
🔢 𝗖𝗼𝘂𝗻𝘁 𝗔𝗻𝘆𝘁𝗵𝗶𝗻𝗴: 𝗡𝗲𝘄 𝗔𝗜 𝗠𝗼𝗱𝗲𝗹 𝗖𝗼𝘂𝗻𝘁𝘀 𝗢𝗯𝗷𝗲𝗰𝘁𝘀 𝗳𝗿𝗼𝗺 𝗧𝗲𝘅𝘁 𝗔𝗰𝗿𝗼𝘀𝘀 𝟲 𝗗𝗼𝗺𝗮𝗶𝗻𝘀
Researchers from Tsinghua University released Count Anything, a vision model that counts objects in images based on a text query.
It uses a dual approach: a region-level counter for large sparse objects and a pixel-level counter for small crowded ones. The two outputs are fused into a single point set showing where each counted instance is.
The model covers six domains: general scenes, remote sensing, histopathology, cellular microscopy, agriculture, and microbiology.
They also built CLOC, a 220K-image dataset across 619 categories with 15M object instances to train and benchmark it on.
Count Anything substantially beats existing open-world counting methods across all six domains.
Project page: GitHub
#ComputerVision #ObjectCounting #AIResearch #Tsinghua
───
🤖 𝗙𝗼𝗿 𝗺𝗼𝗿𝗲 𝗔𝗜 𝗻𝗲𝘄𝘀 𝗮𝗻𝗱 𝘀𝘁𝗼𝗿𝘆 𝘀𝗼𝘂𝗿𝗰𝗲𝘀, 𝘀𝗲𝗮𝗿𝗰𝗵 "𝗚𝗲𝗻𝗔𝗜𝗦𝗽𝗼𝘁" 𝗼𝗻 𝗧𝗲𝗹𝗲𝗴𝗿𝗮𝗺

ALT News article image
2

May 27
Count objects accurately with Ultralytics YOLO26! 🔢
Define lines or polygon-based regions and count objects as they move through scenes, ideal for traffic analysis, retail analytics, crowd monitoring, and smart surveillance systems.
Learn more ➡️ bit.ly/43TBF5S
#Ultralytics #ComputerVision #ObjectCounting

1
6
44
2,099
May 19
Count rooftop panels with Ultralytics YOLO26 OBB! 🏠
Use oriented bounding boxes to detect solar panels from aerial views and capture their orientation, enabling accurate counting for inspections, asset management, and infrastructure analytics.
Explore more ➡️ bit.ly/43TBF5S
#Ultralytics #YOLO26 #AI #ObjectCounting #ComputerVision
3
19
163
15,298
Mar 5
Monitor ice rink activity with Ultralytics YOLO26! 🚀
Count people inside the rink in real time and generate a movement heatmap to analyze crowd density, improve safety, and optimize space usage.
Explore more ➡️ bit.ly/43TBF5S
#Ultralytics #YOLO26 #AI #ObjectCounting #ComputerVision
1
2
31
1,584
6 Nov 2025
Count cows in the field in real time with Ultralytics YOLO! 🐄
Define a line or region, track herd movement, and get accurate counts as animals cross your gate. Build smarter agritech monitoring in minutes.
Explore more ➡️ ow.ly/3hyq50Xg2aC
#Agritech #AI #ObjectCounting
10
481
31 Jul 2025
Count boats with precision using Ultralytics OBB models!
This demo uses oriented bounding boxes to detect and count boats from above, ideal for aerial monitoring and marine analytics.
Explore more ➡️ ow.ly/68ox50WaBRM
#ObjectCounting #OBB #ComputerVision
1
4
365

1 May 2025
🚀 New from Groundlight: Object Counting 🔢
We’re excited to announce a major step forward in simplifying computer vision — the launch of our new Counting Mode, for accurate, real-time object counting.
Whether you're counting cars 🏎️ , people 👯, or pallets, our latest feature empowers teams to count the exact things they want to count — no training data or ML expertise required.
This is a game-changer for industries like:
📦 Logistics & Warehousing
🏭 Manufacturing
🚗 Traffic & Parking Analytics
🏬 Retail Operations
And more!
Huge kudos to the Groundlight team for continuing to make computer vision accessible to every developer. Counting mode is available to users on the Business plan - try it out and let us know what you think!
👉 Read the full press release: businesswire.com/news/home/2…
#VisualAI #ComputerVision #ObjectCounting #AIforDevelopers #EdgeAI #GroundlightAI
5
159
30 Apr 2025
Automate capsule counting with Ultralytics YOLO11! 💊
Real-time capsule tracking ensures precise pharmaceutical packaging, quality control, and inventory management using AI-powered object counting.
Explore more ➡️ ow.ly/yLIe50VgciU
#AI #ObjectCounting #PharmaTech
2
22
635
26 Dec 2024
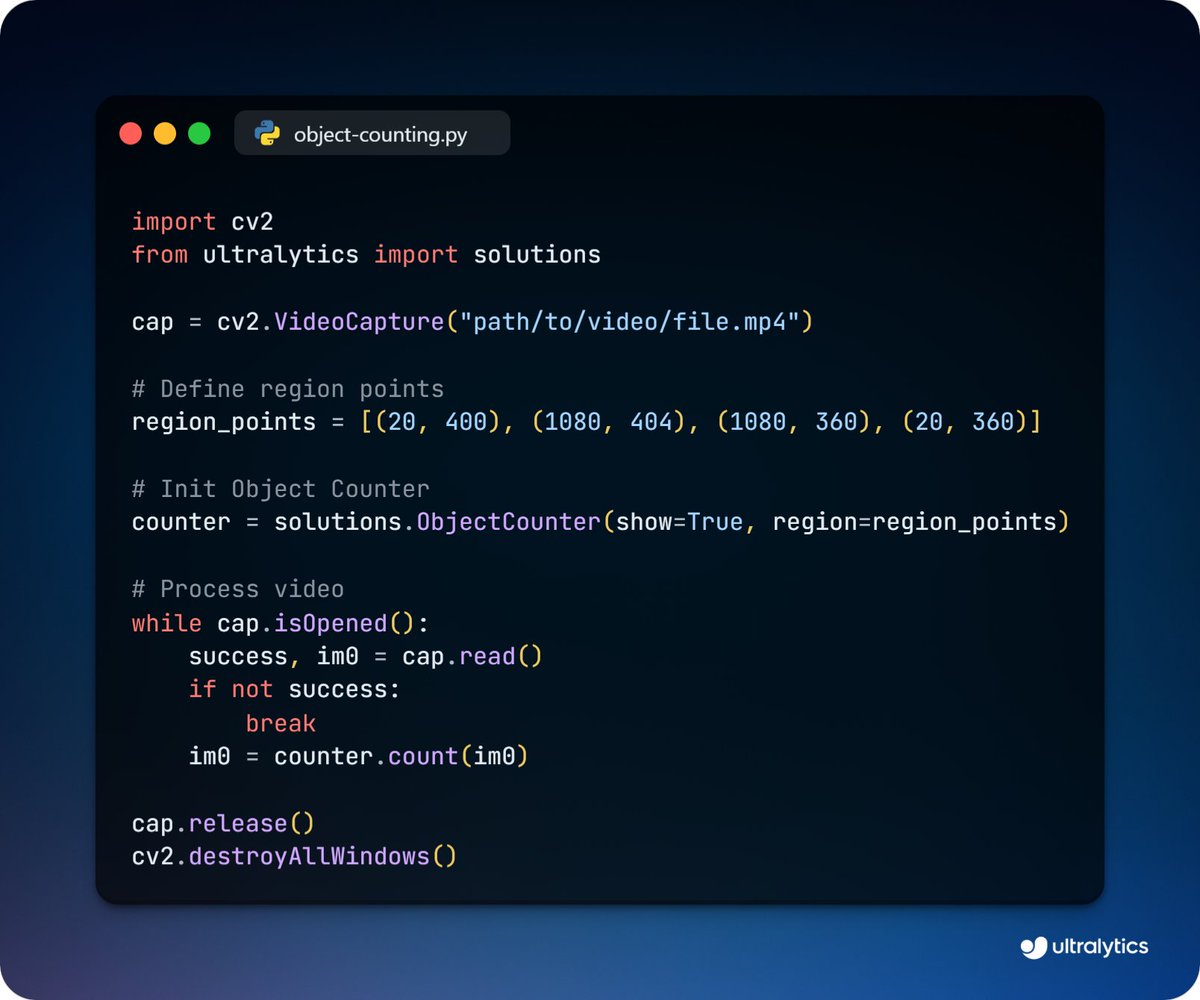
Count objects accurately with Ultralytics YOLO11! 🔢
Leverage YOLO11’s precision for real-time object counting across various scenarios. It's ideal for inventory management, crowd analysis, and more.
Learn more ➡️ ow.ly/QK5b50U52Fg
#YOLO11 #ObjectCounting #ComputerVision
1
11
459
6 Dec 2024
New tutorial | Counting ships using Ultralytics YOLO11 Oriented Bounding Boxes (OBB) 🚢
Learn how to leverage YOLO11 OBB for accurate object detection and counting in real-world applications i.e counting ships.
Watch now ➡️ youtube.com/watch?v=T8K47Atj…
#AI #ObjectCounting #YOLO11
1
9
386

29 Oct 2024
With VisionAgent, our generative Visual AI builder, you can automate tasks like inventory tracking in minutes—no complex coding required!
Learn more about VisionAgent: landing.ai/visionagent
#AI #VisualAI #ObjectCounting #Automation #Innovation
2
2
2
316

18 Oct 2023
🔥 NEW FEATURE: Object Counting Across Multiple Regions with Ultralytics YOLOv8
Accurate and adaptable #objectcounting is essential. This method tallies objects within defined regions, enabling advanced analysis with a multi-region focus.
Interactive region adjustments are as easy as a Left Mouse Click. Real-time object counting enhances precision while accommodating unique requirements.
✅ Dynamic Region Adjustment: Tailor regions on-the-fly for adaptable projects.
✅ Versatile Region Drawing: Create multiple regions with polygon and rectangle support.
✅ Swift Real-Time Processing: Fast and accurate results that can be applied across various domains.
The code is available in our repository 🔗 lnkd.in/eBf5jjq8
2
10
39
2,502

31 Aug 2023
Revolutionizing efficiency with IvedaAI Object Counting - harnessing cutting-edge technology for precise and seamless object enumeration. 📊🤖 #IvedaAI #ObjectCounting #InnovationInTech $IVDA
2
22
758

28 Feb 2023
#highlycitedpaper
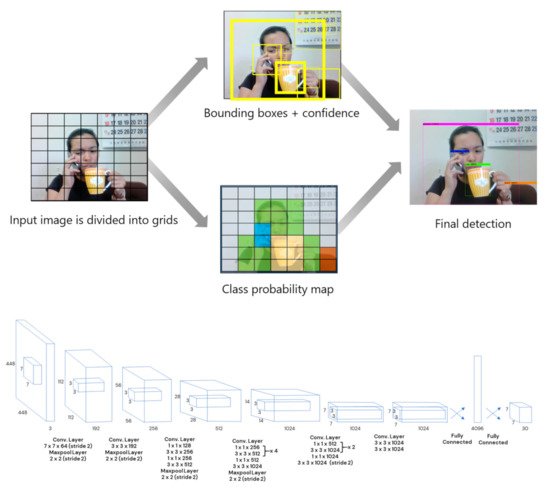
Real Time Pear Fruit Detection and Counting Using YOLOv4 Models and Deep SORT
mdpi.com/1424-8220/21/14/480…
@UNIV_TSUKUBA_EN
#YOLO #YOLOv4 #DeepSORT #ObjectCounting
1
2
347

4 Nov 2022
Ever thought about monitoring shrimp? We did, and here’s the case study of an #objectcounting project carried out with #computervision, #deepneuralnetworks, #PyTorch, #Streamlit, and #LabelStudio. All for the sake of a more accurate estimation of #biomass production.
@AWI_Media

1

28 Sep 2022
Object Counting
#Python #ArtificialIntelligence #CPP #objectdetection #backgroundremoval #Objectcounting #OpenCV

1

13 Nov 2020
Counting Objects in Images Training
#Africa4AI #ObjectDetection #ObjectCounting #DeepLearning #TensorFlow

1
3
9

18 Nov 2019
Possibility for so much #mathtalk! This would be a great option for students to play on their own once it’s modeled. #subitizing #objectcounting
18 Nov 2019

Thanks for a great conference, @eriksonmath. The Jumping on the Lily pads is one of our favorite counting games! youngmathematicians.edc.org/…
1
2
30 Oct 2019
So much excitement @shufordnccs today with Kindergarten! I bet they thought they were “just playing”. #objectcounting #gripandmanipulation #handdominance #followingdirections #playwithpurpose
30 Oct 2019





1
10