

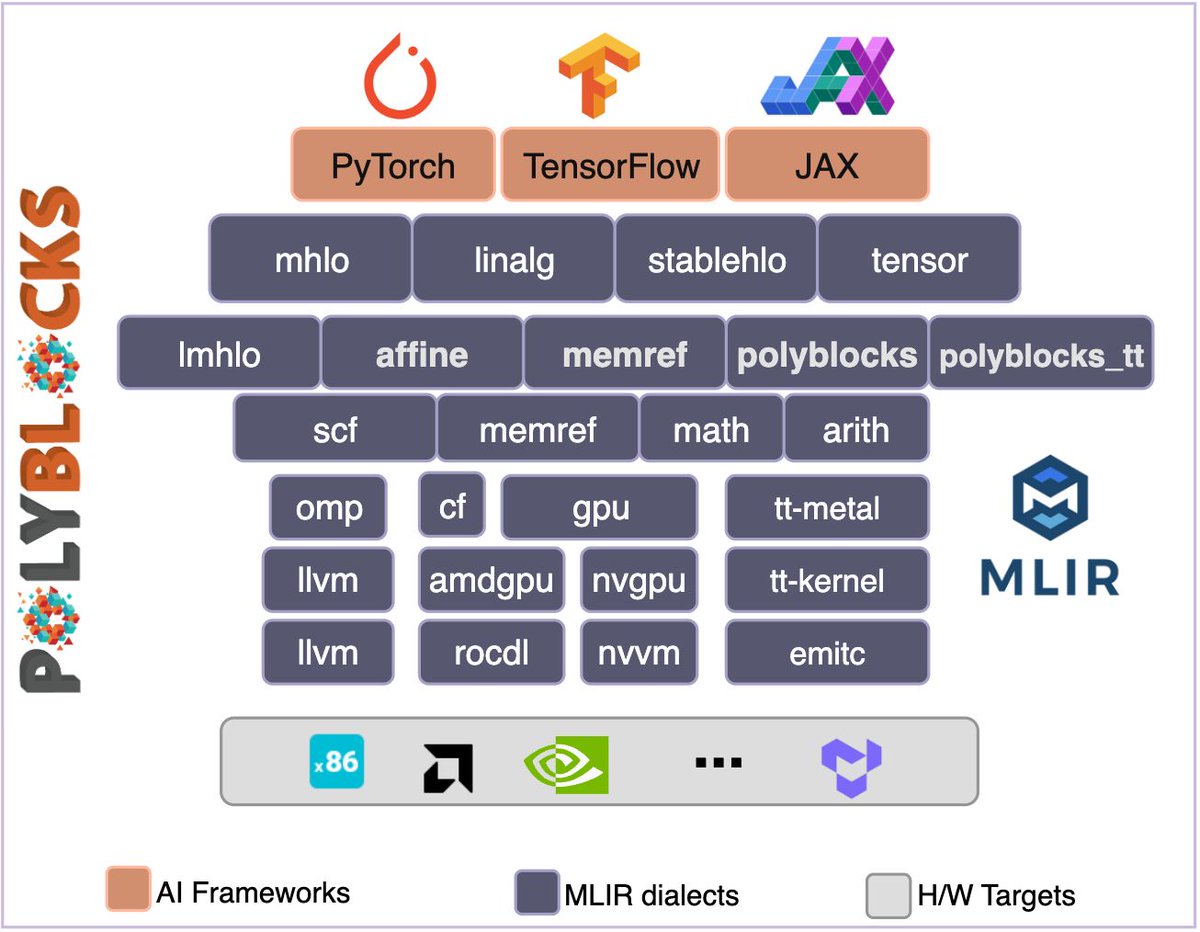
ALT PolyBlocks compiler stack: from PyTorch/JAX/etc. to hardware.
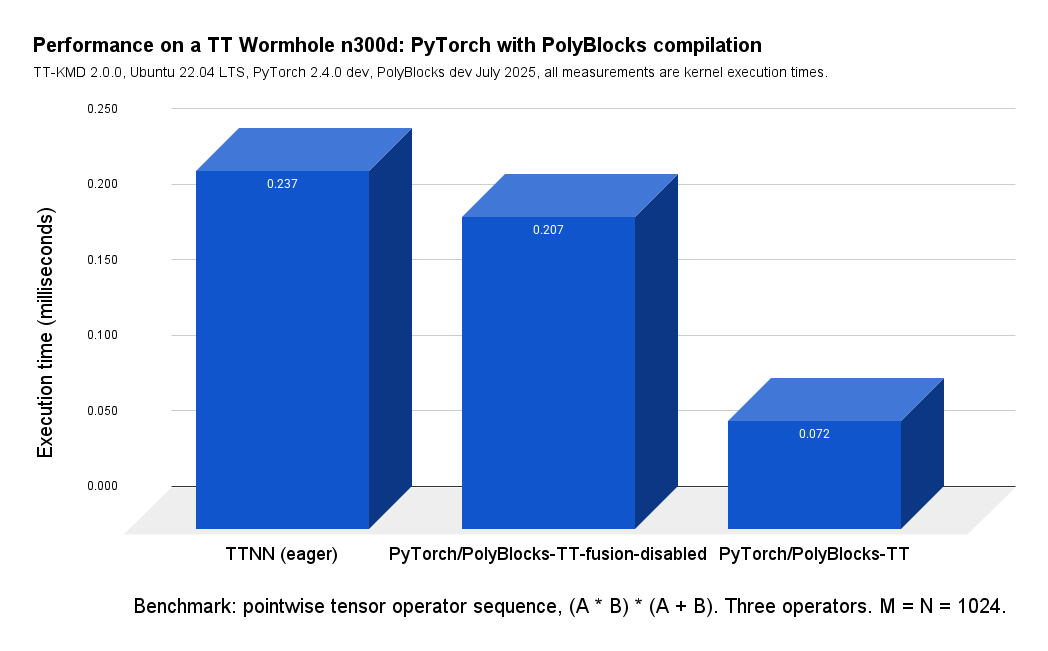
ALT Automatic fusion with the PolyBlocks compiler for PyTorch to Tenstorrent hardware.
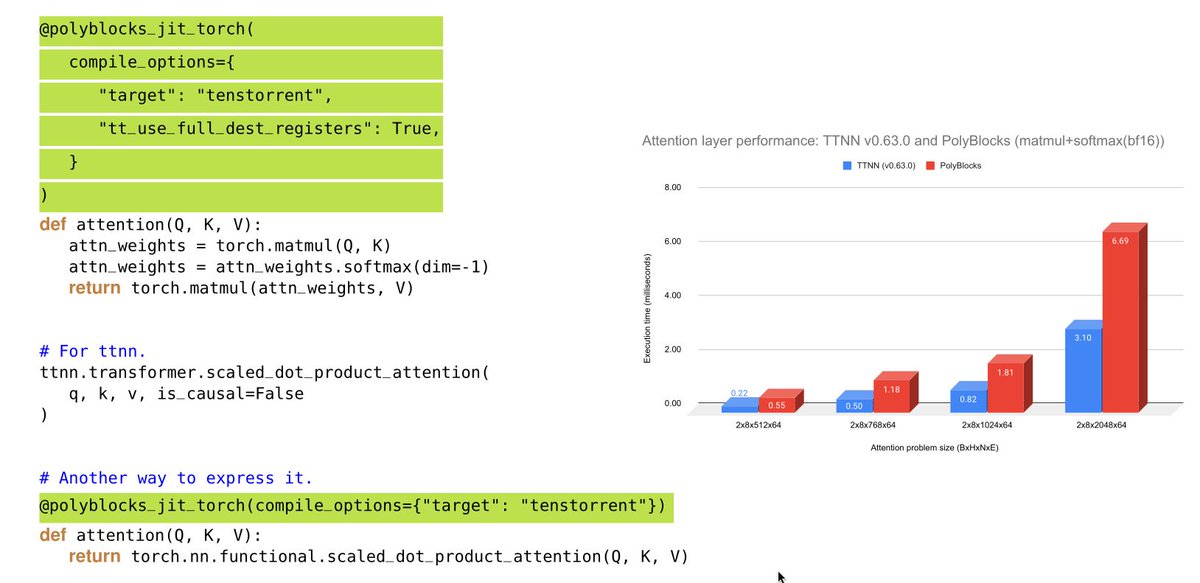
ALT Automatic fusion and tiling for the attention layer with the PolyBlocks compiler for PyTorch to Tenstorrent hardware.

ALT The PolyBlocks team -- at IISc, Bangalore, India.


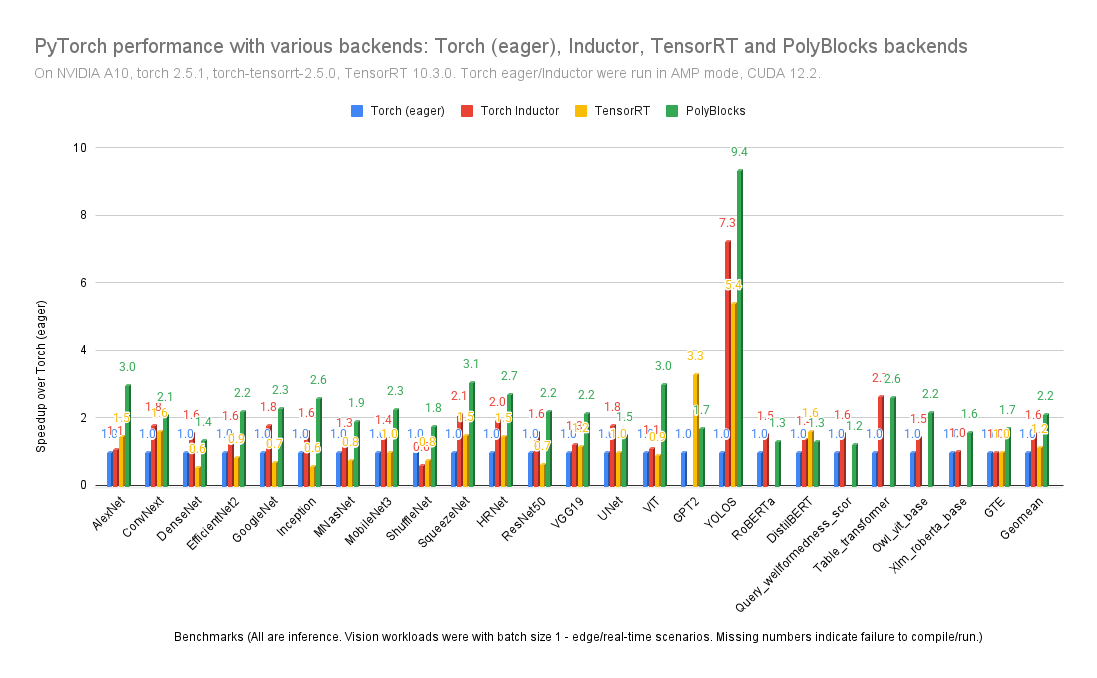
ALT PolyBlocks compiler performance on PyTorch AI workloads.
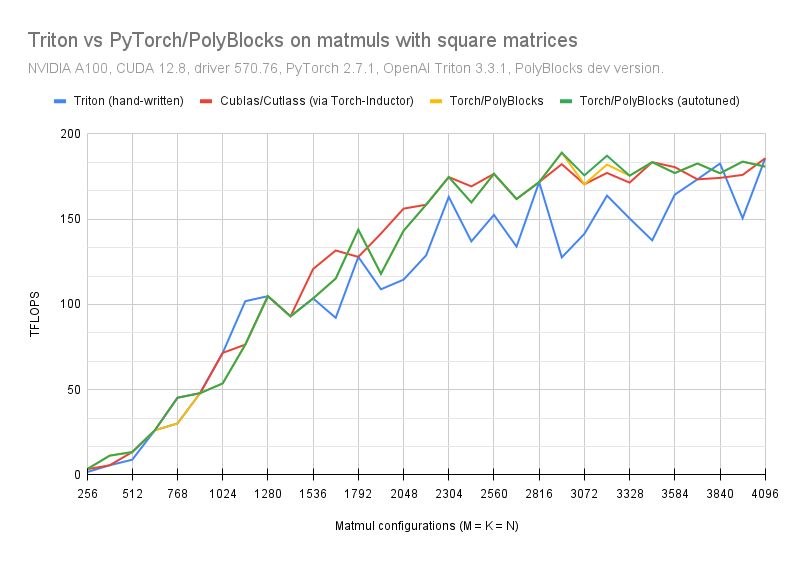
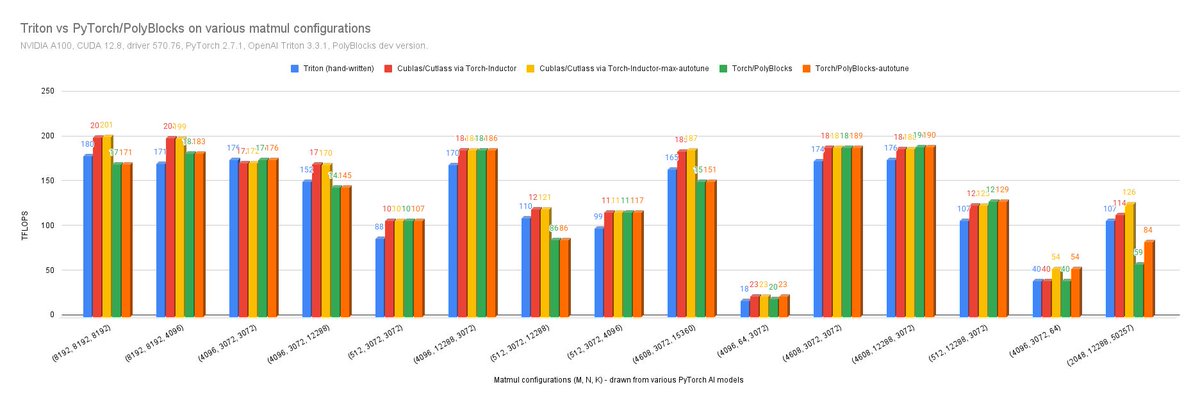
ALT PolyBlocks vs Triton vs Cublas/cutlass


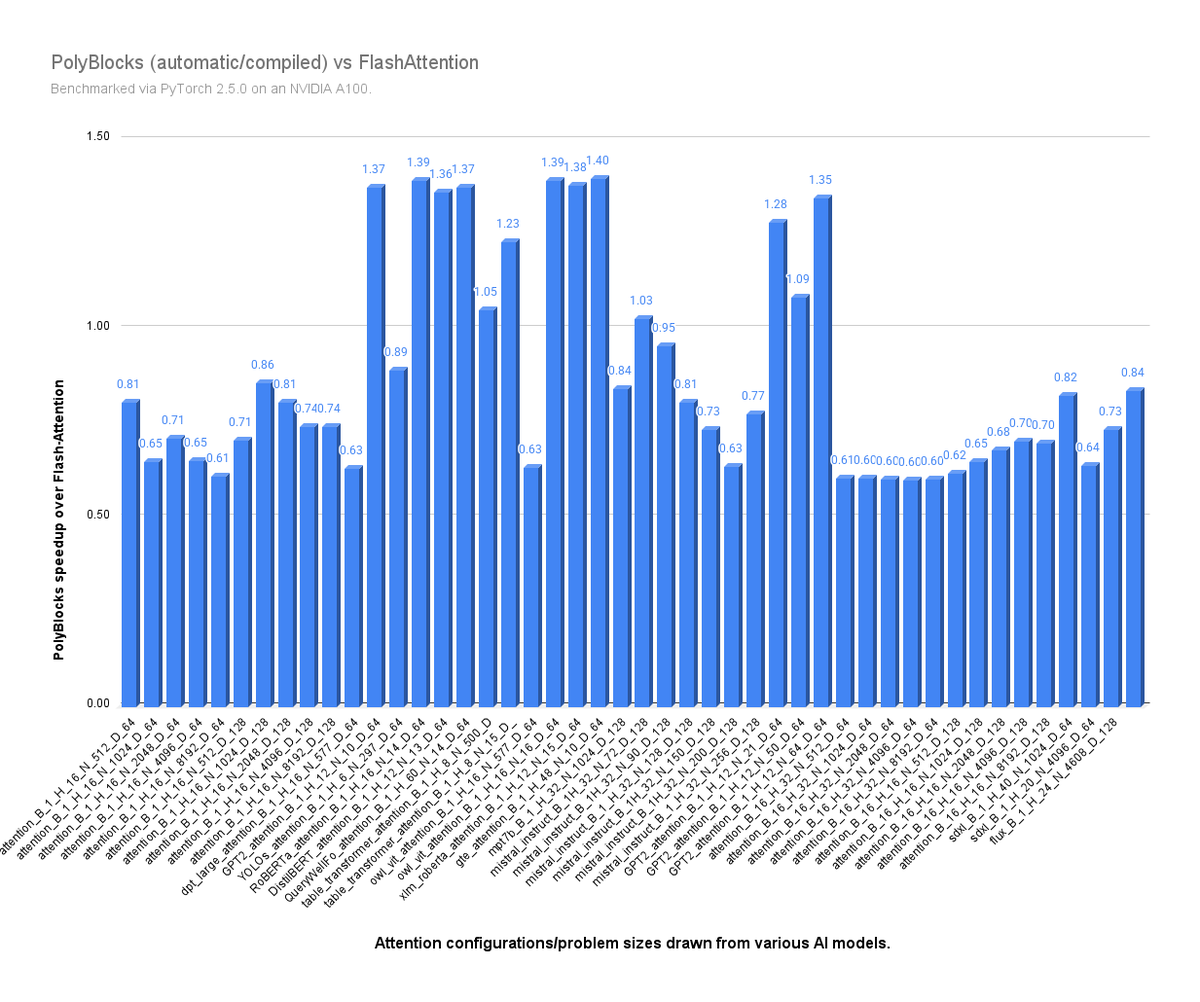
ALT PolyBlocks (automatic) vs FlashAttention benchmarked on an NVIDIA A100
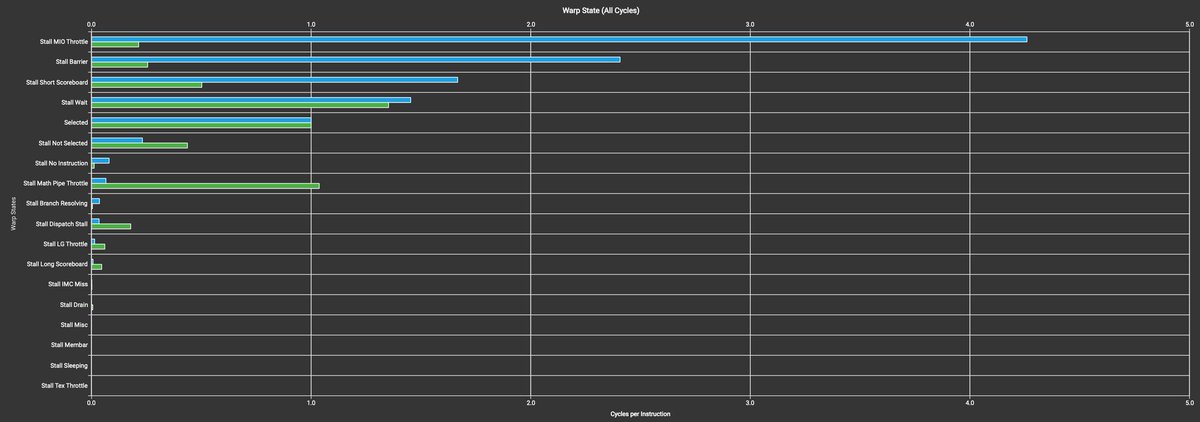
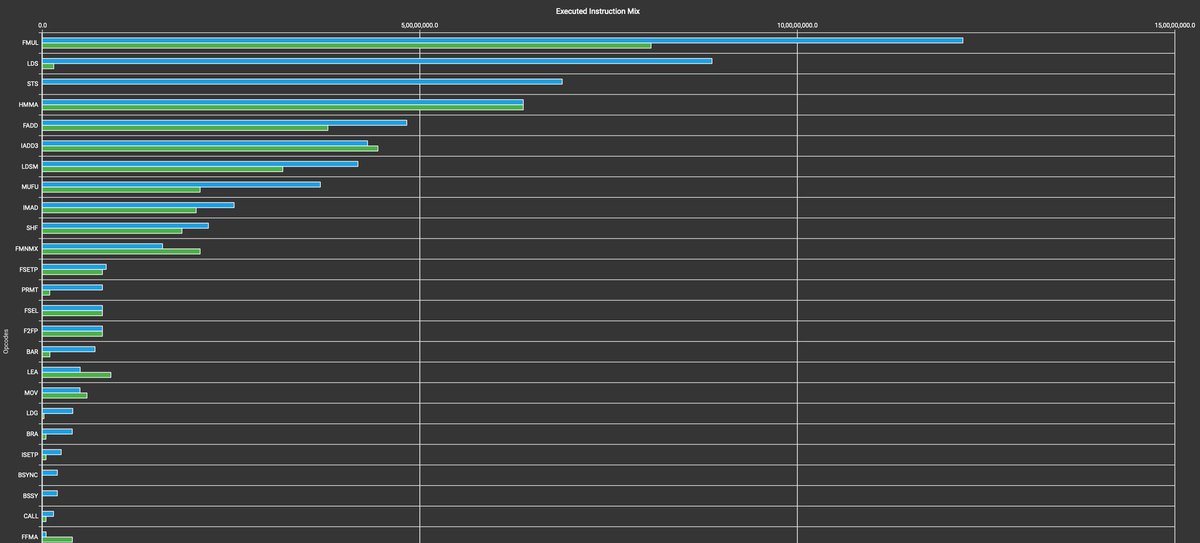

ALT PolyBlocks compiled code: performance improvement with WMMA-level fusion
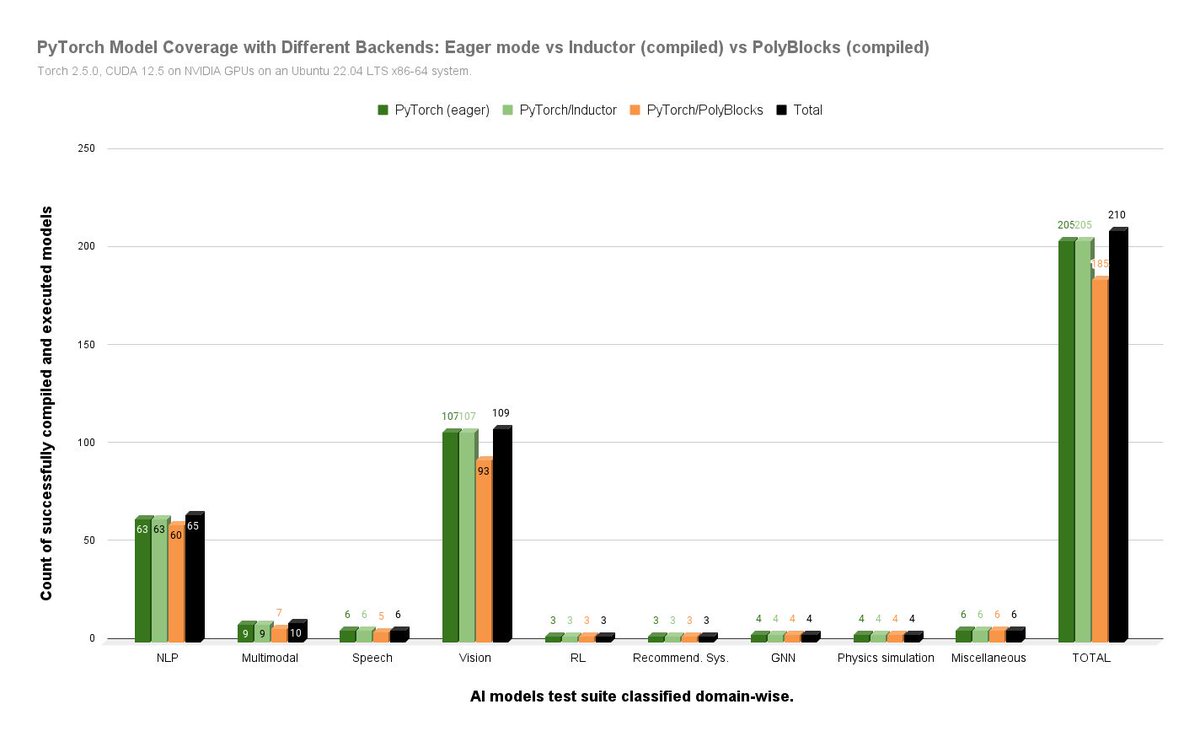
ALT PyTorch model coverage with the PolyBlocks compiler backend.
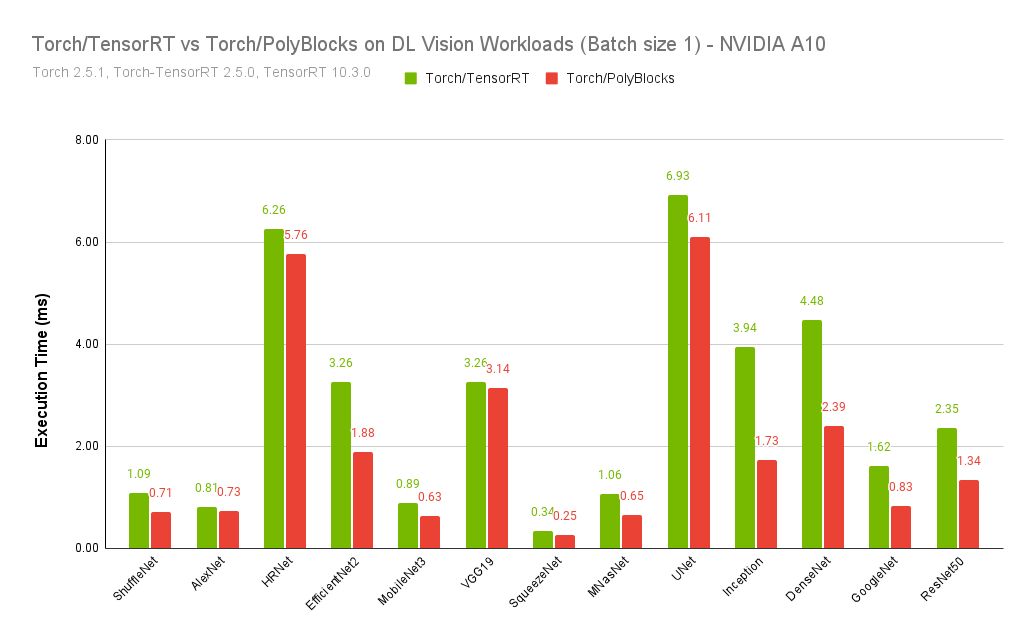
ALT TensorRT vs PolyBlocks with PyTorch on batch size 1
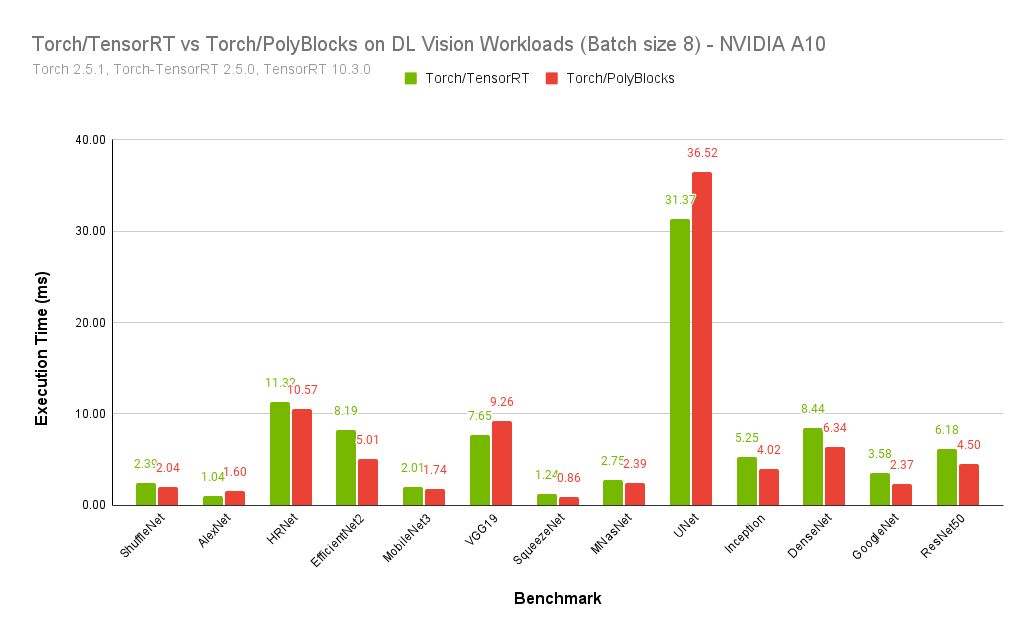
ALT TensorRT vs PolyBlocks with PyTorch on batch size 8
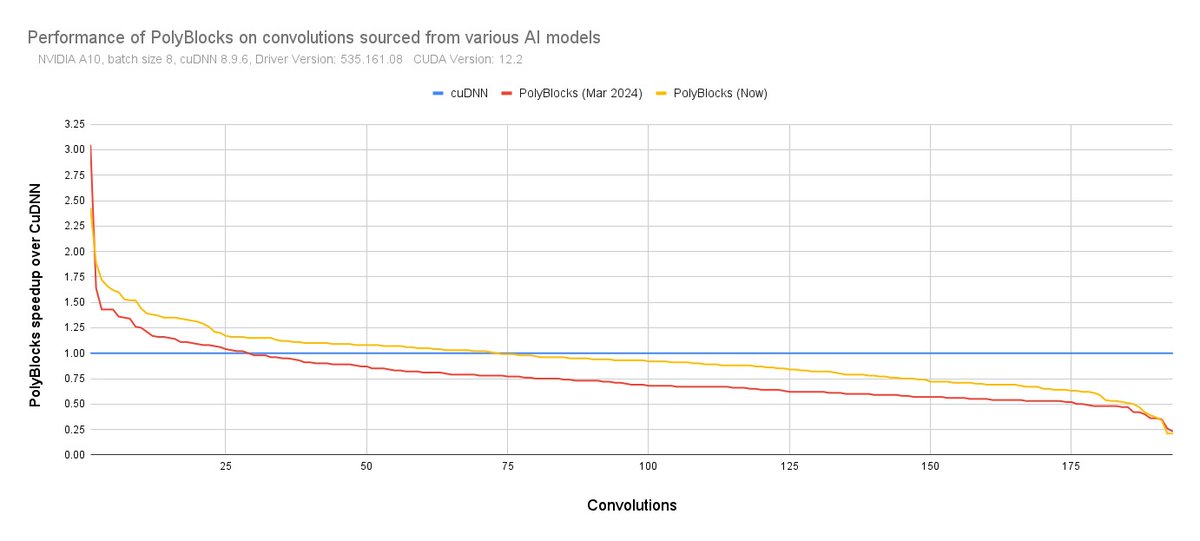
ALT PolyBlocks vs CuDNN on various convolution operator sizes.


ALT Compile Torch with PolyBlocks with a single line.

ALT Torch (eager) vs Torch/PolyBlocks compiled on an NVIDIA Jetson Orin Nano.

ALT JAX with PolyBlocks as backend: performance improvement on 'attention' computation over JAX-JIT (XLA).

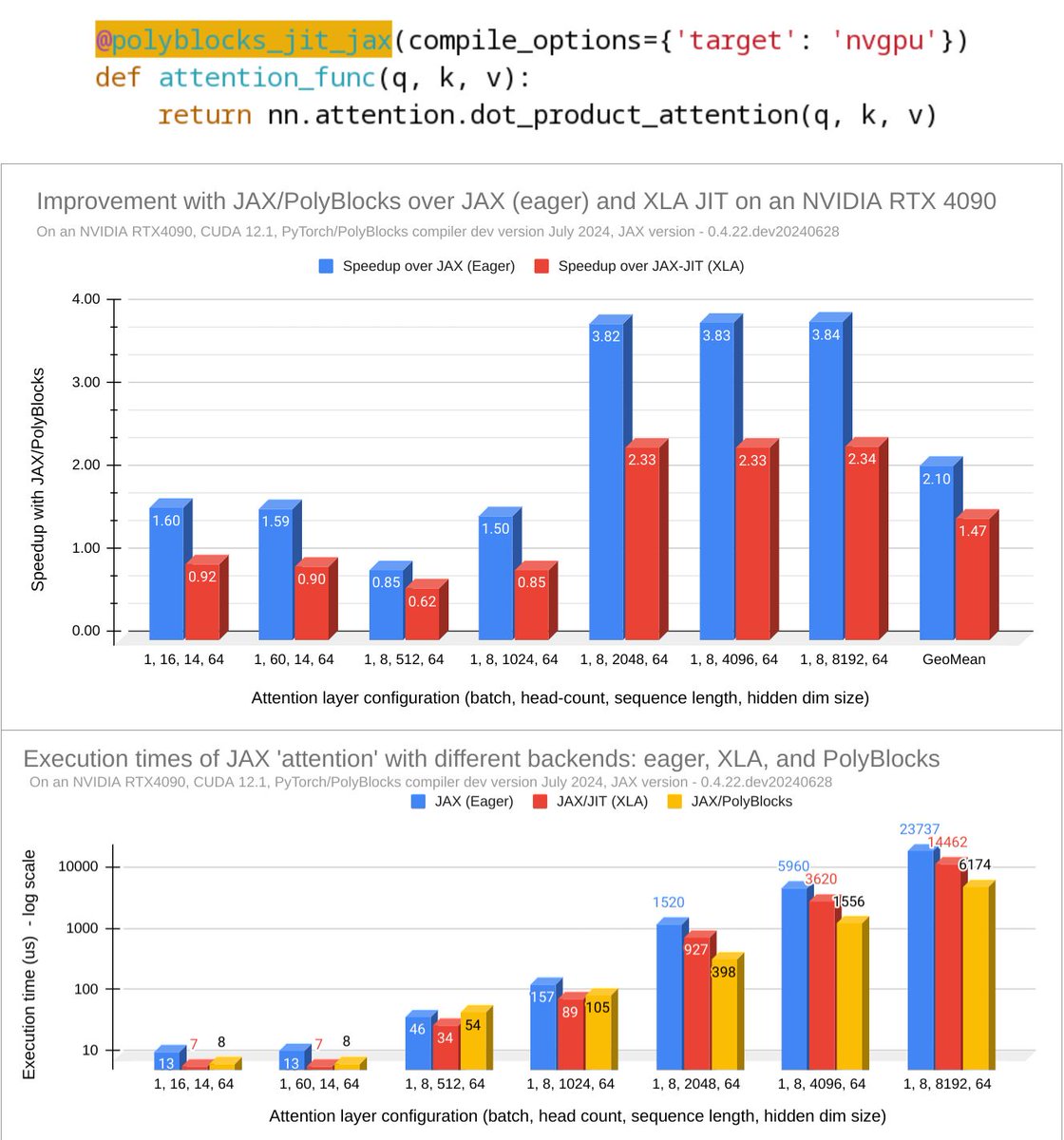
ALT JAX with PolyBlocks JIT vs JAX eager vs JAX XLA JIT on attention layer computation.

ALT JAX with PolyBlocks JIT vs JAX eager vs JAX XLA JIT on attention layer computation.
ALT JAX with PolyBlocks JIT vs JAX eager vs JAX XLA JIT on attention layer computation.
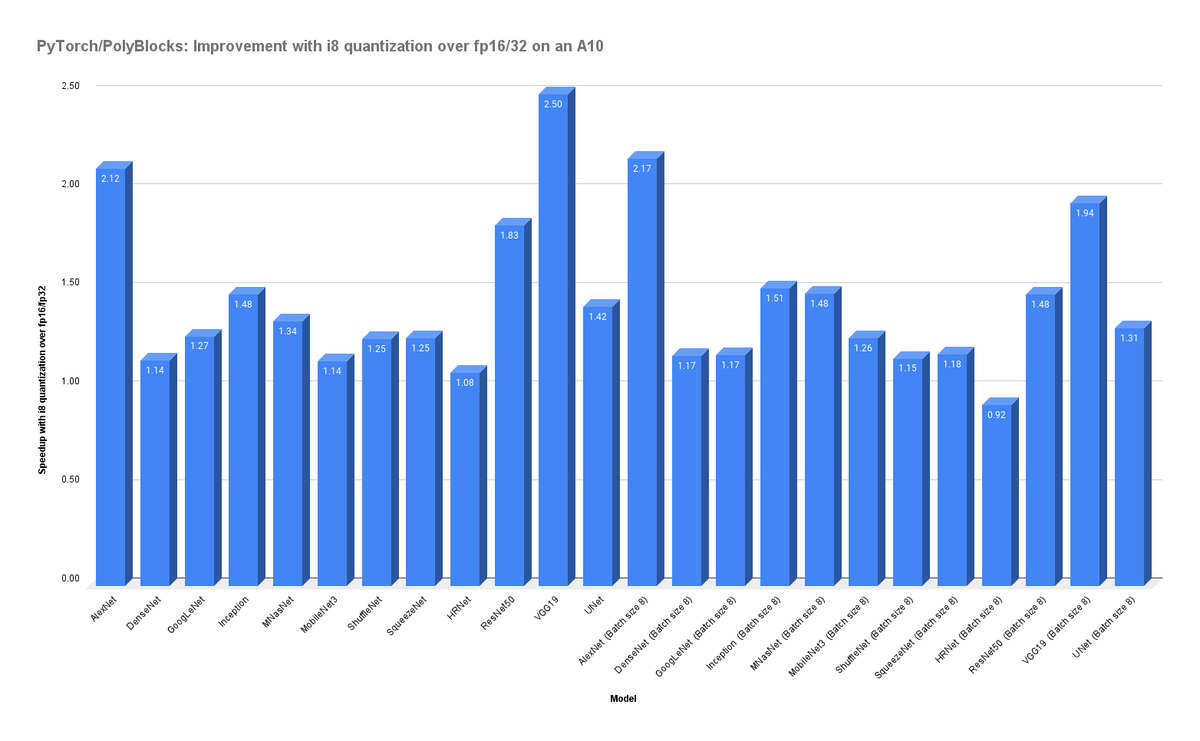
ALT Improvements when quantizing from fp16/fp32 to int8 with the PyTorch/PolyBlocks compiler.