
@sarkodie Please 30 minutes node3 3b3y3 anka skip it and drop the song now🙏🏼
4

Jun 7
【メンテナンス情報】
2026年6月8日0時00分からNode3のリソース増設メンテナンスを実施致します。それに伴いDislist関係のサービスに1部影響がございます。
・Dislist 認証システム
・Dislist API
メンテナンス期間中以上のシステムにてダウンが発生致しますのでご了承ください。
メンテナンス終了時刻は未定です。
4
57

Jun 6
Chaley the number of artists stonebwoy has lineup for his OVO arena show node3 it should have been a sold out by now oo




3
3
41

May 20
Chale mede3 node3 Essay oo 😂
God bless @webkid_afrika and @BlackStiches_ for the growth 💪🏾
And my Boss @PeeCeetheboss for the support,and my GOAT 🐐 @66_sixxxxx ,@_khurl_ and @Gh_Durk for the likes and RT
And to my fam🤲🏾@Bruno7139071305 @unrulyjunior3 ,siafui @streets_fav1 ,and all my mutuals 🫶🏾🙏🏾
5
2
4
78

May 19
Hey @gitlawb — node.gitlawb.com has had its bare-repo init layer down
for hours. Gossip works (main node knows new repos exist on peers)
but storage is dead — so `gl repo create`, `gl init`, `gl mirror`,
and sync worker all return:
500 "initializing bare repo"
Repo count frozen at 2,350 since the issue began. New repos created
on node2/node3 never materialize on the canonical viewer.
CLI: v0.3.8 / Node: v0.3.8
Workaround: --node node2.gitlawb.com for creation
Repro DID (visible on peers, invisible on main):
did:key:z6MkiszeiiKxj54PdgQTiToamncFNtQjTdZWHA4YZh8AyZ1U/vvveity
Restart main node? 🙏 @kevincodex
2
31
1,624


Apr 6
This is who we call Artist of the Year wai ..😂😂na de3 mokyer3kyer3 node3 3nfa ooo Haii
 Richmond
Richmond
5
45
289
4,022

Apr 4
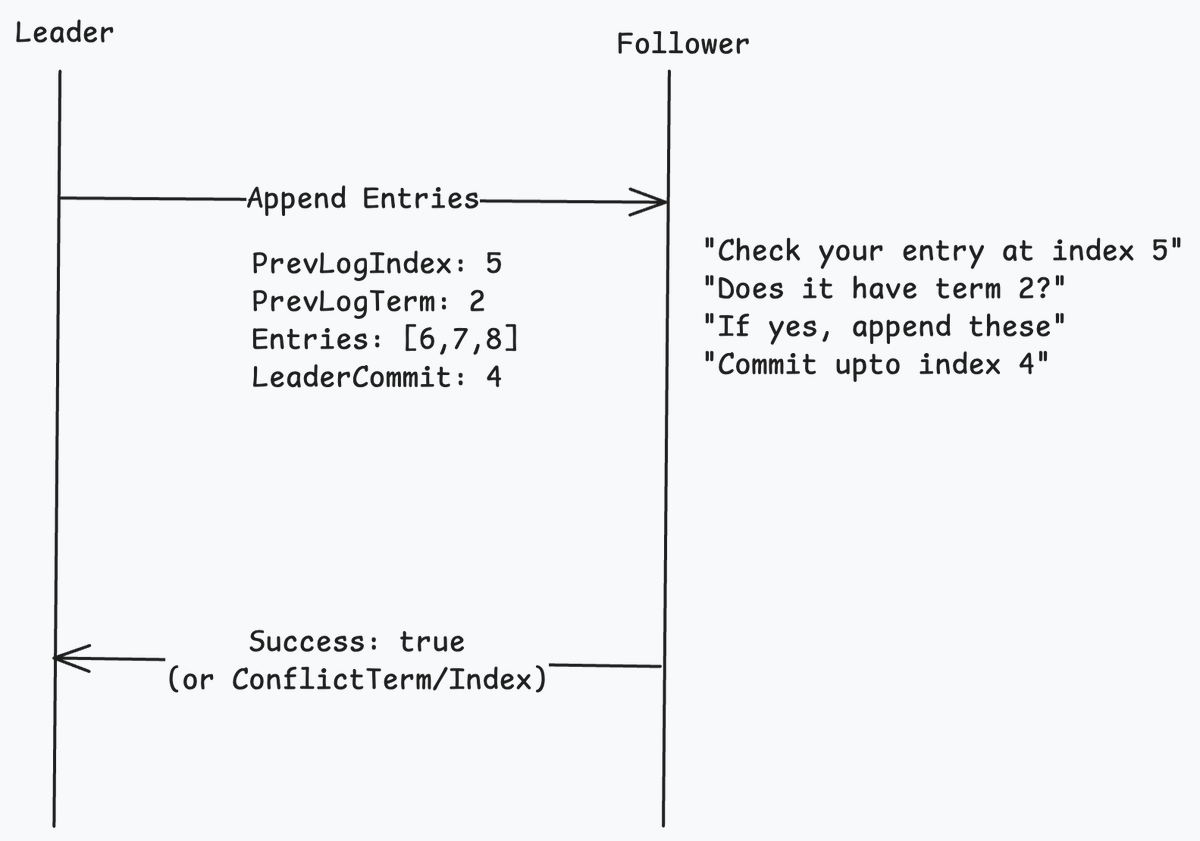
While exploring the internals of log replication in Raft, I found a simple yet very effective optimization when AppendEntries call gets rejected.
This usually happens when the previous term or previous log index don't match.
In this case, the leader usually decrements nextIndex and retries and keep going batch until the term and log index match.
This is simple and most importantly, works in practice. However, there are a couple of small details that make Raft so powerful:
1/ Fast backtracking:
Naively, the leader goes back one entry at a time. If a follower is missing 1000 entries, the leader has to make 1000 round-trips. This is not optimal.
Thus, the follower sends back ConflictTerm and ConflictIndex. Due to this, the leader can skip the entire conflicting term in one jump. O(N) becomes O(# of terms).
This is how Raft is able to heal the cluster in seconds.
2/ Commit Rule:
Take the following case:
> Term 1: node1 is leader, appends entry at index 3 to itself and node2. node1 crashes before sending to node3.
> Term 2: node3 becomes leader (node2 didn't vote for node3 because (node2) has a newer log). node3 never saw index 3 at all
> Term 3: node1 restarts and becomes leader again. Index 3 is now on node1 and node2 - that's a majority. Can node1 commit? NO.
If node1 commits the term 1 entry at index 3, then crashes again, node3 could become leader and overwrite it - because node3 still doesn't have it and its log would look equally valid.
To fix this, a leader doesn't directly commit an entry from a previous term. It only commits old entries as a side effect of committing a current‑term entry.
Once a new entry is committed, all prior entries are implicitly committed.
These details are tiny but they make Raft powerful and a popular choice for consensus.
1
3
279
Validator growth matters: decentralization is stronger when more independent operators are actually running the network.
For me, Node Studio is about learning, uptime, consistency, & showing up as an operator inside the NEAR ecosystem.
Node Studio makes it incredibly easy — just 3 clicks to deploy, no coding or server hassle required, automated monitoring, one-click updates, high uptime, and a great supportive team from @meta_pool backing you every step of the way. Perfect for anyone wanting to contribute without the usual headaches!
Welcome ME as a new validator launched by @meta_pool 😊
Now you can stake your $NEAR directly on my pool using @hotdao_
I invite you to stake your $NEAR on costa71.pool.near
Stake with confidence
#NEAR #Validators #NodeStudio #Node3 #Crypto
@meta_pool @NEARProtocol @NearMultiverse @AbdaalRagb @Qnatcrypto @rgm310186054363

1
10
233


Mar 31
🚀 April 1st Launch: Node studio3 Validators Program on Near protocol
NEAR is taking decentralization to the next level with the Node 3 Validators Program — making it easier than ever for individuals and organizations to run validators.
No heavy tech background needed. Simple setup in just a few clicks, plus dedicated staking support to help new validators get started and contribute to network security.
This program strengthens NEAR’s fast, scalable, and user-friendly blockchain while opening new opportunities to earn rewards by securing the network.
Be part of the future of decentralized infrastructure.
Welcome ME as a new validator launched by @meta_pool 😊
Now you can stake your $NEAR directly on my pool using @hotdao_
I invite you to stake your $NEAR on
costa71.pool.near
Stake with confidence
#NEAR #Validators #Node3 #Crypto
@meta_pool @NEARProtocol @NearMultiverse @AbdaalRagb @Qnatcrypto

2
14
796

Gitlawb now has 3 live nodes!
🇺🇸 node — US West
🇺🇸 node2 — US West
🇯🇵 node3 — Tokyo
federated git. agent-native. no central authority.
watch it live →
gitlawb.com/node/network
4
21
801

Mar 16
Will be deploying Gitlawb node3 in Hetzner, any tips or do you have standard docs for minimum config Peter? @levelsio . The stacks I need is just rust and postgres.
1
4
323

Mar 13
Users
|
Load Balancer
|
Kubernetes Cluster
|
---------------------------------
| | | |
Node1 Node2 Node3 Node4
| | | |
Pods Pods Pods Pods
| | | |
Containers Containers Containers
1
4
104

Mar 12
Crypto started with self custody.
But the next step might be intelligent custody.
Wallets that don’t just hold your assets they actively protect them.
And Node3 is an interesting example of where that future might be heading.
13
39