
Exciting progress with our team project! We collaborated closely, turned ideas into tangible plans, and can’t wait to share the final result soon. #Teamwork #ProjectWork,

1
1

May 10
🌍 Available for online projects and partnerships. Ready to start immediately and contribute with dedication. #Freelance #ProjectWork

15
31
1,049
Exciting news 🎉. We're one step closer to restoring this Georgian landmark as scaffolding starts to go up in the Tea Room.
Keep following as we bring you regular updates as the Tea Room begins to take shape.
#ProjectWork #TeaRoom #Restoration

1
4
224
This week we're #UnderTheFloorboards of the Tea Room. At the moment the site team are busy on the joinery, getting things ready for the new ceiling that will eventually go up on the lower ground floor.
#ProjectWork

1
4
196

Mar 3
🔧 Engineering in Action 🚧
Behind every strong structure, there is smart planning and hard work.
Today I am working on my project — focusing on precision, safety, and quality.
An engineer doesn’t just build structures, ideas into reality. 💡🏗️
#EngineeringLife #ProjectWork #Civ

1
3
95

Mar 1
புதுச்சேரியில் ரூ.2,713 கோடியில் திட்டப் பணிகளை தொடங்கி வைத்தார் பிரதமர் மோடி dinakaran.com/news/primemini…
#projectwork #puducherry #modi #DinakaranNews
328

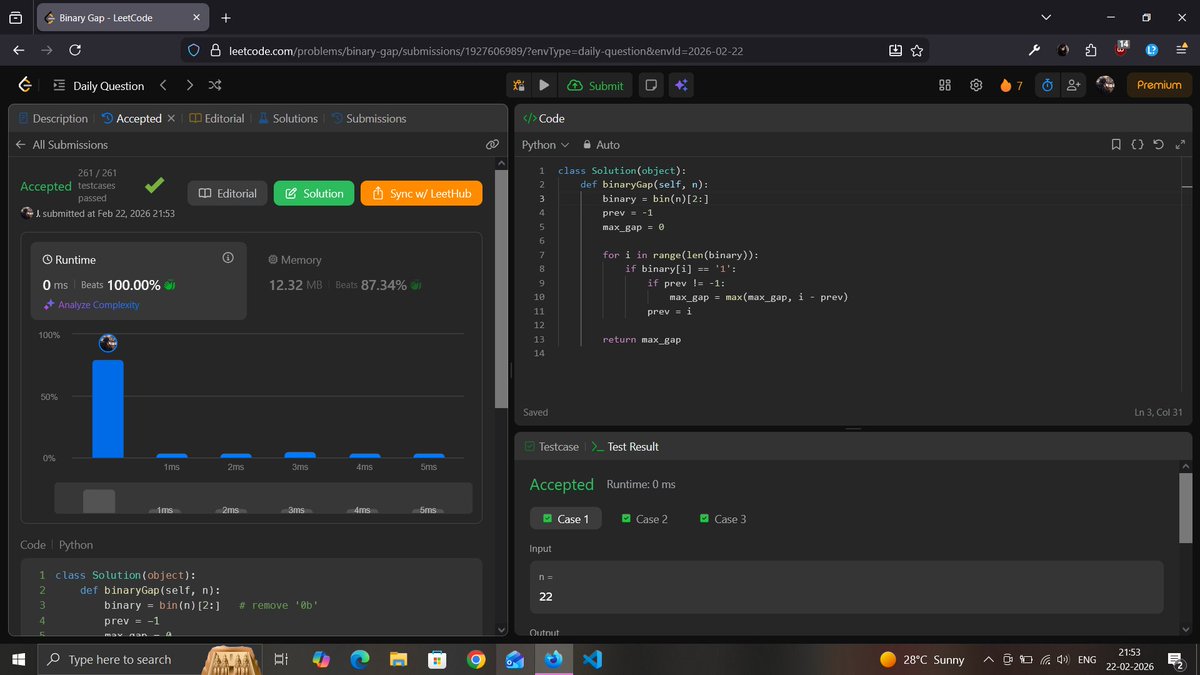
Today’s Progress Update
• Solved POTD 868: Binary Gap (very easy)
• Applied to roles
• Updated UI of my projects and made improvements
• Setting up an org and fighting errors
#LeetCode #OpenSource #CodingJourney #ProjectWork
3
20
272


2
29

Jan 14
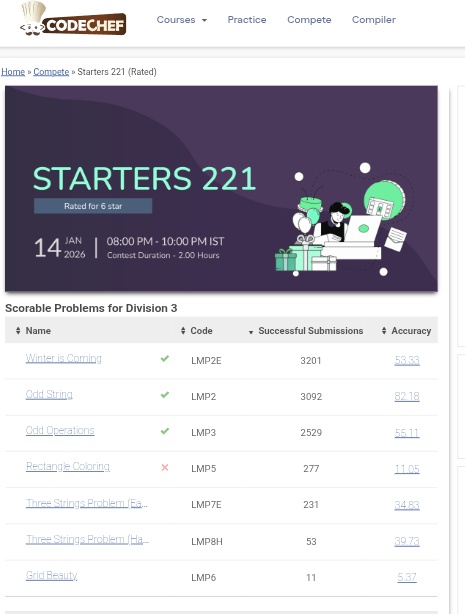
Day 9 🚀
• Solved 1 LeetCode problem
• Gave a contest — feeling happy with the performance 😊
• Made project contributions
#LeetCode #CodingLife #CompetitiveProgramming #DeveloperJourney #Consistency #ContestLife #ProjectWork #BuildInPublic 🚀
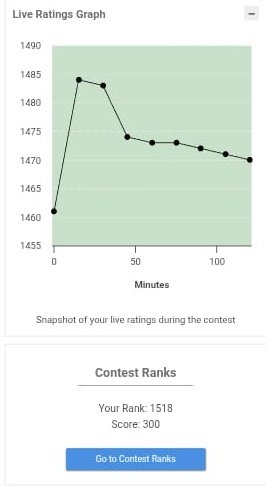

1
1
10
115

Jan 14
Happy Makar Sankranti to all!🙏💐
Happy Pongal, Happy Lohri, Happy Ughadi! 🙏
I am on a tour of beautiful Mumbai, Kokan & Goa region with the editing / post production of our project in full swing!
Let this Makar Sankranti bring a joy, happiness, hope and prosperity to all of us!
#happymakarsankranti #happylohri
#happypongal #BusinessTour #projectwork
#HappyMakarSankranti #HappyBhogi



1
4
49
Jan 8
Day 6 🚀
Gave my sem exam today — it was f*cking hard 😤
Still made a project contribution 💻🔥
#Day6 #StudentLife #SemExams #CodingLife #ProjectWork #Consistency #Grind
2
5
88

मध्यप्रदेश राष्ट्रीय सेवा योजना, महाराजा छत्रसाल बुंदेलखंड विश्वविद्यालय छतरपुर अंतर्गत विश्वविद्यालय की राष्ट्रीय सेवा योजना ईकाई द्वारा साप्ताहिक प्रोजेक्ट कार्य के तहत दीवारों के रंग रोगन का कार्य किया गया।
#MPnss #nssindia #mcbunss #projectwork




3
6
59


12 Dec 2025
finished my projectwork and heading to bed now !! <333 gngn my friends love you all MWWWAAAH!! <333
2
3
170

30 Nov 2025
Long-running agents aren’t enough on their own the future belongs to specialized multi-agent teams.
@AnthropicAI November 26, 2025 article “Effective Harnesses for Long-Running Agents” clearly outlines one of the biggest limitations of current AI agents:
👉 A single agent struggles to make consistent progress on complex, multi-hour or multi-day tasks.
Each context window resets its memory, leading to half-implemented features, lost progress, inconsistent environments, and agents prematurely claiming that a project is “done.”
Anthropic proposes a two-part solution:
1️⃣ Initializer agent sets up the environment, feature list, and initial structure
2️⃣ Coding agent makes incremental progress and leaves clean artifacts
But the most important insight from the article is this:
“Specialized agents like a testing agent, a quality assurance agent, or a code cleanup agent could do an even better job at sub-tasks across the software development lifecycle.”
🚀 @almanak recognized this long before
While designing their DeFi strategy-building infrastructure, Almanak realized early that a single “super coder agent” would never scale reliably.
Because of this, they embraced a specialized multi-agent architecture from day one.
Almanak’s Strategy Builder uses a coordinated team of agents to take a strategy from ideation to deployment:
Research Agent – analyzes market conditions
Quant Agent – designs the strategy logic
Simulation & Backtest Agent – stress-tests risk and performance
Testing Agent – performs end-to-end behavioral checks
QA Agent – validates correctness and consistency
Deployment Agent – ships the strategy to chain safely
This goes far beyond the initializer coding model described by Anthropic.
🧩 Anthropic’s findings map directly to what Almanak already built
Anthropic’s Observed ChallengeAlmanak’s SolutionAgents try to “one-shot” the entire projectWork is divided across specialized agentsContext resets cause lost progressStructured multi-agent workflow stateAgents mark features as “done” before they workQA Testing agents approve every stepEnvironment becomes messy or buggyCleanup QA agents normalize each iterationMissing or incomplete testingDeep simulations robust DeFi backtests
Anthropic is now arriving at the conclusion that single agents have limits.
Almanak has been operating with that assumption and solving it for a long time.
🎯 The takeaway: Specialized agent teams outperform single agents
A lone agent still struggles with long-horizon engineering.
But when responsibilities are split across domain-specific agents:
quality improves,
debugging becomes easier,
progress becomes consistent,
and end-to-end systems become far more reliable.
This is why Almanak’s Strategy Builder lets users run an entire multi-agent quant team without writing a single line of code.
Try it yourself:
👉 app.almanak.co/invite?code=g…

28 Nov 2025

In their latest post @AnthropicAI mentioned:
> "It seems reasonable that specialized agents like a testing agent, a quality assurance agent, or a code cleanup agent, could do an even better job at sub-tasks across the software development lifecycle."
At @almanak we knew all along and can confirm that indeed a team of specialized agents does a better job than a single coder agent.
Meet the Strategy Team writing and testing your whole DeFi strategy from ideation to deployment.
Try if for yourself: builder.almanak.co/
anthropic.com/engineering/ef…

7
1
14
567

22 Nov 2025
Received the honour of getting our internship projectwork on Vakyaganitam being released in book form by @IKS_Media both in English&Tamizh. This work summarises the 1&2 chapters of the 13th cy CE work Vakyakaranam which teaches the calculation of the longitude of various grahas.




3
8
48
1,927

16 Nov 2025
Just finished my winter jacket design assignment. Learning and improving every day ❄️🧥✨ #UX #DesignJourney
#Design
#DesignLife
#CreativeProcess
#UXDesign
#UIUX
#DesignCommunity
#StudentDesigner
#ArtStudent
#Portfolio
#ProjectWork
#Trending
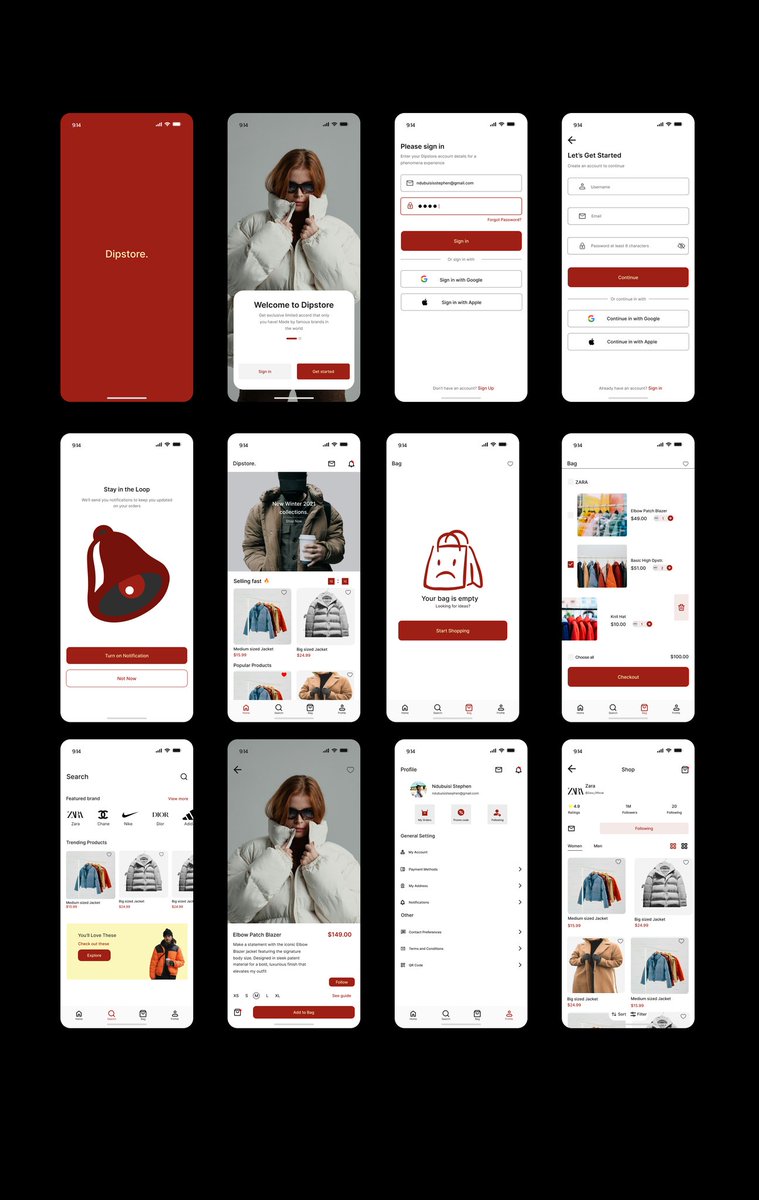

3
2
6
106

28 Oct 2025
📅 Day 35/100 – DSA Dev Grind 🚀
✅ Solved 2 questions on GFG 💻
✅ Worked on my project 🔧
Enjoying time with my school friend who has recently visited Bhopal — coding, progress, and good company all together 😄
#100DaysOfCode #DSA #ProjectWork #Consistency
2
73

8 Oct 2025
That's the Cold Bath safely tucked up while the building works are taking place. We'll be checking the water levels and condition of the bath using the handy set of steps.
#ProjectWork #ColdBath #HistoricPreservation #BathAssemblyRooms #NationalTrustSouthWest
2
2
384

30 Sep 2025
Day 216
Worked on my project today 💻✅ Feeling productive!
#CodingJourney #DevLife #Programming #ProjectWork #KeepLearning #TechLife
4
65