
Joined October 2015
- Tweets 117
- Following 564
- Followers 986
- Likes 504
15 Photos and videos
















One year later with Omni and this test can pass. I saw it getting pretty close, so I tweaked the prompt:
> A video of a man counting to 10 on his fingers, show the number in the corner. A new number every 1s, no dialogue other than the numbers he says. He uses two hands for numbers bigger than 5.
- the model does 1 to 5 consistently well
- struggles more when two hands are used, usually on 7 and 8
- if you ask it to count faster, errors increase
- it keeps a good cadence

A new prompt to add to the fofr-benchmark:
> a man counts out loud from 1 to 10, using his fingers and holding them up as he goes
> a man counts out loud from 1 to 10, "1, 2, 3, 4, 6, 7, 8, 9, 10", he counts using his fingers and holds them up as he goes
15
11
172
41,145
Yulia Rubanova retweeted

May 29
Genuinely amazed by how many generalist visual capabilities one can squeeze out of this model
A quick test of using Omni to edit a video and add labelled bounding boxes around objects.
> Add a labelled bounding box around the monster truck and the flag
1
5
61
8,538

May 24
A few days post-I/O, people are starting to see what Gemini Omni is capable of.
Being a part of this project from the early days, it’s been amazing to watch native multimodality open up a new space of possibilities for video generation. Give it a try.
May 19

We’re dropping Gemini Omni: our first step towards a model that can create anything from anything - starting with video.
It combines Gemini’s intelligence with our generative media systems - representing a leap forward in world understanding, multimodality, and editing 🧵
5
728

not sure why nobody is talking about this but Google Omni is insane at video editing
Original Video (left) vs Omni Edited Video (right)
everyone is comparing it to Seedance and missing the point completely. Seedance is for generating videos from scratch. Google Omni is for editing videos that already exist. which are two completely different use cases
this is like when Nano Banana 1 first came out and nobody realized how big it was going to be. this is the first AI that can actually properly edit videos..
i've generated a few hundred videos with this model and it can do literally any type of edit you can think of. changing voices, swapping characters, removing watermarks, adding captions, transitions, pop ups, whatever. if you can describe the edit you want it can do it
this completely crushes every other model on the market when it comes to video editing. nothing else even comes close right now
and this is just the flash model. imagine what the pro version is going to be able to do when it drops in a couple months
this should have way more hype than it's getting..
40
35
414
28,691
Yulia Rubanova retweeted

May 19
The likeness preservation and natural realism coming out of Gemini #Omni Flash is absolutely unreal 🤯
Huge shoutout to the insanely talented team for pushing these boundaries. The team absolutely cooked. 👨🍳🔥
If Flash is this good... imagine what Pro is about to unleash. 👀✨
2
13
63
3,298
Yulia Rubanova retweeted

May 19
We sat down with @OfficialLoganK @nbrichtova @doomie @gbarthmaron to talk about Gemini Omni Flash. It was pretty wild.
7
20
206
41,520
Yulia Rubanova retweeted

May 19
Super excited to see Gemini Omni finally out in the world! Having been part of this project since its inception, I've seen how its native multimodal capabilities can redefine what's possible. We're truly entering the "Nano Banana era" for video generation. Give it a try!
4
7
60
4,104
Apr 20
Excited to head to ICLR 2026 in Rio de Janeiro 🇧🇷!
Happy to chat about video generation, controllability and world models!
1
1
36
2,243
Apr 10
We released Veo 3.1 Ingredients more than 6 months ago, and it is still ranking on top!
Apr 7

BREAKING: Veo 3.1 Fast and Veo 3.1 by @GoogleDeepMind are in 1st and 2nd place on Multi-Image to Video Arena
These models can successfully reference multiple input images to create a video that users love
At an average generation time of 48 seconds, they are also the two fastest video generation models
Huge congrats to the @GoogleDeepMind team for this achievement!

7
635
Jan 13
New version Ingredients to Video is out!
Now with a portrait mode, better storytelling and consistency -- now available directly on Youtube Shorts.
It is the most rewarding experience to be part of this team and put this into the hands of real users.
Jan 13
We’re updating Veo 3.1 Ingredients to Video to help create more expressive and dynamic clips, produce better visual consistency and more. 📽️
Here’s what’s new 🧵
8
436
13 Dec 2025
Veo is officially a world simulator for robotics! 🤖🎥
We used action-conditioned Veo to evaluate robotics policies entirely in a generated video. This is a game-changer for scalable, safe robotics testing. Loved working with the team on this!
12 Dec 2025

Generalist robots need a generalist evaluator. But how do you test safety without breaking things? 💥
🌎 Introducing our new work from @GoogleDeepMind:
Evaluating Gemini Robotics Policies in a Veo World Simulator
veo-robotics.github.io
🧵👇
2
15
1,140
Yulia Rubanova retweeted
12 Dec 2025
So excited to finally talk about this work!
Veo is a surprisingly strong world simulator. We fine-tuned Veo on action-conditioned, multi-view robotics data.
Key result: running a policy in the world model is strongly correlated with real-world results.
A few important take-aways:
1) Veo Robotics models real-world physics and robot interactions
2) The base model's world knowledge is retained after fine-tuning and can model OOD scenarios not seen in the robotics data
3) The world model can be used to score task success or failure for a given policy
4) This proves useful for predictive red teaming: simulate dangerous or rare scenarios that would be difficult or irresponsible to execute on the real robot, and judge its performance
I couldn't be more excited about where generalist video models are headed.
12 Dec 2025
Generalist robots need a generalist evaluator. But how do you test safety without breaking things? 💥
🌎 Introducing our new work from @GoogleDeepMind:
Evaluating Gemini Robotics Policies in a Veo World Simulator
veo-robotics.github.io
🧵👇
15
29
225
44,473
Yulia Rubanova retweeted

21 Nov 2025
Our second Nano Banana in three months 🚢 🚢. Super proud of the team!!
Looking forward to seeing what you'll create with it. Any feedback welcome!
20 Nov 2025

You went 🍌🍌 for Nano Banana. Now, meet Nano Banana Pro.
It’s SOTA for image generation editing with more advanced world knowledge, text rendering, precision controls. Built on Gemini 3, it’s really good at complex infographics - much like how engineers see the world:)

1
10
72
11,396
15 Nov 2025
Try out Veo Ingredients -- now on Gemini App!
14 Nov 2025

We’re back with another update to Veo 3.1:
Rolling out now on mobile and desktop, you can upload multiple reference images alongside your video prompts, to create entirely new worlds and more nuanced videos that are true to your vision.
1
4
811
21 Oct 2025
Excited to share a huge update Veo Ingredients!
Now your characters can speak🎤 and sing🎶
Seriously, this opens up a whole new level of storytelling. Try it out on Flow: labs.google/flow
#VeoIngredients #veo3_1
15 Oct 2025
🖼️ Ingredients to video
Give multiple reference images with different people and objects, and watch how Veo integrates these into a fully-formed scene - complete with sound.
4
499
21 Oct 2025
Veo 3.1 got a major quality upgrade 👇 Try it out!

🚨🎬 Big news from Video Arena!
@GoogleDeepMind’s latest Veo 3.1 now ranks #1 in both Text-to-Video and Image-to-Video leaderboards. 🏆
This is a 30-point leap from Veo 3.0 → 3.1, making it the first model to break 1400 in Video Arena history!
Huge congrats to the @GoogleDeepMind team for pushing the frontier of video generation forward!
More details in the thread 🧵
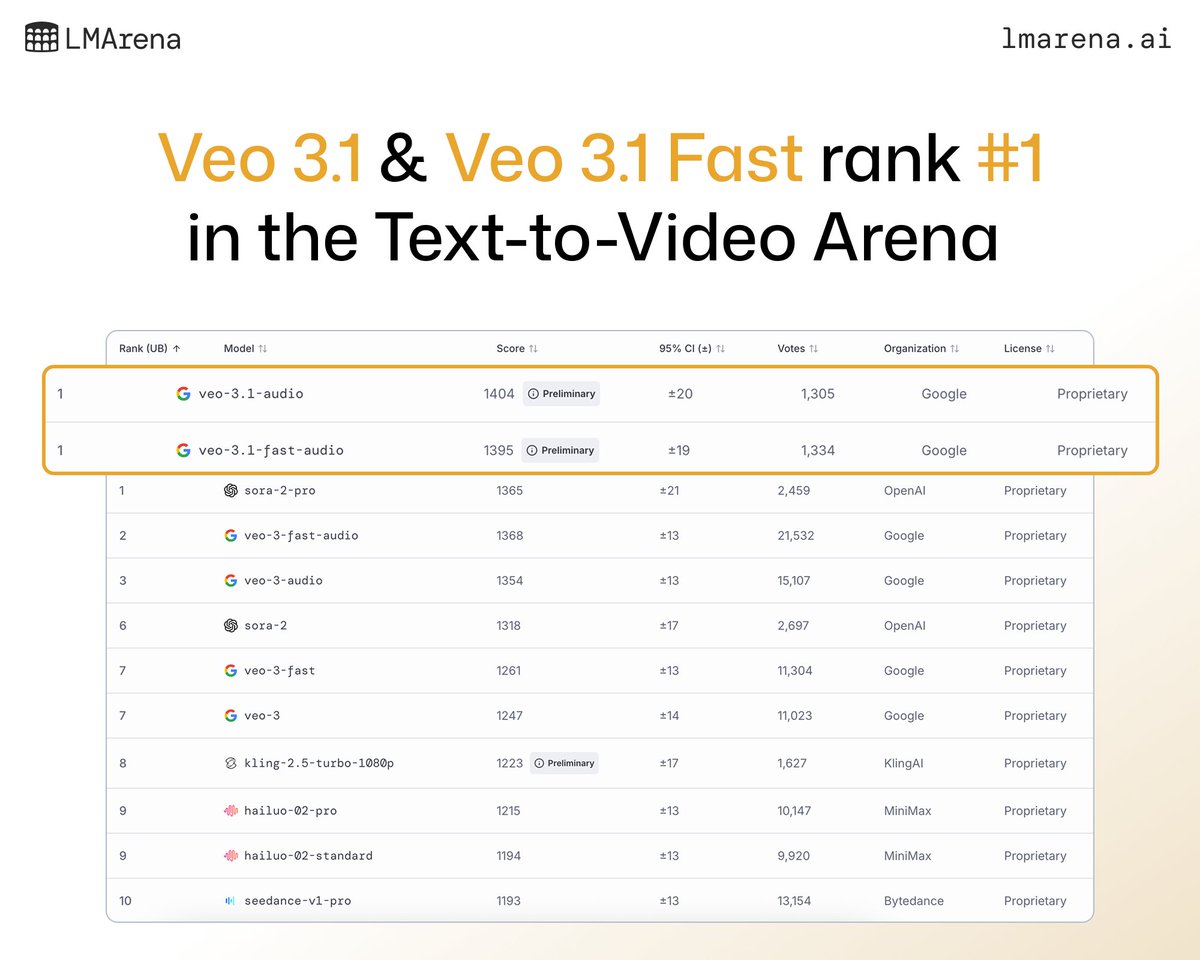
8
570
30 Sep 2025
What an incredible night! Thank you @corl_conf for shaking things up and inviting both a K-pop band and a Korean traditional music band to the CoRL Banquet. It made the evening truly special.
29 Sep 2025

1
11
2,342
28 Sep 2025
Veo 3 has powerful visual reasoning capabilities out of the box 👾 It can solve puzzles, understand optical illusions, reason about gravity, lighting, color mixing and more! Veo just keeps on giving 🍏
Check out a detailed investigation by our Deepmind colleagues below 👇
25 Sep 2025

🔥Veo 3 has emergent zero-shot learning and reasoning capabilities!
This multitalented model can do a huge range of interesting tasks.
It understands physical properties, can manipulate objects, and can even reason.
Check out more examples in this thread!
1
8
824
30 Aug 2025
Veo Ingredients is available with Veo Fast ⚡️ Make your creations 10x faster and with fewer credits!
We've also made huge strides on improving character consistency.
Here are some examples made from my profile image, and the results are amazing. 👇
28 Aug 2025

We posed a creative challenge to our Discord community: start with the exact same ingredients and a prompt to create something in Flow.
The results... delightful! ✨
1
2
4
3,223
30 Aug 2025
1
149
30 Aug 2025
116