
24 Oct 2025
built Objectron a lightweight ORM written completely from scratch in Python.
It handles: Model -> Table mapping, Field descriptors, Session (Unit of Work), Dynamic Query Builder (filters, chaining of queries), Connection handling, Database agnostic via adapters (SQLite for now)
2
24
2,396

⚡️ Meet Kyvo — the new all-in-one model from Caltech!
Kyvo’s a transformer that can juggle text, images, and 3D scenes like a pro! It syncs everything *token by token,* unlocking fresh possibilities for multi-modal AI. 🤖✨
🔍 What Kyvo Can Do:
- Represents 3D scenes as lists of objects with attributes: shape, size, type, pose, position.
- Merges text, images, and 3D into one cohesive view.
- Renders images from scenes, reconstructs 3D from photos, answers scene-related questions, and modifies scenes on command.
- Uses special encodings for precise object shape recovery.
🧪 Tested On:
- Datasets: CLEVR, ObjaWorld, Objectron, ARKitScenes.
- Tasks: rendering, object recognition, scene instructions, Q&A.
✅ Why It’s Cool:
- Versatility: One model tackles multiple tasks and data formats.
- Flexibility: Excels in both generation and comprehension.
- A leap towards AI truly seeing the world in 3D—not just 2D! 🌍💡

2
1
2
114

15 Sep 2025
📢BlenderFusion: 3D-Grounded Visual Editing and Generative Compositing
BlenderFusion is a novel framework that merges 3D graphics editing with diffusion models to enable precise, 3D-aware visual compositing. Unlike prior approaches that struggle with multi-object and camera disentanglement, BlenderFusion leverages Blender for fine-grained control and a diffusion-based compositor for realism, bringing unprecedented flexibility to scene editing and generative compositing.
🔑 Key Highlights:
☑️ 3D-Grounded Control: Segments and lifts objects into editable 3D entities, enabling precise manipulation of objects, camera, and background.
☑️ Generative Compositor: Dual-stream diffusion model refines Blender renders into photorealistic outputs, correcting artifacts and enhancing realism.
☑️ Training Strategies: Introduces source masking and simulated object jittering to improve disentangled object-camera control.
☑️ Superior Editing: Outperforms baselines like 3DIT and Neural Assets across multi-object editing, novel object insertion, and complex compositing tasks.
☑️ Generalization: Demonstrates strong results on datasets (MOVi-E, Objectron, Waymo) and unseen real-world scenes, handling diverse edits such as attribute changes, deformations, and background replacement.
🤔 Why It Matters:
BlenderFusion bridges the gap between graphics-based precision and generative synthesis, giving creators, artists, and researchers the ability to craft complex, high-fidelity visual narratives. It represents a leap toward controllable, fine-grained visual generation in both synthetic and real-world settings.
🔗 Explore More:
Paper: arXiv: BlenderFusion
Project Page: blenderfusion.github.io
Related LearnOpenCV Blogs:
🔹Stable Diffusion: learnopencv.com/stable-diffu…
🔹MatAnyone: learnopencv.com/matanyone-fo…
#BlenderFusion #GenerativeAI #3DVision #VisualEditing #DiffusionModels #AI #DeepLearning
1
5
769

8 Dec 2024
🚨NeurIPS 2024 (Spotlight) Paper Alert 🚨
➡️Paper Title: Neural Assets: 3D-Aware Multi-Object Scene Synthesis with Image Diffusion Models
🌟Few pointers from the paper
🎯Authors of this paper addressed the problem of multi-object 3D pose control in image diffusion models. Instead of conditioning on a sequence of text tokens.
🎯They proposed to use a set of per-object representations, Neural Assets, to control the 3D pose of individual objects in a scene.
🎯Neural Assets are obtained by pooling visual representations of objects from a reference image, such as a frame in a video, and are trained to reconstruct the respective objects in a different image, e.g., a later frame in the video.
🎯Importantly, they encoded object visuals from the reference image while conditioning on object poses from the target frame.
🎯This enables learning disentangled appearance and pose features. Combining visual and 3D pose representations in a sequence-of-tokens format allowed them to keep the text-to-image architecture of existing models, with Neural Assets in place of text tokens.
🎯By fine-tuning a pre-trained text-to-image diffusion model with this information, their approach enables fine-grained 3D pose and placement control of individual objects in a scene.
🎯They further demonstrate that Neural Assets can be transferred and recomposed across different scenes. Their model achieves state-of-the-art multi-object editing results on both synthetic 3D scene datasets, as well as two real-world video datasets (Objectron, Waymo Open).
🏢Organization: @GoogleDeepMind , @Google Research, @UofT , @VectorInst , @ucl
🧙Paper Authors: @Dazitu_616 , @YuliaRubanova , @RishabhKabra , @drewAhudson ,@igilitschenski , @yusufaytar , @vansteenkiste_s , @KelseyRAllen , @tkipf
📝 Read the Full Paper here: arxiv.org/abs/2406.09292
🗂️ Project Page: neural-assets-paper.github.i…
🎥 Be sure to watch the attached Demo Video - Sound on 🔊🔊
Find this Valuable 💎 ?
♻️QT and teach your network something new
Follow me 👣, @NaveenManwani17 , for the latest updates on Tech and AI-related news, insightful research papers, and exciting announcements.
#NeurIPS2024
6
281

27 Aug 2024
The paper aims to address the problem of multi-object 3D pose control in image diffusion models. The authors propose a solution called "Neural Assets" to control the 3D pose of individual objects in a scene.
The authors evaluate their method on both synthetic (OBJect, MOVi-E) and real-world (Objectron, Waymo Open) datasets. They show that their Neural Assets approach outperforms baseline methods in terms of object identity preservation, editing accuracy, and background modeling. Their method can handle multi-object scenes and enable precise 3D control, such as translation, rotation, and rescaling of objects.
full paper: openread.academy/en/paper/re…

3
249


15 Apr 2023
サポートがきつかったsolutionたち(i.e. Box Tracking, Objectron, Instant Motion Tracking)、MediaPipeの公式でSupport endedになっているので、心置きなくお別れする
2
219

Objectron: Objectron is a dataset of short, object-centric video clips. In addition, the videos also contain AR session metadata including camera poses, sparse point-clou ...
Lang: Jupyter Notebook
⭐️ 2071
#MachineLearning
github.com/google-research-d…
1
3
334

3D Pose Estimation (Objectron) is an object recognition #technology to determine the 3-dimensional positions of objects. Explore hot #AI vision topics in our blog! viso.ai/blog

1
2
287
Objectron: Objectron is a dataset of short, object-centric video clips. In addition, the videos also contain AR session metadata including camera poses, sparse point-clou ...
Lang: Jupyter Notebook
⭐️ 2043
#MachineLearning
github.com/google-research-d…
1
2
12
1,114

30 Jun 2022
[Day 30]
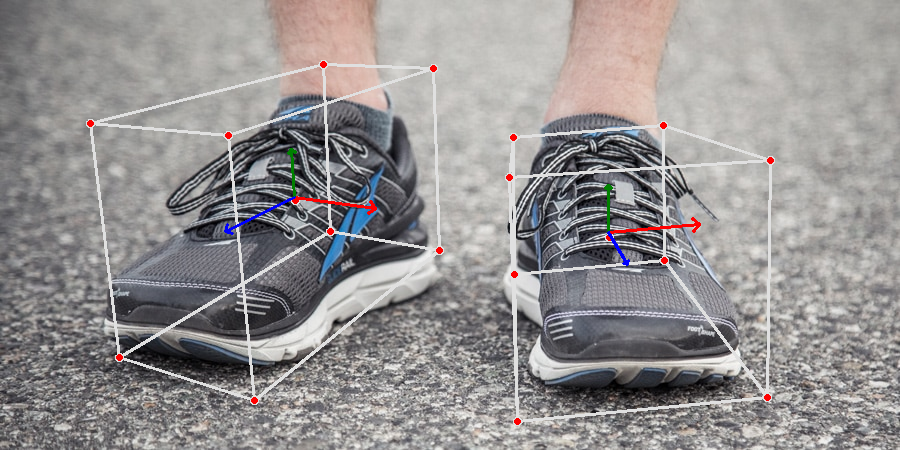
Trying the 3D object detection using MediaPipe library and Objectron pre-trained models.



1
3

You find identical or related research from most big players. Google, for example, published Objectron in 2020 already, 3D object detection, real-time on mobile.
ai.googleblog.com/2020/03/re…
1
4

30 Apr 2022
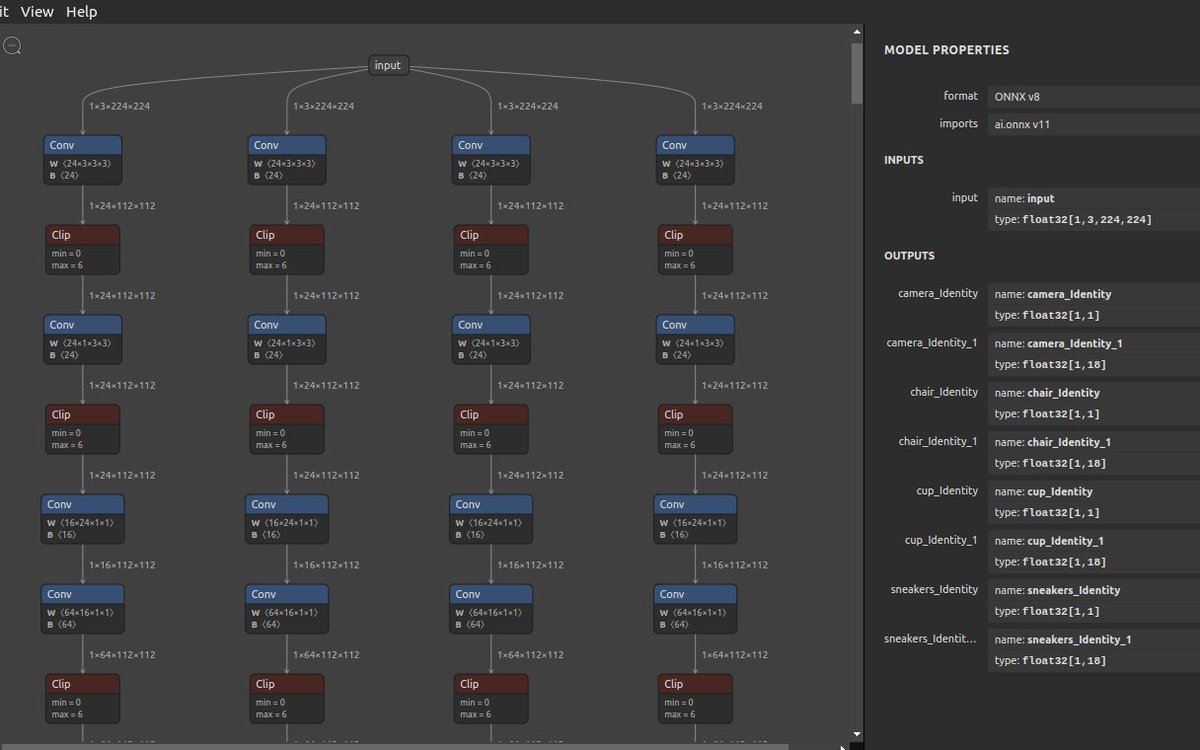
MediaPipe の Objectron の4オブジェクト分の4種類のTFLite を ONNX へ変換したうえでひとつのONNXファイルにマージしてみた。成功した。画像を一枚与えると カメラ、椅子、マグカップ、スニーカーの4種類の3Dバウンディングボックスが得られるはず。激重いはず。
5
30 Apr 2022
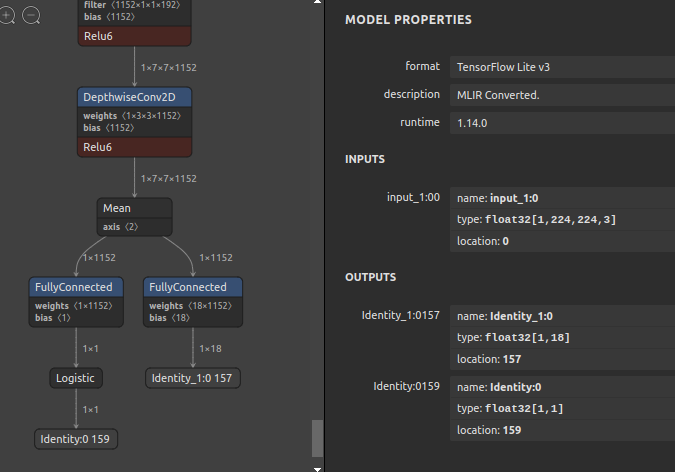
Objectron の Camera, Cup, Chair, Sneakers の4種類のマージは簡単そう。どのように出力を作ると嬉しいのでしょうかね? まぁ、興味ないか。
1. ひとつのオブジェクトにつき2つの出力 ✕ 4オブジェクト →合計8出力
2. ひとつのオブジェクトの出力2つを4オブジェクトで Concat →合計2出力
2
29 Apr 2022
そうか、いまひらめいた。Objectronの複数オブジェクトに分離したモデルをONNXでひとつにマージして1入力から複数出力を得られるモデルに改造してしまえばいいんだ。(良くない)
3

22 Mar 2022
Transframer is a general-purpose framework for image modeling and vision tasks based on probabilistic frame prediction: bit.ly/3L53pbH
Generative models of video are always fun to see! Great results on Objectron from this U-Net/Transformer-based model.
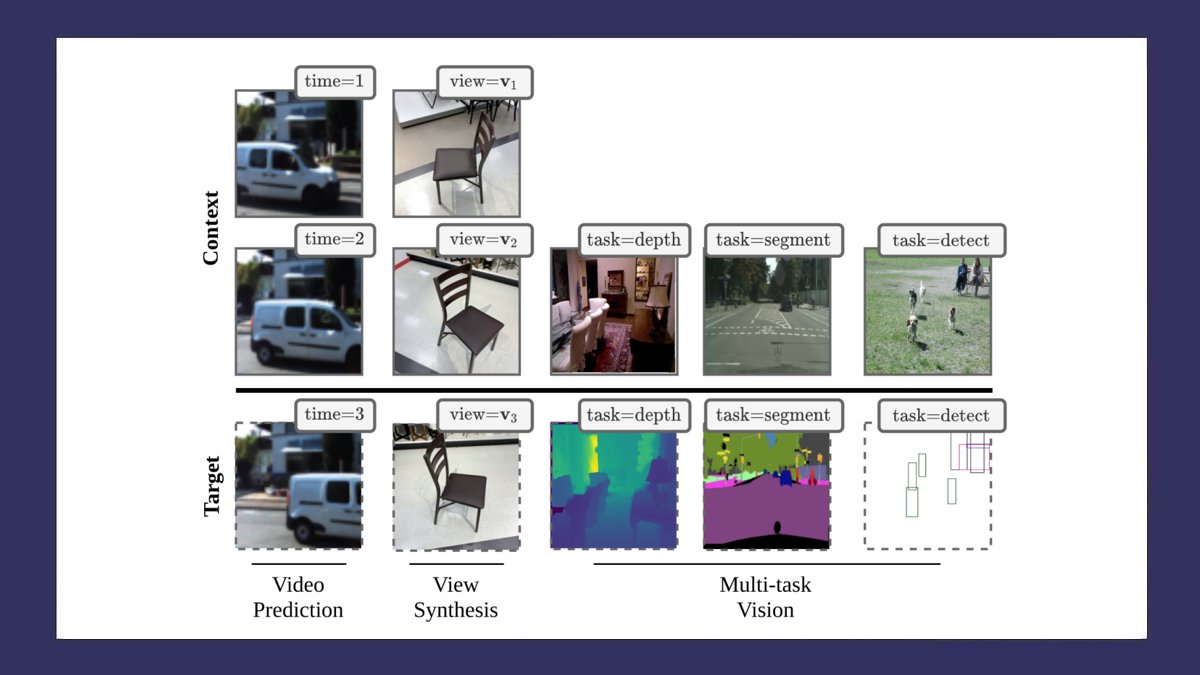
3
6

24 Feb 2022
Is this Objectron? Is the training code available for use?
2

4 Feb 2022
#5: Did you know that @GitHub also hosts datasets & metadata? Like this one:
🤳 "The Objectron dataset is a collection of short, object-centric video clips, which are accompanied by AR session metadata that includes camera poses and sparse point-clouds."
github.com/google-research-d…
2
4
13

1 Feb 2022
Objectron a dataset of 15,000 annotated videos and 4M annotated images!
GitHub github.com/google-research-d…
120
748
15 Jan 2022
うーん。Objectron から自動生成したKerasモデルを読み込みし直したら全パラメータが Trainable になってるな。てことは、最終層だけカットして生成した.h5をロードして、新しく定義し直した最終層に読み込んだモデルのoutputをinputとして食わせることができれば良い?
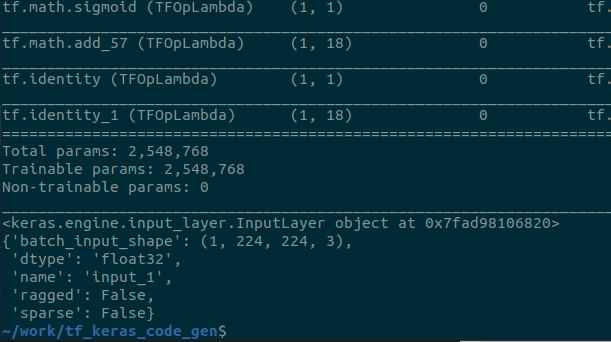
15 Jan 2022

あれ?転移学習ってそもそも何をするんでしたっけ?最終出力層に近いレイヤーだけ自分で定義したレイヤーですげ替えたりデータセットを変えてトレーニングし直すんでしたっけ?
4