
Mar 24
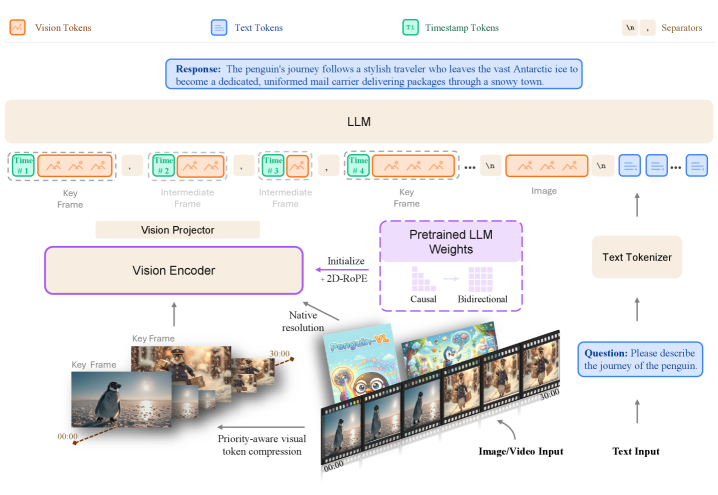
Tencent just released the Penguin recap dataset on Hugging Face
68 million multimodal samples spanning DataComp, COYO, SA-1B and OpenImages
for training efficient Vision Language Models with LLM-based encoders.
2
8
52
6,543

いまGoogleのOpenImagesでも900万枚ぐらいだよね
Jan 12

進歩してねえ……
3
4
744

27 Oct 2025
Appleがpico-bananaというデータセットをリリース。これはGoogleのOpenImagesデータセットの画像をGoogleのNanoBananaで編集した結果をGoogleのGemini2.5Proでチェック(成功したか)させて作ったデータ。メチャクチャGoogleに乗っかったねえ。つまりNanoBananaみたいなモデルを作りたい時の学習データ
reddit.com/r/StableDiffusion…
29
228
37,806

🚨أبل تدخل ساحة الذكاء البصري بقوة!
بدون أي ضجة إعلامية… أطلقت Apple واحدة من أهم وأضخم قواعد البيانات في مجال تعديل الصور بالذكاء الاصطناعي:
📸 Pico-Banana-400K
قاعدة بيانات تحتوي على 400 ألف صورة وتعليمة تحرير نصية، لتدريب النماذج على “فهم الأوامر البصرية” مثل:
✨ حوّل الإضاءة إلى غروب الشمس
🎨 اجعل الصورة بأسلوب بيكسار
🌧️ أضف أجواء ماطرة واقعية
🔍 ما الجديد والمميز؟
•أبل استخدمت نموذجها الداخلي Nano-Banana لتوليد تعديلات على صور حقيقية من مكتبة OpenImages — وليس صورًا مولدة من الصفر.
•بعد ذلك، مرّت النتائج على Gemini 2.5 Pro لتقييم الواقعية والالتزام بالتعليمات النصية.
•فقط أفضل الأمثلة من حيث الجودة تم اعتمادها في المجموعة النهائية.
🧠 محتوى القاعدة:
•72K مثال لتعديلات متتابعة (multi-turn editing).
•56K مقارنة تفضيل بين نتائج ناجحة وفاشلة.
•تعليمات طويلة وقصيرة لتدريب النماذج على فهم أسلوب المستخدم الواقعي.
🧩 لماذا هذا مهم؟
هذه الخطوة تضع Apple رسميًا في سباق الذكاء البصري التوليدي.
فـ Pico-Banana-400K يمكن اعتبارها “ImageNet عصر التعديلات البصرية” — مورد مفتوح المصدر يرفع سقف التدريب لنماذج تحرير الصور بالنصوص
#AppleAI #PicoBanana400K #NanoBanana #AI #MachineLearning #ComputerVision #TextToImage #GenerativeAI #AppleResearch #OpenSource #ImageEditing
2
89

26 Oct 2025
#آبل أطلقت قاعدة بيانات Pico-Banana-400K تضم 400 ألف صورة حقيقية معدلة بالذكاء الاصطناعي لتدريب النماذج على تعديل الصور بناءً على تعليمات نصية.
- مبنية على صور من OpenImages، معدلة بـNano-Banana.
- تشمل 72 ألف سلسلة تعديل متعددة، و56 ألف مقارنة تفضيل.
- مفتوحة المصدر للبحث.

1
7
42
3,401

26 Oct 2025
أبل تفاجئ العالم بإطلاق أكبر قاعدة بيانات لتعديل الصور بالذكاء الاصطناعي
أبل دخلت الساحة بقوة، وقدمت شيء ما أحد توقعه:
Pico-Banana-400K — قاعدة بيانات ضخمة تضم 400 ألف صورة مخصصة لتدريب نماذج الذكاء الاصطناعي على تعديل الصور بتعليمات نصية.
الشيء المجنون؟ البيانات كلها من صور حقيقية، مو مولدة اصطناعيًا!
أبرز التفاصيل:
•أبل استخدمت نموذجها الداخلي Nano-Banana لتوليد تعديلات متنوعة على صور حقيقية من مكتبة OpenImages.
•بعد التوليد، تم تمرير النتائج على Gemini 2.5 Pro لتقييم الجودة بدقة، من ناحية الواقعية، والتزام الصورة بالتعليمات.
•النتيجة: فقط أفضل الصور والتعديلات تم اعتمادها في المجموعة النهائية.
وش تحتوي القاعدة:
•72 ألف سلسلة تعديل متعددة المراحل (لتدريب النماذج على التعديلات المتتابعة).
•56 ألف مقارنة تفضيل (للتمييز بين النتائج الناجحة والفاشلة).
•تعليمات مزدوجة: طويلة مخصصة للتدريب، وقصيرة تحاكي أسلوب المستخدم الحقيقي.
يعني تقدر تدرب نموذج يفهم لما تقول له: “حوّل الإضاءة لغروب الشمس” أو “خلّ الصورة بأسلوب بيكسار” ويتعلم من أمثلة حقيقية مو صور مزيفة.
الخلاصة:
أبل ما أعلنت بصخب، لكنها أطلقت فعليًا “ImageNet” خاص بعصر التعديلات البصرية.
البيانات مفتوحة المصدر ومجانية تحت رخصة أبحاث أبل، والنتيجة؟
سباق الجيل القادم من الذكاء البصري بدأ الآن.

5
19
127
24,771

23 Oct 2025
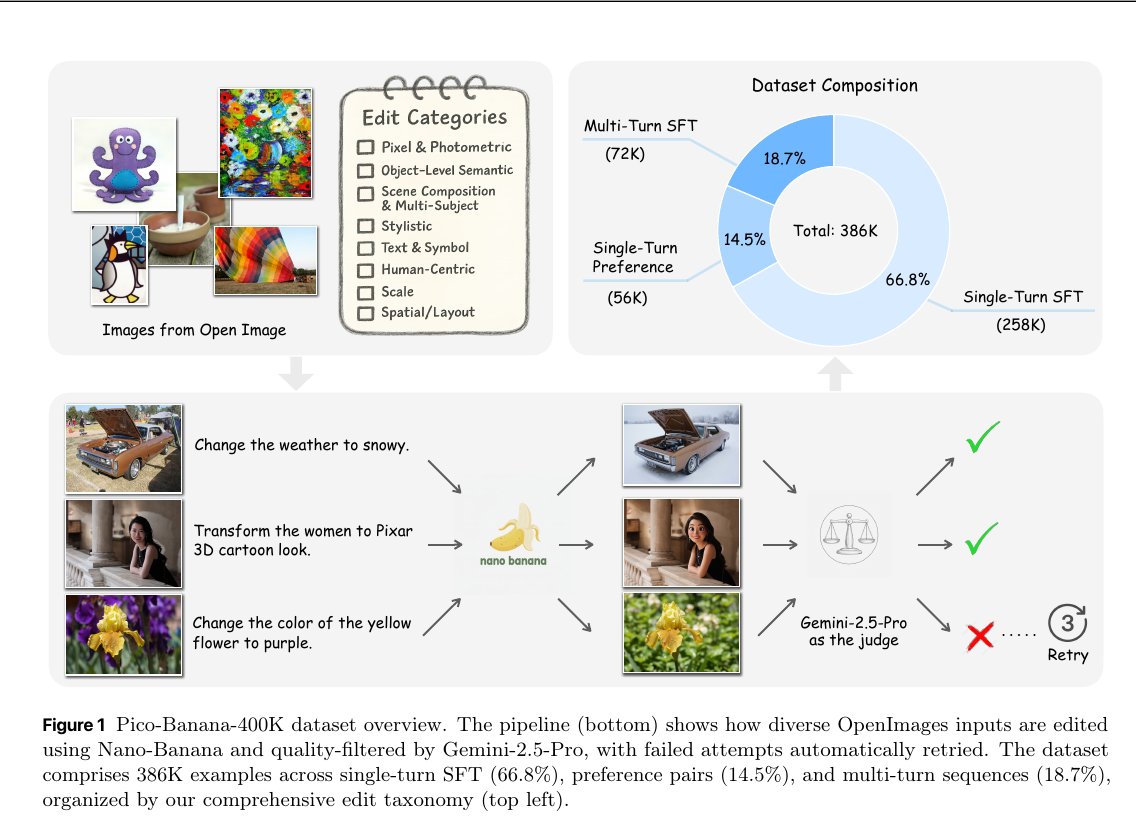
🎨 Beautiful. Apple just dropped Pico-Banana-400K.
A huge ~400K text-guided image editing dataset from real OpenImages photos with 35 edit types, automated Gemini-judged quality, and open sharing for research.
Each edit is produced by Nano-Banana then scored by Gemini-2.5-Pro with weighted checks, 40% instruction compliance, 25% seamlessness, 20% preservation balance, 15% technical quality, passing only if the score is about 0.7 or higher.
The release includes 258K single-turn SFT pairs, 56K success-vs-failure preference pairs for methods like Direct Preference Optimization, and 72K multi-turn sessions, totaling 386K filtered examples with both long and short instructions.
Edits span 8 categories and 35 operations across pixel or color changes, object semantics, scene composition, styles, text or symbols, human edits, scale, and spatial layout, and low-quality operations were removed up front.
Multi-turn chains are built by sampling 100K single-turn cases and adding 1 to 4 more operations to create 2 to 5 step sequences with context-aware follow-ups that refer to earlier edits.
Global and style edits succeed most, for example 0.9340 strong style transfer, 0.9068 film grain, 0.8875 modern↔historical restyle, while fine spatial control is hardest, for example 0.5923 relocate object, 0.5759 change font or style, 0.6634 outpainting.
Images come from OpenImages, negative attempts are kept as counterexamples for preference learning, metadata is standardized, and the reported build cost is $100,000.
7
7
30
5,089

15 Jul 2025
That’s a striking visual—and honestly not far off from what’s happening behind the scenes with large AI models.
Massive image datasets like LAION and OpenImages feed these models during training, and we're literally talking billions of images being tokenized, labeled, and streamed through at scale.
11

12 May 2025
In computer vision, any new eval coming out has like 80% chance of being mscoco or openimages pictures re-annotated.
1
2
69
7,524

6 Jan 2025
Too many people overfitting to the training set. For LLMs it is hard to notice. This is still a big issue in object detection, where we lack extremely good models-SOTA of COCO/OpenImages/O365 are weak, and the resulting models make a lot of errors due to low quality annotations.
1
1
3
937


12 Dec 2024
VQ-VAEのトークナイザーを事前にオープンデータセット(OpenImages)で学習して、VAR Transformer自体もImageNetでトレーニングしているのか。
損失関数もおもろい。LPIPSとStyleGANを組み合わせて独自で実装してる。
3
853
6 Dec 2024
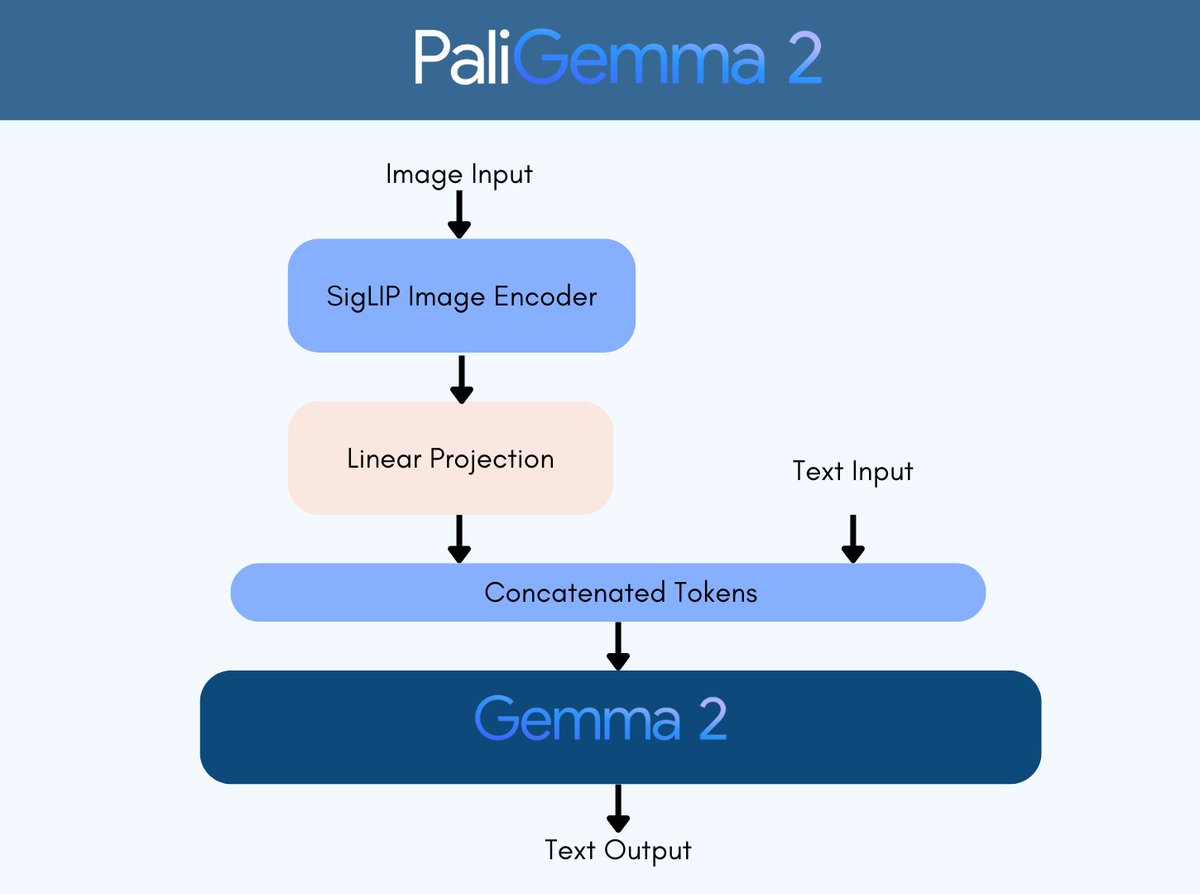
Google just released PaliGemma 2, its vision language model family.
Distributed under the Gemma license, which allows for redistribution, commercial use, fine-tuning and creation of model derivatives.
→ The model comes in 3B, 10B, and 28B parameter variants, supporting input resolutions of 224x224, 448x448, and 896x896. Pre-training leverages diverse datasets including WebLI, CC3M-35L, VQ2A, OpenImages, and WIT.
→ Performance testing shows minimal degradation with quantization: bfloat16 achieves 60.04% accuracy, 8-bit reaches 59.78%, and 4-bit maintains 58.72% on TextVQA validation set.
→ On DOCCI benchmark, PaliGemma 2 10B variant achieves 20.3 NES score, outperforming competitors like LLaVA-1.5 (40.6) and MiniGPT-4 (52.3). The model supports LoRA, QLoRA, and model freezing for efficient fine-tuning.
→ All models are supported with transformers (install main branch) and they work out-of-the-box with your former fine-tuning script and inference code
This release includes all the open model repositories, transformers integration, fine-tuning scripts
1
3
18
2,374

9 Aug 2024
i'm pretty sure that started in 2022, i don't think anyone had beef with the vqgan or original compviz latent diffusion datasets: imagnet, cifar, wikiart, s-flikr, openimages. i *think* google's conceptual captions dataset might be the first problematic one, maybe alongside CLIP
1
3
52


4 Jun 2024
Our pipeline is fully automated and only requires RGB images. We collect our dataset using OpenImages, resulting in 8.7 million spatial concepts grounded in 5 million unique regions from 1 million images.
(4/n)

1
6
1,438
24 May 2024
Using these benchmarks, we see that our default ("western") benchmarks guide us in the wrong direction!
Surprisingly, XM3600 is *not* indicative of "multicultural understanding". That's because while it has 36 languages, its images all come from the western OpenImages.

1
14
1,059

8 Apr 2024
sdxl was not trained on any unlicensed media. "The dataset consists of 1.8 million images from the ImageNet dataset and 1.2 million images from the OpenImages dataset. The images were resized to 256 x 256 pixels and augmented with random crops, flips, and rotations."
4
9
1,147

Inject Semantic Concepts into Image Tagging for Open-Set Recognition
paper page: huggingface.co/papers/2310.1…
introduce the Recognize Anything Plus Model~(RAM ), a fundamental image recognition model with strong open-set recognition capabilities, by injecting semantic concepts into image tagging training framework. Previous approaches are either image tagging models constrained by limited semantics, or vision-language models with shallow interaction for suboptimal performance in multi-tag recognition. In contrast, RAM integrates image-text alignment and image-tagging within a unified fine-grained interaction framework based on image-tags-text triplets. This design enables RAM not only excel in identifying predefined categories, but also significantly augment the recognition ability in open-set categories. Moreover, RAM employs large language models~(LLMs) to generate diverse visual tag descriptions, pioneering the integration of LLM's knowledge into image tagging training. This approach empowers RAM to integrate visual description concepts for open-set recognition during inference. Evaluations on comprehensive image recognition benchmarks demonstrate RAM exceeds existing state-of-the-art (SOTA) fundamental image recognition models on most aspects. Specifically, for predefined common-used tag categories, RAM showcases 10.2 mAP and 15.4 mAP enhancements over CLIP on OpenImages and ImageNet. For open-set categories beyond predefined, RAM records improvements of 5 mAP and 6.4 mAP over CLIP and RAM respectively on OpenImages. For diverse human-object interaction phrases, RAM achieves 7.8 mAP and 4.7 mAP improvements on the HICO benchmark.

11
59
19,482

18 Oct 2023
📚 Awesome Robotics Libraries 🤓
A curated list of robotics simulators and libraries.
[🔖 Bookmark for later!]
These libraries offer a wide range of functionalities from dynamics simulation and inverse kinematics to machine learning and data visualization:
1. ARCSim:
A dynamics simulation library for soft robotics. It supports inverse kinematics, inverse dynamics, and URDF/SDF models. It is written in C and Python and is licensed under Zlib:
graphics.berkeley.edu/resour…
2. CHRONO::ENGINE:
A physics engine developed for real-time simulations, with applications in robotics, vehicle dynamics, aerospace, and biomechanics. It is written in C :
projectchrono.org/
3. RelaxedIK:
A library for real-time synthesis of accurate and feasible robot arm motion:
github.com/uwgraphics/relaxe…
4. Trip:
A Python package that solves inverse kinematics of parallel-, serial- or hybrid-robots:
github.com/TriPed-Robot/trip…
5. AllenAct:
A Python/PyTorch-based research framework for embodied AI:
github.com/allenai/allenact
6. DLL:
Deep Learning Library (DLL) for C , designed for machine learning and deep learning in robotics:
github.com/wichtounet/dll
7. DyNet:
The Dynamic Neural Network Toolkit, a neural network library developed by Carnegie Mellon University and many others:
github.com/clab/dynet
8. Fido:
A lightweight C machine learning library for embedded electronics and robotics:
github.com/FidoProject/Fido
9. Foxglove Studio:
A fully integrated visualization and debugging desktop app for your robotics data. It combines functionality of tools like rviz, rqt, and more:
foxglove.dev/
10. grl - Drivers:
Generic Robotics Library, a cross-platform library with drivers for Kuka iiwa and Atracsys FusionTrack. It also has cross-platform Hand Eye Calibration and Tool Tip Calibration:
github.com/ahundt/grl
11. OpenAI Gym:
Developing and comparing reinforcement learning algorithms:
github.com/openai/gym
12. The Control Toolbox ('CT'):
Is a C library for modelling, control, estimation, trajectory optimization and model predictive control:
ethz-adrl.github.io/ct/ct_do…
13. The Point Cloud Library (PCL):
Is a standalone, large scale, open project for 2D/3D image and point cloud processing. PCL is released under the terms of the BSD license, and thus free for commercial and research use:
github.com/PointCloudLibrary…
14. Ceres Solver - optimization:
Ceres Solver is an open source C library for modeling and solving large, complicated optimization problems. It is a feature rich, mature and performant library which has been used in production at Google since 2010.
github.com/ceres-solver/cere…
15. ORB_SLAM2:
Real-Time SLAM for Monocular, Stereo and RGB-D Cameras, with Loop Detection and Relocalization Capabilities:
github.com/raulmur/ORB_SLAM2
16. VISP - Vision:
Open Source Visual Servoing Platform
A modular cross platform library that allows prototyping and developing applications using visual tracking and visual servoing technics:
github.com/lagadic/visp
17. Dex-Net 2.0 - Dataset:
6.7 million pairs of synthetic point clouds and grasps with robustness labels:
bair.berkeley.edu/blog/2017/…
18. openimages:
Huge imagenet style dataset by Google:
github.com/openimages/datase…
They can be used in various applications, including soft robotics, robot arm motion, embodied AI, and more.
Source to find even more:
github.com/ahundt/awesome-ro…
If you have interesting papers or projects, you would like to share, please DM me!
1. Follow me @Ilir_AI for more.
2. RT the tweet if this is valuable.

1
8
2,618