
Check the one made by PolyBlocks!
youtu.be/97G9BS8lzkM
1
3
7
233

Mar 10
Finally, here's the paper on PolyBlocks describing how fully code-generating compilers for AI chips can be built! This is the culmination of multiple years of R&D and engineering. There is now enough reusable infrastructure in our toolkit to quickly build high-performing PyTorch/JAX compilers for new chips, no matter how weird or unique their capabilities are, and without relying on any "kernel" libraries or manual model optimization or porting. The paper isn't exhaustive, but it provides details on the key parts, the design choices, and why they are powerful.
arxiv.org/abs/2603.06731
2
18
86
5,666
Jan 12
Polymage's PolyBlocks engine enables the rapid development of compilers for new AI chips, extracting close-to-peak performance from hardware, and realizing high-performance AI systems for vision, text, generative AI, and more. Highly promising results here from Polymage's collaboration with @tenstorrent --- showing that the right compiler technology can be a leapfrog advance to the programming ecosystem for new chips!
More details: docs.polymagelabs.com/articl…
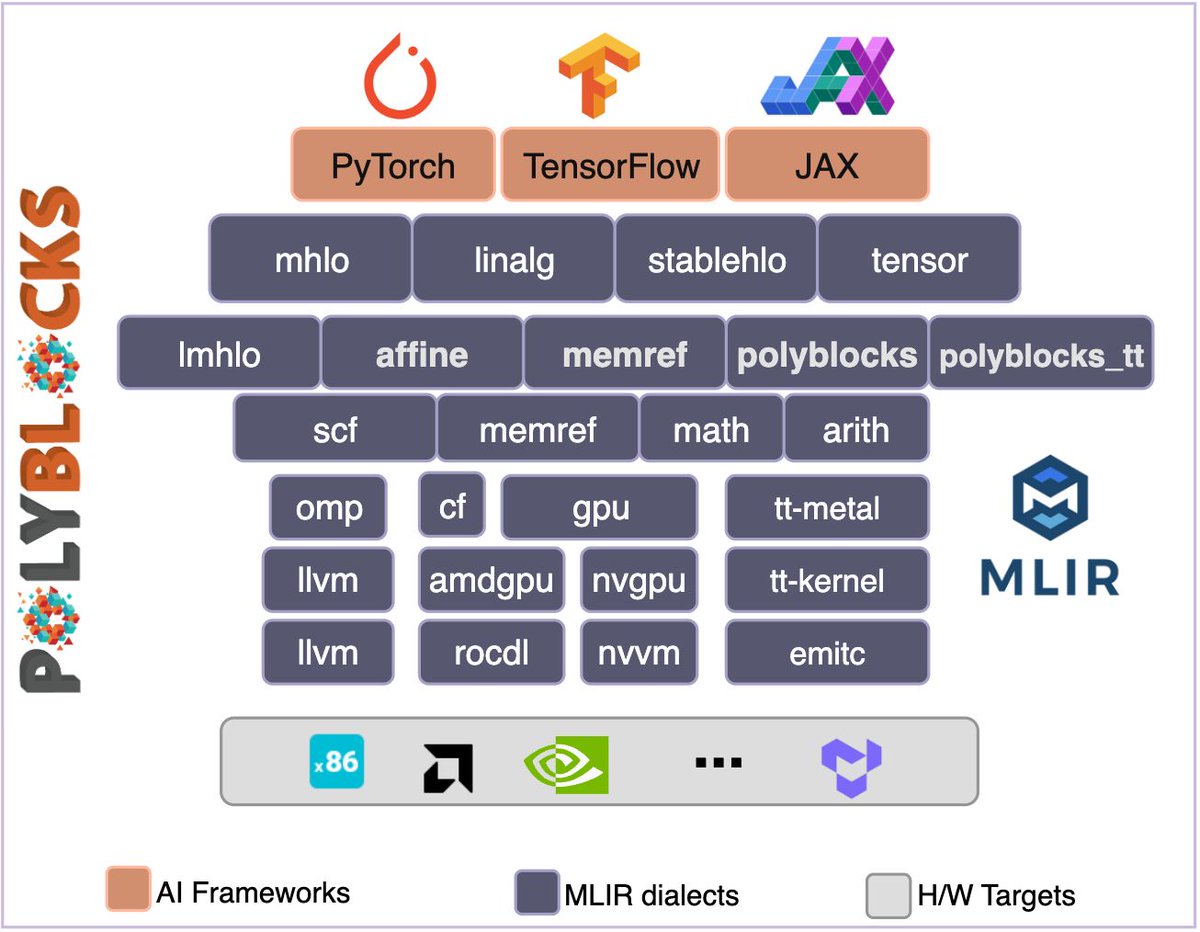
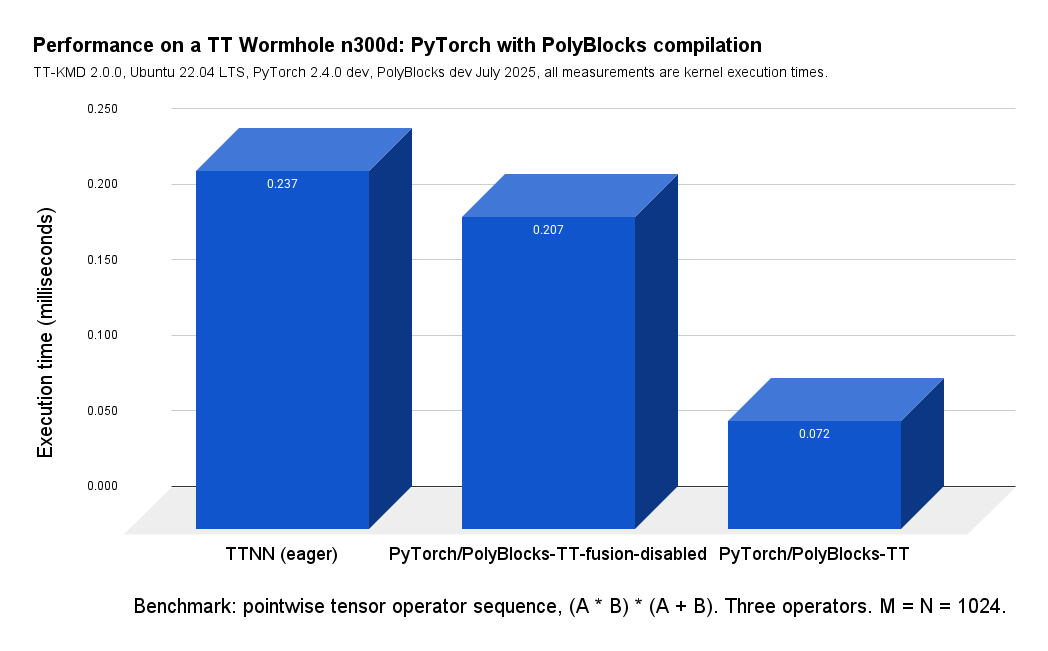
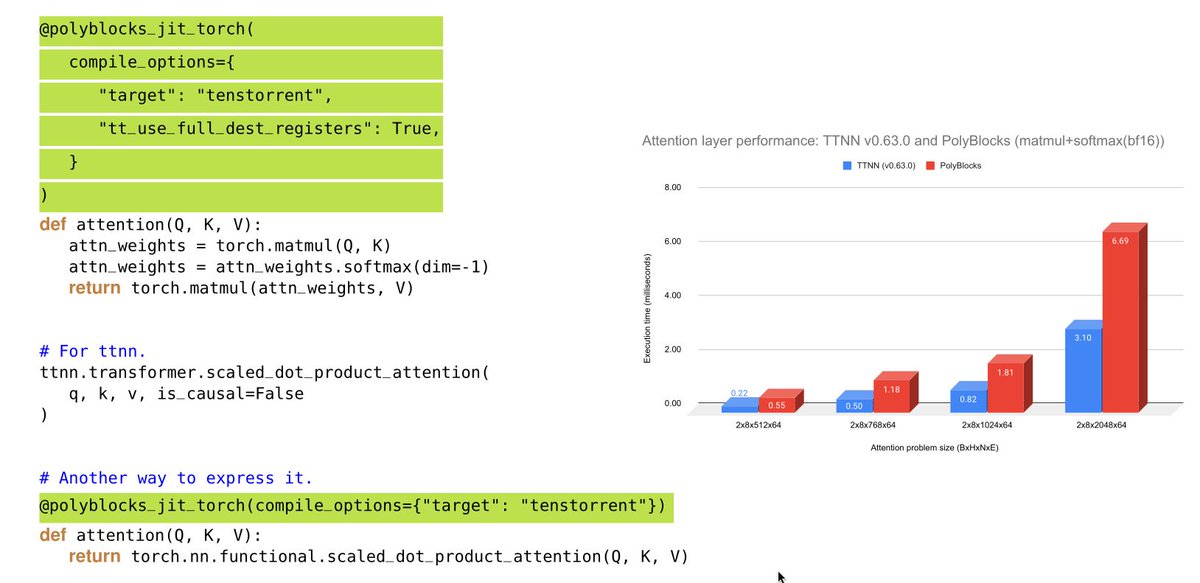

4
12
486


29 Aug 2025
With constant improvements in its optimization passes, PolyBlocks-generated code continues to get better! We compare here against all other state-of-the-art production PyTorch backends on a variety of workloads, including transformer-based and convolution-based ones. The latest round of improvements comes from more/better unroll-and-jam, more fusion across operators, simplifying away invariant computation, and wider use of on-chip memory.
The impact of such compiler technology would be even greater for new hardware that doesn't yet have a well-established library/programming ecosystem.
More info: docs.polymagelabs.com
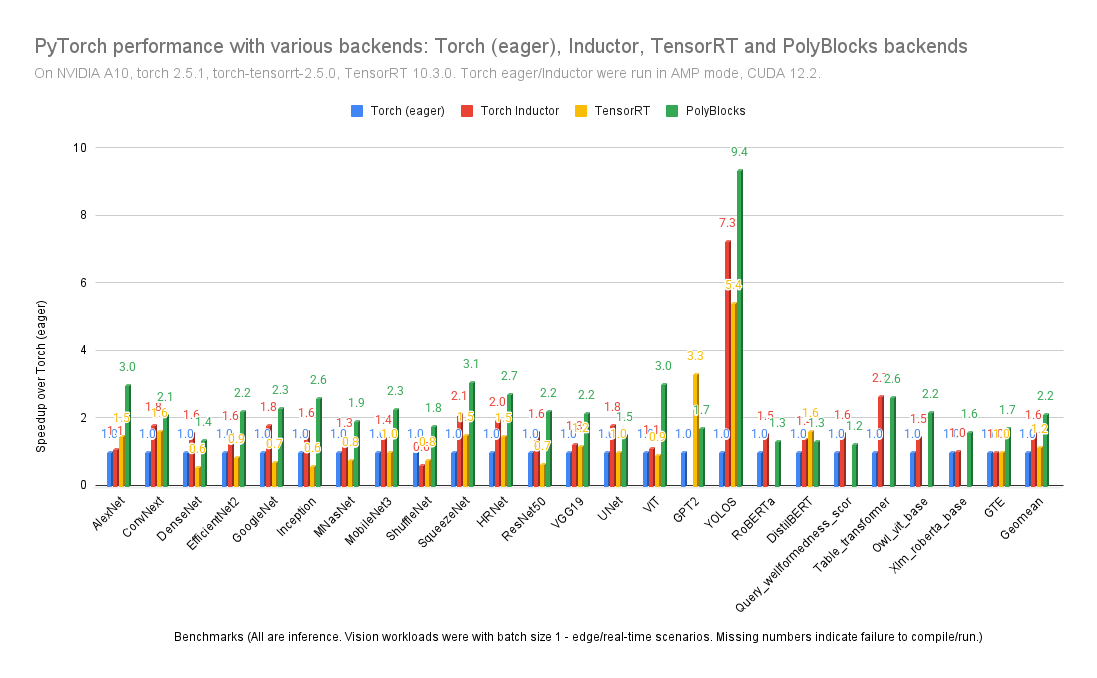
2
4
16
985
23 Jun 2025
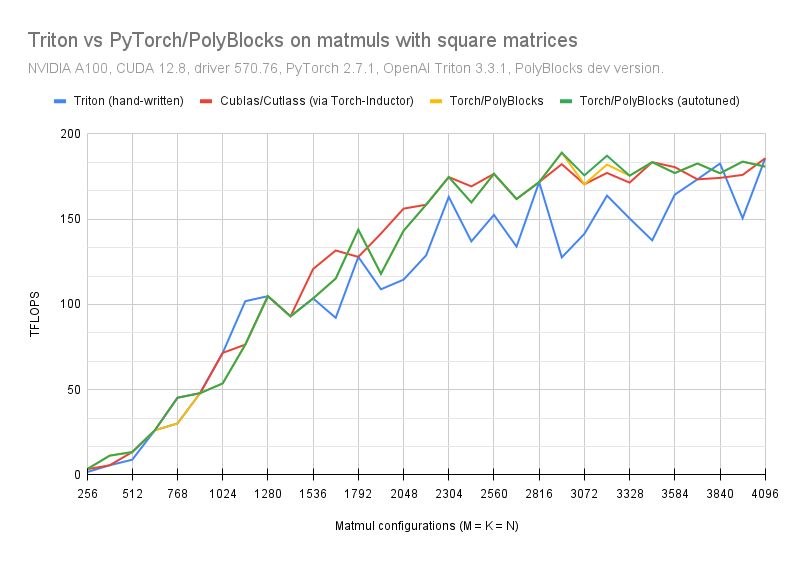
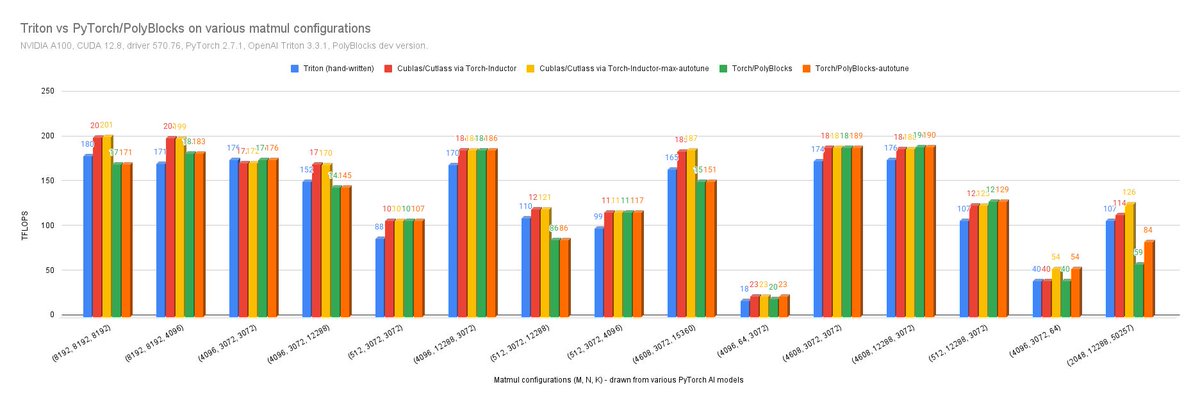
Programming and compiling for AI hardware happen today through multiple approaches, but they broadly fall into low-level, mid-level, and high-level ones. (1) Low-level is based on hand-written kernels (CUDA, CUTLASS, assembly/PTX, similar) on which the default execution engines of AI frameworks (eager-mode) are built; (2) mid-level is mostly OpenAI Triton, Pallas, and cuTile (announced); and (3) high-level ones, which are compilers for PyTorch/JAX/TF functions, e.g. Inductor, XLA, and PolyBlocks. One would stop building low-level libraries/kernels if mid-level ones (e.g. Triton) delivered good/comparable performance; similarly, one would stop relying on hand-written mid-level if high-level compilers delivered comparable performance. Results here compare the high-level fully automatic approach of PyTorch-PolyBlocks against OpenAI Triton and against lower-level kernels (CuBLAS) on an NVIDIA GPU.
While Inductor is an automatic compiler, it still relies on a combination of low-level (e.g. cublas/cutlass kernels) and mid-level frameworks (Triton); for matmul, perhaps exclusively cublas/cutlass (so no code generation).
For Triton, the implementation used was from triton-lang.org/main/getting…
Results here show high performance can be achieved with compact/productive programming if compilers are built right!
Know more: docs.polymagelabs.com

6
16
963

30 May 2025
Godot Visual Effects v2 is out now!
Download: bukkbeek.itch.io/effectblock…
Watch: youtu.be/svPZOkWt0Z4?si=NYB4…
#vfx #shader & particle #effects - #fire #explosion #magic and more!!
Follow | Share
#indie #blender #godot #3d #lowpoly #stylized #gameart #gamedev #indiedev #PolyBlocks
9
191
30 Jan 2025
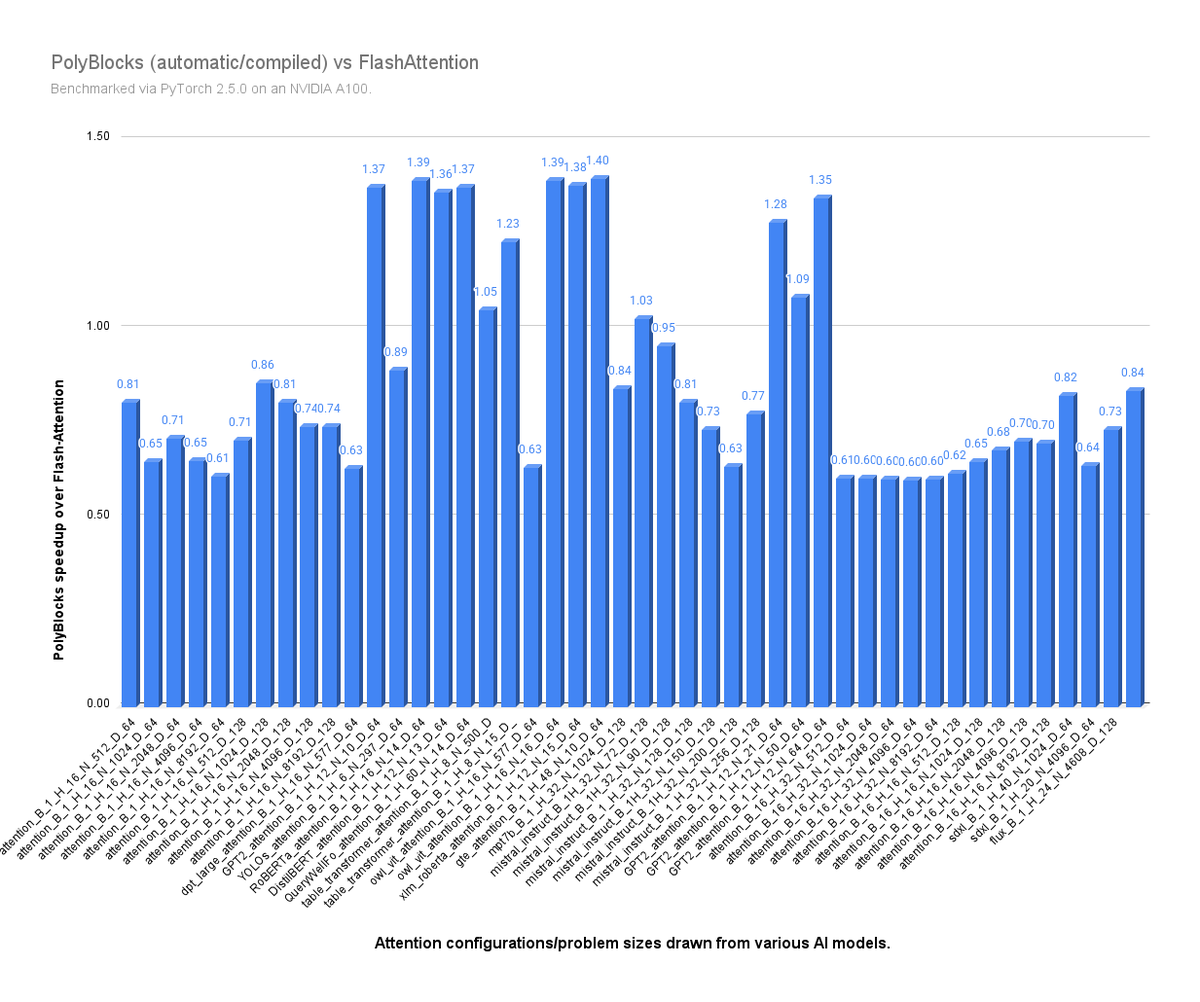
Automatically generated code from PyTorch-PolyBlocks is now 1.3 to 1.4x as fast as hand-written FlashAttention kernels in several cases! At 85% of Flash-Attention performance overall (geomean) across 45 diverse attention layer problem sizes/configurations drawn from numerous state-of-the-art AI models!
Results below are with PyTorch 2.5 on an NVIDIA A100. (FlashAttention was benchmarked via Torch Inductor.)
More info: docs.polymagelabs.com
#compiler #ai #polyblocks
3
8
1,347
23 Jan 2025
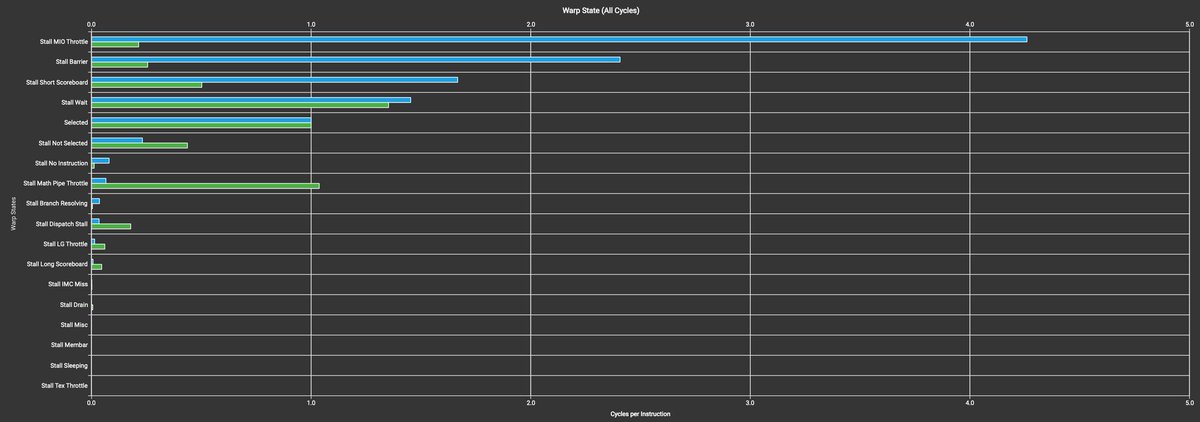
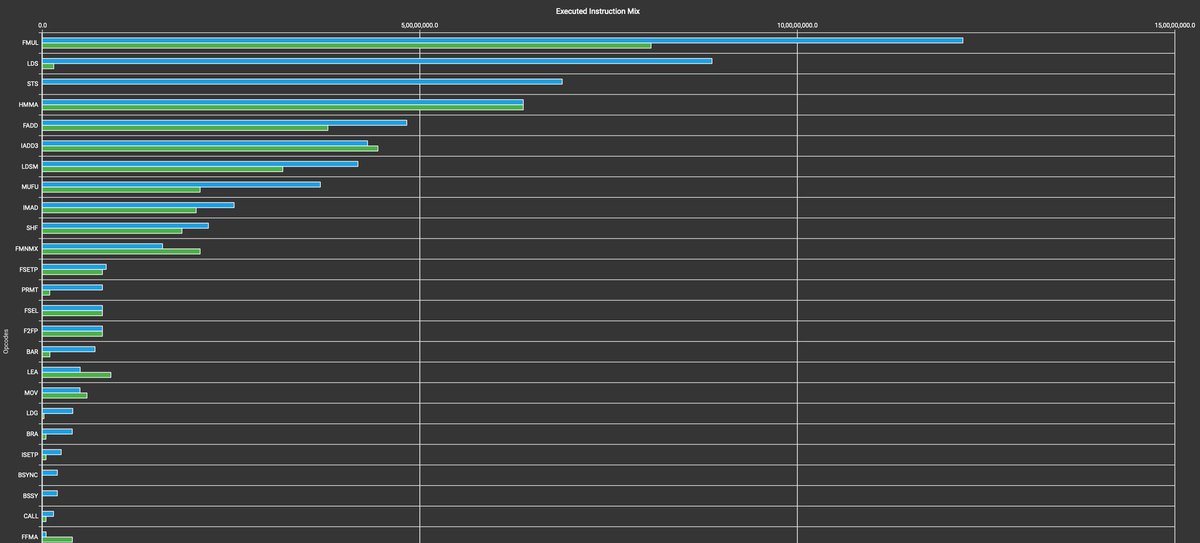
Optimizing computations for memory hierarchies (caches, explicitly addressed on-chip memory, and registers) has been an art since superscalar processors became popular in the 90s. Some of the most important computations today are optimized for multiple levels of cache and fast memories all the way up to register files. We show how important the last step of optimizing for register reuse is even after you've optimized everything greatly for on-chip memory, in this case, NVIDIA GPUs' shared memory scratchpads. Results below show the amount of improvement gained by eliminating back-and-forth transfers to shared memory by reusing data in the registers (for all but for the true input and output). This evaluation is done for "attention" layer computations drawn from various AI workloads; these computations are at the heart of all transformer-based networks, LLMs and auto-regressive models in general.
The comparison here is between already optimized/fused attention layer code generated by the PyTorch/PolyBlocks compiler with and without WMMA register-level fusion on an NVIDIA A100 - something we can do by turning on/off an optimization flag. On an absolute scale, PolyBlocks compiler-generated code here is at ~80% of hand-written flash-attention-kernel-based performance (measured via Torch inductor), geomean across 26 diverse/assorted attention workloads).
More information: docs.polymagelabs.com

1
6
11
526
10 Dec 2024
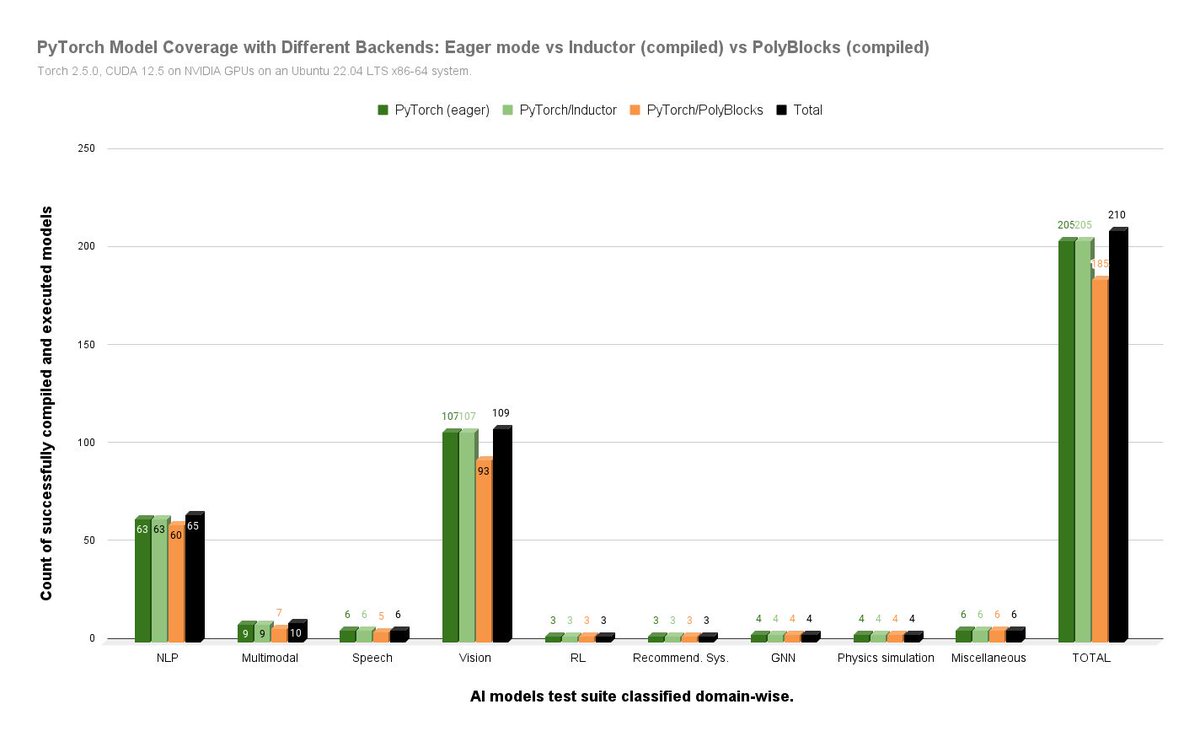
While we've posted in the past on PolyBlocks performance, we now report its coverage on all the 210 PyTorch models recently used in the evaluation of the PyTorch-2 paper from ASPLOS 2024 (pytorch.org/assets/pytorch2-…). These benchmarks are publicly available and drawn from HuggingFace, TIMM, and TorchBench suites. PolyBlocks can successfully compile and execute 185 of these 210 models (push button, no source changes)! These models span various AI domains with some containing nearly 25,000 tensor operators. 90% of the models that run with PyTorch's standard runtime or compiler work with PolyBlocks!
Benchmarks courtesy: github.com/pytorch/pytorch/t…
6
13
826
13 Nov 2024
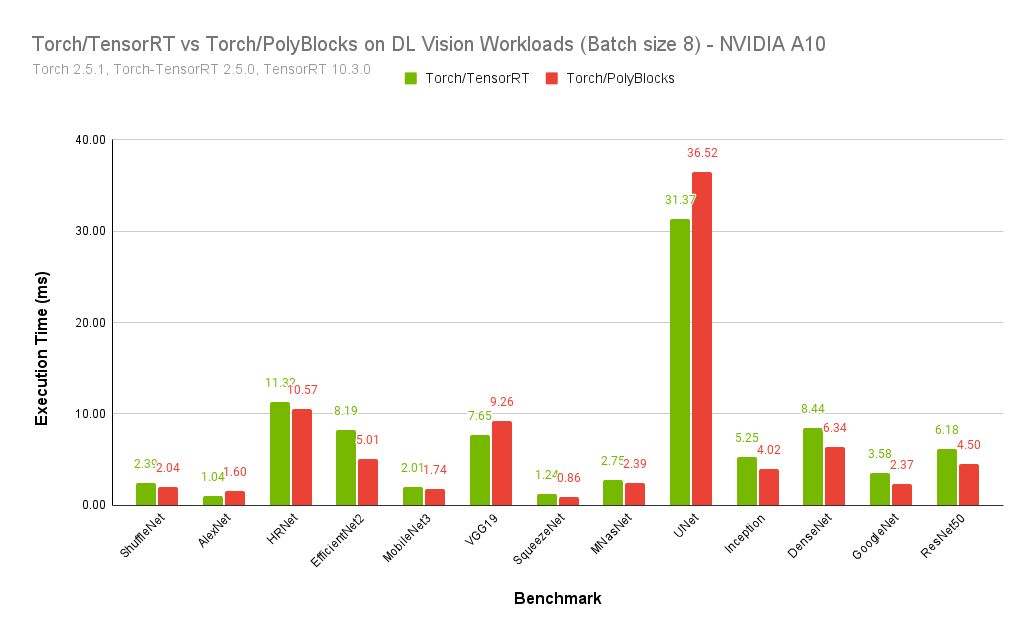
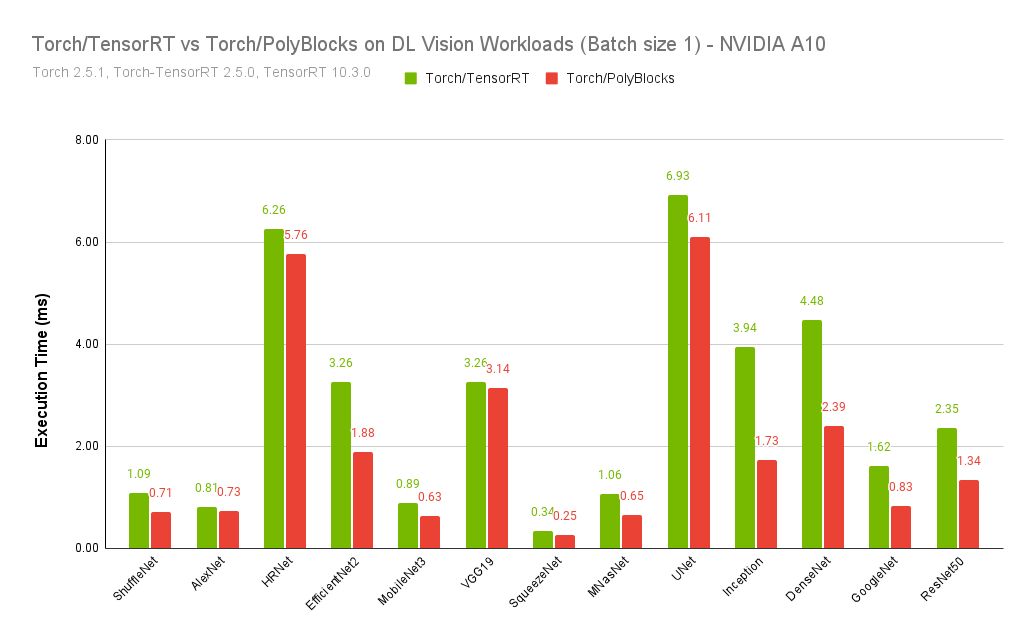
For PyTorch, PolyBlocks is now consistently and significantly faster than NVIDIA TensorRT on various AI vision workloads!
The PolyBlocks compiler engine recently switched from solely relying on WMMA operations to MMA (these determine how the matmul cores are programmed on NVIDIA GPUs). With this and other improvements, the PyTorch/PolyBlocks compiler consistently beats TensorRT (a state-of-the-art inference engine/compiler employing expert-written kernels) on a variety of deep learning vision models from TorchVision and HuggingFace - by an average of 1.5x and up to 2.3x as fast. Benefits come from better fusion of operators and better-generated code for the convolution operators in several cases.
PolyBlocks can be simply used with:
torch.compile(func, backend="polyblocks")
Try it out on the Polymage playground!
playground.polymagelabs.com
Docs: docs.polymagelabs.com
4
13
793
22 Oct 2024
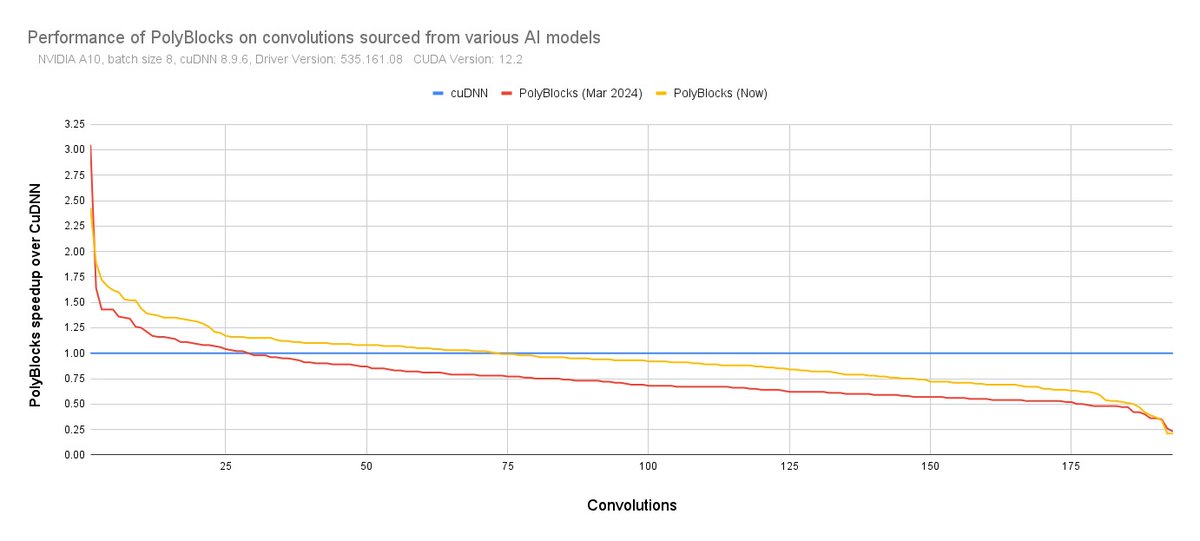
The PolyBlocks compiler generates all its code through MLIR, LLVM, and PTX, and we compare it here against the NVIDIA CuDNN library on ~200 assorted deep learning convolution configurations drawn from various popular models (mainly vision). CuDNN is expected to be hand-written by NVIDIA experts in GPU assembly and CUDA.
PolyBlocks compiled code is:
1. faster than CuDNN on 73/193 convolutions.
2. provides more than 10% improvement on 43/193 convolutions.
3. within 25% of CuDNN on 147/193 convolutions.
4. within 2x of CuDNN performance on 186/193 convolutions.
The performance of automatically generated code benefits from continuous improvements, avoiding specific library maintenance issues arising from the cross-product of multiple versions of kernels tuned for buckets of problem sizes x hardware.
More info: docs.polymagelabs.com
7
18
961

28 Sep 2024
Prof. Uday (@ukrb84) from #PolyMageLabs is sharing all the crazy things that goes inside PolyBlocks.
#Keynote #IICT
1
2
6
210
22 Aug 2024
PolyBlocks-compiled PyTorch model on an NVIDIA Jetson Orin Nano (embedded system), executing DETR (transformer-based object detection) on every video frame: 20x as fast as anything else that worked out of the box!
youtube.com/watch?v=ei9zNbyT…
3
8
593
20 Aug 2024
PolyBlocks can now compile out of the box for an edge AI device as well—in this case, an NVIDIA Jetson Orin Nano (Arm64 integrated NVIDIA GPU). A couple of large HuggingFace models benchmarked here!
- About 2x as fast as Torch 2.4.0 (eager) on DETR (Detection transformer for object detection) and YOLOS.
- Can generate a native binary for ARM64 integrated GPU in PolyBlocks AOT mode
In action on a video: youtube.com/watch?v=ei9zNbyT…
Acks: Thanks to 'dusty-nv' github.com/dusty-nv for the PyTorch 2.4.0 CUDA 12.2 wheel for Jetson.


4
18
1,014
31 Jul 2024
Compiler systems for Python-based AI frameworks typically defer lower-level optimizations to LLVM, which uses a low-level representation (closer to assembly than higher-order constructs); these systems include XLA, Halide, and Torch Inductor/Triton. OTOH, using MLIR allows one to perform even lower-level optimizations (like unrolling and reordering innermost loop operations) more effectively since the compiler can see through the memory accesses better than with "pointer offset" abstraction used by LLVM. One can also make a good tradeoff with parallelism available since both loops and multi-dimensional arrays are first-class concepts in MLIR.
With some lower-level opts now implemented in MLIR-based PolyBlocks, PolyBlocks' performance is even better - JAX/PolyBlocks is more than 3x as fast as JAX/XLA on several multi-head attention computations (esp. longer context lengths). (These results can be compared with those posted on the same sizes two weeks ago without additional lower-level opts.)
More info on PolyBlocks: docs.polymagelabs.com
#compiler #ai

16 Jul 2024

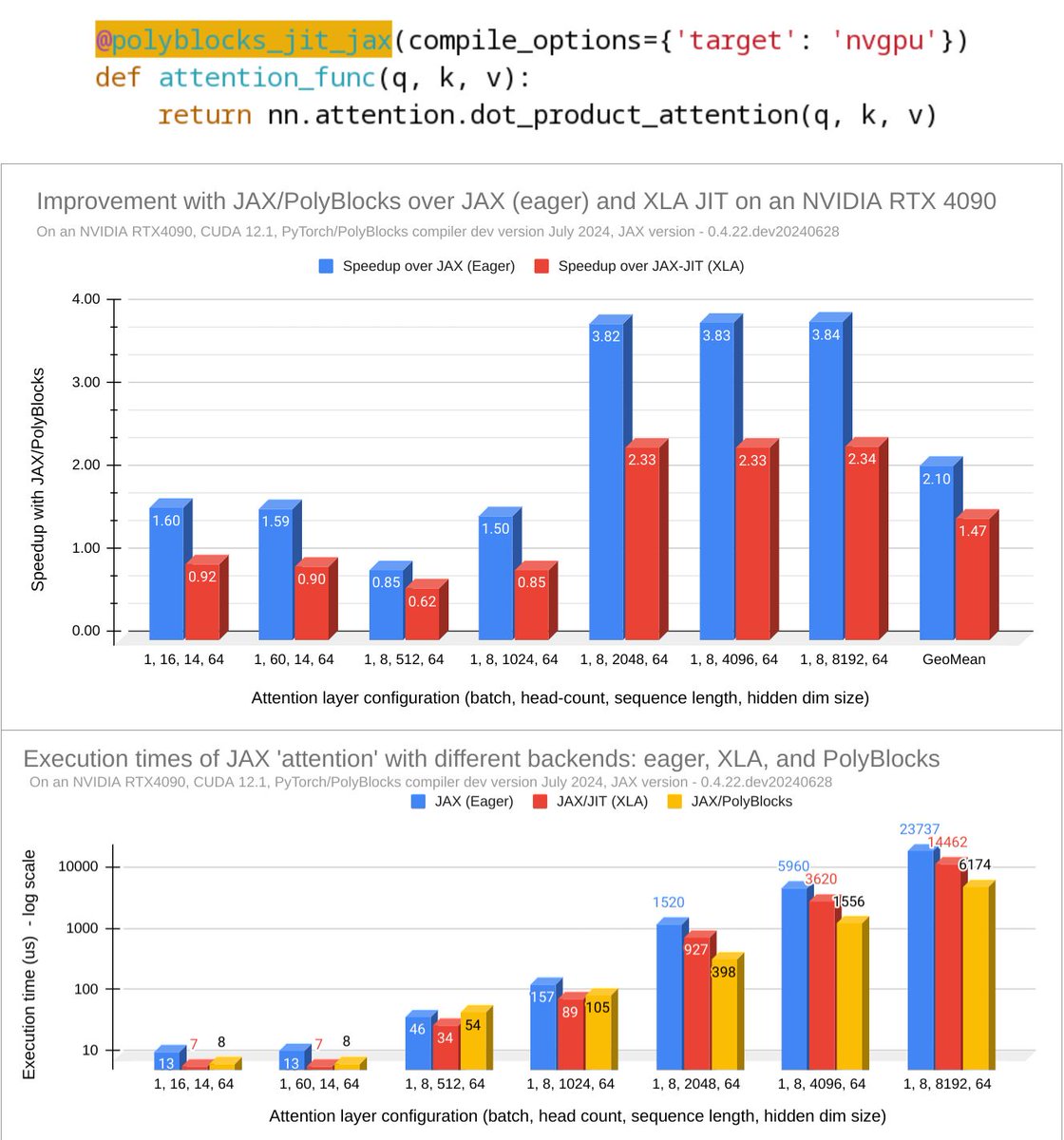
PolyBlocks-compiled JAX is up to 2.3x as fast as JAX JIT (XLA) for various 'attention' layer configurations! 1.5x as fast on average and 2.1x as fast as non-compiled code (eager execution). Requires just a one-liner to use!
JAX (eager or JIT), in these cases, relies on a mix of Triton and CUTLASS GEMM kernels. OTOH, PolyBlocks compiled code is fully generated, with the same transformations/optimizations as in the case of PyTorch/PolyBlocks.
Note: Absolute execution times on the y-axis are on the log scale. All time measurements here are the total of nsys kernel execution times.
More info: docs.polymagelabs.com
2
4
29
2,276

17 Jul 2024
Whenever people speak of building compilers for AI, they end up building them only for PyTorch, or only for NVIDIA GPUs, or the PyTorch x NVIDIA GPUs combination! Such systems aren't reusable, modular, or future-proof.
While XLA (github.com/openxla/xla) is an exception, it doesn't deliver coverage or performance for PyTorch (pytorch.org/assets/pytorch2-… ), one of the dominant AI frameworks today, or for CPUs or GPUs in several cases. (XLA's intermediate representation isn't geared to address it, either.)
PolyBlocks works for the entire cross-product of {PyTorch, JAX, TensorFlow} x {NVIDIA GPUs, AMD GPUs, CPUs} - yes, all nine combinations! Same transformations and similar improvements over the default compiler backends that come with the respective frameworks -- through a single compiler engine.
16 Jul 2024
PolyBlocks-compiled JAX is up to 2.3x as fast as JAX JIT (XLA) for various 'attention' layer configurations! 1.5x as fast on average and 2.1x as fast as non-compiled code (eager execution). Requires just a one-liner to use!
JAX (eager or JIT), in these cases, relies on a mix of Triton and CUTLASS GEMM kernels. OTOH, PolyBlocks compiled code is fully generated, with the same transformations/optimizations as in the case of PyTorch/PolyBlocks.
Note: Absolute execution times on the y-axis are on the log scale. All time measurements here are the total of nsys kernel execution times.
More info: docs.polymagelabs.com
2
9
45
4,176
16 Jul 2024
PolyBlocks-compiled JAX is up to 2.3x as fast as JAX JIT (XLA) for various 'attention' layer configurations! 1.5x as fast on average and 2.1x as fast as non-compiled code (eager execution). Requires just a one-liner to use!
JAX (eager or JIT), in these cases, relies on a mix of Triton and CUTLASS GEMM kernels. OTOH, PolyBlocks compiled code is fully generated, with the same transformations/optimizations as in the case of PyTorch/PolyBlocks.
Note: Absolute execution times on the y-axis are on the log scale. All time measurements here are the total of nsys kernel execution times.
More info: docs.polymagelabs.com
4
12
7,553
11 Jul 2024
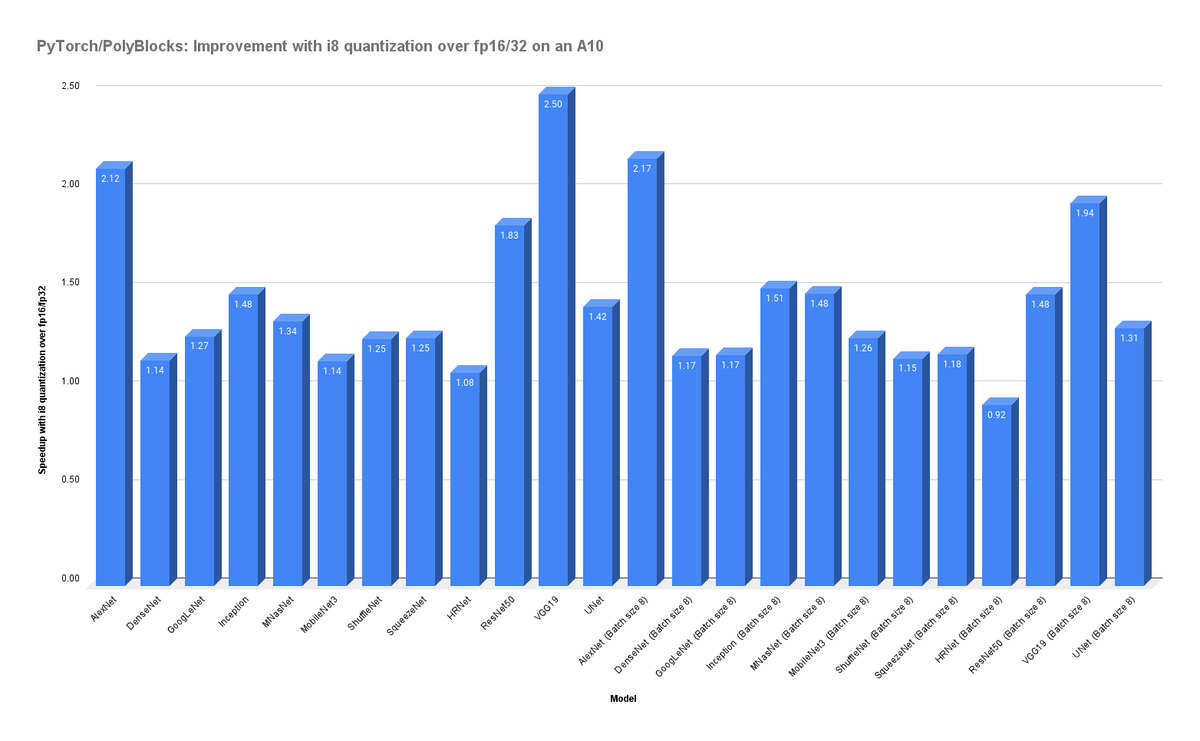
Quantization compilation! The PolyBlocks compiler works with the PyTorch 2.0 export quantization workflow, and all its compiler optimizations apply to quantized models. Fusion of operators is particularly important for quantized models to ensure int8 data enters and leaves the chip as much as possible (instead of int32, fp16, or fp32). Significant improvements when easily switching from mixed precision f16/f32 to i8 and with powerful control for the programmers. About 1.5-2x as fast (on entire vision models) in many cases.
docs.polymagelabs.com/articl…
9 Jul 2024
Our first article on how the PolyBlocks compiler works in some depth! Also shows the PyTorch 2.0 quantization workflow (e.g., exploiting 8-bit int arithmetic instead of float16/float32), which benefits from the same powerful compiler optimizations of the PolyBlocks engine.
docs.polymagelabs.com/articl…
1
7
16
1,187