
Day 1,606 of consistency,
More training videos made for my team, got started on my report. Both are very important tasks I’m trying get done asap.
Had to re-eval NYResolution daily action goals, trying to prioritize most important task of each day.
Thinking bigger
2
1
6
2,512

Jan 1
Энэ жил гэрийн номинациудаас ер нь хасагдсан байна лээ. Урд жилүүдэд хоолны төрөлд ер нь цом алдаж үзээгүй, энэ жил идсэнийг л тооцохгүй юм бол өөрөөр алга алга.
2026 ондоо цомоо эргүүлэн авахын тулд цөөн боловч чанартай хэдэн инновацилаг “давшилт” хийнэ ээ.
#NYResolution

1
1
19
1,802

31 Dec 2025
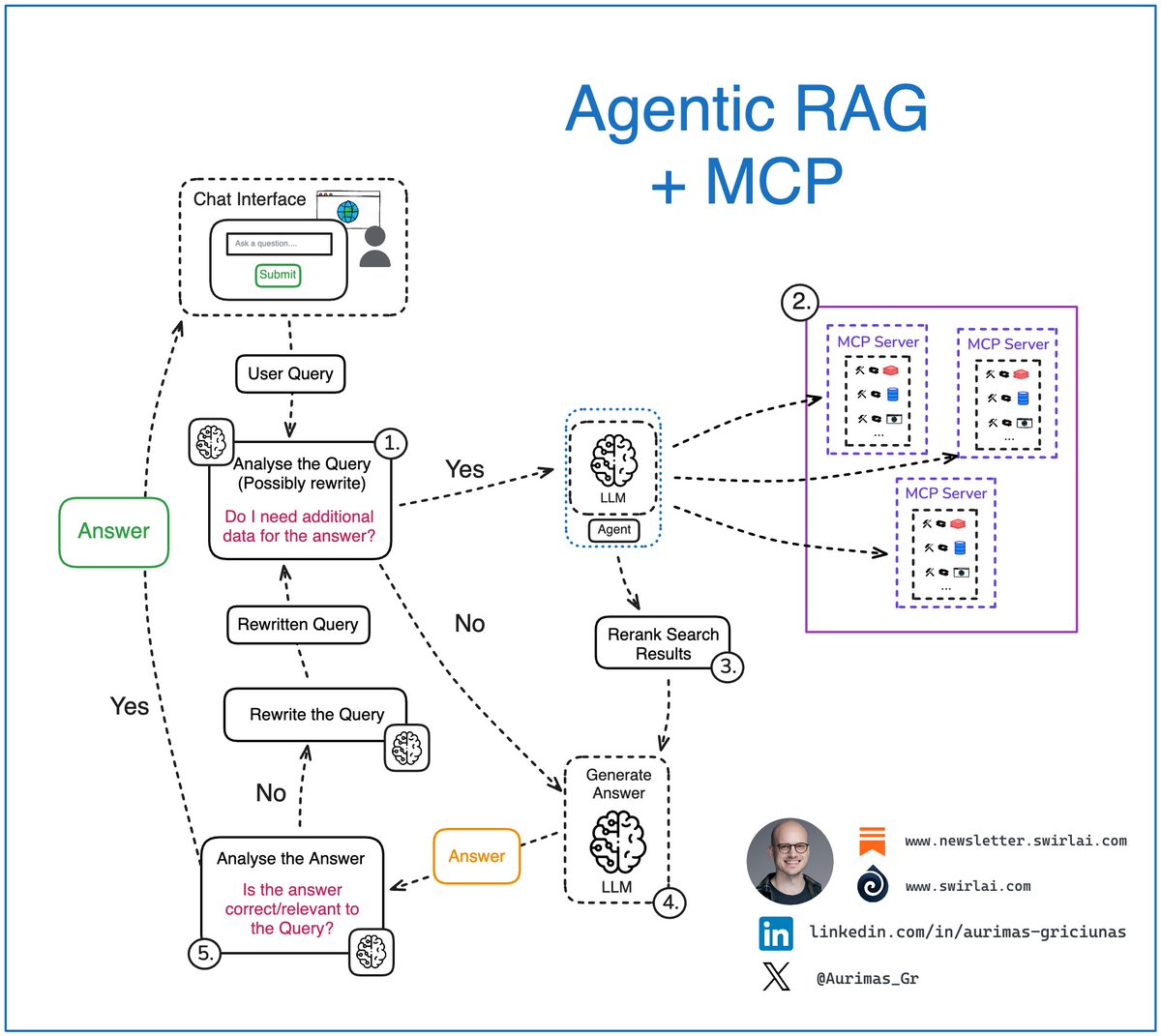
Integrating 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗥𝗔𝗚 Systems via 𝗠𝗖𝗣 👇
If you are building RAG systems and packing many data sources for retrieval, most likely there is some agency present at least at the data source selection for retrieval stage.
This is how MCP enriches the evolution of your Agentic RAG systems in such case (𝘱𝘰𝘪𝘯𝘵 2.):
𝟭. Analysis of the user query: we pass the original user query to a LLM based Agent for analysis. This is where:
➡️ The original query can be rewritten, sometimes multiple times to create either a single or multiple queries to be passed down the pipeline.
➡️ The agent decides if additional data sources are required to answer the query.
𝟮. If additional data is required, the Retrieval step is triggered. We could tap into variety of data types, few examples:
➡️ Real time user data.
➡️ Internal documents that a user might be interested in.
➡️ Data available on the web.
➡️ …
𝗧𝗵𝗶𝘀 𝗶𝘀 𝘄𝗵𝗲𝗿𝗲 𝗠𝗖𝗣 𝗰𝗼𝗺𝗲𝘀 𝗶𝗻:
✅ Each data domain can manage their own MCP Servers. Exposing specific rules of how the data should be used.
✅ Security and compliance can be ensured on the Servel level for each domain.
✅ New data domains can be easily added to the MCP server pool in a standardised way with no Agent rewrite needed enabling decoupled evolution of the system in terms of 𝗣𝗿𝗼𝗰𝗲𝗱𝘂𝗿𝗮𝗹, 𝗘𝗽𝗶𝘀𝗼𝗱𝗶𝗰 𝗮𝗻𝗱 𝗦𝗲𝗺𝗮𝗻𝘁𝗶𝗰 𝗠𝗲𝗺𝗼𝗿𝘆.
✅ Platform builders can expose their data in a standardised way to external consumers. Enabling easy access to data on the web.
✅ AI Engineers can continue to focus on the topology of the Agent.
𝟯. Retrieved data is consolidated and Reranked by a more powerful model compared to regular embedder. Data points are significantly narrowed down.
𝟰. If there is no need for additional data, we try to compose the answer (or multiple answers or a set of actions) straight via an LLM.
𝟱. The answer gets analyzed, summarized and evaluated for correctness and relevance:
➡️ If the Agent decides that the answer is good enough, it gets returned to the user.
➡️ If the Agent decides that the answer needs improvement, we try to rewrite the user query and repeat the generation loop.
Learn how to handle Agentic RAG system with data sources via MCP hands-on in my End-to-end AI Engineering Bootcamp. Next cohort kicking off on January 12th: maven.com/swirl-ai/end-to-en…
🎁 Code NYRESOLUTION for 10% off.
Are you using MCP in your Agentic RAG systems? Let me know about your experience in the comment section 👇
18
99
568
27,694
30 Dec 2025
Learn how to make your RAG system production ready hands-on in my End-to-end AI Engineering Bootcamp. Next cohort kicking off on January 12th: maven.com/swirl-ai/end-to-en…
🎁 Code NYRESOLUTION for 10% off.
1
7
887
30 Dec 2025
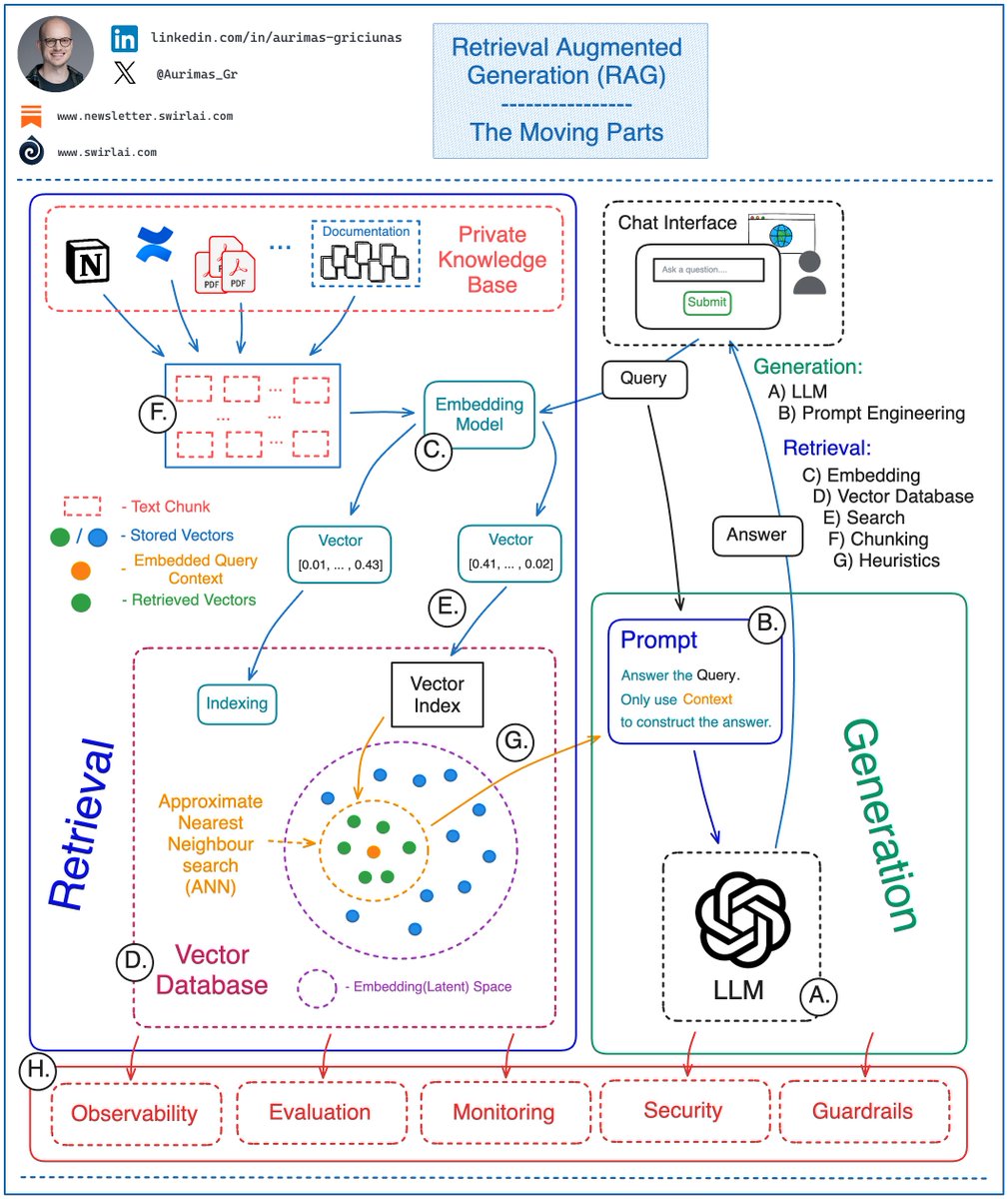
Don't get fooled, building a 𝗽𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻 𝗴𝗿𝗮𝗱𝗲 𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹 𝗔𝘂𝗴𝗺𝗲𝗻𝘁𝗲𝗱 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻 (𝗥𝗔𝗚) 𝗯𝗮𝘀𝗲𝗱 𝗔𝗜 𝘀𝘆𝘀𝘁𝗲𝗺 is a challenging task. Read until the end to understand why 👇
Here are some of the moving parts in the RAG based systems that you will need to take care of and continuously tune in order to achieve desired results:
𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹:
𝘍 ) Chunking - how do you chunk the data that you will use for external context.
- Small, Large chunks.
- Sliding or tumbling window for chunking.
- Retrieve parent or linked chunks when searching or just use originally retrieved data.
𝘊 ) Choosing the embedding model to embed and query and external context to/from the latent space. Considering Contextual embeddings.
𝘋 ) Vector Database.
- Which Database to choose.
- Where to host.
- What metadata to store together with embeddings.
- Indexing strategy.
𝘌 ) Vector Search
- Choice of similarity measure.
- Choosing the query path - metadata first vs. ANN first.
- Hybrid search.
𝘎 ) Heuristics - business rules applied to your retrieval procedure.
- Time importance.
- Reranking.
- Duplicate context (diversity ranking).
- Source retrieval.
- Conditional document preprocessing.
𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻:
𝘈 ) LLM - Choosing the right Large Language Model to power your application.
✅ It is becoming less of a headache the further we are into the LLM craze. The performance of available LLMs are converging, both open source and proprietary. The main choice nowadays is around using a proprietary model or self-hosting.
𝘉 ) Prompt Engineering - having context available for usage in your prompts does not free you from the hard work of engineering the prompts. You will still need to align the system to produce outputs that you desire and prevent jailbreak scenarios.
And let’s not forget the less popular part:
𝘏) Observing, Evaluating, Monitoring and Securing your application in production!
Learn how to make your RAG system production ready hands-on in my End-to-end AI Engineering Bootcamp. Next cohort kicking off on January 12th: maven.com/swirl-ai/end-to-en…
🎁 Code NYRESOLUTION for 10% off.
What other pieces of the system am I missing? Let me know in the comments 👇
15
46
178
9,889
29 Dec 2025
Learn how to implement tracing hands-on in my End-to-end AI Engineering Bootcamp. Next cohort kicking off on January 12th: maven.com/swirl-ai/end-to-en…
🎁 Code NYRESOLUTION for 10% off.
5
1,147
29 Dec 2025
𝗔𝗜 𝗢𝗯𝘀𝗲𝗿𝘃𝗮𝗯𝗶𝗹𝗶𝘁𝘆 is a must have in your tool belt as an AI Engineer. 𝗧𝗿𝗮𝗰𝗶𝗻𝗴 sits at the core of it, why is it important?
Tracing and instrumentation of software have been around for decades now. With AI systems resembling regular software even more, we are now moving the practice here as well (with a few key differences).
Let’s look into the process of tracing from a perspective of a naive RAG system.
𝘍𝘦𝘸 𝘥𝘦𝘧𝘪𝘯𝘪𝘵𝘪𝘰𝘯𝘴:
𝘼) An Orchestrator in the GenAI system application is the central piece of software that orchestrates the end-to-end process. Think of apps using LangChain, LlamaIndex or Haystack.
𝘽) Trace is the end-to-end application flow from the entry point till the answer is produced, it is composed of smaller pieces called spans.
𝘾) Span is a smaller piece of the application flow that represents an atomic action like a function call or a database query. They can be sequential, or run in parallel.
ℹ️ As part of span we capture general metadata like start and end time, inputs and outputs of the span. On top of this metadata we track information specific to the GenAI system elements.
What might a trace look like for a naive RAG system?
𝟭. A query that has been submitted to the chat application.
𝟮. The query is embedded into a vector.
✅ Additional metadata like input token count is persisted with the span so that we can estimate the cost of the procedure.
𝟯. ANN lookup performed against the Vector DB to retrieve the most relevant context.
✅ Additional metadata about the query is persisted as part of the span together with the retrieved pieces of context and their relevance.
𝟰. A prompt is constructed from the system prompt and retrieved context.
𝟱. The prompt is passed to the LLM to construct the answer.
✅ Additional metadata about input and output token count is captured together with the span so that we can estimate the cost of the procedure.
𝘞𝘩𝘺 𝘪𝘴 𝘵𝘳𝘢𝘤𝘪𝘯𝘨 𝘰𝘧 𝘎𝘦𝘯𝘈𝘐 𝘴𝘺𝘴𝘵𝘦𝘮𝘴 𝘪𝘮𝘱𝘰𝘳𝘵𝘢𝘯𝘵?
- These applications are usually complex chains, errors can happen in different steps of your application. E.g. Embedding of query is taking longer than expected or you have reached API limits of LLM provider.
- Cost for calling LLM APIs will be variable depending on the length of inputs and produced outputs. You would usually trace this information and analyze it to help forecast expenses.
- GenAI systems are non-deterministic and will deteriorate over time. They need to be evaluated on span level rather than input/output of the entire system so that you can tune each piece separately.
- …
Learn how to implement tracing hands-on in my End-to-end AI Engineering Bootcamp. Next cohort kicking off on January 12th: maven.com/swirl-ai/end-to-en…
🎁 Code NYRESOLUTION for 10% off.
Are you tracing your Agents? Let me know in the comments 👇

10
39
239
13,168

22 Dec 2025
Learn how to leverage these patterns hands-on in my End-to-end AI Engineering Bootcamp. Next cohort kicking off on January 12th: maven.com/swirl-ai/end-to-en…
🎁 Code NYRESOLUTION for 10% off.
1
14
1,684
22 Dec 2025
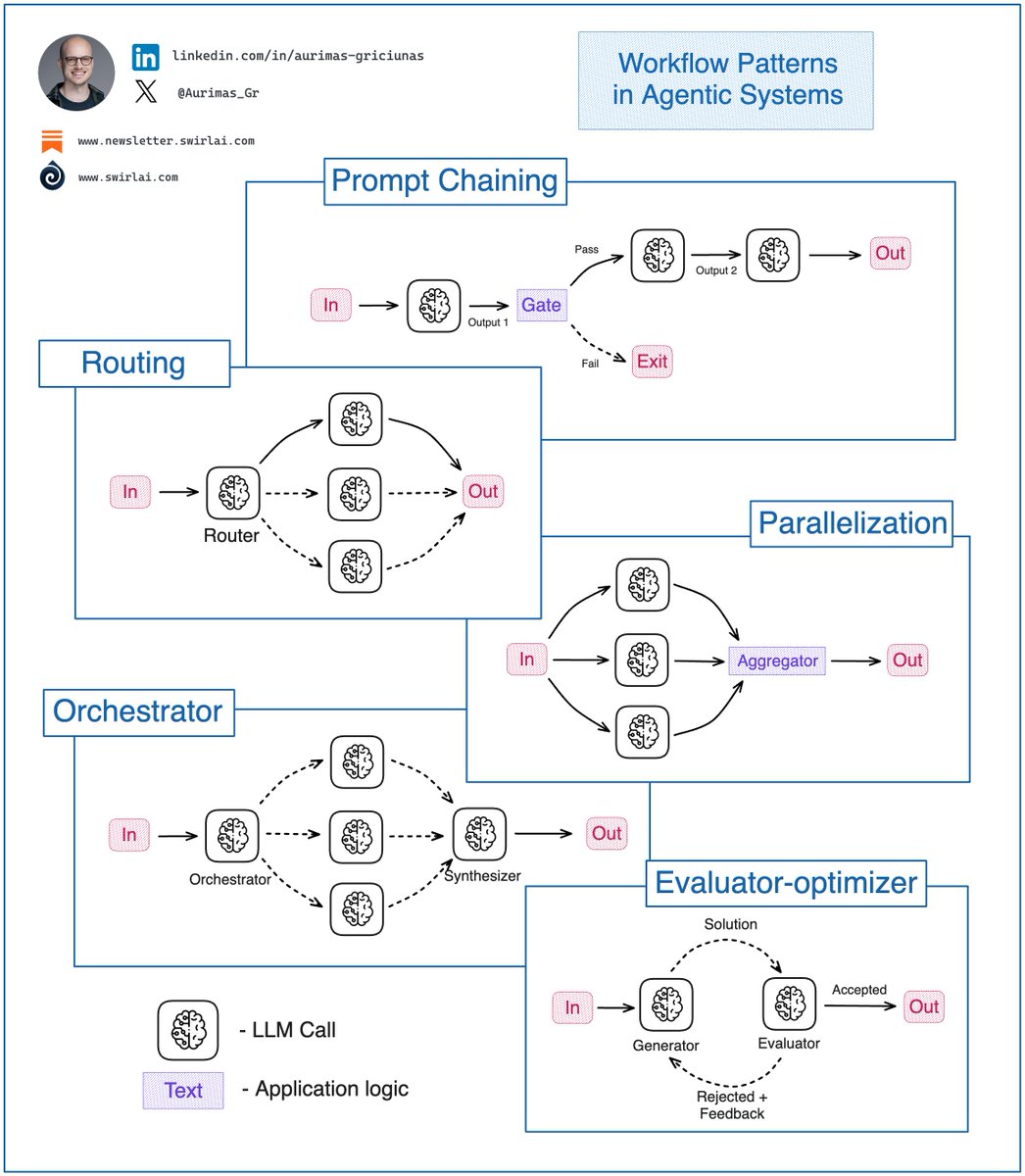
You must know these 𝗔𝗴𝗲𝗻𝘁𝗶𝗰 𝗦𝘆𝘀𝘁𝗲𝗺 𝗪𝗼𝗿𝗸𝗳𝗹𝗼𝘄 𝗣𝗮𝘁𝘁𝗲𝗿𝗻𝘀 as an 𝗔𝗜 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿.
If you are building Agentic Systems in an Enterprise setting you will soon discover that the simplest workflow patterns work the best and bring the most business value.
At the end of last year Anthropic did a great job summarising the top patterns for these workflows and they still hold strong.
Let’s explore what they are and where each can be useful:
𝟭. 𝗣𝗿𝗼𝗺𝗽𝘁 𝗖𝗵𝗮𝗶𝗻𝗶𝗻𝗴: This pattern decomposes a complex task and tries to solve it in manageable pieces by chaining them together. Output of one LLM call becomes an input to another.
✅ In most cases such decomposition results in higher accuracy with sacrifice for latency.
ℹ️ In heavy production use cases Prompt Chaining would be combined with following patterns, a pattern replace an LLM Call node in Prompt Chaining pattern.
𝟮. 𝗥𝗼𝘂𝘁𝗶𝗻𝗴: In this pattern, the input is classified into multiple potential paths and the appropriate is taken.
✅ Useful when the workflow is complex and specific topology paths could be more efficiently solved by a specialized workflow.
ℹ️ Example: Agentic Chatbot - should I answer the question with RAG or should I perform some actions that a user has prompted for?
𝟯. 𝗣𝗮𝗿𝗮𝗹𝗹𝗲𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻: Initial input is split into multiple queries to be passed to the LLM, then the answers are aggregated to produce the final answer.
✅ Useful when speed is important and multiple inputs can be processed in parallel without needing to wait for other outputs. Also, when additional accuracy is required.
ℹ️ Example 1: Query rewrite in Agentic RAG to produce multiple different queries for majority voting. Improves accuracy.
ℹ️ Example 2: Multiple items are extracted from an invoice, all of them can be processed further in parallel for better speed.
𝟰. 𝗢𝗿𝗰𝗵𝗲𝘀𝘁𝗿𝗮𝘁𝗼𝗿: An orchestrator LLM dynamically breaks down tasks and delegates to other LLMs or sub-workflows.
✅ Useful when the system is complex and there is no clear hardcoded topology path to achieve the final result.
ℹ️ Example: Choice of datasets to be used in Agentic RAG.
𝟱. 𝗘𝘃𝗮𝗹𝘂𝗮𝘁𝗼𝗿-𝗼𝗽𝘁𝗶𝗺𝗶𝘇𝗲𝗿: Generator LLM produces a result then Evaluator LLM evaluates it and provides feedback for further improvement if necessary.
✅ Useful for tasks that require continuous refinement.
ℹ️ Example: Deep Research Agent workflow when refinement of a report paragraph via continuous web search is required.
𝗧𝗶𝗽𝘀:
❗️ Before going for full fledged Agents you should always try to solve a problem with simpler Workflows described in the article.
Learn how to leverage these patterns hands-on in my End-to-end AI Engineering Bootcamp. Next cohort kicking off on January 12th: maven.com/swirl-ai/end-to-en…
🎁 Code NYRESOLUTION for 10% off.
What are the most complex workflows you have deployed to production? Let me know in the comments 👇
26
141
822
42,261
19 Dec 2025
Learn how to work with ReAct pattern hands-on in my End-to-end AI Engineering Bootcamp. Next cohort kicking off on January 12th: maven.com/swirl-ai/end-to-en…
🎁 Code NYRESOLUTION for 10% off.
1
1
5
1,105
19 Dec 2025
What is 𝗥𝗲𝗔𝗰𝘁 𝗔𝗴𝗲𝗻𝘁 pattern?
As with most of the Agentic System Design patterns, it is all about flow engineering - how you construct the initial prompt and how you route your system according to the outputs produced by the LLM.
ReAct stands for Reasoning and Action. This means that the Agent is prompted to do both, reason about the actions it should take next and is provided the tools that it can use to act on the plan in the real world. After the actions are taken, they are used to reason about the next steps.
The implementations can vary, but on a high level you will see:
𝟭. The initial prompt is very important and is something that you would spend time tuning, on a high level:
➡️ You ask the LLM to solve the provided user query.
➡️ Provide the Agent with the list of tools it can use.
➡️ Ask it to print out the Reasoning and results of the Actions taken while performing a step.
➡️ Provide a list of actions and produced results so far - you start with an empty list.
➡️ You prompt the agent to take no more than N reasoning loops.
𝟮. This is an optional step where you can analyse the reasoning, you either check if the User Query was solved already or you can do that in the initial prompt. Here is also where you can break out of the loop if exceeding max steps.
𝟯. Reasoning output will have the next tool to be used. You execute the tool call and get the results.
𝟰. Combine the reasoning and tool call result, update the Reasoning and Action history with the data and run the updated prompt through the LLM again.
𝟱. Repeat until either the User Query is answered or N steps are reached.
ℹ️ Similar types of architectures are used to implement fully autonomous agents and agentic systems. The goal is to go beyond just CoT reasoning and allow the agent to reason continuously on actions it is taking in the real world.
❗️ Be sure to limit the amount of tools you give to your ReAct Agents. To many and your agent will get confused (try to stay bellow 10, less than 5 is even better). If you have many tools, start splitting your Agentic system into multiple Agents/Tasks.
✅ From my experience, this pattern works well as part of a larger Agentic System but is limited standalone.
Learn how to work with ReAct pattern hands-on in my End-to-end AI Engineering Bootcamp. Next cohort kicking off on January 12th: maven.com/swirl-ai/end-to-en…
🎁 Code NYRESOLUTION for 10% off.
Have you tried implementing the ReAct agent pattern in your applications? What were your main observations? Let’s discuss in the comment section 👇

15
80
360
18,436
18 Dec 2025
We keep trying to teach AI by adding more tools. The real gap is how we think about systems.
When I was thinking about End to End AI Engineering Bootcamp, I wanted it to be fundamental. Not a tour of tools or frameworks. But the way of thinking about AI system development, from problem framing to production.
This bootcamp isn’t about the hype, it’s about focus. It’s about full-cycle engineering, not simplified demos that don’t work outside notebooks. It’s about building confidence ‘I can do this’.
The second cohort has just closed, and reading the feedback reminded me why I care so much about my work. It reflects exactly the principles the course was built on: sequencing over shortcuts, engineering judgment over recipes, and responsibility for how systems behave in the real world.
What makes this especially rewarding is watching the transformation. Students arrive with ideas and they leave with working AI systems.
I have been incredibly lucky with my students. Teaching them was a joy. Seeing their progress is both my motivation and the standard I hold the course to as it continues to evolve.
Join me in the next cohort which is kicking off on January 12th: maven.com/swirl-ai/end-to-en…
🎁 Use Code NYRESOLUTION at check out for 10% off.
1
2
26
3,392
17 Dec 2025
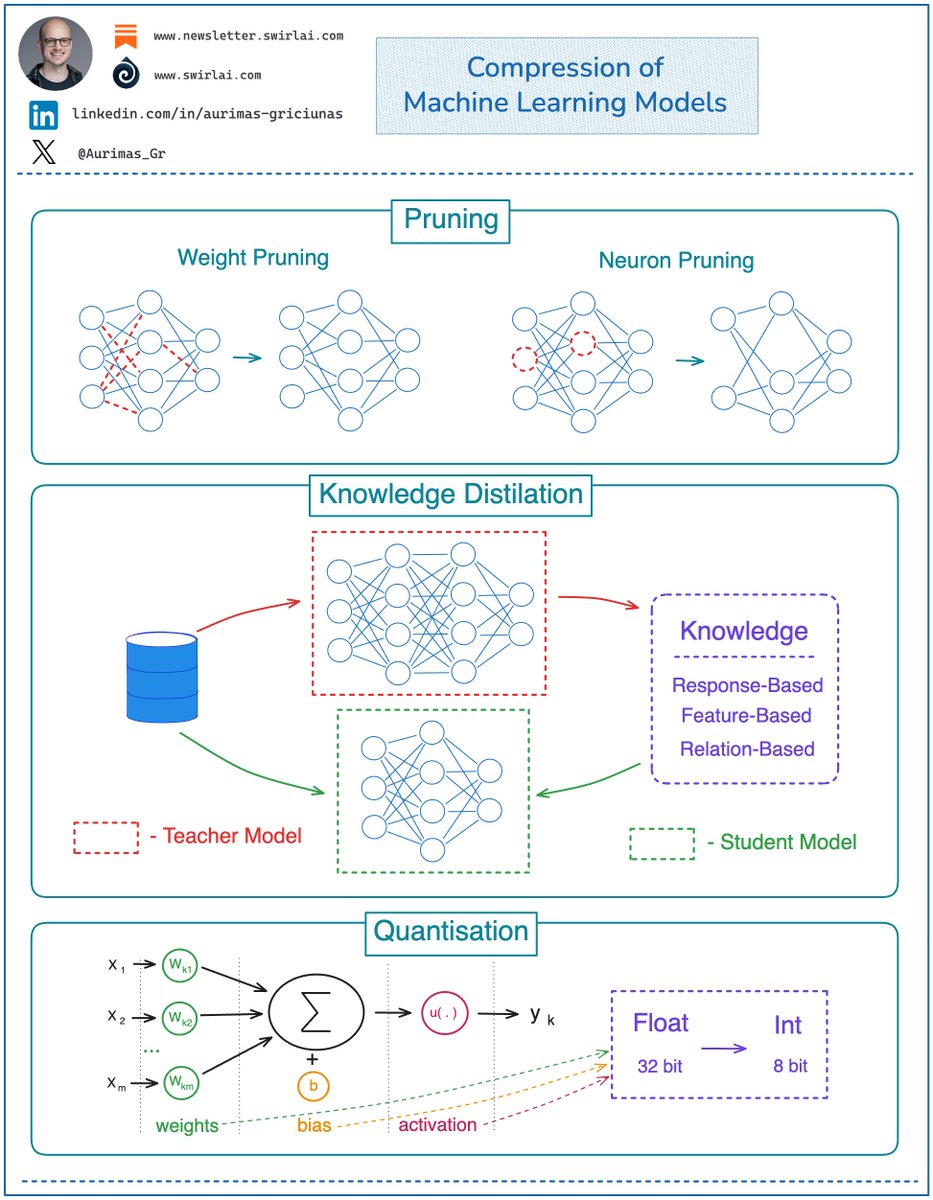
Understanding and being able to apply 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗟𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗺𝗼𝗱𝗲𝗹 𝗖𝗼𝗺𝗽𝗿𝗲𝘀𝘀𝗶𝗼𝗻 will distinguish you as a standout 𝗔𝗜 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿. Here is why 👇
Small Language Models will be the cornerstone of modern Agentic Systems. When you deploy ML models to production you need to take into account several operational metrics that are in general not ML related:
👉 𝗜𝗻𝗳𝗲𝗿𝗲𝗻𝗰𝗲 𝗟𝗮𝘁𝗲𝗻𝗰𝘆: How long does it take for your Model to compute inference result and return it.
👉 𝗠𝗼𝗱𝗲𝗹 𝗦𝗶𝘇𝗲: How much memory does your model occupy when it’s loaded for serving inference results.
Both of these are important when considering operational performance and feasibility of your model deployment.
👉 Large models might not fit on a device if you are considering edge deployments.
👉 Latency of retrieving inference results might make business case non feasible. E.g. Recommendation Engines require latencies in milliseconds as ranking has to be applied as the user browses your website or app in real time. Bad news for LLM fans!
👉 …
You can influence both latency and size by applying different Model Compression methods, some of them are:
➡️ 𝗣𝗿𝘂𝗻𝗶𝗻𝗴: this method is mostly used in tree-based and Neural Network algorithms. In tree-based ones we prune leaves or branches from decision trees. In Neural Networks we remove nodes and synapses (weights) while trying to retain ML performance metrics.
✅ In both cases the output is a reduction in the number of Model Parameters and model size.
➡️ 𝗞𝗻𝗼𝘄𝗹𝗲𝗱𝗴𝗲 𝗗𝗶𝘀𝘁𝗶𝗹𝗹𝗮𝘁𝗶𝗼𝗻: this type of compression is achieved by:
👉 Training an original large model which is called the Teacher model.
👉 Training a smaller model to mimic the Teacher model by transferring knowledge from it, this model is called the Student model. Knowledge in this context can be extracted from the outputs, internal hidden state (feature representations) or a combination of both.
👉 We then use the “Student” model in production.
➡️ 𝗤𝘂𝗮𝗻𝘁𝗶𝘇𝗮𝘁𝗶𝗼𝗻: a most commonly used method that doesn’t have much to do with Machine Learning. This approach uses fewer bits to represent model parameters.
👉 You can apply quantization techniques both during the training and after the models has been already trained.
👉 In regular Neural Networks what is quantized are Model Weights, Biases and Activation Functions.
👉 Most usual quantization is from float to integer (32 bits to 8 bits. There are talks about 1 bit LLMs nowadays 😅).
➡️ …
❗️ While the above methods do reduce the size of the models, allowing them to be deployed in production scenarios, there is almost always a reduction in accuracy so be careful and evaluate it accordingly.
What methods for reducing model size have you used? What were the main challenges? Let me know in the comment section!
Join me in my End-to-end AI Engineering Bootcamp. Next cohort kicking off on January 12th: maven.com/swirl-ai/end-to-en…
🎁 Code NYRESOLUTION for 10% off.
#LLM #AI #MachineLearning
4
3
20
1,317
16 Dec 2025
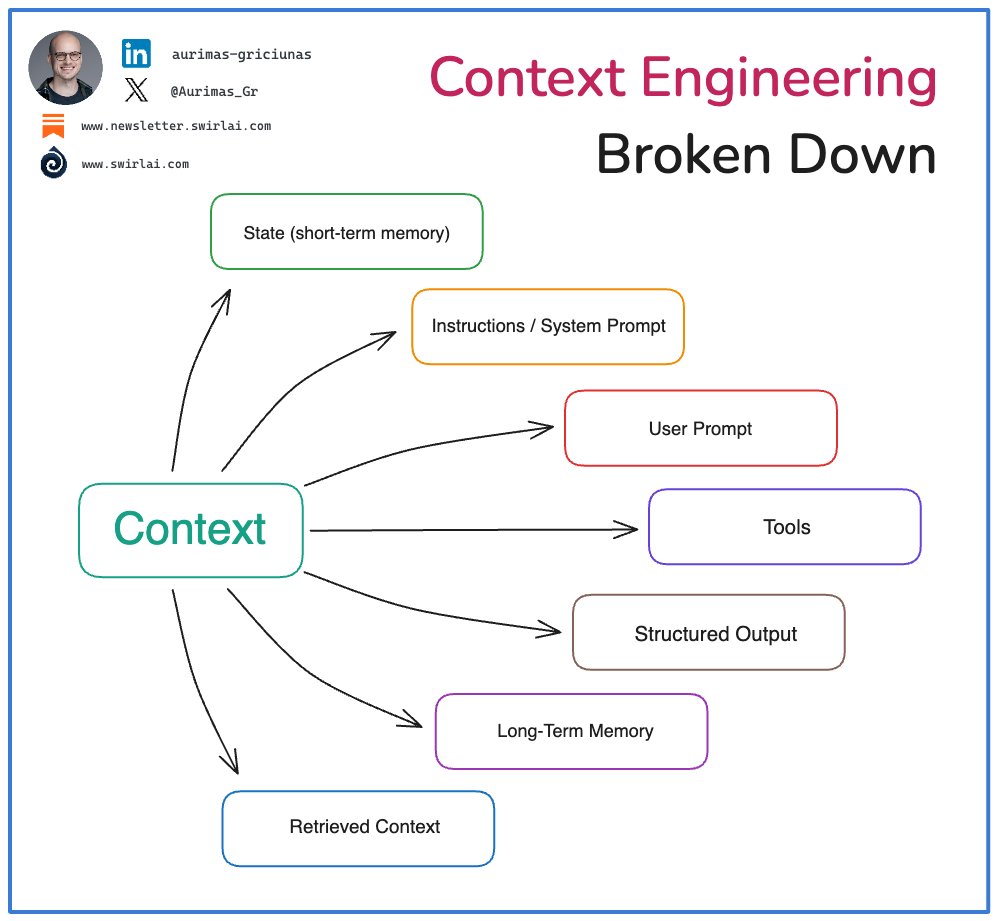
Still figuring out what 𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 is about? 👇
Few weeks ago I wrote down my thoughts and experiences about the practice in one of my Newsletter episodes.
In general, Context provided to LLMs in Agentic Systems can be split into the following categories:
- Instructions / System Prompt.
- User Prompt.
- Retrieved Context.
- Short-Term Memory.
- Long-Term Memory.
- Structured Outputs.
- Tools.
Each of the categories has its own set of challenges when building Agentic Systems. I’ve delved deeper into each, applying the lessons from building in the trenches.
Check the article out here: newsletter.swirlai.com/p/bre…
Any war stories to share when it comes to Context Engineering? Drop them in the comment section! 👇
Learn these techniques hands-on in my End-to-end AI Engineering Bootcamp. Next cohort kicking off on January 12th: maven.com/swirl-ai/end-to-en…
🎁 Use code NYRESOLUTION at checkout for 10% off.
20
39
275
14,091
12 Dec 2025
Learn how to build such systems hands-on in my End-to-end AI Engineering Bootcamp, next cohort kicking off on January 12th: maven.com/swirl-ai/end-to-en…
🎁 Use code NYRESOLUTION at checkout for 10% off.
2
760
12 Dec 2025
𝗠𝗖𝗣 plus 𝗔𝟮𝗔, here is how they complement each other 👇
Protocol wars continue to rage, let's understand how Googles A2A (Agent2Agent) protocol is different from MCP and how they complement each other (read till the end).
𝘔𝘰𝘷𝘪𝘯𝘨 𝘱𝘪𝘦𝘤𝘦𝘴 𝘪𝘯 𝘔𝘊𝘗:
𝟭. MCP Host - Programs using LLMs at the core that want to access data through MCP.
❗️ When combined with A2A, an Agent becomes MCP Host.
𝟮. MCP Client - Clients that maintain 1:1 connections with servers.
𝟯. MCP Server - Lightweight programs that each expose specific capabilities through the standardised Model Context Protocol.
𝟰. Local Data Sources - Your computer’s files, databases, and services that MCP servers can securely access.
𝟱. Remote Data Sources - External systems available over the internet (e.g., through APIs) that MCP servers can connect to.
𝘌𝘯𝘵𝘦𝘳 𝘈2𝘈:
Where MCP falls short, A2A tries to help. In multi-Agent applications where state is not necessarily shared
𝟲. Agents (MCP Hosts) would implement and communicate via A2A protocol, that enables:
➡️ Secure Collaboration.
➡️ Task and State Management.
➡️ User Experience Negotiation.
➡️ Capability discovery - similar to MCP tools.
𝗛𝗼𝗻𝗲𝘀𝘁 𝘁𝗵𝗼𝘂𝗴𝗵𝘁𝘀:
❗️ Open protocols for Agent communication are important but they are just a piece of the picture, there will be a need for standards that govern all of the existing protocols and other missing pieces. E.g.
❓ How do we standardise tracing and Observability in multi-agent IOA systems?
❓ How do we retain the identity of the running job of an AI Agent instance if the communication standard is not unified in different parts of the pipeline?
❓ ...
✅ More on this in my future posts, stay tuned!
Let me know your thoughts in the comments. 👇
Learn how to build such systems hands-on in my End-to-end AI Engineering Bootcamp, next cohort kicking off on January 12th: maven.com/swirl-ai/end-to-en…
🎁 Use code NYRESOLUTION at checkout for 10% off.
#LLM #AI #MachineLearning

14
74
431
18,580
11 Dec 2025
Less talking, more building: 𝗠𝘂𝗹𝘁𝗶-𝗔𝗴𝗲𝗻𝘁 𝗥𝗲𝘀𝗲𝗮𝗿𝗰𝗵 𝗦𝘆𝘀𝘁𝗲𝗺 𝗳𝗿𝗼𝗺 𝘀𝗰𝗿𝗮𝘁𝗰𝗵! 👇
Some weeks ago I released an episode of my Newsletter and an update to the 𝗔𝗜 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝘀 𝗛𝗮𝗻𝗱𝗯𝗼𝗼𝗸 GitHub repository.
There I implemented a Deep Research Agent from scratch without using any LLM Orchestration frameworks (using DeepSeek-R1 for some planning tasks).
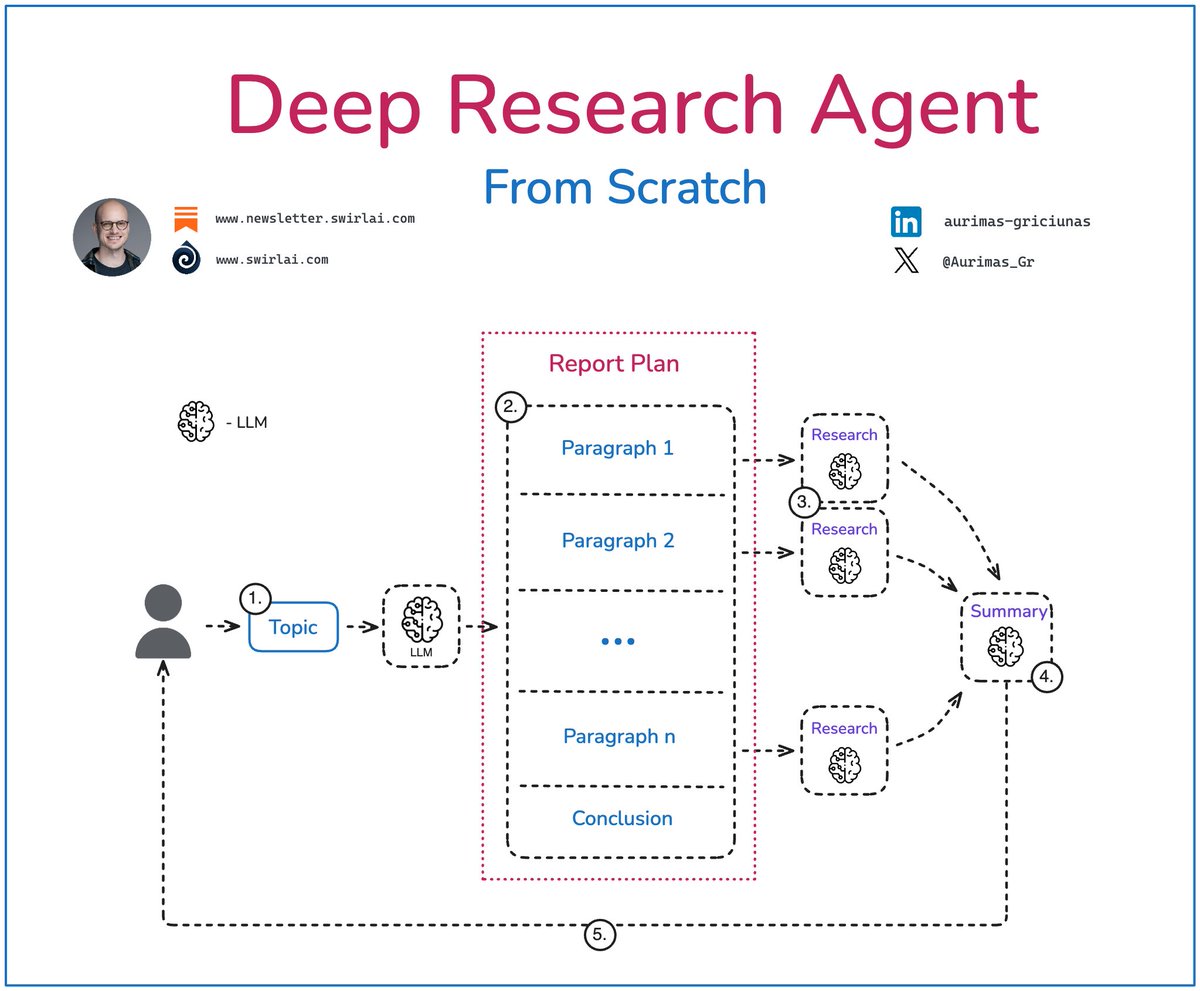
In the project we implement the following Agentic topology:
𝟭. A user provides a query or topic to be researched.
𝟮. A LLM creates an outline of the final report that it will be aiming for. It will be instructed to produce not more than a certain number of paragraphs.
𝟯. Each of the paragraph description is fed into a research process separately to produce a comprehensive set of information to be used in report construction. Detailed description of the research process will be outlined in the next section.
𝟰. All of the information will be fed into a summarisation step that will construct the final report including conclusion.
𝟱. The report will then be delivered to the user in MarkDown form.
Each of the research steps are following given flow:
𝟭. Once we have the outline of each paragraph, it will be passed to a LLM to construct Web Search queries in an attempt to best enrich the information needed.
𝟮. The LLM will output the search query and the reasoning behind it.
𝟯. We will execute Web search against the query and retrieve top relevant results.
𝟰. The results will be passed to the Reflection step where a LLM will reason about any missed nuances to try and come up with a search query that would enrich the initial results.
𝟱. This process will be repeated for n times in an attempt to get the best set of information possible.
Detailed walkthrough Blog Post: newsletter.swirlai.com/p/bui…
GitHub with implementation code and Notebooks to follow: github.com/swirl-ai/ai-angin…
Learn how to build such systems hands-on in my End-to-end AI Engineering Bootcamp, next cohort kicking off on January 12th: maven.com/swirl-ai/end-to-en…
🎁 Use code NYRESOLUTION at checkout for 10% off.
Happy Building!
Be sure to leave a like or star if you find the content useful!
#LLM #AI #MachineLearning
11
57
347
16,115
10 Dec 2025
Learn these infrastructure layers hands-on in my End-to-end AI Engineering Bootcamp, next cohort kicking off on January 12th: maven.com/swirl-ai/end-to-en…
🎁 Use code NYRESOLUTION at checkout for 10% off.
2
4
805
10 Dec 2025
Some 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁𝘀 might seem simple from the outside. They are not 👇
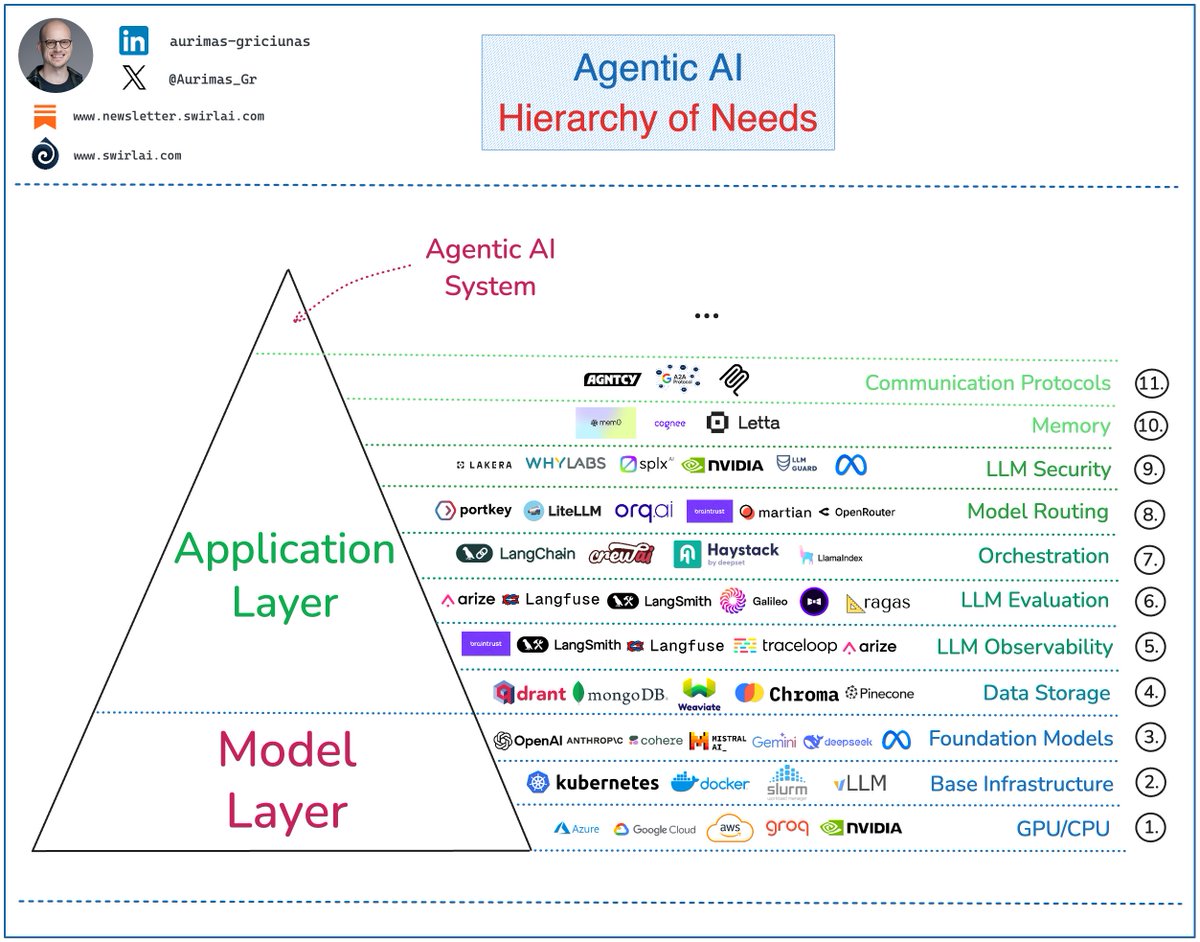
Here are some of the layers that are hidden from you as a user of agentic
We usually start building and experimenting with Raw Model APIs. These rely on complex underlying infrastructure.
𝟭. 𝘎𝘗𝘜/𝘊𝘗𝘜 Resources.
𝟮. 𝘉𝘢𝘴𝘦 𝘐𝘯𝘧𝘳𝘢𝘴𝘵𝘳𝘶𝘤𝘵𝘶𝘳𝘦 that orchestrates Model deployment. Think Kubernetes, Slurm, vLLM.
𝟯. 𝘍𝘰𝘶𝘯𝘥𝘢𝘵𝘪𝘰𝘯 𝘔𝘰𝘥𝘦𝘭𝘴 themselves that required tens of millions of dollars to be trained.
To produce a reliable MVP you will need some internal data and visibility to your system. This will require you to make choices in how you:
𝟰. 𝘚𝘵𝘰𝘳𝘦 the data: Vector DBs, Graph DBs etc.
𝟱. 𝘖𝘣𝘴𝘦𝘳𝘷𝘦 𝘓𝘓𝘔 interactions to see into the actions your system is performing. You will need this for debugging and evolving your Agents.
Scaling up requires more stability and insights into what is happening inside of the system.
𝟲. 𝘌𝘷𝘢𝘭𝘶𝘢𝘵𝘪𝘰𝘯 helps you to go beyond passively observing the system to proactively monitoring it by bringing automation via evaluation rules that are applied against steps performed by your Agents.
𝟳. 𝘖𝘳𝘤𝘩𝘦𝘴𝘵𝘳𝘢𝘵𝘪𝘰𝘯 of the system: LLM Orchestration frameworks help with solving issues like retries, chaining your prompts, tool calling etc.
To expose your application to the general public you would need additional automations and guardrails to prevent disasters that could shut your business in seconds.
𝟴. 𝘔𝘰𝘥𝘦𝘭 𝘙𝘰𝘶𝘵𝘪𝘯𝘨 helps in choosing best LLMs for your prompts, prompt management, fallback mechanisms in case of unresponsive LLM APIs or hitting API limits. Etc.
𝟵. 𝘚𝘦𝘤𝘶𝘳𝘪𝘵𝘺 is critical to avoid disasters related to data leakage. Think Guardrails, Red Teaming etc.
❗️And these are just basic requirements, there is more 🙂
Come in the emerging requirements:
𝟭𝟬. Memory.
𝟭𝟭. Agent Communication Protocols.
...
Anything I am missing? Let me know in the comments 👇
Learn these infrastructure layers hands-on in my End-to-end AI Engineering Bootcamp, next cohort kicking off on January 12th: maven.com/swirl-ai/end-to-en…
🎁 Use code NYRESOLUTION at checkout for 10% off.
#LLM #AI #MachineLearning
15
54
262
13,639