first-ever general purpose LLM with encoderfree audio input!
Jun 3

Our new Gemma 4 12B model hits a sweet spot between size performance: it can run locally on a laptop, while enabling powerful multi-step reasoning and agentic workflows. Can’t wait to see what the community does with this one!
8
20
99
19,780
Hugging Face retweeted

Jun 12
I'm seeing a lot of angry people lately... remember, you can always run your coding agent locally ;)
llama.cpp OpenCode = fast, reliable and private inference.
This is @UnslothAI North-Mini-Code-1.0-GGUF running at ~50 tokens/s on my Macbook
9
5
69
12,360
Hugging Face retweeted

Alibaba Qwen3.7 slowly fading into irrelevance at the frontier due to proprietary stance.
In it's place we have Minimax M3 and... *checks notes* Rio 3.5 397b, made by the municipal IT company of Rio de Janeiro's city government.
huggingface.co/prefeitura-ri…

103
259
2,552
1,208,278

Hugging Face retweeted

SITUATION DETECTED: The city of Rio de Janerio has post-trained a model.
Based on Qwen 7/2, Rio 3.5 Open 397B adds SwiReasoning on top of the base Qwen model — a framework that dynamically switches between standard chain-of-thought and latent-space reasoning, guided by entropy-based confidence signals, so the model only "thinks out loud" when it needs to and otherwise reasons silently in hidden space for better token efficiency.
63
173
2,176
225,285
Hugging Face retweeted
There is no inevitability in AI. We all have agency in what comes next:
Path 1: closed-source APIs, concentration of power, and a future decided by a handful of people in Silicon Valley and DC
Path 2: open-source AI, where everyone gets to participate, own, and build together, including orgs like the city of Rio.
Pick your path anon!

SITUATION DETECTED: The city of Rio de Janerio has post-trained a model.
Based on Qwen 7/2, Rio 3.5 Open 397B adds SwiReasoning on top of the base Qwen model — a framework that dynamically switches between standard chain-of-thought and latent-space reasoning, guided by entropy-based confidence signals, so the model only "thinks out loud" when it needs to and otherwise reasons silently in hidden space for better token efficiency.
30
45
468
35,258
Hugging Face retweeted

Jun 12
MiniMax v3 is out and it ships with an MSA kernel that gets crazy speedups the longer your sequence length is.
It's shipped on the Kernel Hub as well and is integrated in transformers: huggingface.co/kernels/MiniM…
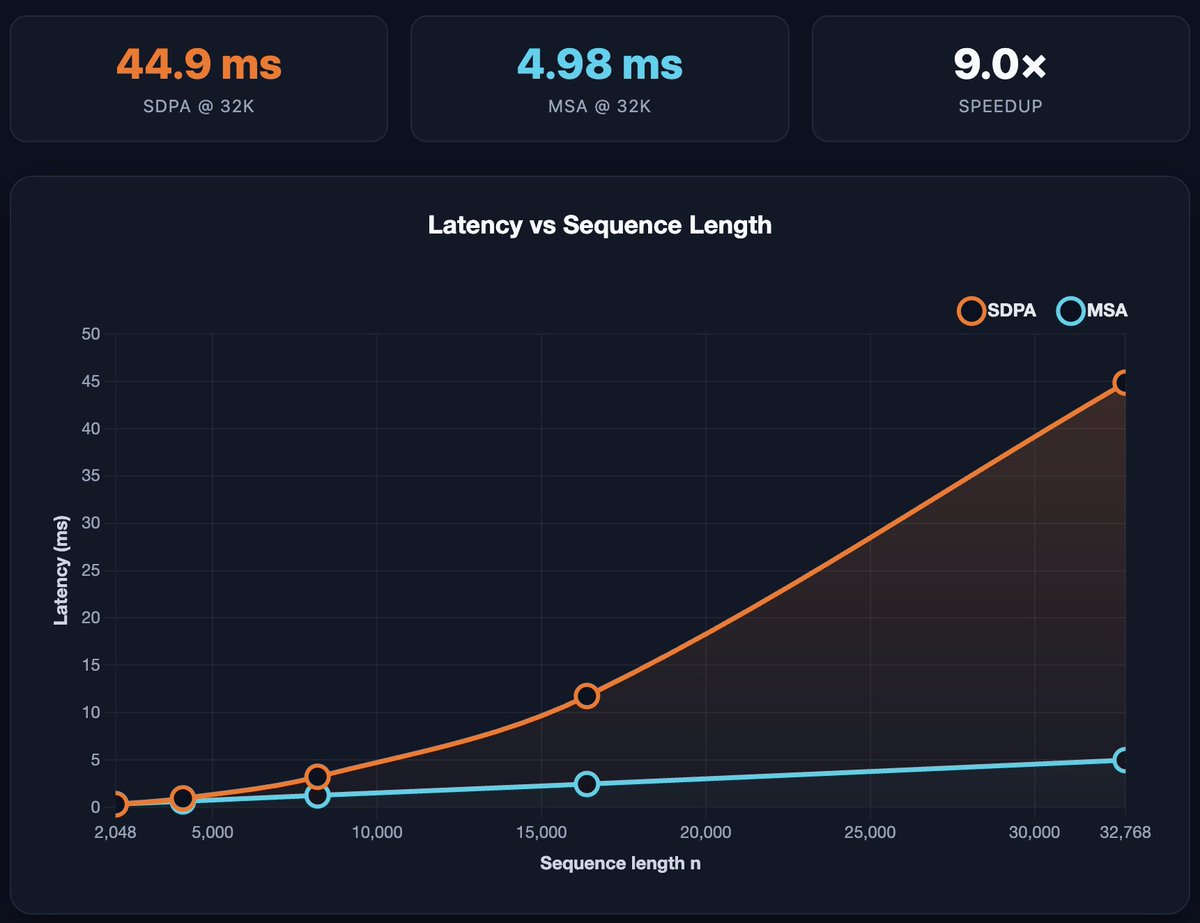
5
10
42
10,250
Hugging Face retweeted

Jun 12
interesting MiniMax shipped a kernel on Hugging Face 👀
huggingface.co/kernels/MiniM…
1
6
57
16,757
Hugging Face retweeted

Jun 12
🤗 MiniMax M3 from @MiniMax_AI is now live on @huggingface — supported by Novita.
Open weights.
~428B total parameters.
~23B activated parameters.
Built for the Agent Era.
3
12
61
15,418
Hugging Face retweeted
Jun 12
Have a great week end (don't forget to touch grass 🍃)
1
3
46
11,258
Hugging Face retweeted

Jun 12
new transformers tutorials just dropped for vision 🔥
🛰️ segmentation on satellite imagery: fine-tune RF-DETR-Seg segment buildings
📱 object detection on mobile UI: fine-tune RF-DETR on screenshots
runs on toaster, converges fast, give to your agent for your use cases🫡
8
32
177
14,893
Hugging Face retweeted

Jun 12
MiniMax M3, Open-Weight, Now On Hugging Face , with only ~428B parameters and ~23B activated parameters
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…

Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

112
328
2,740
621,465
Hugging Face retweeted

Jun 12

14
17
245
18,872
Hugging Face retweeted

Jun 12
Published my first kernel to go the last mile to optimize LTX-2.3 from @Lightricks!
torch.compile cuDNN attn already gave a 1.42x boost. W/ the custom kernel added, I got 1.52x on a GB10 🔥
This was my systematic exploration of a simple agentic kernel dev workflow.
More 👇

7
6
59
9,305
Hugging Face retweeted

Jun 12
Real-time social robotics, from the cloud to your local device.
Watch Ian from our DevX team use Gemini Live for a seamless voice chat with Reachy Mini.
Then, stick around until the end to see the robot running locally on Gemma 4!
37
144
1,270
99,968
Hugging Face retweeted

Jun 11
Agents are only as good as the environments behind them. At Mercor, we've built deep expertise in the realistic, economically-grounded environments that help agents bridge the gap from the lab to real-world usefulness.
We want to put that expertise to work for the broader ecosystem—so we're glad to be joining the OpenEnv committee, alongside Meta @PyTorch, @nvidia, @PrimeIntellect, @huggingface, and others, to help guide the open foundation for agentic environments.

6
20
78
15,407
Hugging Face retweeted
Jun 11
HF has become the best storage platform for PRIVATE and PUBLIC models and datasets, both intermediary and final ones! Great example from @heyjasperai who used HF buckets to store their Monet dataset and train models directly on it!
More details: huggingface.co/storage/testi…

8
17
105
18,063
Hugging Face retweeted

Jun 11
Explore your @huggingface repos in a whole new way 🔥
Visualize storage, discover outliers, and navigate your repos directly from the terminal.
`hf repos ls --explore`
8
18
110
27,094

Hugging Face retweeted

Jun 8
🔓 And the best part — we're open-sourcing it.
1,000 tps on a 1T model wasn't a single breakthrough — it's deep model × system co-design between the MiMo and TileRT teams, all on general-purpose GPUs (no Cerebras-style wafer-scale, no Groq-style SRAM ASICs).
On the model side: FP4 quantization (smaller footprint, less memory traffic) DFlash, our block-masked parallel speculative decoding that accepts far more tokens per verification. On the system side, TileRT tailors its compiler & kernels to exactly these techniques.
The result: a 1T model breaking 1,000 tps on a single, standard 8-GPU node.
🤗 Open weights (FP4 DFlash checkpoint): huggingface.co/XiaomiMiMo/Mi…
11
49
578
40,037