
 made by @healerstag
made by @healerstag
Apr 25
Previously, I explored LangChain System Design & how the pipeline works.
Today, I went one level deeper.
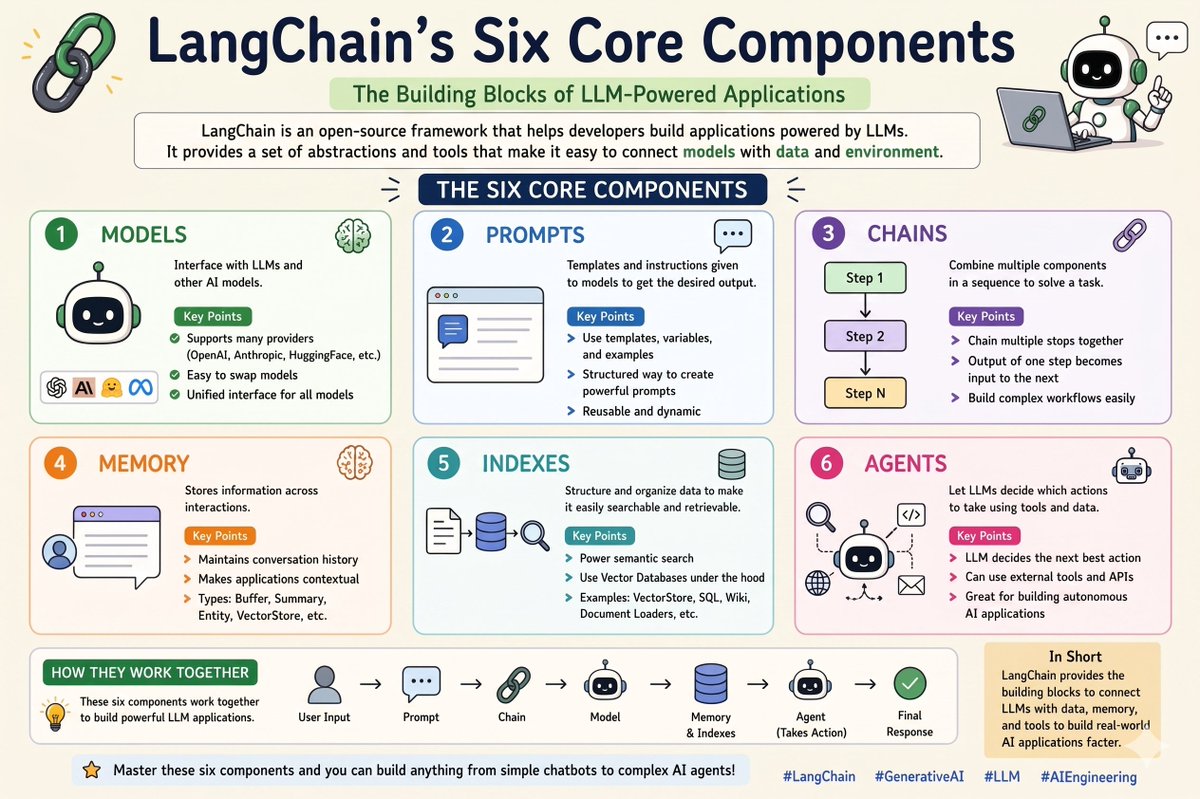
LangChain is built on 6 core components that power everything.
LangChain’s 6 Core Components:
Models → Interface to interact with LLMs & embedding models
Prompts → Structured inputs that control model output
Chains → Connect multiple steps into a pipeline
Memory → Stores conversation context across interactions
Indexes → Connect external data (PDFs, DBs, APIs) using retrieval
Agents → AI systems that can think, decide & take actions
Component 1: Models
Models are the core interfaces for interacting with AI models.
Historical challenges in NLP:Natural Language Understanding (NLU): ability to comprehend user queries (e.g., "Can you check my email now?").
Context-aware text generation: producing relevant, coherent responses.
LLMs solved these two major problems by training on vast internet data, enabling advanced understanding and contextual generation.
New challenges post-LLMs: LLMs are large (often >100GB), making local deployment difficult for individuals or small companies due to resource and cost constraints. Solution: API-based access from providers like OpenAI, enabling pay-per-use without local resource needs. However, APIs from different providers (OpenAI, Anthropic, Claude, etc.) have different interfaces and response formats, complicating multi-provider support.
LangChain’s Models component standardizes API interactions, allowing developers to communicate with various LLMs using a consistent interface with minimal code changes.
Example: Switching between OpenAI and Claude APIs requires changing only a couple of lines in code, with similar response parsing.
LangChain supports two types of models: Language Models (LLMs): text-in, text-out (e.g., chatbots, AI agents). Embedding Models: text-in, vector-out; used primarily for semantic search and similarity tasks.
LangChain supports numerous providers and models, with features like: Tool calling Structured JSON output Local deployment capability Multi-modal input
Documentation lists many supported providers such as OpenAI, Anthropic, MistAI, Azure, HuggingFace, IBM, etc.
Component 2: Prompts
Prompts are the inputs sent to LLMs.
They are extremely sensitive; minor changes in prompts can drastically alter outputs.
Prompt engineering has emerged as a professional field with many jobs, focusing on crafting effective prompts.
LangChain offers flexible and powerful prompt creation, supporting: Dynamic, reusable prompts with placeholders (e.g., "Summarize {topic} in {tone} tone"). Role-based prompts where the system and user prompts can be layered to guide LLM behavior (e.g., system prompt indicating an experienced doctor, user prompt asking medical questions).
Few-shot prompting: providing examples to the model before querying, improving output accuracy (e.g., customer support ticket classification with labeled examples).
These prompt templates enable guiding the model to generate contextually relevant responses.
Component 3: Chains
Chains allow building pipelines by connecting multiple components or models sequentially or conditionally.
Example: A pipeline that translates a lengthy English text (~1000 words) into Hindi and then summarizes it in less than 100 words.
Without chains, manual management of input-output at each stage is needed; chains automate passing outputs as inputs to subsequent stages.
Types of chains possible: Sequential chains: simple one-after-another steps. Parallel chains: sending the same input to multiple models, combining their outputs. Conditional chains: branching logic based on conditions (e.g., different actions based on customer feedback sentiment).
Chains drastically reduce development complexity and manual coding.
Component 4: Indexes
Indexes connect applications to external knowledge sources like PDFs, websites, and databases to answer queries beyond the LLM’s training data.
Indexes consist of four subcomponents: Document Loader: loads external data (e.g., PDFs from cloud storage). Text Splitter: breaks documents into smaller chunks for processing (e.g., page-wise or paragraph-wise). Vector Store: converts chunks into embeddings (vectors) and stores them in a specialized database for semantic search. Retriever: on a query, generates an embedding, performs semantic search on vector store, and returns relevant chunks to LLM for response generation.
Use case example: Asking company-specific private questions (e.g., leave policy) that ChatGPT cannot answer because it lacks access to proprietary data.
By connecting an LLM to private documents via indexes, the system can answer such queries effectively.
Component 5: Memory
LLM API calls are stateless by default; each request is independent with no knowledge of previous interactions.
This causes problems for applications like chatbots, which require conversational context.
LangChain’s Memory component adds statefulness to conversations, preserving context across API calls.
Types of memory supported:
Conversation Buffer Memory: stores entire conversation history and sends it with each API call. Drawback: large history increases cost. Conversation Buffer Window Memory: stores only last N interactions (e.g., last 100 messages). Summary-Based Memory: stores a summarized version of the conversation to save tokens and cost. Custom Memory: specialized storage for user preferences or facts for personalized conversations.
Memory enhances user experience by enabling context-aware interactions.
Component 6: Agents
Agents are the most advanced LangChain component, enabling creation of AI agents with reasoning and tool access.
AI agents differ from chatbots in that they not only converse but also perform actions based on user requests.
Example: Chatbot can answer “What are the best summer travel destinations in India?” based on training data. AI agent can answer “What’s the cheapest flight from Delhi to Shimla on Jan 24?” by calling external APIs and fetching live data. Further, AI agent can book the flight automatically via API.
Key agent capabilities: Reasoning: breaking down complex queries step-by-step (e.g., chain-of-thought prompting). Tool Access: interacting with APIs or utilities like calculators, weather services, booking systems.
Example workflow: User asks agent to multiply today’s Delhi temperature by 3. Agent queries weather API to get temperature. Agent uses calculator tool to multiply the value. Agent returns final answer to user.
Agents are considered the future of AI applications, combining LLM understanding with actionable capabilities.
LangChain simplifies building such agents, and future videos will cover their detailed implementation.
Today I discussed about foundational introduction to all six core LangChain components.
In Upcoming tweets, I will deep dive into each component, starting with Models.
#GenerativeAI #LangChain #AIEngineering #LLM
Apr 23

Yesterday, I explored what LangChain is and why it’s important.
Today, I went deeper into:
How LangChain actually works behind the scenes (System Design)
Search Techniques: Keyword vs Semantic Search
Keyword Search: Finds pages containing specific words (e.g., "linear regression").
This method is inefficient and often returns many irrelevant pages due to lack of context understanding.
Semantic Search: Attempts to understand the meaning of the query and retrieves contextually relevant pages, drastically reducing irrelevant results and improving answer quality.
Semantic search identifies pages discussing the concept “parts of linear regression” rather than just matching keywords.
Role of the ‘Brain’ Component (Core System)
The system synthesizes the user query and the retrieved pages into a system query sent to the “brain”.
The brain has two key capabilities:
Natural Language Understanding (NLU): To comprehend the meaning of the query in any language (e.g., English or Hindi).
Context-Aware Text Generation: To read the relevant pages, extract the precise answer segments, and generate a coherent response.
This mechanism ensures a contextual, meaningful answer rather than a raw text dump.
Why Not Pass the Entire Book Directly to the Brain?
Sending the full book to the brain is computationally expensive and inefficient.
Analogous to a student asking a teacher for help: specifying the exact page of doubt enables faster and more accurate answers.
Hence, semantic search reduces the scope of data passed to the brain, improving efficiency and response quality.
Deep Dive: How Semantic Search Works via Embeddings
Semantic search transforms texts and queries into vector embeddings :- numeric representations capturing semantic meaning.
Example: Three paragraphs about cricketers Virat Kohli, Jasprit Bumrah, and Rohit Sharma are converted into vectors.
A query like “How many runs has Virat scored?” is also vectorized.
The system calculates similarity between the query vector and paragraph vectors. The paragraph with the highest similarity is selected to answer the query.
This vector similarity technique enables meaning-based search rather than keyword matching.
Detailed System Workflow :-
1.Uploaded PDFs are stored in cloud storage (e.g., AWS S3).
2.The document loader imports the PDF into the system.
The PDF is split into smaller chunks (e.g., by pages, paragraphs, or chapters).
3.Each chunk is converted into embeddings using an embedding model, resulting in potentially thousands of vector representations stored in a vector database.
4.When a user submits a query, the query is also embedded into vector form.
5.The system retrieves the top-N most similar chunks by comparing query embeddings with stored embeddings.
6.These chunks and the query are combined into a system query sent to the brain (LLM) for answer generation.
The final answer is returned to the user.
Major Challenges in Building Such a System
Building the Brain: Developing a component that can fully comprehend queries and generate accurate context-aware answers is very challenging.Breakthrough came in 2017 with the Transformer model, followed by models like BERT and GPT, enabling advanced NLU and text generation. Today, existing LLMs handle this challenge, so developers can use APIs rather than building from scratch.
Computational Challenge: Hosting and running large LLMs on personal servers is resource-intensive and costly.Solution: Companies like OpenAI and Anthropic provide APIs for LLMs hosted on their servers, enabling pay-as-you-use access without infrastructure overhead.
Orchestration Challenge: Integrating and coordinating multiple system components (document loaders, text splitters, embedding models, vector databases, LLM APIs) into a seamless pipeline is complex.Manually coding and maintaining this is difficult and error-prone.
How LangChain Addresses These Challenges
LangChain offers built-in functionality and components enabling plug-and-play integration of all moving parts.
It handles the orchestration between components, reducing boilerplate code and complexity.
LangChain supports switching components easily (e.g., changing embedding models, vector databases, or LLM providers) without rewriting the core logic.
It enables developers to focus on their business logic and ideas rather than infrastructure details.
Key Benefits of LangChain
Chain Concept:Supports chaining multiple components and tasks into pipelines (chains). Automates passing outputs from one component as inputs to another. Supports complex workflows including parallel and conditional chains.
Model-Agnostic Development:Compatible with various LLM providers (OpenAI, Google, open-source LLMs). Easy to switch models or providers without changing application logic.
Comprehensive Ecosystem:Offers numerous document loaders (PDF, cloud files, etc.). Multiple text splitters and embedding models are available. Variety of vector stores/databases supported.
Memory and State Handling:Supports conversational memory, enabling context retention across multiple queries. For example, remembers previous discussion about linear regression without needing explicit mentions again.
Common Use Cases for LangChain
Conversational Chatbots:Replace or augment customer call centers with chatbots that understand queries and provide solutions. Chatbots handle first-level questions; complex queries are forwarded to humans.
AI Knowledge Assistants:Chatbots integrated with specific data (e.g., course materials) to answer domain-specific questions.
AI Agents:Advanced chatbots that perform actions, not just conversations (e.g., booking tickets, making reservations). Useful for users unfamiliar with complex websites or processes.
Workflow Automation:Automate business or personal workflows using AI-based chains.
Summarization and Research Helpers:Summarize large documents or research papers. Useful when uploading large private data not allowed on public LLM services. Enables private company-specific chatbot solutions.
next time, I will cover the complete LangChain ecosystem and its each component in detail.
Viewers are encouraged to like, share, and repost.
#GenerativeAI #LangChain #AIEngineering #RAG #LearningInPublic

2
1
200




Mistai hookup like quinn and santana did in glee #imcooking
1
8
137


your fav YJ ship based on your fav character
nat: mistynat
jackie: mistyjackie
shauna: mistyshauna
lottie: mistylot
misty: mistynat
tai: mistai
van: mistyvan
mari: mistymari
laura lee: mistylee
akilah: mistykilah

5
2
22
1,068