
🚨 PURE TERROR — SHE FELL 164 FEET REALIZING MID-AIR THERE WAS NO CORD 👀💔
Bungee jumper plummeted to her death after staff never attached the rope.
She realized it mid-jump.
164 feet of pure horror.
This is nightmare fuel.
You trusting these “professionals” after this?? Drop your thoughts 👇
#BungeeJumpDeath #NoRope #FatalFall #WTFisHappening instagram.com/reel/DZisL8lEq…
1
2
14,125

Jan 25
「Would You Sacrifice It All?」
@AlexHonnold
He walked where only eagles dream,
bare hands on steel, heart loud above the city.
No rope, no net, just courage and sky,
each hold a question, each move a reply.
At 508 meters he didn’t just reach the top –
he proved that limits are only places
where brave hearts decide to never stop.
/
「你願為此賭上一切嗎」
他走在唯有雄鷹才敢夢見的地方,
雙手緊抓冰冷鋼鐵,心跳聲在城市上空轟鳴。
沒有繩索,沒有安全網,只有勇氣與天空相伴,
每一次抓握都是一個提問,每一步攀登都是一個回答。
在508公尺的高空,他不只是抵達了頂點——
他證明所謂「極限」,其實只是那個地方,
在那裡,勇敢的心選擇永不停止前進。
/
「すべてを懸ける覚悟はあるか」
彼は、ただ鷲だけが夢見ることを許された場所を歩いていた。
両手で冷たい鋼鉄をつかみ、その鼓動は街の上空に轟き渡る。
ロープもなく、安全ネットもなく、あるのは勇気と空だけで、
掴むたびに自分に問いかけ、一歩登るたびにその問いに答えていく。
高さ508メートルの空の上で、彼はただ頂点に辿り着いただけじゃない――
「限界」と呼ばれるものが、本当はただの一点にすぎないと証明した。
そこは、勇敢な心が「まだ終わらない」と選び続ける場所なのだ。
#alexhonnald #Taipei101 #FreeSolo #NoRope #UrbanClimbing #SkyscraperClimb #ClimbingLegend #Sacrifice #WouldYouSacrificeItAll
#台北101 #無繩索攀登 #攀岩傳奇
#日系漫畫畫作
#フリーソロ #ロープなし #クライミング #アーバンクライミング #限界突破 #勇気 #無謀ではなく勇気 #伝説の一歩 #歴史的瞬間

4
218


5 Dec 2025
STATE CHAMPIONS‼️🏆 So proud of this group of seniors‼️ 20 years of “almost”, 20 years of “heartbreak”, 20 years of “not good enough”… BUT NOT TODAY‼️ @MohiganFootball
#ThisIsMorgantown 🏆
#ThisPlay 🏈
#NOROPE 💥


1
11
55
1,488


24 Jul 2025
NoRope,
、、、有刺鉄線でどうしてもアレが浮かんでしまうんです。
24 Jul 2025

名付け親キャンペーン開催!!
この度Waryu Designブランドより有刺鉄線デザインをあしらったヨーヨーホルダーをリリースします。
リリースにあたり
画像のホルダーの商品名を皆様の中から応募で決めさせていただきたくご協力のお願いです。
選ばれた方1名に"ホルダーをプレゼント"と共に"名付け親"になっていただきます!
◯応募期間は本日より1週間後の
"7月31日"まで。
◯応募方法は
・ホルダー名を書いてこちらのポストを引用リポスト
と、
・@waryu_design
↑こちらの公式アカウントをフォロー、でご応募完了です!
ついでにいいねも押してくださると嬉しいです。
※ フォローはこのアカウントではなく
→@waryu_design ←
こちらのアカウントになりますのでご注意ください。
当選者の方にはDMで結果のご連絡と、公式よりポストで皆様に発表をさせていただきます。
沢山の皆様からご応募お待ちしております。

3
445

9 Jul 2025
NoRoPE working better than straight RoPE is still crazy to me
1
1
53

8 Jul 2025
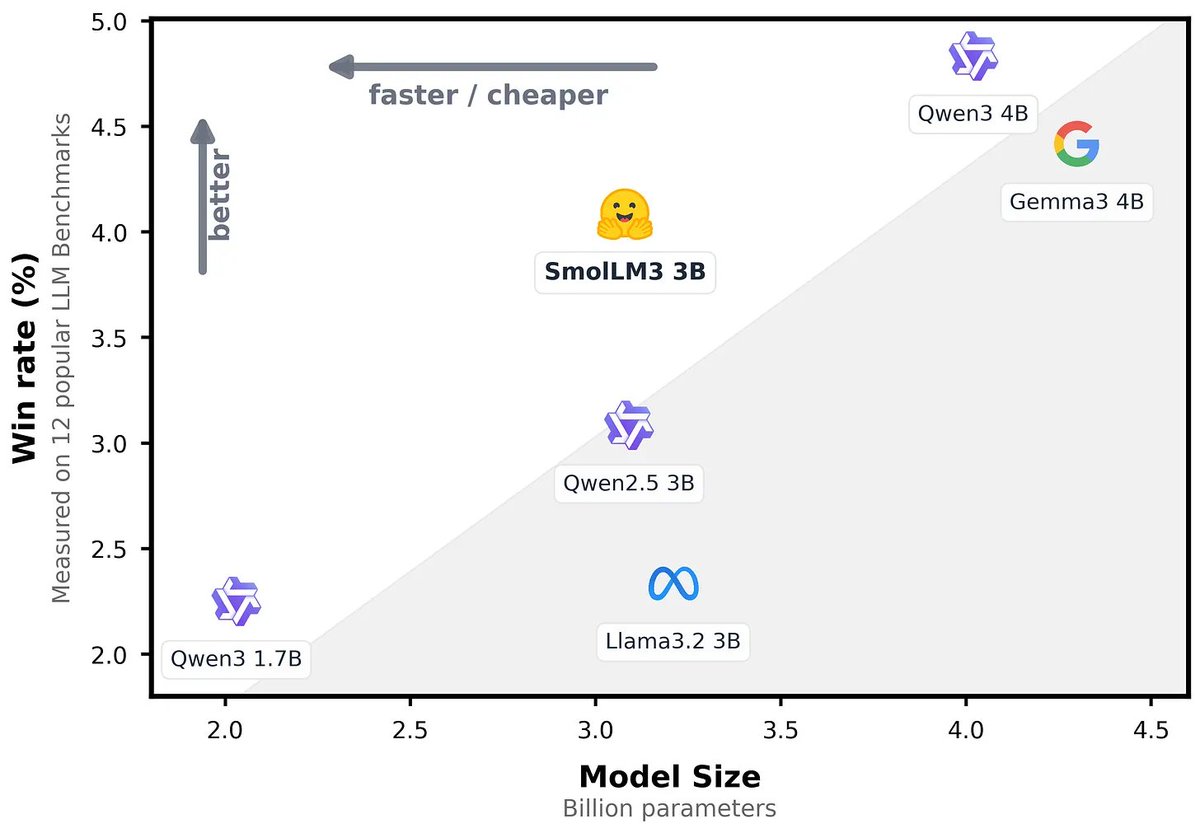
🏆 Huggingface releases SmolLM3, SoTA 3B model, 128k context, dual mode reasoning (think/no_think)
🤖 @huggingface released SmolLM3, a 3B parameter multilingual reasoner that matches bigger 4B models, handles 128k tokens, and ships with an open-sourced training blueprint in this blog post.
🌍 They pre-trained on 11.2T tokens then stretched context with YARN up-sampling, finishing the run on 384 H100 GPUs in 24 days.
🧠 A built-in dual think / no_think switch lets users decide between fast answers or slower chain-of-thought traces.
🛠️ How they pulled it off
Grouped Query Attention trades multi-head attention for 4 compact query groups, shrinking memory without hurting accuracy.
NoPE removes rotary position math from every 4th layer, so the model remembers long passages yet stays snappy with short ones. NoPE is a twist on the usual rotary position embeddings. The SmolLM3 crew borrowed it from the 2025 study “RoPE to NoRoPE and Back Again”. They turn off rotary position math in every 4th transformer layer, so 1 out of 4 blocks handles tokens without any positional stamp.
That small skip keeps numerical noise from piling up as the text gets longer, boosts efficiency, and still keeps short-prompt quality steady. In SmolLM3, the trick helps a 3B model train cleanly on 64k-token sequences and stretch to 128k at inference time without extra hacks.
Intra-document masking keeps sentences from different web pages isolated during training, stopping weird cross-talk.
They mix web, code, and math across 3 stages, bumping code to 24% and math to 13% near the end because those domains sharpen reasoning.
After the main run they add 100B extra tokens only to extend context, raising RoPE theta to 5M so the model natively learns sequences up to 64k before YARN doubles it at inference.
A short “mid-training” on 35B reasoning traces teaches the model to explain its steps, while supervised fine-tuning balances 0.8B reasoning tokens against 1B direct-answer tokens.
They align responses with Anchored Preference Optimization, a stabler cousin of DPO, then merge checkpoints so long-context skill rebounds without losing fresh logic boosts.
Benchmarks show the base model tops every other 3B system on HellaSwag, ARC, and GSM8K, and the instruct variant edges close to Qwen3-4B while staying lighter.
Everything, from datasets to evaluation code, sits on GitHub, and Huggingface.
2
3
21
2,804



10 Feb 2025
All Unsigned 2025, JUCO and Portal Players your time is now! Come join us at UNCP for our Unsigned Prospect Camp March 1st! You do not want to miss this opportunity to Show up and Show Out!
Register today: markhallfootballcamps.com/ev…
#BraveNation #NoRope

19
55
130
33,184
7 Feb 2025
The Newest Addition to #NSD2025
🔏| Tate Simpson
🏟️| Rockingham, NC
🎓| Richmond County
🏈| Defensive Line
📲| @THETATESIMPSON
#NOROPE
9
26
7,832

5 Feb 2025


1
4
31
2,240
5 Feb 2025
The Newest Addition to #NSD2025
🔏| Jonathan Barnett
🏟️| Fredericksburg, VA
🎓| St Michaels HS
🏈| Wide Receiver
📲| @jon_barnett3
#NOROPE
22
56
13,707
5 Feb 2025
The Newest Addition to #NSD2025
🔏| Duke Lewis
🏟️| Starke, FL
🎓| Bradford HS
🏈| Defensive End
📲| @DemaurisLewis
#NOROPE
14
34
9,592
5 Feb 2025
The Newest Addition to #NSD2025
🔏| Kayon Mitchell
🏟️| Charlotte, NC
🎓| Rocky River HS
🏈| Offensive Line
📲| @Kayon_Mitchell
#NOROPE
14
29
5,975
5 Feb 2025
5 Feb 2025

The Newest Addition to #NSD2025
🔏| Kentrelle White
🏟️| Sanford, NC
🎓| Lee County HS
🏈| Offensive Line
📲| @kdub54439761
#NOROPE
3
11
1,005
5 Feb 2025
The Newest Addition to #NSD2025
🔏| Kentrelle White
🏟️| Sanford, NC
🎓| Lee County HS
🏈| Offensive Line
📲| @kdub54439761
#NOROPE
16
28
6,892
5 Feb 2025
The Newest Addition to #NSD2025
🔏| Tyquawn Murphy
🏟️| Lugoff, SC
🎓| Lugoff Elgin HS
🏈| Defensive Back
📲| @MurphyTyquawn2
#NOROPE
16
29
7,100
5 Feb 2025
The Newest Addition to #NSD2025
🔏| Marc-Sanchtz Lordeus
🏟️| Boca Raton, FL
🎓| West Boca HS
🏈| Linebacker
📲| @MarcLordeus
#NOROPE
1
17
34
11,441
5 Feb 2025
The Newest Addition to #NSD2025
🔏| Kaleb Staton
🏟️| Rocky Mount, NC
🎓| Northern Nash HS
🏈| Defensive Back
📲| @kalebstaton5
#NOROPE
14
21
6,717