
12 Hidden Claude Code Features That Change How you Work
Source:@AnalyticsVidhya analyticsvidhya.com/blog/202…
#ClaudeAI #AppliedAI #GenerativeAI #LLMs #PromptEngineering #AIAgents #AIWorkflows #AIEngineering #DigitalTransformation #AppliedAI #LearningTogether #AITrends #ResponsibleAI

1
9

🚀 AI Starts With Data, Not Prompts.
Many engineers jump directly into:
✅ RAG
✅ Agents
✅ MCP
✅ LLMs
✅ Vector Databases
But there is one problem.
Most real-world enterprise data is not AI-ready.
It's buried inside:
📄 PDFs
📄 Claims
📄 Contracts
📄 Invoices
📄 Reports
📄 Scanned Documents
Before AI can reason, retrieve, or automate...
it first needs structured, high-quality data.
That's where Document Intelligence comes in.
In this free hands-on session, I walk through how to build an end-to-end Document Intelligence pipeline that transforms raw PDFs into AI-ready datasets.
Topics covered:
🔹 PDF Text Extraction
🔹 Claim-wise Document Processing
🔹 Data Cleaning & Normalization
🔹 Chunking Strategies
🔹 Embeddings & Vector Databases
🔹 RAG Foundations
🔹 AI Agents
🔹 Structured Data Extraction
🔹 ML-Ready Dataset Creation
If you're a Software Engineer looking to move into AI Engineering, this is one of the most practical starting points.
AI doesn't begin with ChatGPT.
AI begins with data.
🎥 Full video available on my YouTube channel.
What do you think is harder today?
1️⃣ Building the AI model
2️⃣ Preparing the data for the AI model
#AI #AIEngineering #DocumentIntelligence #RAG #AIAgents #LLM #MachineLearning #DataEngineering #SoftwareArchitecture #CloudArchitecture #CareerGrowth #AIArchitect #RahulSahay
youtube.com/watch?v=seITz8Cx…

21

6

Submitted my Full Stack AI Engineer assignment for @getalchemyst.
12 hours of building an AI Agent Console that handled both normal and chaos modes connection drops, out-of-order messages, duplicates, latency spikes, and tool calls.
#AIEngineering #AlchemystAI
1
9

🛠️ 开源工具推荐:《Hivemind》—— 给所有 AI Coding Agent 共享一个大脑,从真实轨迹里自动提炼技能
用了好几个 AI Coding Agent 的人大概都遇过这件事:每个工具学到的东西都锁在自己的上下文里,换一个工具就得从头来,例如Claude Code 里用顺手的工作流,在 Codex 或 Cursor 里根本不知道。
Hivemind 解决的是这个问题:它作为所有 Agent 共享的记忆层,自动捕获会话里的 prompt、工具调用和响应轨迹,把重复出现的高质量模式挖掘出来,转化成可复用的 SKILL.md 文件,在团队和工具之间传播。来自 Activeloop(Y Combinator 支持),开源创作者的 Deep Lake 向量数据库同团队。
核心特性:
1. 自动模式挖掘:从你的实际使用轨迹里发现什么值得保存,不需要手动整理
2. 跨 Agent 技能传播:SKILL.md 格式,Claude Code、Codex、Cursor、Hermes Agent 等全支持
3. 混合检索(词法 语义):关键词精确查找和语义模糊匹配双模式覆盖
4. SQL 虚拟文件系统:结构化存储,记忆可查询、可版本化、可迁移
5. 会话摘要 Wiki 自动生成:长对话浓缩成可索引的知识片段
6. 基准验证(LoCoMo):比基线便宜 25%、每个问题少用 1.7 倍 token、减少 31% 交互轮次
项目特别适合同时用多个 AI Coding Agent 工作、希望工具之间能互相「学习」而不是各自孤立运行的开发者和工程团队。目前已获得 929 stars ⭐,是当前跨 Agent 共享记忆与技能传播领域最完整的开源实现之一。
与单个 Agent 的内置记忆系统(如 Claude Code 的 CLAUDE.md)相比,Hivemind 的核心差异在于「跨工具」:不是 Claude Code 自己的记忆,而是所有工具共享的技能库,换工具不等于从头开始,团队的工程智慧可以在工具间传播。
github.com/activeloopai/hive…
#AIAgent #ClaudeCode #VibeCoding #codex #AIEngineering

4
1
26
1,678

hardwiring your AI product to one LLM provider is a mistake.
OpenAI has an outage? everything breaks.
pricing changes? margin disappears.
a better model drops? you can't switch.
today i called 4 providers through LangChain — same code, different models underneath.
𝗪𝗛𝗔𝗧: LangChain chat models are an abstraction layer over every major LLM. one .invoke() call works for OpenAI, Anthropic, Gemini, HuggingFace.
𝗪𝗛𝗬: provider flexibility is risk management. the model landscape moves fast. your architecture shouldn't lock you in.
𝗥𝗘𝗔𝗟 𝗪𝗢𝗥𝗟𝗗: route simple queries to Gemini Flash (cheap), complex reasoning to Claude (best quality), domain tasks to a fine-tuned HuggingFace model (private). one codebase. intelligent routing.
the model is just a config. that's the shift.
code 👇
github.com/victorjanni/Langc…
#LangChain #LLMs #AIEngineering #BuildingInPublic

34

#𝐀𝐈 #𝐅𝐫𝐞𝐞𝐋𝐋𝐌𝐀𝐏𝐈 #𝐎𝐩𝐞𝐧𝐒𝐨𝐮𝐫𝐜𝐞 #𝐋𝐋𝐌 #𝐀𝐏𝐈𝐆𝐚𝐭𝐞𝐰𝐚𝐲 #𝐀𝐈𝐃𝐞𝐯𝐞𝐥𝐨𝐩𝐦𝐞𝐧𝐭 #𝐂𝐨𝐝𝐢𝐧𝐠 #𝐌𝐚𝐜𝐡𝐢𝐧𝐞𝐋𝐞𝐚𝐫𝐧𝐢𝐧𝐠 #𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐯𝐞𝐀𝐈 #𝐃𝐞𝐯𝐞𝐥𝐨𝐩𝐞𝐫𝐓𝐨𝐨𝐥𝐬 #𝐀𝐈𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠
#𝐭𝐡𝐫𝐞𝐚𝐝
#𝐝𝐫𝐲𝐥𝐢𝐤𝐨𝐯

ALT 𝐓𝐡𝐞 𝐜𝐨𝐯𝐞𝐫 𝐢𝐦𝐚𝐠𝐞 𝐨𝐟 𝐭𝐡𝐞 𝐩𝐨𝐬𝐭.
1
1
1
21

RAG isn't a silver bullet! Large context windows hide errors. Build robust LLM apps with strong data ingress (e.g., local PDF parsing via Docling) & rigorous model evaluation. #LLMOps #AIEngineering
12

🚀 Day 226 – #LearnInPublic
🔎 Learned Production RAG Architectures
🔹 Retrieval, reranking & generation pipelines
🔹 Vector databases for semantic search
🔹 Chunking, embeddings & context management
#RAG #LLM #AIEngineering #MLOps #100DaysOfCode
1
16

The architecture evolved from a heavily modular agent system into a lean 3-agent core optimized for execution reliability and lower latency.
Demo architecture breakdown below 👇
GitHub: github.com/Hou-dini/project-…
#AIEngineering #MultiAgentSystems #LLMOps #AgenticAI
7

anthropic says claude wrote 80% of their production code last month. one engineer hasn't coded in 5 months.
i'm an iOS dev. i shipped an iOS Android app solo anyway.
the shift isn't coming. it's already here.
#ClaudeCode #AIEngineering
1
1
18

LLMs are powerful, but they need memory & context. 🧠
Unlocked the "Building AI Agents with @MongoDB" badge via @Credly! Ready to build autonomous agents using vector embeddings. 🤖
Check out the badge: credly.com/badges/4bb9ea7c-8… #AIEngineering #MongoDB #AIAgents #VectorSearch #mern

1
12

🤔 You picked the best model on the market. Your app still gives inconsistent answers, forgets context mid-conversation, and breaks when real users show up.
The problem isn't the LLM. Swipe through to see what's actually going wrong - and why so many AI apps in 2026 are failing for the same reason.
Once you see it, you can't unsee it.
If you're ready to fix the layer most builders ignore, our Agentic AI Bootcamp starts July 14.
10 weeks, instructor-led, built for practitioners who are done debugging symptoms and want to fix the root cause. Link in the replies.
#ContextEngineering #AgenticAI #LLMDevelopment #AIEngineering #DataScienceDojo



2
3
6
759

12h
Day 6 of my AI/LLM Internship Journey 🚀
Today I learned:
✅ FastAPI Basics
✅ REST API Design
✅ Pydantic for Data Validation
✅ async/await in Python
✅ Virtual Environments & .env Files
✅ Built a Chat API endpoint
One thing that clicked today:
Pydantic validates incoming data before it reaches your business logic, making APIs much safer and more reliable.
Every day I'm learning something new in AI Engineering and Backend Development.
What was the most useful FastAPI concept you learned as a beginner?
#AI #LLM #MachineLearning #FastAPI #Python #GenerativeAI #AIEngineering
35

Deleting for one user never breaks another user's search → Concurrent uploads are handled safely with no extra infra Vectors are shared. Access is isolated. That's the right model for multi-user RAG.
#RAG #Qdrant #VectorDatabase #LLM #AIEngineering #Python
1
3

I find it funny everyone talking about local models coz fable was banned. Local models are far from anything fable, opus, gpt 5.5 or even deepseek, kimi, glm and others can achieve. Let’s stop kidding ourselves and be realistic
#aiengineering
15

The best AI engineers don't chase every new model.
They focus on: • Understanding the problem • Evaluating outputs • Building reliable systems • Delivering value
Tools change. Fundamentals last.
#AIEngineering #MachineLearning
1
17

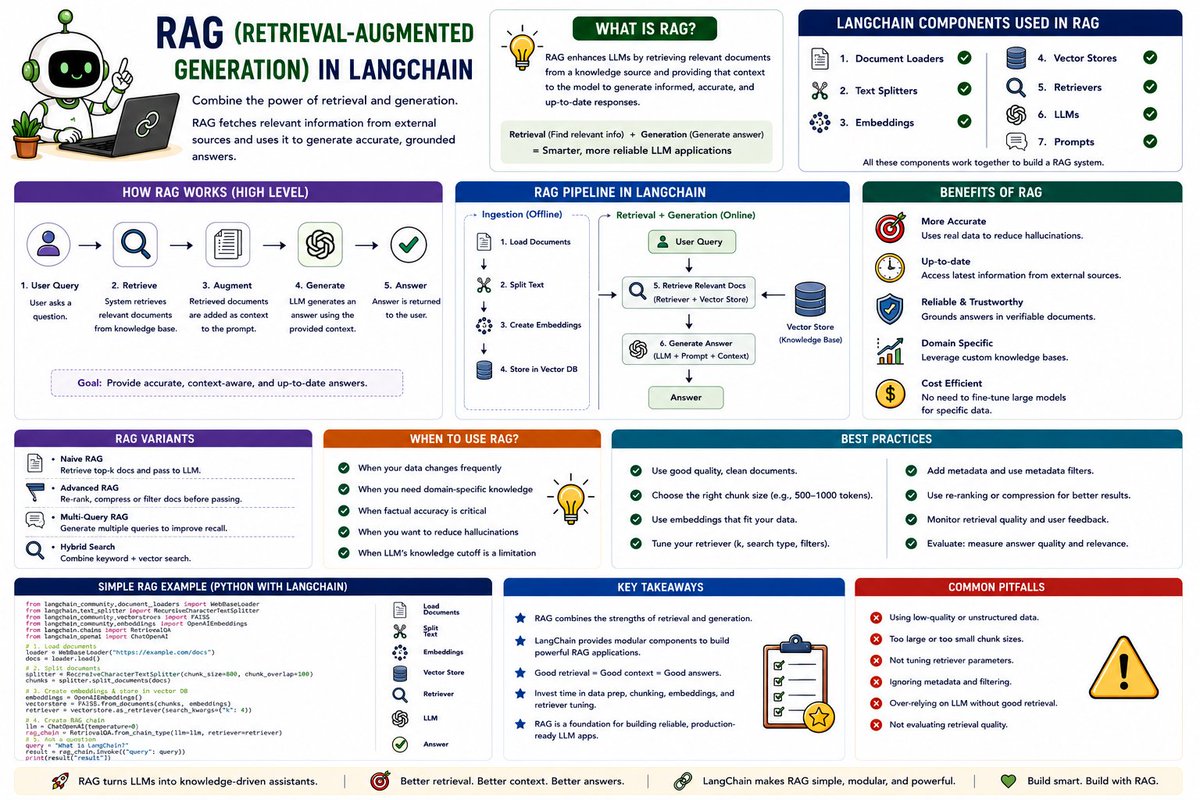
Today I am introducing and continuing the Gen AI with LangChain series with a focus on an important topic called RAG (Retrieval-Augmented Generation), a highly useful generative AI application widely adopted after the advent of large language models (LLMs).
Earlier where four main components essential to RAG were covered extensively:
-Document Loaders: Tools for loading data from various sources.
-Text Splitters: Mechanisms to divide large texts into manageable chunks.
-Vector Stores: Databases that store text as embeddings (dense vector representations).
-Retrievers: Components for semantic search over vector stores to fetch relevant chunks.
With this foundation, the time is now right to understand RAG in detail, including its definition, necessity, and functioning.
It begins with the “Why” of RAG by discussing limitations of LLMs:
-LLMs are large transformer-based neural networks with billions of parameters (weights and biases).
-They undergo pre-training on massive datasets (internet-scale) that encodes parametric knowledge inside the model’s parameters.
-The greater the parameter count (e.g.,7B→13B→70B)(e.g.,7B→13B→70B), the more knowledge the model can potentially store.
-Users query LLMs via prompts to access this stored knowledge.
However, there exist three major limitations or problem scenarios in the traditional prompt-LLM approach:
1. Private Data Queries:
The LLM cannot answer questions about private or domain-specific data not seen during pre-training. For example, querying about a course video’s content on a private website fails because it was never part of the pre-training data.
2. Recent Data/Timeliness:
LLMs have a fixed knowledge cutoff date. Text or events after that point (new news, updates) won't be reflected in their parametric knowledge, leading to failures in answering up-to-date questions.
3. Hallucination:
The model may generate factually incorrect information confidently. For instance, falsely claiming Einstein played football professionally. This issue arises due to the probabilistic nature of LLMs trying to predict likely responses, sometimes inventing facts.
These three challenges make relying solely on parametric knowledge insufficient.
Fine-tuning is introduced as one common technique to partially address these problems:
-Fine-tuning means retraining a pre-trained model on a smaller, domain-specific dataset.
-This adapts the model to additional knowledge (e.g., medical domain), improving accuracy on specialized queries.
-Two methods of fine-tuning are explained:
1. Supervised Fine-tuning: Using labeled prompt-response pairs (inputs and desired outputs) - usually thousands to millions of examples.
2. Continued Pre-training (Unsupervised): Training on domain-specific raw texts without labels.
-Additional advanced methods like RLHF (Reinforcement Learning with Human Feedback) and LoRA (parameter-efficient tuning) are mentioned.
-An analogy is drawn: Fine-tuning is like an engineering graduate undergoing company-specific on-the-job training to perform domain-specific tasks well.
How fine-tuning solves the three problems:
-Private Data: The model’s parametric knowledge now includes private/domain-specific info after tuning.
-Recent Data: Frequent re-tuning with updated datasets reflects new information. However, this gets expensive and repetitive if updates are frequent.
-Hallucination: Fine-tuning on tricky prompts with explicit "I don't know" answers can reduce hallucination by teaching the model to avoid guessing.
Limitations of fine-tuning:
-Computationally expensive to train huge models.
Requires expert AI engineers and data scientists.
Frequent updating is costly and slow, making it impractical for rapidly changing data.
Hence, fine-tuning, while helpful, is not always the ideal solution.
A second, alternative technique called In-Context Learning is introduced:
-Defined as the ability of large language models (like GPT-5, Claude, LLaMA) to learn how to perform a task by observing examples in the prompt itself without updating the model weights.
-This is also known as few-shot prompting, where examples of input-output pairs are provided inline, and the model generalizes from these to new inputs.
The idea is extended: Instead of few-shot prompting with examples of task solutions, send the task context itself as prompt context.
-Example: A long lecture on linear regression (2 hours).
-When a student asks a question about "gradient descent," embed the specific transcript segment related to gradient descent as context in the prompt.
-This approach provides the model with external knowledge during prompt time rather than relying solely on its parametric knowledge.
This technique is defined as Retrieval-Augmented Generation (RAG):
-RAG means making a language model smarter by injecting external relevant information (context) at query time.
-The prompt comprises both the user query and surrounding context retrieved from external knowledge.
-The LLM uses both its internal parametric knowledge and the provided external context to answer, drastically improving accuracy and reliability.
Technical architecture of a RAG system broadly includes two core concepts:
-Information Retrieval: A well-studied traditional area focused on efficiently finding relevant documents or data segments.
-Text Generation: Enabled by LLMs for generating natural language answers.
RAG combines these:
The process can be divided into four steps:
1.Indexing
Preparing an external knowledge base
Loading and processing source documents
2.Retrieval
Searching the knowledge base
Finding relevant pieces (chunks) based on the user query
3.Augmentation
Creating a prompt that combines the user query and retrieved context
Guiding the LLM with relevant information
4.Generation
The LLM generates the answer
Uses the prompt and its internal knowledge to respond
Overall, RAG is positioned as a better, cheaper, and simpler alternative to fine-tuning that does not require retraining or labeled data, just maintaining an updated vector store.
Next , I will talk about "Tools".
#GenerativeAI #LangChain #AIEngineering #LLM #RAG
Jun 10

Today, I continue the Gen Ai/LangChain series focusing on retrievers, a crucial component in building Retrieval-Augmented Generation (RAG) applications.
Retrievers are central in RAG systems to fetch relevant documents based on user queries.
I will explain what retrievers are, their need, different types, and provide live code demonstrations.
This is the fourth core component after covering Document Loader, Text Splitter, and Vector Stores, preparing viewers to start working with RAG systems.
What Are Retrievers?
-A retriever is a component in LangChain that fetches relevant documents from a data source in response to a user query.
-The data source can be a vector store, API, or any repository where documents are stored.
-Process: The user inputs a query → the retriever searches the data source → it identifies and retrieves the most relevant documents → returns them as LangChain Document objects.
-Functionally, a retriever acts like a search engine.
-Retrievers are runnable objects in LangChain with an invoke() method, allowing easy chaining and integration. Multiple retriever types exist to accommodate different use cases.
Classification of Retriever Types
1. Data Source Type :
The nature/source of documents the retriever queries.
Examples:
Wikipedia Retriever
Vector Store Retriever
Archive Retriever (research papers)
2. Search Strategy :
The algorithmic method used to find relevant documents within the data source.
Examples:
Maximum Marginal Relevance (MMR)
Multi-Query Retriever
Contextual Compression Retriever
-Many retrievers exist in LangChain (20-30 ), covering diverse scenarios.
- I will focus on the most relevant and widely-used retrievers with references for further reading.
Wikipedia Retriever
-Queries the Wikipedia API using user queries to fetch relevant articles as LangChain Document objects.
-Works via keyword matching (not semantic or syntactic search).
-Acts as a search engine over Wikipedia content, not as a document loader that pulls all articles.
-Example: Query about "Geopolitical history of India and Pakistan from a Chinese perspective" → Wikipedia API returns relevant articles based on keyword overlap.
Vector Store Retriever
--The most common retriever type in LangChain.
Performs semantic similarity search by comparing vector embeddings of the user query with vectors of stored documents.
-Workflow:Documents are embedded into dense vectors using an embedding model.
-Vectors are stored in a vector database (e.g., Chroma, Faiss).
-Query is vectorized and compared against stored vectors to identify most similar documents.
-Supports integration with multiple vector stores and embedding models.
Why use a vector store retriever instead of direct similarity search?
-Vector stores provide only one search strategy (similarity-based).
-Retrievers offer abstraction and the ability to implement multiple search strategies beyond simple similarity search, enhancing flexibility and advanced querying capabilities.
Search Strategy-Based Retrievers: Maximum Marginal Relevance (MMR)
-Problem addressed: Simple similarity search often returns documents that are redundant—multiple docs expressing the same idea, limiting diversity in results.
-MMR balances relevance and diversity by selecting documents that are both relevant to the query and dissimilar to already selected documents.
Additional Retriever Types and Resources
-Beyond the featured retrievers, many others exist such as:
Parent Document Retriever
Time Weighted Vector Retriever
Self Query Retriever
On-sample Retriever
Multi Retriever
-For comprehensive detail and code on these retrievers, LangChain documentation is recommended (linked in video description).
-The landscape is broad, and covering all retrievers in one video is impractical.
-Future videos/projects may cover advanced retriever implementations as needed.
Why So Many Retriever Types?
-Different retrievers solve distinct problems and optimize retrieval for various contexts.
-From a generative AI perspective, retrievers are typically used in RAG-based systems:Simple RAG systems may return suboptimal or redundant retrievals.
-Advanced retrievers improve retrieval quality, relevance, and diversity, enhancing downstream generation quality.
-Developers often experiment by replacing or upgrading retrievers in an existing RAG system to improve performance.
-Understanding retrievers is essential for building robust and efficient RAG applications with LangChain.
Key Insights
-Retrievers are fundamental building blocks of RAG systems for effective document retrieval.
-Multiple retrieval strategies exist to tackle inherent challenges like ambiguity, redundancy, and document size.
-LangChain’s design treats retrievers as runnable, extensible components supporting flexible integration.
-Selection and tuning of retriever types directly impact the quality and diversity of results, which in turn influences the final generative AI outputs.
-Understanding these retriever types enables developers to build advanced, optimized RAG workflows adapted to specific application contexts.
#GenerativeAI #LangChain #AIEngineering #LLM #RAG

1
66

dashboards are for humans. logs are for devs. but what about your agents? i’m moving toward structured cli and api outputs designed for agentic consumption. if the agent can’t read the result, the task isn't done.
building for agents means moving past visual feedback. i prefer schema-first architecture where the output is designed to be parsed, not just viewed. when your consumer is an agent, structure is the priority.
#laravel #aiengineering #api #webdev

7

AI is already the future. Are you building it?
SVIT Anantapur — B.Tech & M.Tech in AI & ML. NAAC Accredited. Admissions Open 2026–27. svitatp.ac.in
#SVITAnantapur #AIEngineering

ALT SVIT Anantapur Engineering College poster showing B.Tech CSE AI ML and M.Tech AI Machine Learning admissions open 2026–27. NAAC Accredited, AICTE Approved, JNTUA Affiliated. 100% Placement Assistance. Contact 7093227022.
13