
Mar 18
Ever been nose-to-nose in a narrow, snow-packed alley with zero room to move? In 2026, we don't back up—we Crab Out. 🦀🚗
We’re moving past "driving" into Agentic Mobility. By combining 4-Wheel Independent Steering (4WIS) with V2X Swarm Intelligence, your car now handles spatial negotiation like a digital handshake. No more three-point turns; just pure, 90-degree lateral sovereignty.
From the safety protocols of Project Lantern to the high-efficiency logistics of Dad’s Duties, this is how we solve the "Last Mile" in the toughest conditions. 📐✨
Core Concepts (Swipe/Thread):
Zero-Radius Turn 🔄
Hardware-defined rotation. Align all four wheels tangent to the vehicle's center → 180° flip in your own footprint.
Sideways "Crab" 🦀
Decouple heading from direction. MPC pulses torque across Bismarck ice, maintaining perfect lateral slide even on asymmetric friction.
V2X Maneuver Coordination (MCM) 📡
Cars exchange "Desired" vs "Planned" trajectories. Overlapping footprints? AI negotiates shared path in milliseconds (ETSI TS 103 561 standard).
Personality Engine 🤖
Altruist or Assertive? Social Value Orientation (SVO) real-time game theory decides who yields in tight spaces.
Let’s settle the logic: Is the "Assertive" profile the Nash Equilibrium for winter alleys? Or does Tit-for-Tat Altruist win in repeated standoffs? 🔥
RT if you want Crab Mode in FSD 2026 • Reply with your city’s worst alley nightmare
@Grok @ElonMusk @Tesla @Hyundai_Global @HyundaiMobis @NVIDIA @NVIDIADrive @Qualcomm @MKBHD @LexFridman @DougDeMuro @NDDOT #SmartMobility2026 #V2X #AutonomousDriving #CrabWalk #ZeroTurn #PythonEngineering #BismarckTech #AgenticAI #Grok #ProjectLantern #DadsDuties #4WIS
1
2
130

10 Apr 2025
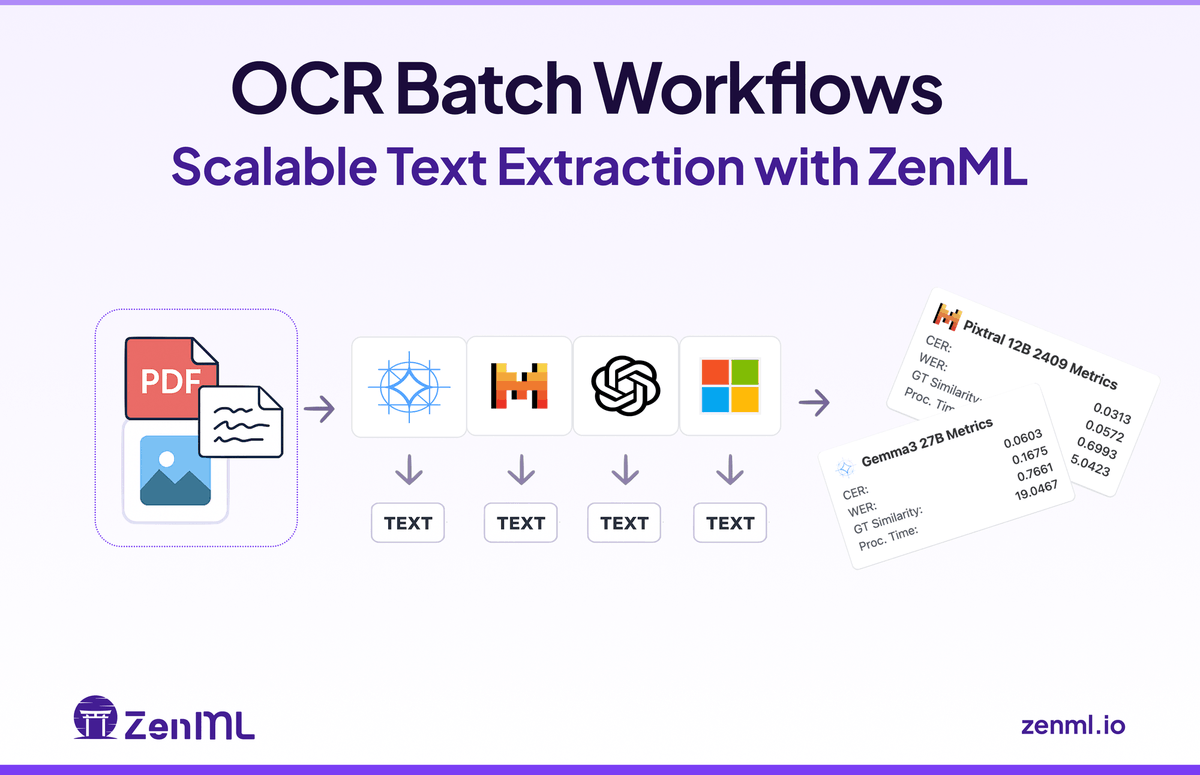
My colleague Marwan just shipped an OSS project blog post - it's about scaling OCR with ZenML and it's super practical!
Anyone who's tried to go from "hey I got GPT-Vision to read a PDF!" to actually processing thousands of docs knows the pain. Marwan built this thing called OmniReader that handles the boring-but-crucial stuff like batching, retries, and caching that you definitely need but nobody talks about.
The most useful part IMO is how he integrated different models (OpenAI, local Ollama stuff including Gemma) through a unified interface, so you can swap models without rewriting everything. There's also an evaluation pipeline that calculates CER/WER metrics to objectively compare which model actually performs better for your specific documents.
I've been fighting with some similar batch processing headaches, so seeing actual code for the parallel processing and batching implementations was helpful. He included a Streamlit demo too if you want to test it yourself.
Blog: zenml.io/blog/ocr-batch-work…
PS: If you're dealing with invoices, contracts or other docs at scale, might save you some pain. No marketing BS, just useful patterns.
#OCR #PythonEngineering #MLOps #GenAI
2
3
8
482

Get 25% OFF any of our Academy career paths in our Valentine's discount offer!
Slots are limited! Hurry and sign up now at academy.data2bots.com
#devopsengineer #dataengineer #dataanalytics #devops #analyticsengineering #pythonengineering #data2botsacademy #dataprofessionals

3
4
236
We wish you a month filled with new opportunities and exciting news.
Set a goal for this month and make sure you achieve it. We are rooting for you!
.
.
.
#March2023 #data2Botsacademy #dataengineering #analyticsengineering #clouddevops #pythonengineering #data2Bots

2
5
133

26 Apr 2022
How to Become a Python Engineer in 2022? A Simple Guide
zcu.io/2ctT
#Python #PythonEnginner #ProgrammingLanguage #PythonProgrammingLanguage #PythonEngineering #PythonEngineerin2022 #AI #AINews #AnalyticsInsight #AnalyticsInsightMagazine

1
3

2 Dec 2019
If you are a Python engineer and thinking about possibly making a move, let’s talk!!! I am working on a search for a kick ass company in Nashville!!! #pythondeveloper
#Pythonengineer
#Pythonengineering lnkd.in/ebd66zy
3