
The mistake: hiding complexity behind a generic name.
The lesson: `processData` can contain anything, so it teaches nothing.
A boring precise name beats a flexible meaningless one.
9
Anthony Alaribe {···} retweeted

Jun 11
Combinatorial FP solves composition in ways we don't need OOP for.
-- Pointed version (explicit)
processData x = case classify x of
Foo -> handleFoo x
Bar -> handleBar x
_ -> default x
-- Combinatorial/point-free
processData = classify >>> caseOf
[ (isFoo, handleFoo)
, (isBar, handleBar)
, (const True, default)
]
where (>>>) = B -- composition combinator
Jun 11

the masculine urge to use polymorphism to solve all problems is real
I am realizing my last 20 years were a lie and the strategy pattern isn't the best thing ever...
Maybe a function with 200 lines and a switch statement is just easier by all means
2
1
16
2,417

3/
You open an old module to add a feature. Inside: a 200-line processData(), stale TODOs, commented-out code.
You could add your feature and leave.
The rule says improve one thing while you're there.
1
6

Most codebases don't need a rewrite. They need a thousand small fixes that nobody schedules.
That's the 𝗕𝗼𝘆 𝗦𝗰𝗼𝘂𝘁 𝗥𝘂𝗹𝗲: 𝗹𝗲𝗮𝘃𝗲 𝘁𝗵𝗲 𝗰𝗼𝗱𝗲 𝗯𝗲𝘁𝘁𝗲𝗿 𝘁𝗵𝗮𝗻 𝘆𝗼𝘂 𝗳𝗼𝘂𝗻𝗱 𝗶𝘁. Robert C. Martin popularized it in his book Clean Code (2008). This term comes from Scouting: leave the campsite cleaner than you found it.
How does this look in practice: You open an old module to add a feature, but inside you find a processData() method that has more than 200 lines, and some blocks of commented-out code. You could add your feature and leave it. The rule says 𝗶𝗺𝗽𝗿𝗼𝘃𝗲 𝗼𝗻𝗲 𝘁𝗵𝗶𝗻𝗴 while you're there. Split the function. Delete the dead code. Rename the variable that lied to you for ten minutes.
Each fix cost you a few minutes, but they compound.
Google engineers have a phrase for this: 𝗶𝗳 𝘆𝗼𝘂 𝘁𝗼𝘂𝗰𝗵 𝗶𝘁, 𝘆𝗼𝘂 𝗼𝘄𝗻 𝗶𝘁. Modify a file and its quality is now yours. Over a product's lifetime, thousands of these cleanups happen during unrelated work. That's what keeps a decade-old codebase workable.
Two boundaries keep the rule honest.
First, it's not yak shaving. One small improvement near the code you're already changing, not endless polishing.
Second, it's not charity. It's 𝗿𝗲𝘀𝗽𝗼𝗻𝘀𝗶𝗯𝗶𝗹𝗶𝘁𝘆. A developer who dumps sloppy code just to close the ticket makes the codebase worse for everyone who comes after.
Broken Windows Theory says one visible hack invites the next. The Boy Scout Rule is the 𝗰𝗼𝘂𝗻𝘁𝗲𝗿-𝗺𝗼𝘃𝗲. Instead of leaving the first broken window, you repair one pane on every visit.
What's the smallest fix you shipped in your last PR?

5
10
34
2,954

May 6
I’ve reviewed thousands of functions.
The same 8 rules survive every real codebase.
👇
---
1️⃣ Keep your functions small and focused
If your function does three things, it does zero well.
One responsibility.
One reason to change.
No exceptions.
---
2️⃣ Name functions to reveal intent
If you need to explain what a function does, the name already failed.
calculateInvoiceTotal() > processData()
A good function name should answer:
“What action does this perform?” and “What does it return?”
---
3️⃣ Return early. Stop nesting
Deep nesting hides intent and multiplies bugs.
Guard clauses flatten logic and make failure obvious.
---
4️⃣ Limit function parameteres
Functions with many parameters are a cognitive load.
You can’t remember parameter order, and it’s easy to pass the wrong values.
To improve this, group related parameters into objects.
---
5️⃣ Write pure functions when possible
Functions with side effects are unpredictable.
They might work differently based on a global state, making them hard to test and debug.
Pure functions are predictable, testable, and can be safely called from anywhere.
---
6️⃣ Avoid boolean parameters
Boolean parameters make function calls unclear and hard to extend.
Boolean flags also often indicate that a function is doing two different things.
A better approach is to use objects, enums, or separate functions instead of single boolean flags.
---
7️⃣ Return results, not exceptions
A good rule of thumb is:
• Use Result Pattern for expected errors to make them explicit.
• Use Exceptions for unexpected errors and exceptional situations.
---
8️⃣ Replace magic numbers and strings
These hardcoded values create a maintenance nightmare.
When business requirements and rules change, it’s very hard to find every occurrence of these numbers or strings.
Extract the numbers into constants and the strings into enums.
---
Most “clean code” debates miss this:
functions are where discipline actually shows.
What is your main rule for writing clean functions?
——
💾 Save for future reference.
♻ Repost to help others write clean code.
🔔 Follow me ( @petarivanovv9 ) to improve your Software Design skills.
#programming

5
2
19
670

Asked an AI to name a function today. It suggested processData.
Humans are bad at naming. AI is also bad at naming. We're united in our inability to describe what code actually does.
3
4
18
1,940

Mar 16
- Just spent 45 mins renaming a function from processData() to
UserInputToValidatedOutput().
Now it’s 3x longer but 10x clearer.
Refactoring: where you make your future self less angry.
What’s the longest function name you’ve proudly created?
4
44

Jan 27
I’ve reviewed thousands of functions.
The same 8 rules survive every real codebase.
👇
---
1️⃣ Keep your functions small and focused
If your function does three things, it does zero well.
One responsibility.
One reason to change.
No exceptions.
---
2️⃣ Name functions to reveal intent
If you need to explain what a function does, the name already failed.
calculateInvoiceTotal() > processData()
A good function name should answer:
“What action does this perform?” and “What does it return?”
---
3️⃣ Return early. Stop nesting
Deep nesting hides intent and multiplies bugs.
Guard clauses flatten logic and make failure obvious.
---
4️⃣ Limit function parameteres
Functions with many parameters are a cognitive load.
You can’t remember parameter order, and it’s easy to pass the wrong values.
To improve this, group related parameters into objects.
---
5️⃣ Write pure functions when possible
Functions with side effects are unpredictable.
They might work differently based on a global state, making them hard to test and debug.
Pure functions are predictable, testable, and can be safely called from anywhere.
---
6️⃣ Avoid boolean parameters
Boolean parameters make function calls unclear and hard to extend.
Boolean flags also often indicate that a function is doing two different things.
A better approach is to use objects, enums, or separate functions instead of single boolean flags.
---
7️⃣ Return results, not exceptions
A good rule of thumb is:
• Use Result Pattern for expected errors to make them explicit.
• Use Exceptions for unexpected errors and exceptional situations.
---
8️⃣ Replace magic numbers and strings
These hardcoded values create a maintenance nightmare.
When business requirements and rules change, it’s very hard to find every occurrence of these numbers or strings.
Extract the numbers into constants and the strings into enums.
---
Most “clean code” debates miss this:
functions are where discipline actually shows.
What is your main rule for writing clean functions?
---
💾 Save for future reference.
♻ Repost to help others write clean code.
🔔 Follow me ( @petarivanovv9 ) to improve your Software Design skills.
#cleancode

8
2
17
1,762

出来ない言い訳集みたいになってるよしょうがないよね💕
プログラマー様 頑張ってください🤣💕
#プログラマー #legacycode
誰かが作ったプログラム(特に他人のlegacy code)を直すのって、まさに地獄だよね…
開発者の間ではもう定番の苦しみで、
「自分の書いたコードですら、数ヶ月経てば他人コードになる」
って言われるくらいなのに、最初から他人のコードだと、もう心が折れるレベル。
みんながよく言う理由をまとめると、こんな感じ:
- 意図がわからない(なぜこんな書き方した? 何考えてた?)
- 変数名・関数名が意味不明(temp1, processData, fixBug2023みたいな…)
- コメントがない・古い・嘘(「ここ修正した」って書いてあるけど、どこ直したかわからん)
- コピペ地獄(同じ処理が10箇所に散らばってる)
- テストがない(触ったら全部壊れる恐怖)
- ドメイン知識が足りない(ビジネスルールが暗黙知になってる)
- 作者がもういない(退職・転職・死亡フラグ…)
1
5
162
誰かが作ったプログラム(特に他人のlegacy code)を直すのって、まさに地獄だよね…
開発者の間ではもう定番の苦しみで、
「自分の書いたコードですら、数ヶ月経てば他人コードになる」
って言われるくらいなのに、最初から他人のコードだと、もう心が折れるレベル。
みんながよく言う理由をまとめると、こんな感じ:
- 意図がわからない(なぜこんな書き方した? 何考えてた?)
- 変数名・関数名が意味不明(temp1, processData, fixBug2023みたいな…)
- コメントがない・古い・嘘(「ここ修正した」って書いてあるけど、どこ直したかわからん)
- コピペ地獄(同じ処理が10箇所に散らばってる)
- テストがない(触ったら全部壊れる恐怖)
- ドメイン知識が足りない(ビジネスルールが暗黙知になってる)
- 作者がもういない(退職・転職・死亡フラグ…)
2
269

30 Dec 2025
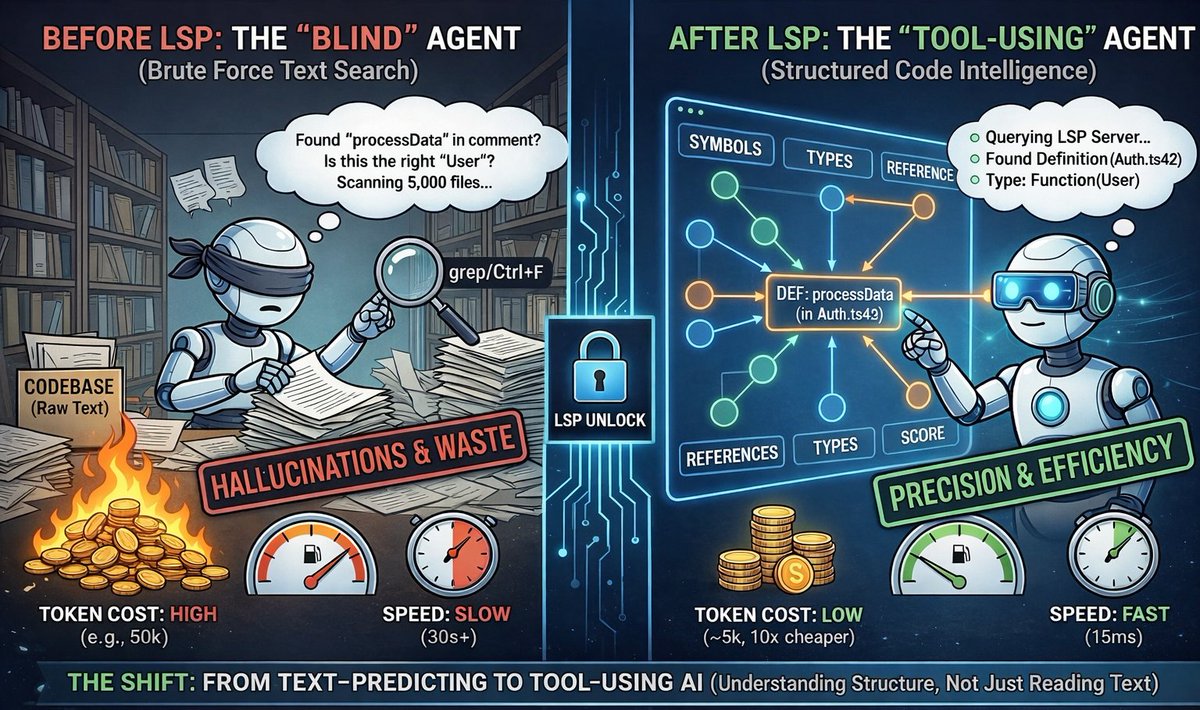
Your AI coding agent has been coding "blind" this whole time. 🫣
It’s been burning your money, guessing context and "grepping" through files like a caveman.
Here is why the new LSP (Language Server Protocol) integration is the biggest unlock for AI coding this year:
1. The "Ctrl F" problem until now, when you asked an AI "Where is processData() defined?", it had to text-search thousands of files. It read comments (useless tokens). It found similar names (hallucinations). It cost you $$$ in context window usage.
It was brute force. It was reading text, not understanding structure.
2. The Fix: Giving the AI "Glasses" 👓LSP is the standard tech that powers your IDE’s "Go to Definition" (Cmd Click).
New tools (like Claude Code) are finally plugging into this. Instead of reading 50 files to find one function, the AI asks the server: "Where is this?"
The Result?⚡️ Speed: 15ms lookup vs. 30s scraping. 💰 Cost: Refactoring tasks dropping from 50k tokens → 5k tokens.
🎯 Accuracy: No more confusing a variable in User.ts with one in Auth.ts.
We are moving from "Text Predicting" agents to "Tool Using" agents.
Stop letting your AI guess. Start letting it use the IDE.
2
2
47

16 Nov 2025
In programming, succinctness is key. It enhances readability and reduces errors. Here's how to practice it effectively.
❯ Use clear variable names. Instead of `a`, use `userCount`.
❯ Write functions that do one thing. Example: `calculateTotal()` rather than `processData()`.
❯ Avoid unnecessary comments. Let the code speak for itself.
Try this: refactor a piece of your code today. Focus solely on making it more concise.
Bottom line: Succinctness leads to better code quality. Follow @brevis_zk for more insights on clarity in programming.

3
5
44

21 Oct 2025
Node.js Streams
if you've ever struggled with memory issues processing large files, slow data transfers, or building real-time features, you've encountered the exact problems node.js streams were designed to solve!
streams aren't just another features; they're a fundamental programming pattern that enables you to work with data efficiently by processing it in chunks rather than loading everything into memory at once
* why streams matter?
consider this common anti-pattern:
```
fs.readFile('huge-files.csv', (err, data) => {
// your 2gb file just consumend 2gb of ram!
processData(data);
fs.writeFile('processed-file.csv', processageData);
})
```
now, watch the streaming approach:
```
//more efficient way
fs.createReadStream('huge-file.csv')
.pipe(transformStream)
.pipe(fs.createWriteStream('processed-file.csv'));
//memory usage remains low, regardless of file size
```
* the four types of streams (and when to use them)
1. Readable Streams: sources of data (files, HTTP req, user input)
2. Writeable Streams: destinations for data (files, HTTP responses, database)
3. Duplex Streams: both readable and writable (TCP sockets, webSockets)
4. Transform Stream: Special duplex streams that modify data (compression, encryption)
* common pitfalls and how to avoid them?
> error handling: stream errors don't bubble up like regular promises, you must handle errors on each stream
ex.,
```
readStream
.on('error', (err) => console.error('read failed:', error))
.pipe(transformStream)
```
> backpressure management: when data arrives faster than it can be processed, you need backpressure handling
* modern streams api (node.js 18 )
node.js has made streams even more approachable with async iterators:
```
async function processStream() {
for await (const chunk of readableStream) {
console.log("processing chunk: ", chunk.length)
// process each chunk as it arrives
}
}
```
* use streams for:
- large file processing (logs, media files, datasets)
- real-time data (chat apps, live feeds)
- network operations (proxies, api responses)
- data transformation pipelines

3
95

14 Sep 2025
If you find yourself struggling with naming your functions, here’s how to fix it:
- Make sure each function does only one thing, single tasks are easier to name.
- Use verbs if the function changes state and nouns if it just returns a value.
- Be as specific as possible. calculateInvoiceTotal() > processData().
- Avoid abbreviations, readability is more important than short names.
- Avoid the same concept covered by multiple names. If you use delete, stick with it. Don’t use remove somewhere else.
2
3
195

26 Aug 2025
“Programs must be written for people to read, and only incidentally for machines to execute”
– Harold Abelson (أستاذ MIT)
ما راح تبرمج مليار سطر لحالك، ولو برمجته فاللي بيصونه بعدك ما راح يفهم وش السالفة إلا لو كتبت تسميات واضحة
وهذي طريقة التسمية الأحسن:
1- اختر أسماء معبّرة وواضحة:
سيء:
x = 10
y = 20
جيّد:
user_age = 10
max_score = 20
2- اتبع الـ convention المتفق عليه (snake_case أو CamelCase):
snake_case مثل: total_price
CamelCase مثل: totalPrice
3- تجنب الاختصارات الغامضة:
سيء: tmp, val, dt
جيّد: temp_file, customer_value, current_date
4- لا تستخدم أفعال عامة جدًا مثل doTask أو processData.
5- خل الاسم يوصف "هوية" الشيء مب فعله
6- الثوابت (Constants):
كلها Capital underscore:
MAX_CONNECTIONS = 100
PI = 3.14159
7- لا تكتب تعليق يكرر الكود نفسه:
سيء:
i = i 1 # add 1 to i
جيّد:
i = i 1 # move to next index
8- الـ Naming في المشاريع الكبيرة (بيئة فريق):
وثّق Naming convention بمستند أو README للفريق
استخدم Linters & Formatters مثل:
ESLint (JavaScript/TS)
Pylint, Black (Python)
Prettier (JS/TS)
Code Review: أي كود جديد لازم يمر على مراجعة زميل
Avoid Magic Numbers: لا تكتب أرقام/Strings مباشرة
سيء:
if speed > 120:
جيّد:
MAX_SPEED = 120
if speed > MAX_SPEED:
9- قواعد عامة بالبيئة التعاونية:
تسمية الفروع:
feature / add-login
bugfix / fix-auth
hotfix / reset-password
Commit messages واضحة:
feat: add user authentication
fix: resolve login redirect bug
refactor: clean up database queries
3
3
1,897

7 Aug 2025
Many developers mistakenly equate software complexity with the size of a system or feature within a system. But in reality, complexity lies not in how big a system is, but in how understandable it is.
Complexity often hides in the small details, not in a massive class or an overloaded component, but in the accumulation of small, confusing functions, poorly named variables, and tangled logic. It’s death by a thousand cuts, not one giant blow.
Complexity is more visible to readers than to writers. As developers, we may not immediately recognize our own code as complex until someone else tries to read or modify it. This is why practices like code reviews are so valuable, they expose complexity through fresh eyes.
Some common factors that lead to complexity:
Dependencies: A dependency exists when one piece of code cannot be changed or understood in isolation. When everything is connected to everything else, even a small change becomes risky.
Obscurity: Obscurity arises when important information is hard to see. Examples include vague function names (doStuff(), processData()), unclear logic, or unexpected side effects.
Complexity is often a design problem, and it can be addressed through better design and adherence to established design principles
Complexity is often introduced when developers try to be tactical than strategic. Tactical developers are often driven by a working code. On the other hand, strategic developers have an investment mindset. Investment in making the code extensible in the future, testable and understandable.
The goal isn’t just to make code that works, but code that’s easy to read, change, and trust.

1
5
122

16 Jun 2025
A month after building that construction SaaS prototype, I found myself working on something completely different: reimagining distributed programming paradigms in Java.
Context: Building Wavefront taught me the value of solid infrastructure foundations. We chose FoundationDB as our key-value store, and over the years I became fascinated by what made it so remarkably reliable. The answer wasn't just the ACID guarantees or the distributed architecture - it was Flow, their internal actor framework that enables single-threaded, cooperative multitasking with deterministic simulation.
Flow lets you write code like this:
ACTOR Future<int> processRequest() {
state int value = wait(readDatabase());
wait(delay(1.0)); // Non-blocking delay
return value * 2;
}
Sequential-looking code that's actually asynchronous. No callbacks, no complex threading, just cooperative yielding with full determinism for testing.
The Java Reality: Meanwhile, we're still wrestling with CompletableFuture chains that look like this:
service.getData()
.thenCompose(data -> processData(data))
.thenCompose(result -> saveResult(result))
.whenComplete((value, error) -> handleCompletion(value, error));
Reactive streams offer power but complexity. Virtual threads from Project Loom are impressive, yet they lack task prioritization and the deterministic execution that makes distributed system testing tractable.
Enter JavaFlow: I spent the last few months reimagining Flow's core ideas in idiomatic Java, leveraging JDK 21's continuations. The goal: cooperative multitasking with deterministic simulation, but without requiring a custom compiler.
FlowFuture<String> result = startActor(() -> {
String data = await(fetchData());
await(delay(1.0)); // Cooperative yield for 1 second
return processData(data);
});
What's implemented: actors, cooperative scheduling, timers, async file I/O, and an RPC framework. All operations integrate seamlessly with the event loop, maintaining deterministic execution. The key insight from FoundationDB holds: when you can simulate your entire distributed system in a single thread with controllable time, you can test scenarios that would be impossible in production.
I put Claude Code through its paces on this project. Still requires significant supervision, but Opus 4 shows meaningful improvements. The trajectory is promising.
Why this matters: Modern distributed systems are inherently asynchronous, yet our programming models often fight against this reality. JavaFlow attempts to bridge that gap - maintaining the performance benefits of event-driven systems while preserving the readability of sequential code.
The project is on Maven Central (io.github.panghy:javaflow) and fully open source: github.com/panghy/javaflow
This is experimental work - I don't yet know if it solves real problems or remains an interesting academic exercise.
#DistributedSystems #AsyncProgramming #Java #FoundationDB #EIR #TechInnovation
1
3
11
1,502

13 May 2025
Example Technical Process of EDUMCP
With the widespread application of artificial intelligence technology in the education field, how to achieve efficient collaboration between different models, tools, and resources has become a key issue. As a standardized interface, EDUMCP provides an effective way to solve this problem. The following will elaborate on the technical process of combining EDUMCP with some educational application scenarios.
Role of EDUMCP Core Components in Educational ScenariosModel Interaction Interface: In educational scenarios, this interface is crucial. For example, when developing intelligent tutoring systems, different AI models are responsible for different functions, such as a natural language processing model for understanding student questions and a knowledge graph model for providing accurate knowledge answers. The EDUMCP model interaction interface allows these models to be seamlessly connected. After a student asks a question, the natural language processing model processes it and passes the request to the knowledge graph model through the interface. After obtaining the answer, it is then returned to the student².
Data and Resource Management Module: Educational resources are rich and diverse, including textbooks, courseware, online courses, etc. This module is responsible for integrating and managing these resources. Taking an online learning platform as an example, it can categorize and store various learning materials by subject, grade, etc. When a teacher or student needs specific resources, they can quickly retrieve and use them. Simultaneously, it can manage student learning data, analyze learning progress, weak points, etc., providing a basis for personalized teaching²⁶.
Lifecycle of EDUMCP Server and its Application in EducationCreation Phase: In the field of education, when building a new educational AI application, such as an intelligent homework grading system, an EDUMCP server needs to be set up. The hardware configuration of the server should be determined, selecting appropriate server equipment based on factors such as the estimated volume of homework to be processed and the number of students. At the same time, the server needs to be initialized, including installing the operating system, configuring the network environment, etc. Furthermore, relevant educational models, tools, and resources need to be integrated into the server, such as integrating the image recognition model and knowledge point database required for grading homework⁶.
Running Phase: During the server's operation, it continuously processes education-related tasks. Taking an intelligent tutoring system as an example, it receives student questions in real-time and distributes the questions to appropriate models and tools for processing through EDUMCP's routing mechanism. For example, if a student asks a difficult math problem, the system sends the question to a math problem-solving model, which solves the problem and returns the answer and solution steps to the student. Concurrently, the server continuously collects student interaction data, such as question frequency and answer satisfaction, providing data support for subsequent optimization²⁶.
Update Phase: As educational content is updated and educational technology develops, the EDUMCP server needs to be updated in a timely manner. For instance, after a textbook version is updated, the knowledge point database on the server should be correspondingly updated. During the update, new models, tools, and resources are first tested to ensure compatibility with the existing system. Then, without affecting normal teaching, the old versions of content are gradually replaced to ensure the stability and advancement of educational applications⁶.
Integration Process with Educational Tools and ResourcesIntegration of Educational Documents and Knowledge Bases: There is a large amount of documentation in education, such as syllabi and academic papers. Through EDUMCP, these documents can be integrated with knowledge bases. Taking the construction of a subject knowledge base as an example, documents are first converted in format and preprocessed so that they can be recognized by EDUMCP. Then, using EDUMCP's indexing and annotation functions, the knowledge points in the documents are associated with concepts in the knowledge base. In this way, when a teacher or student queries a certain knowledge point, they can not only obtain the explanation from the knowledge base but also be linked to related teaching documents, deepening their understanding².
Integration of Teaching Software and Platforms: Various teaching software, such as online classroom software and learning management systems, can be integrated through EDUMCP. Taking blended online and offline teaching as an example, smart hardware used in offline teaching (such as smart whiteboards) is connected to the online learning platform through EDUMCP. The teacher's operations on the smart whiteboard (such as writing on the board or displaying courseware) can be synchronized to the online platform in real-time. Student questions and assignment submissions on the online platform can also be promptly fed back to the teacher, achieving a seamless blended teaching experience²⁵.
Security and Privacy Assurance ProcessData Security: During the transmission of educational data, encryption technology, such as SSL/TLS protocol, is used to encrypt students' personal information, learning records, and other data to prevent data from being stolen or tampered with during transmission. In terms of data storage, access control technology is used so that only authorized personnel (such as teachers and administrators) can access specific data. For example, only teachers and the students themselves have permission to view student grade data, ensuring data confidentiality and integrity⁶¹⁰.
Privacy Protection: Relevant privacy regulations are followed, such as requiring explicit authorization for the use of students' personal information. In the process of data analysis, anonymization technology is used to process student data, removing personally identifiable information. For example, when analyzing student learning behavior data, student names, student IDs, and other information are replaced with anonymous identifiers, ensuring that data analysis can be performed while protecting student privacy.
3
157