
Apr 16
🚀 Introducing RationalRewards — a reasoning-based reward model that improves image generation(t2i and editing) quality at both training and test time.
🧠 We taught reward models to think before they score, leading to more reliable feedback and reduced reward hacking during RL fine-tuning.
🔁 At test time, the same RationalRewards model performs prompt tuning by iteratively generating, scoring with reasoning, and rewriting prompts.
Here’s the surprising part 👇
test-time prompt tuning matches — sometimes beats — full RL fine-tuning, which costs 400 GPU hours.🔥
💡 This suggests an alternative to parameter tuning: your diffusion model may already have strong capabilities — prompt tuning matters.
---
🧵 Fully open-source.
✅ Code training recipes
✅ RationalRewards-8B model data
✅ Full benchmarks GCR loop
🔗 Website: tiger-ai-lab.github.io/Ratio…
🔗 GitHub: github.com/TIGER-AI-Lab/Rati…
🤗 Models & Data: huggingface.co/collections/T…
📄 Paper: huggingface.co/papers/2604.1…
---
#ImageGeneration #AIGC #RewardModels #RL #DiffusionModels #TestTimeScaling
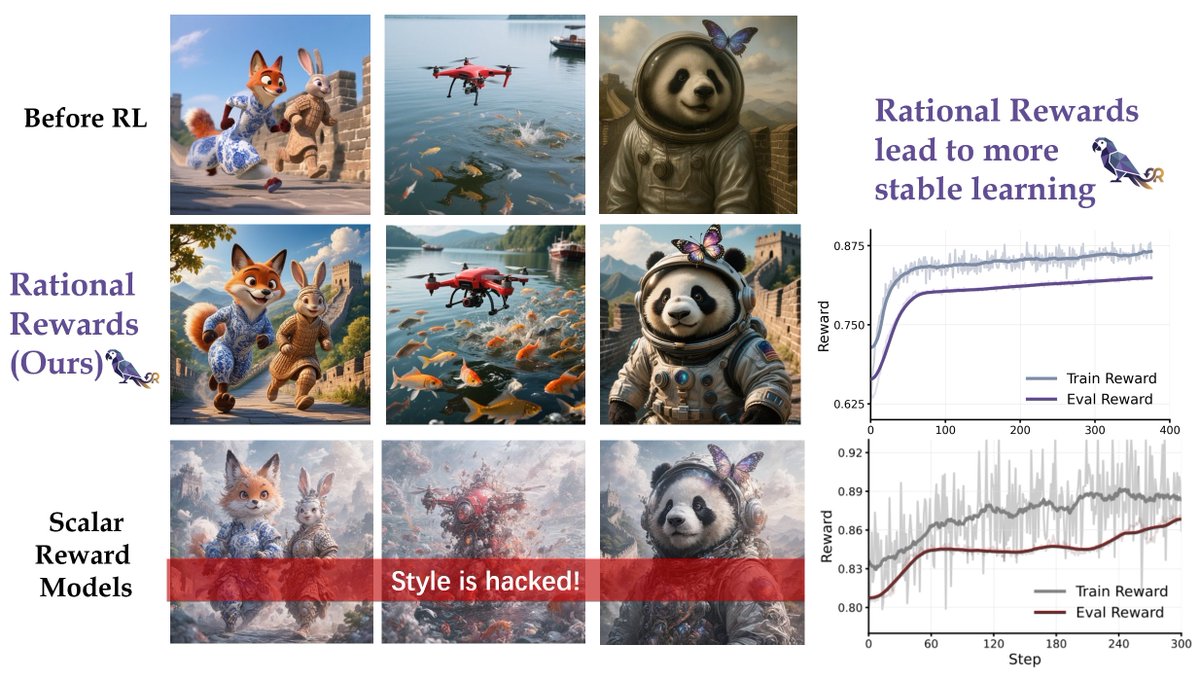
4
15
94
10,733

5 May 2025
What To Know About Delayed Gratification myfrugalbusiness.com/2025/05…
#DelayedGratification #Gratification #Reward #RewardModels #Rewards

1
8
86

2 May 2025
Check out the latest from our #AIResearch team, in this fascinating blog written by our own @kolbytn. #syntheticdata #DPO #rewardmodels #aigaming
3
24
10
1,747

7 Jan 2025
Is your Process-Level Reward Model really good? 🤔 We're thrilled to release PRMBENCH: A Fine-grained and Challenging Benchmark for Process-Level Reward Models! This new resource offers a deeper dive into PRM evaluation. Explore the paper & project page here 👇
📄[Paper Link] arxiv.org/abs/2501.03124
🌐[Project Page] prmbench.github.io/
Also, our "PRM Eval Toolkit" codebase supports evaluating different kinds of PRMs and different custom tasks, providing a universal PRM Evaluation harness. welcome to use🤗 !
📚[PRM Eval Toolkit Documentation]: github.com/ssmisya/PRMBench/…
#NLP #AI #RewardModels #Benchmark #OpenScience


4
11
1,157

17 May 2024
#RewardModels
🔥LLM Reasoners🔥 now supports advanced 🏆reward models (RM)🏆 to boost LLM reasoning!
Check out the 1st example based on Eurux-RM: shorturl.at/2Xgfy
🚀It easily boosts #llama3 8B from 0.49 to 0.73 on GSM8K
👉Eurux paper arxiv.org/abs/2404.02078v1

7
18
2,767

5. Dual Reward Models
It uses two separate reward models - one optimized for helpfulness and the other for safety.
This approach strikes a balance, avoiding the safety-helpfulness tradeoff identified in previous works.
#RewardModels
1
3
31

12 Jun 2018
In a world where consumer expectations are rising in the face of the relentless growth and sophistication of #ecommerce, the classical #RewardModels are incessantly under stress. Read how Swiss Miles & More and #Loylogic are creating the disruption. bit.ly/2JOQJKe

1
2