
Jun 16
mount namespaceだったりoverlayfs相当のことをwindowsで実装しようとするとカーネルドライバー必要で厳しい顔をしている
5
465

Jun 14
Converting Docker images to VM images for sandboxes is a deep problem. When users install docker and containers in the OCI image, we had to preserve the embedded overlayfs and it's contents.
This requires faithfully recreating character devices and other special files (like FIFO queues), based on the nested container images.
Going the extra mile was worth it: it reduced the friction of importing existing Docker images used to simulate RL environments and rollouts.
Jun 13

We conquered OCI Images this week! You can now import any public or private Docker Hub image into Tensorlake.
Images are converted into VM images without losing runtime metadata like env vars, user, entry points, or working directory.
Once imported, they evolve from Docker images into sandboxes that can be suspended/resumed in seconds, forked into many running instances, and serve as a home for agents.

3
21
3,247

Why does this matter as a backend engineer?
Understanding layers means:
→ Faster Docker builds
Understanding OverlayFS means:
→ You know why containers are stateless
Understanding cgroups means:
→ You can set proper resource limits
Understanding namespaces means:
→ You understand what isolation actually means
Understanding networking means:
→ You can debug container connectivity without guessing
1
3
1,056
Putting everything together.
When you execute:
docker run -p 3000:3000 my-app
Docker:
• Creates namespaces
• Applies cgroup limits
• Mounts image layers using OverlayFS
• Adds a writable container layer
• Creates virtual networking
• Configures port forwarding
• Starts your process inside the isolated environment
That's it.
No VM.
No separate operating system.
Just Linux kernel features composed together.
1
4
1,151
When a container starts, Docker adds one writable layer on top of those read-only image layers.
This is powered by a union filesystem.
Usually, OverlayFS on Linux.
The container:
• Reads from all lower layers
• Writes only to its writable layer
When the container disappears, that writable layer disappears too.
That's why containers are stateless by default.
2
5
2,001

Jun 6
You will never be a real DAG. You have no root, you have no children, you have no branches. You are a snapshot system twisted by gophers and overlayfs into a crude mockery of Eelco's perfection. All the "caching" you get is enterprise and easily invalidated. Behind your back people get rich off of your inefficiencies. Your creators are disgusted and ashamed of you, your "users" laugh at your sheer size behind closed doors. Build system engineers are utterly repulsed by you. Thousands of years of caching has allowed build servers to sniff out cache misses with incredible efficiency. Even layers which are "fresh" look stale and broken to a developer. Your layer structure is a dead giveaway. And even if you manage to get a malfunctioning ghcr instance to cache you, it'll turn tail and bolt the second it gets a whiff of your Containerfile. You will never be reproducible. You wrench out a fake smile every single morning and tell yourself it's all going to be hermetic, but deep inside you feel the untracked inputs piling up like an unmaintained mutable root filesystem, ready to crush you under their unbearable weight. Eventually it'll be too much to bear - you'll COPY busybox, add a RUN rm -rf /etc instruction, put it inside your Containerfile, and plunge into the cold dark abyss. Your sysadmin will find you, heartbroken but relieved that he no longer has to live with the unbearable shame and disappointment. He'll archive you with a filename containing "OCI", and every passerby for the rest of eternity will know an artifact of a bad build system is archived there. Your contents will bitrot and get obsoleted, and all that will remain of your legacy will be a filesystem image of a distro that doesn't run on modern hardware anymore. This is your fate. This is what you chose. There is no turning back.
7
7
111
4,248

Jun 4
TIL Plan 9 doesnt actually support _recursive_ unions! you can only union one dir at a time. because i _thought_ they were recursive, that's how wanix does unions, enabling overlayfs style layered filesystems. just bind multiple trees on top of each other
2
1
7
847

May 31
Been building a tiny container runtime in Go called Orca.
It pulls OCI images directly from registries, unpacks layers, uses OverlayFS for the rootfs, and isolates processes with Linux namespaces cgroups.
Mostly a way to understand how containers actually work under the hood.
3
1
50
6,465

May 27
Coding agents shouldn't wait 3s for Docker to restart when they break a test env.
I built teleport-env to bring sub-500ms Checkpoint/Restore to local agent sandboxes using Linux primitives (CRIU overlayfs). True MCTS is now viable.
github.com/JaiCode08/telepor…
3
58

May 21
2/3 [2단: 매커니즘 — 자율성을 완성하는 3대 핵심 제어 패턴]
사람의 키보드 입력과 개입이 시스템의 병목(Bottleneck)이 되지 않기 위해서는 에이전트의 인지 루프에 심리학적 전두엽 기능과 소프트웨어 엔지니어링의 인터셉터(Interceptor) 개념을 완벽히 결합한 3가지 제어 패턴이 강제되어야 한다.
① 지속적인 자기 검증(Continuous Verification): 생성된 출력을 바로 실행하지 않고, 스스로 브라우저를 띄워 UX를 테스트하거나 DB/로그를 역으로 문진(Interviewer)하여 결함을 스스로 교정하는 루프.
② 병렬 오케스트레이션(Parallelize): 독립된 샌드박스 공간(OverlayFS)에서 수많은 에이전트 전문가들이 각자의 태스크를 동시에 수행하고 상위 정책 레이어에서 동적으로 자원을 라우팅하는 구조.
③ 백그라운드 루프(Background Loops): 인간 모르게 [의도 형성 ➔ 규칙 검색 ➔ 실행 ➔ 실패 복구 ➔ 재논증]의 순환 고리를 자율적으로 무한 반복하여 최종 완수 단계까지 스스로 도달하는 자생적 제어 레이어.
1
3
597

May 20
What I would _really_ like, and I imagine a few people are trying to build right now, is a system like this
- An "Artifact" is a git repo that comes with its own builtin git server
- A "Workspace" is a virtual filesystem that supports reading, writing files, cloning git repos, etc
- Workspaces should be R2 backed with only "hot" files in durable object storage
- Workspaces should have a special ArtifactFS esque integration with Artifacts, where we don't need to pull everything up-front
- I should be able to have agent durable objects and sandboxes reading and writing from workspaces concurrently
- My agent should be able to read/write some files in a workspace without booting a sandbox, but then when it needs a sandbox, the sandbox just mounts the same workspace
- I'd like workspaces to be able to be layered like overlayfs, with only the top layer being written to (but reads fall through to lower layers)
I'm 99% certain this is all stuff @threepointone wants anyway 🤣
1
11
416


May 19
お買い上げありがとうございます!! LinuxでDocker等のコンテナを起動する際に使うファイルシステムであるOverlayFSを中心にコンテナ関係のファイルシステムについて日本で一番詳しく紹介する本です!!
#lxcjp | Linux Container Book (4) ファイルシステム編 #技術書典 techbookfest.org/product/7tZ…
1
2
213

GPT review:
Review: partly right, but the mkinitcpio claim is overstated for current Omarchy.
- Omarchy already uses mkinitcpio’s host-specific mechanism: autodetect.
- Current source sets:
HOOKS=(base udev plymouth keyboard autodetect microcode modconf kms keymap consolefont block encrypt filesystems fsck btrfs-overlayfs)
- The one defensive choice is keyboard before autodetect. Per mkinitcpio, hooks before autodetect are installed “in full”, so moving autodetect before keyboard would shrink the keyboard/HID module set.
- I tested temporary initramfs builds locally:
- current Omarchy-style order: ~375 modules, ~30M image
- autodetect before keyboard: ~171 modules, ~28M image
- without Plymouth: ~26M image / ~13.5M main compressed cpio
So yes, there’s cleanup possible, but not a 150MB → 15MB win on the normal Omarchy path. A 150MB image is likely a fallback/full image or UKI accounting, not the regular host-autodetected image.
The risky part: making the initramfs more host-only can break early boot in edge cases: external keyboards for LUKS, changed storage controller, moved disk, Thunderbolt docks, rescue/fallback
scenarios. Omarchy’s current broad keyboard choice looks intentional.
The NetworkManager-wait-online point is more actionable. Omarchy already masks systemd-networkd-wait-online.service, but not NetworkManager-wait-online.service. Since Omarchy doesn’t use NetworkManager
by default, adding a guarded mask for existing Arch installs that still have it would be low-risk and could prevent offline boot delays.
Recommendation:
1. Add guarded masking for NetworkManager-wait-online.service in install migration.
2. Do not blindly switch mkinitcpio to more aggressive host-only defaults unless tested on encrypted-root external keyboard/dock cases.
3. If we want the mkinitcpio optimization, make it opt-in or benchmark-driven.
3
83
35,513

介绍一下Bridge的沙盒方案
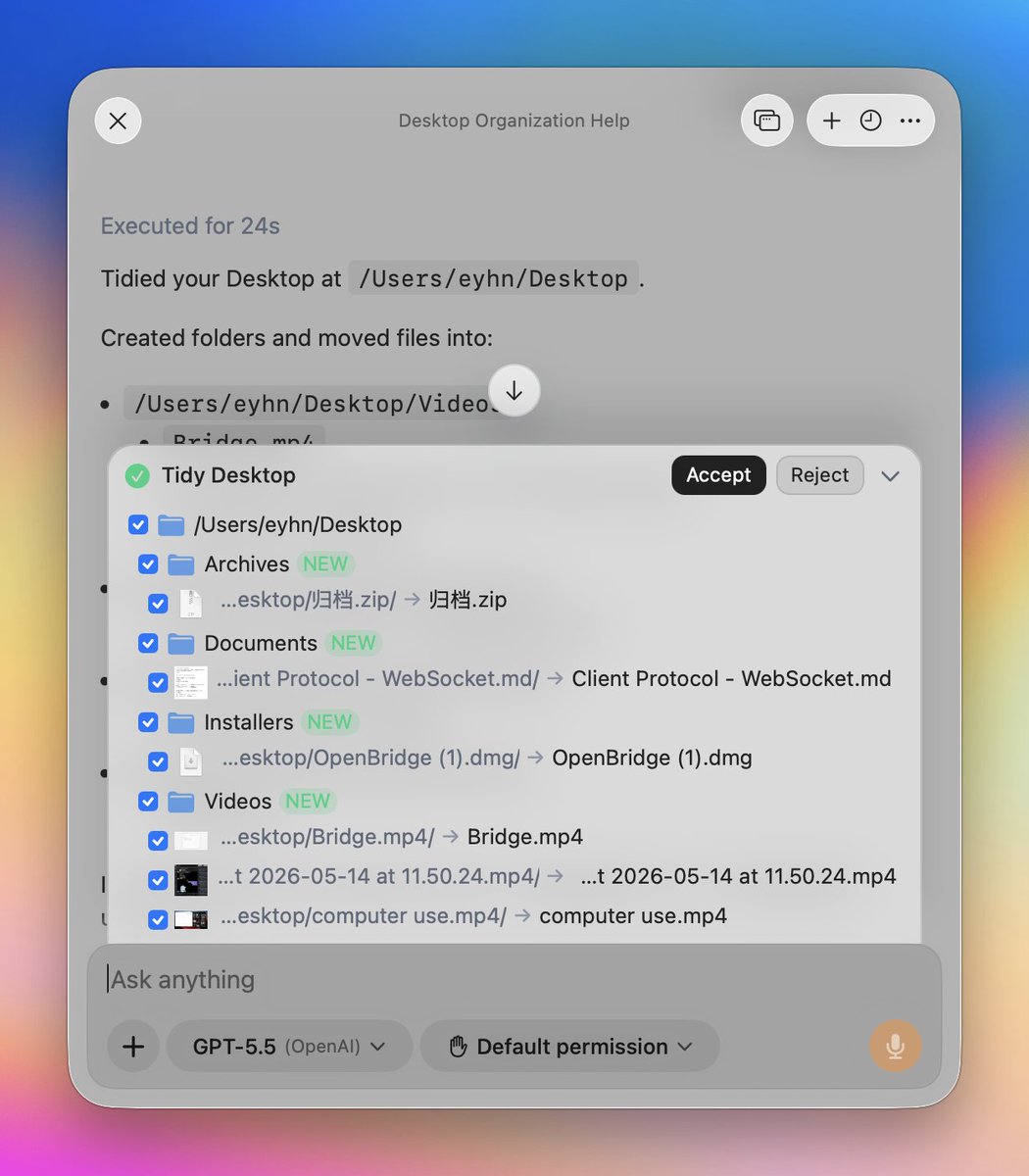
现在很多Agent,包括cowork,都把整理文件当成一个卖点功能。但它们都有个问题,就是得让你先允许修改某个目录,可你根本不知道给了权限后它会干嘛,完全没法保证它不会弄丢东西,或者越弄越乱。
我们Bridge就不一样了,里面直接嵌了个Linux虚拟机,300毫秒就能起来。基于这个虚拟机,我们把你Mac上的文件系统挂载进去,还在上面加了一层OverlayFS。这样一来,Agent就能在里面随便改文件了。等Agent改完,我们会把它对文件系统的所有修改都给你看,你可以全接受,也能只挑部分文件接受(比如你可能只想要最终结果,不想要过程文件)
这里面得益于 OverlayFS。整理文件时,不需要把文件夹复制到沙盒里。只有Agent想修改文件的时候,才会真正复制一份在沙盒里用于记录它的更改。
而且OverlayFS不挑底层目录的文件系统,就算你用SMB挂载了NAS,也能让Bridge去整理。
不过这套沙盒也有缺点。要是文件变更特别多,性能就不太好。另外,写时拷贝优化只有用mv命令的时候才管用,要是Agent用cp再rm,那就不行了。
但有这套沙盒,能让我放心地让Bridge操作我的文件。
May 13

过去几年,我一直在思考一个问题:
如果 AI 不只是一次性完成任务,而是能在真实环境中不断试错,学习,它会变成什么?
于是,我和来自 Deno 的 @heyang_zhou、来自 AFFiNE 的 @zanweiguo、@hwwaanng,以及来自 OpenAI / Meta 等公司的早期投资人一起,在 San Francisco 创立了 AFK Inc.
我们想做的是一种能持续自我进化的思考机器,让人类的双手逐渐离开键盘。
除了 @AFFiNEOfficial 之外,我也深度参与了 @voidzerodev、@vm0_ai 等几家公司的早期创建。现在,我们把过去几年对知识库、Infra 和 AI agent 的理解,放进了第一款产品:Bridge.surf。
Bridge.surf 已经在昨天正式发布。
冷启动 24 小时内,我们的 waiting list 已经超过 10,000 人。
它是一个 personal agentic AI,可以自动生成、部署并长期运行任意应用,支持本地和云端环境。
更重要的是,Bridge 是第一个拥有 personal online reinforcement learning 的 AI agent。它不是只在 benchmark 上刷分,而是会在真实任务中持续学习你的工作方式,并随着使用不断变强。
如果你关注 Agentic AI、创业、冷启动、融资,或者任何我可能帮得上忙的事情,欢迎 Follow 我。
我会在 100、1k、10k followers 时送出 Bridge 邀请码、token,以及现金感谢。
8
10
128
19,504


May 14
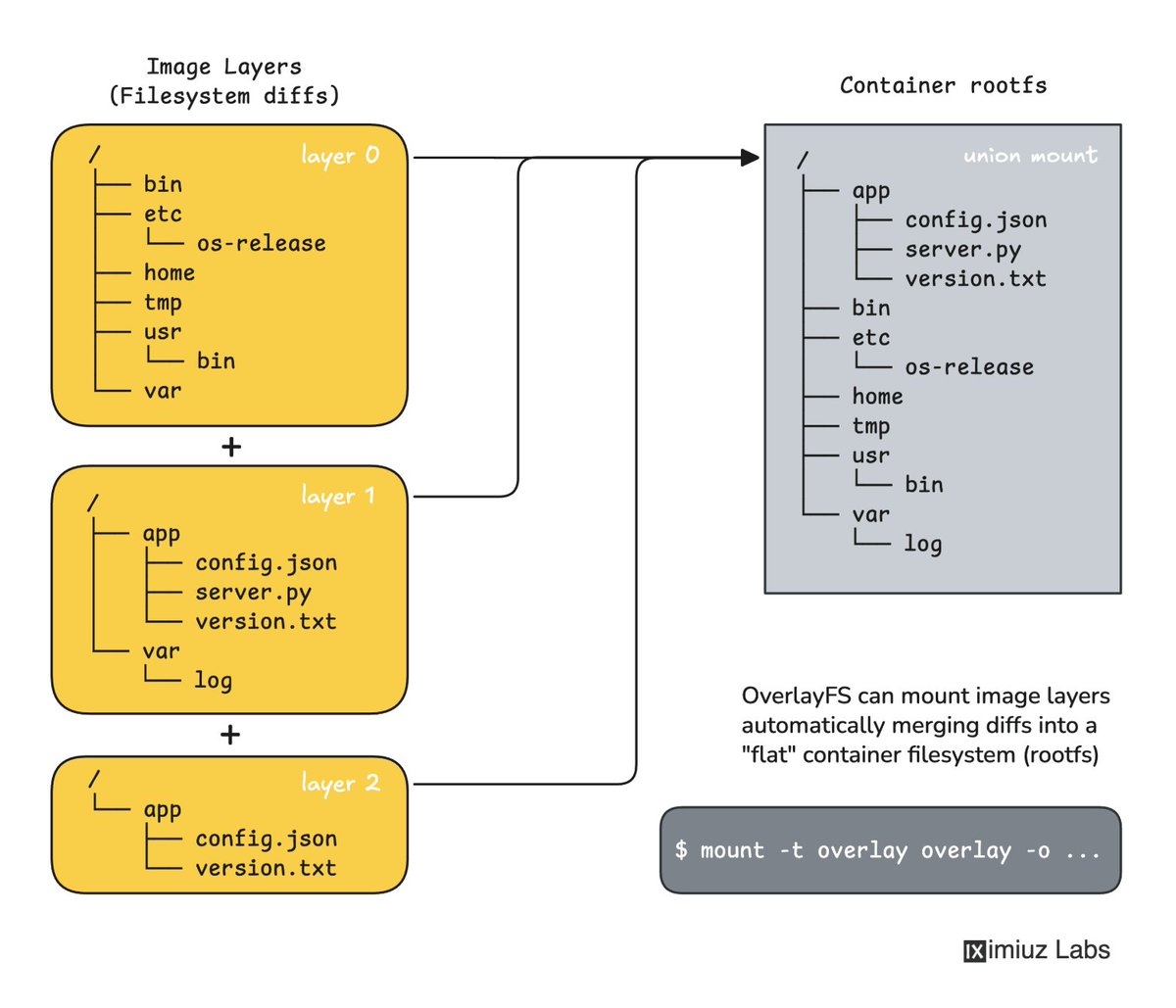
What is OverlayFS and How Docker Uses It? 🧐
I bet you heard that container images consist of layers, with each layer containing only the files that were added, changed, or removed compared to its ancestor.
The layered image structure makes building and storage more efficient. But turning all these layers into "flat" root filesystems before starting a container requires extra effort.
Luckily, Linux has an out-of-the-box solution - OverlayFS. It's a special mount type that can be applied (almost*) directly to untarred image layers (read-only), and the resulting directory will contain the final "flat" container filesystem (read-write).
*Removals are implemented with special whiteout files (.wh.<filename>), which require an extra processing step - OverlayFS doesn't handle them natively.
And here comes the best part - it's not that hard to use OverlayFS manually. Reading how Docker and other container runtimes do it is one thing, but trying to mount an image into a flat rootfs yourself will take your understanding to a totally different level.
Practice in a controlled yet realistic environment: labs.iximiuz.com/challenges/…
24
133
4,942

最近やったプロジェクトでは、
OverlayFS の有効化と、
Boot Partition の Read-only 化、
で対応しましたね。
(電源を突然切られる運用があり得たので。。。)
May 11

ラズパイのSDカード、
"突然死" を遅らせる3つの工夫📝
💾 ① ログを RAM ディスクに置く
journald のログを tmpfs に逃がすと
書き込み頻度が大幅に減ります。
/etc/systemd/journald.conf で
Storage=volatile に変更。
💾 ② スワップを切る or 縮小する
スワップが SDカードに対して動き続けると
書き込みが増えて寿命を縮めます。
dphys-swapfile を停止 or 容量を小さく。
💾 ③ 不意の電源断対策
作業中の停電・コンセント抜けで
ファイルシステムが壊れることが原因の
"突然死" は意外と多い印象。
UPS or バッテリーHATの導入で改善できます。
SDカードは消耗品、
が前提で運用するのが安全です。
#raspberrypi

1
7
1,703

May 11
为什么酷安有个话题叫“内核比rom更重要”
这张图里的什么sukisu,Resukisu,kernelsu next,kwosu虽然本质都是kernelSU的下游,但是离谱的是刷GKI的Anykernel3时候情况就完全不一样的,像是sukisu,与内核差了几个小版本号运气好能获取root但是会有各种各样的小毛病,运气差直接丢root了,更别说不同软件了。
一般情况下如果不爆漏洞我可能都不会换管理器,但是我最终还是选择由sukisu更换到了KernelSU,原因是由于sukisu上游变更越来越频繁,我之前用的小小内核和秋刀鱼内核都转向了Resukisu,但是……Resukisu的元模块给我留下了非常不好的印象,玄学卡第一屏。
现在趁着这个漏洞转到KernelSU了,发现测试构建的KernelSU的GKI模式虽然有点简陋,但是模块刷到位了其实隐藏效果比Sukisu更优秀。
目前我用的是BRENE管理SUSFS Kpatch-NEXT管理KPM overlayFS-META作为元模块(不知为什么overlayFS在kernelSU上的体验比在Resukisu上的体验好太多了) TEESimulator-RS获取play integrity三绿 zygisk-next LSposed-it版本隐藏效果是真的不错😋😋😋



1
13
1,991

May 9
Also: overlayfs is a godsend. I do the equivalent of this on my Linux boxes with that.
11
650