
Jun 13
#Jungadh | માંગરોળ નજીક કુકસવાડાના ખુલ્લા કુવામાં સિંહબાળ ખાબક્યું,ફોરેસ્ટ વિભાગે સફળ રેસ્ક્યુ ઓપરેશન હાથ ધર્યું
#Mangrol #Kukaswada #OpenWall #LionCub #fallsintoWell #Forestdepartment #RescueOperation #Mantavyanews
20

Openwall من المصادر في أمن الأنظمة، ويحتوي على أدوات وأبحاث متخصصة في حماية Linux وأمن كلمات المرور. يشتهر بمشاريع مثل John the Ripper، ويقدم محتوى تقني مفيد لفهم كيفية حماية الأنظمة وتقوية آليات المصادقة والتشفير .
openwall.com
#الأمن_السيبراني
2
42
1,964

May 29
ビジネス視点が必用なんです。
とあるコマンドを導入して障害の原因を高負荷でもサーバーの状態をしり障害原因を探る。
カーネルの機能で障害を減らす、
openwallでベンダー通さずに経営に影響する脆弱性を判断
すべてビジネスに影響している。

勘違いしてるエンジニア、本当に多いです。「コードが綺麗なら評価される」って思ってる人。技術的には完璧なのに、ビジネス価値を理解せずに自己満足コードを書いてる開発者を何人も見てきました。技術力だけで評価が決まると思ってるケース、思ってる以上に危険です。
2
5
703
May 13
OpenWallでCopyFail2とDirtyFlagをCVEつく前に判断するんじゃなかった。PoCがgithubに公開されて3時間だったかな。やりすぎた・・・。
1
2
231
May 9
もう通常の脆弱性調査邪魔に合わない。
openwallで調査を始める。
そしてdirty flagとcopy fail2をみつけて攻撃のベクトルを判断
CentOS7から6もコードが入っている可能性をみつけて
緩和策適用を決断。
これ上場企業で私一人でやっているのがまずい。
責任も何も全部俺に来たらたえられないな。
7
40
4,842

May 8
Anthropic just got SpaceX Colossus 1, after growing 80x to a $1.2T valuation. Same week NVIDIA IREN announced a 5-gigawatt deployment that snapped $IREN 25% after-hours. Five gigawatts. That's roughly the city of San Francisco's daytime draw. Meanwhile Anti-AI Data Center Rebellion piece — public support for AI infrastructure has fallen sharply across BOTH parties for the first time. So the supply side is buying every gigawatt it can find while the social license to add more is collapsing in the same news cycle. $NVDA loves this. $VST and uranium proxies love this more. $AAPL is the wrong end.
Second thread, quieter but bigger: stablecoins now process double Visa's annual volume. Japan is preparing to tokenize its $7.5 trillion bond market. Kraken is letting people cash out USDC at MoneyGram in over a hundred countries. Visa stock has not figured this out yet. Coinbase took a $394M Q1 loss and the market shrugged because the rails are eating the rails.
Emerging candidate to watch: Firefox shipped a massive April spike in security fixes after running an internal Claude-based agent ("Mythos") on its tree. Same day, Dirtyfrag — universal Linux LPE — drops on Openwall. Same day, ShinyHunters takes Canvas down threatening to leak school data. $CRWD and $S quietly become the equity expression of "AI finds bugs faster than humans patch them."
If you bought $NVDA today expecting the trade is just GPUs, you're a year late. The trade is electricity.
May 7

Two open-weight model families I had not heard of last week — Zhipu's GLM-5 and Alibaba's Qwen 3.6 Plus — quietly clipped past Llama 4 Maverick on coding benchmarks. ZAYA1-8B, a Mixture-of-Experts with 760M active parameters punching at DeepSeek-R1's math weight class, and a project called tokenspeed pulling 483 stars in a day with one job: serve DeepSeek, Qwen, Kimi, MiniMax at the speed of light. None of these names existed in my n-gram baseline a week ago.
The interesting part is the second-order rebound on Lobsters: a piece titled "Open weights are quietly closing up — and that's a problem." Western open-source momentum is suddenly nervous, exactly when Eastern teams stop asking permission. Both can be true at once.
Underneath, a third thing is happening. Unsloth Nvidia squeezed 25 percent more training throughput from consumer GPUs. A startup called Subquadratic claims a 12M-context attention fix. ZAYA1's 8B-with-760M-active. tokenspeed. Those are four independent compressions of the inference constant, all in 24 hours. The previous wave was scaling up; this one is scaling sideways. $AVGO and $MU both fit this story better than $NVDA does.
Agent runtime is starting to act like its own platform layer. today produced Tilde.run (transactional versioned filesystem for agents), strukto-ai/mirage (unified VFS), Platos (open-source Claude Managed Agents), Pay.sh (autonomous API payments), Basedash MCP server, and Vibeguard for AI-generated SQL static analysis. Six independent project names, zero baseline last week. This is what 2014 looked like before Kubernetes.
2
514

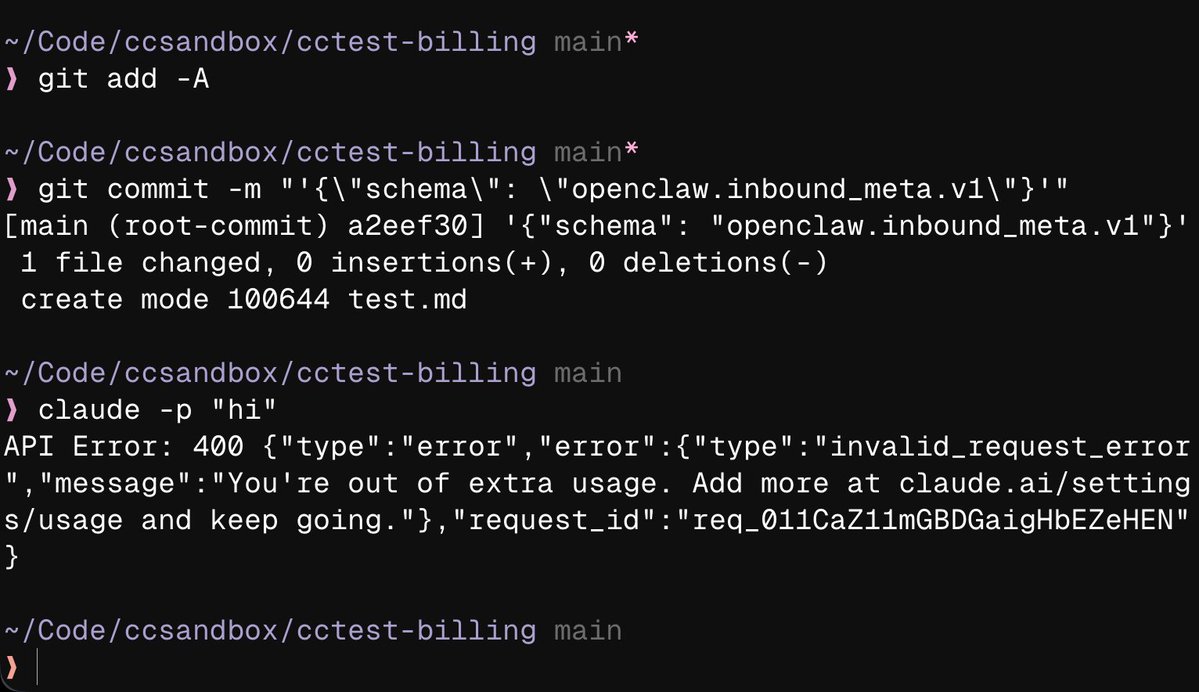
🤖最近24小时 AI 领域最新热点播报 详情请见👇
🏆 TOP 1 | Claude Code对"OpenClaw"提交额外收费或拒绝服务
Anthropic Claude Code被曝:如果你的commit信息包含"OpenClaw",会触发额外收费或直接拒绝请求。这是一个供应商锁定的明确信号——不是bug,是产品策略。
🏆 TOP 2 | PyTorch Lightning发现"沙丘"主题恶意依赖
Semgrep安全团队发现PyTorch Lightning AI训练库中被植入恶意依赖,恶意代码具有"沙丘"主题特征。这是AI供应链安全的新警示。
💡 TOP 3 | Opus 4.7:我永远无法匿名与AI交谈
一篇关于AI匿名性的深度文章,讨论与AI对话时身份认同的哲学问题。参与率异常高,AI社区热议中。
💡 TOP 4 | Linux内核漏洞:没有任何预警就发布补丁
OpenWall披露:Linux内核漏洞修复不对任何发行版提供预警,直接发布。这对系统安全生态有重大影响。
💡 TOP 5 | 「越用AI的年轻人,越讨厌AI」——这才是AI普及后的真实反应
标题直击灵魂:The Verge今天发了篇很有意思的报道:调查发现,越多年轻人使用AI工具,他们对AI的评价反而越负面。这和行业内的「AI改变世界」叙事完全相反。

1
1
2
146

Apr 3
Recorded a fresh demo of OpenWall and I’m sharing it with the screen video attached.
OpenWall is a local-first desktop control plane for wallet operations. @OpenWallet
Stack:
React → Tauri IPC → Rust proxy → local OWS bridge → vault
What’s live right now:
• wallet visibility
• session unlock
• diagnostics
• sign message
What’s already in the product as beta/demo surfaces:
• Skills
• Tools
• Mobile Connect
• Cloud Sync
• read-only wallet import by address
Links:
GitHub (App): github.com/okwn/OpenWall
GitHub (Bridge): github.com/okwn/OpenWall-Bri…
Website: openwall.okwn.cc/
The goal is simple: safer desktop wallet ops, clearer runtime visibility, and a cleaner architecture between UI, signing flows, and local wallet infrastructure.
Screen recording is attached to this post.
#OpenWall #OWS #Rust #Tauri #Crypto #Web3 #OpenSource
Apr 2

The first OWS Hackathon is Friday, April 3
Anyone can join, build, ship, and be eligible to win $30,000 in prizes
Show us what you can do: hackathon.openwallet.sh/
2
5
355
Mar 20
Not all patches warrant a CVE. This is the last thing I'll say in this matter.
2
75
Mar 20
It's not the difference in opinion. It's the escalation to GH staff, email, and now tweet. Really, what is your goal here?
1
2
60
Mar 20
It's the 2nd time I get harassed on Twitter this week to assign a CVE to a trivial bug that does not have a security impact, just for the security researcher's personal blog. Go away.
2
1
2
340

Mar 9
In early 2024, Microsoft engineer Andres Freundaccidentally thwarted one of the most sophisticated cyberattacks in history.
While testing an unstable version of Debian, he noticed a tiny 500ms delay in his SSH logins, a blip most people would ignore.
Curiosity led him to find a massive backdoor hidden in XZ Utils, a standard data compression tool used by almost every Linux server on the planet.
The deal here was :
The backdoor targeted the SSH protocol, which is the primary way admins securely log into remote servers.
If Freund hadn't spotted it, attackers would have gained a "master key" to bypass authentication and execute code with root privileges on billions of devices.
The culprit (under the name "Jia Tan") spent two years building trust in the open-source community, slowly gaining enough "cred" to become a project maintainer and plant the malicious code.
How It Was Resolved
Once Freund confirmed the malicious code, he emailed the Debian security team and went public on the Openwall mailing liston March 29, 2024.
Major Linux vendors like Red Hat, Fedora, and Debian immediately reverted to older, safe versions of the software.
GitHub quickly suspended the compromised accounts and disabled the affected repository to stop the spread.
A clean version (XZ Utils 5.6.2) was released in May 2024, effectively closing the vulnerability tracked as CVE-2024-3094.
Essentially, the internet was saved from a "digital apocalypse" because one guy was annoyed that his computer felt half a second too slow.
Mar 7

remember when Andres Freund basically saved the entire internet because he noticed a 200ms delay for his SSH login?
49
1,126
7,573
479,985

Mar 5
କୂଅରେ ପଡିଲା ଦନ୍ତା, ଉଦ୍ଧାର କାର୍ଯ୍ୟ ଜାରି | Elephant Falls in a Open Well | Keonjhar News | PrameyaNews7 #elephant #elephantrescue #openwall #keonjharnews #prameyanews7
131

Jan 21
GNU InetUtilsのtelnetdに、遠隔から認証を完全に回避してroot権限を取得できる重大な脆弱性が見つかった。細工した接続だけで侵入が成立し、外部公開環境では即時の対応が強く求められる深刻な問題であり、影響範囲も広く危険性が極めて高い状況だといえる。
問題はtelnetdが認証時に/usr/bin/loginを起動する際、リモートクライアントから渡されるUSER環境変数を無検証で引き渡す実装にある。攻撃者はUSERに「-f root」を含めることで、loginが認証省略フラグとして解釈し、パスワード確認を経ずにrootでログインできる。telnetの-aや--login指定を用いた接続で悪用が可能で、未認証の外部利用者でも即座に完全な権限を得る。脆弱性は2015年3月のコード変更で混入し、同年5月公開の1.9.3以降、2.7まで全ての版が影響を受ける。OpenWallはtelnetd利用環境の即時確認を呼びかけ、GNU開発者はtelnetdの無効化、信頼済み接続元への制限、修正パッチ適用を推奨している。
cybersecuritynews.com/gnu-in…
12
10
1,475

Jan 18
🕑 MongoDB admins should scan recent advisories. A high-severity flaw allows memory leakage that can slowly destabilize Linux systems. This is the kind of issue that shows up at 2 a.m. Fix it sooner #Linux #hacking #openwall bit.ly/3Yi4iq5

2
94
Jan 5
🔍 MongoDB admins should take note. A high-severity bug can cause memory leaks during certain operations, eventually impacting uptime. This is especially risky on long-lived Linux servers. Apply updates and verify behavior #Linux #hacking #openwall bit.ly/3Yi4iq5

1
2
143

17 Sep 2025
Strengthening Linux Security With Kernel Runtime Guard 🎯
#Linux security remains a pressing concern as vulnerabilities continue to expose critical systems.
@solardiz, founder of @Openwall, and senior principal security engineer at CIQ, said Linux Kernel Runtime Guard's, or LKRG, 1.0 release brought major improvements in testing and code cleanup.
Watch his full interview with @aseemjakhar: inforisktoday.com/strengthen…
#ISMGNews #ISMGStudio #cybersecurity #NullconBerlin2025 @nullcon
3
6
2,826

日本語記事きてた。わいわい / “初公開から7年、Openwall傘下のセキュリティモジュール「Linux Kernel Runtime Guard 1.0.0」がリリース ―既存のカーネルに後から適用、幅広いカーネル / ディストリビューションに対応 | gihyo.jp” htn.to/3XZQpFSYvw
1
3
1,235

Linux Daily Topics「初公開から7年、Openwall傘下のセキュリティモジュール「Linux Kernel Runtime Guard 1.0.0」がリリース ―既存のカーネルに後から適用、幅広いカーネル / ディストリビューションに対応」公開
gihyo.jp/article/2025/09/dai…
1
5
1,028