
Jun 10
Fingertips reach is reality~
300 points FREE to 6/30
sink-9lv.pages.dev/8dx23a
Code: VV1-75LJ-IL7I-GZ6R
2

Jun 10
Fingertips reach is reality~
300 points FREE to 6/30
sink-9lv.pages.dev/8dx23a
Code: VV1-75LJ-IL7I-GZ6R
2

Jun 5
[Tip de R] · [Paquete 📦] · astronomR: Un puente entre la ciencia de datos y el cosmos en R.
¿Trabajás con datos astronómicos y sentís que R no tiene las herramientas específicas que necesitás? ¡No te preocupes más! El paquete astronomR llega para llenar ese vacío, ofreciendo un marco estadístico robusto para analizar y visualizar datos de astronomía y cosmología.
astronomR te permite:
✔️ Análisis estadístico: Realizá análisis profundos de tus datos cósmicos con funciones diseñadas para este tipo de información.
✔️ Visualización intuitiva: Creá gráficos y exploraciones visuales para entender mejor los fenómenos espaciales.
✔️ Herramientas de cosmología: Aplicá modelos y herramientas específicas para estudios cosmológicos directamente en R.
Lo más valioso de astronomR es que democratiza el acceso a análisis astronómicos complejos, permitiendo que tanto expertos como entusiastas exploren el universo con R.
💡 Tip
Si te dedicás a la astrofísica, la cosmología o simplemente sos un entusiasta de los datos espaciales, probá astronomR. ¡Te va a ahorrar mucho tiempo y simplificar tareas complejas!
🔗 github.com/samrit2442/astron…
✍️ samrit2442
#RStats #RStatsES #Rtips #DataScience
3
21
1,114
Jun 4
[Tip de R] · [Paquete 📦] · tidywikidatar: Explora y consulta Wikidata directamente desde R, obteniendo datos limpios y organizados.
¿Querés usar la riqueza de datos de Wikidata, pero le esquivás a las consultas SPARQL o a las listas anidadas que te devuelve la API? El paquete tidywikidatar te permite interactuar con esta enciclopedia de datos de una manera súper amigable, sin que necesites ser un experto en SPARQL, y te entrega los resultados en data frames prolijos y fáciles de usar.
✔️ Transformación automática: Obtiene directamente data frames ordenados y fáciles de usar, sin procesamientos extra.
✔️ Caching inteligente: Guarda las consultas en una base de datos local (SQLite y otros) para cargar datos rapidísimo la próxima vez que los necesites.
✔️ Interfaz amigable: Accedé a la información de Wikidata sin lidiar con SPARQL ni con estructuras de datos complejas.
💡 Tip
Integralo con el tidyverse para limpiar, transformar y visualizar la información de Wikidata como cualquier otro dataset. Pensalo como tu puente directo a un universo de conocimiento estructurado.
🔗 edjnet.github.io/tidywikidat…
✍️ @EdjNet
#RStats #RStatsES #Rtips #DataScience
2
6
481
May 29
[Tip de R] · [Paquete 📦] · labelled: ¡Manejá tus metadatos!
¿Te frustra perder las etiquetas de tus variables y valores cuando importás datasets a R? ¡No te preocupes más! El paquete labelled es tu aliado para manipular y preservar toda esa información crucial: etiquetas de variables, etiquetas de valores y valores perdidos definidos, especialmente útil si venís de herramientas como SPSS.
✔️ var_label(): Con esta función, podés añadir, consultar o modificar fácilmente las etiquetas descriptivas de tus variables. ¡Tu código y tus informes van a ser mucho más claros!
✔️ val_labels(): Mantené las descripciones de los valores de tus variables (por ejemplo, 1="Masculino", 2="Femenino"), incluso si los tenés como números. ¡Fundamental para el análisis de encuestas!
✔️ na_values(): Definí y gestioná valores perdidos específicos (como -99 para "No aplica"), no solo los NAs estándar. ¡Más precisión en tus análisis y menos ambigüedad!
💡 Tip
Integrá labelled con el paquete haven apenas importás tus datos. Esto te va a asegurar que toda la metadata se preserve intacta desde el principio, ahorrándote un montón de tiempo en reprocesar etiquetas y garantizando la consistencia de tus análisis.
🔗 info en comentarios 👇🏼
✍️ Joseph Larmarange
#RStats #Rtips #RStatsES #labelled #Metadata #DataManagement #DataScience

1
8
32
1,266
May 28
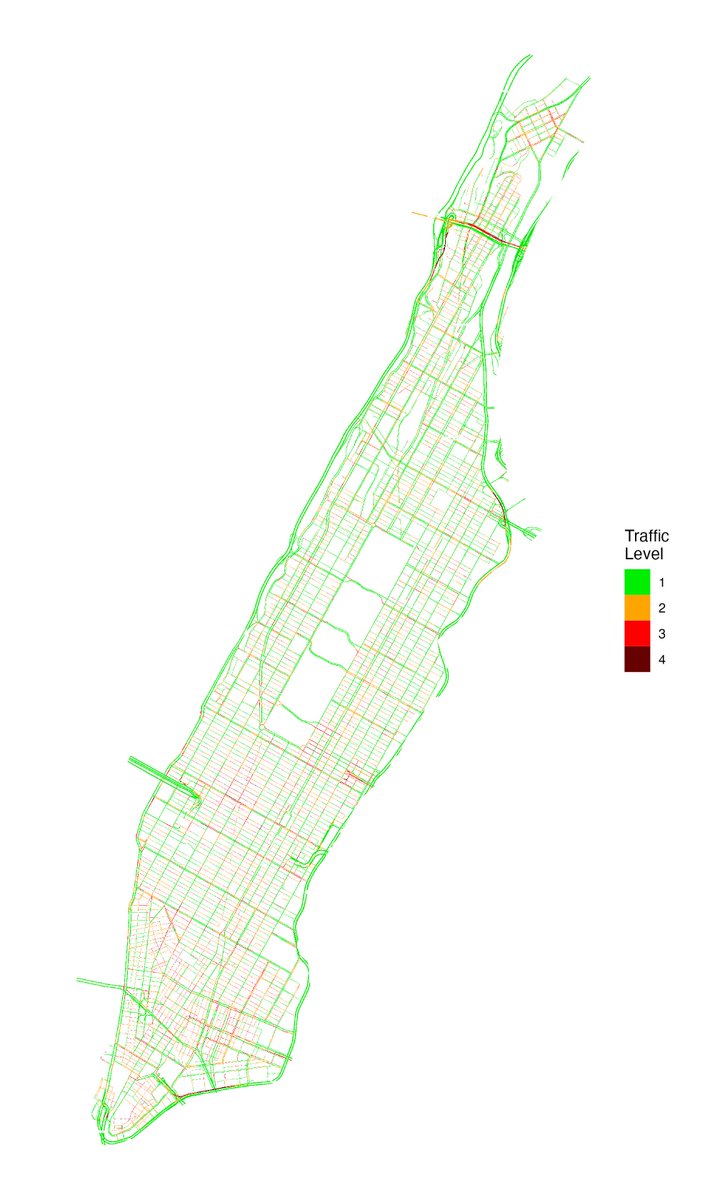
[Tip de R] · [Paquete 📦] · googletraffic: Un paquete para generar datos de tráfico georreferenciados directamente desde la API de Google Maps.
Necesitás datos de tráfico en tiempo real para tus análisis espaciales pero no sabés cómo obtenerlos? El paquete googletraffic te permite crear rasters georreferenciados con información de tráfico de Google Maps, facilitando la integración con otras fuentes de datos y análisis espaciales.
✔️ Crea rasters de tráfico georreferenciados: Obtené una capa espacial con la densidad de tráfico para un área y momento específico.
✔️ Facilita el análisis espacial avanzado: Podés combinar estos datos con otras capas geográficas (población, infraestructura) para entender patrones de movilidad, congestión y su impacto.
✔️ Acceso a datos en tiempo real: Usá la información más reciente de Google Maps para tus proyectos y tomá decisiones informadas.
💡 Tip
Acordate que para usar este paquete vas a necesitar una clave de API de Google Maps. Asegurate de configurarla correctamente con la función google_api_key() para una gestión eficiente de tus credenciales.
🔗 dime-worldbank.github.io/goo…
✍️ DIME-World Bank
#RStats #Rtips #RStatsES #GoogleMaps #DatosDeTrafico #Georreferenciacion
38
157
5,279
May 25
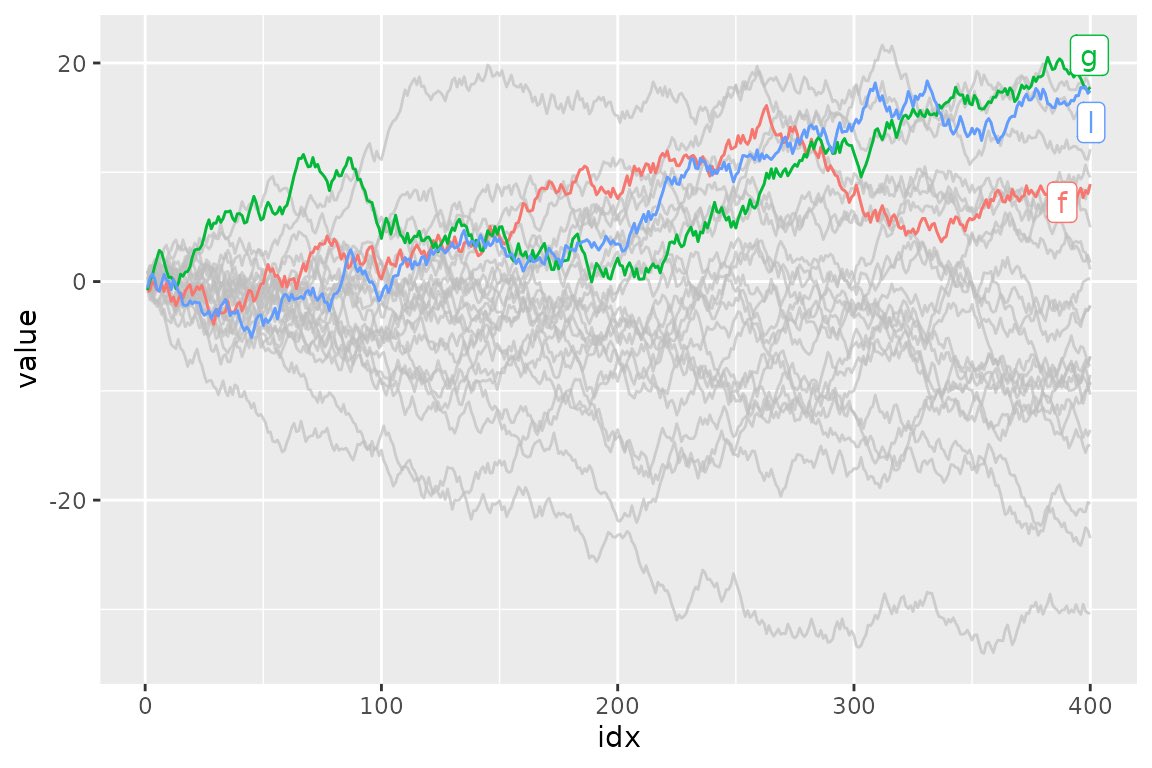
[Tip de R] · [Paquete 📦] · gghighlight: Resaltá líneas y puntos en tus gráficos de ggplot2 para explorar mejor tus datos.
¿Se te mezclan las líneas o puntos en tus gráficos de ggplot2 cuando tenés muchas categorías? ¿Querés destacar solo una parte de tus datos sin crear un gráfico nuevo? El paquete gghighlight te permite resaltar geoms (líneas, puntos, etc.) directamente en tus gráficos de ggplot2 de forma condicional, haciendo que la exploración visual sea mucho más eficiente.
✔️ gghighlight(): Te permite definir una condición lógica (ej. variable > valor, nombre == "categoria") para resaltar automáticamente los elementos que la cumplen, haciendo que lo importante salte a la vista.
✔️ Funcionalidad de 'unhighlight': Los elementos no resaltados se atenúan (bajan la opacidad, cambian a gris), sin borrarlos, manteniendo el contexto general del gráfico.
✔️ Integración perfecta con ggplot2: Agregalo como una capa más ( gghighlight(condicion)) y listo, sin complicaciones ni reescritura de tu código base.
💡 Tip
Usá gghighlight() después de tus capas de geom para aplicarlo fácilmente. Experimentá con los argumentos unhighlight_params para controlar cómo se ven los elementos no resaltados (color, alpha, size) y ajustá la estética a tus necesidades. Podés usarlo de forma interactiva en RStudio para explorar diferentes condiciones rápidamente.
🔗 yutannihilation.github.io/gg…
✍️ Hiroaki Yutani
#RStats #RStatsES #Rtips #DataScience


9
75
2,349
May 20
[Tip de R] · [Paquete 📦] · FakeDataR: Generá datasets sintéticos que cuidan la privacidad, espejando la estructura de tus datos reales.
¿Necesitás compartir un dataset para pedir ayuda, desarrollar un modelo o testear tu código, pero te preocupa la privacidad de los datos originales? ¡Olvidate de editar a mano y arriesgarte a exponer información sensible! El paquete FakeDataR te permite crear copias sintéticas de tus datasets que imitan la estructura, tipos de datos y niveles de factores, pero sin la información sensible. Es la solución perfecta para trabajar de forma segura y eficiente.
✔️ Generá datasets sintéticos que mantienen la estructura (esquema, tipos, niveles de factores, rangos y valores faltantes) de tus datos originales, ¡pero con contenido "falso"!
✔️ Prepará bundles de datos sintéticos con esquemas JSON y guías, listos para usar directamente con Large Language Models (LLMs), agilizando tus workflows de IA.
✔️ Construí datos falsos directamente desde tablas de bases de datos SQL sin necesidad de leer las filas reales, protegiendo la privacidad desde el origen.
✔️ Tené el control para enmascarar o eliminar campos sensibles, asegurándote de que solo compartís lo que es seguro.
💡 Tip
Usá FakeDataR para crear entornos de desarrollo y pruebas seguros. Podés compartir estos datasets sintéticos con colaboradores o LLMs sin riesgo, ya que todo el proceso ocurre en tu máquina, ¡sin subir tus datos reales a la nube!
🔗 zobaer09.github.io/FakeDataR…
✍️ Zobaer Khan
#RStats #RStatsES #Rtips #DataScience

1
35
152
4,532
May 18
[Tip de R] · [Paquete 📦] · worldfootballR: Extraé y limpiá datos de fútbol mundial de fuentes como FBref, Transfermarkt y Understat.
¿Se viene el mundial y soñás con analizar los datos de tus equipos y jugadores favoritos sin perder horas en la web? El paquete worldfootballR es tu aliado perfecto. Te permite obtener estadísticas detalladas de partidos, equipos y jugadores de las principales ligas y competiciones, directamente en R. Decile chau a copiar y pegar tablas, y empezá a analizar de verdad.
✔️ Accedé a resultados de partidos, stats de jugadores y equipos de FBref de forma eficiente.
✔️ Consultá valores de mercado y transferencias de jugadores directamente desde Transfermarkt.
✔️ Recopilá datos avanzados de Understat, como ubicación de tiros y métricas de Expected Goals (xG).
✔️ Unificá fuentes de datos populares para un análisis futbolístico completo y eficiente, optimizando tu flujo de trabajo.
💡 Tip
Para asegurar que tenés la última versión con todas las actualizaciones, instalá worldfootballR directamente desde GitHub (la versión de CRAN está desactualizada):
devtools::install_github("JaseZiv/worldfootballR")
🔗 jaseziv.github.io/worldfootb…
✍️ Jase Ziv
#RStats #Rtips #RStatsES #Futbol #DataScience #Deportes #FBref #Transfermarkt #Understat

12
61
2,840
May 14
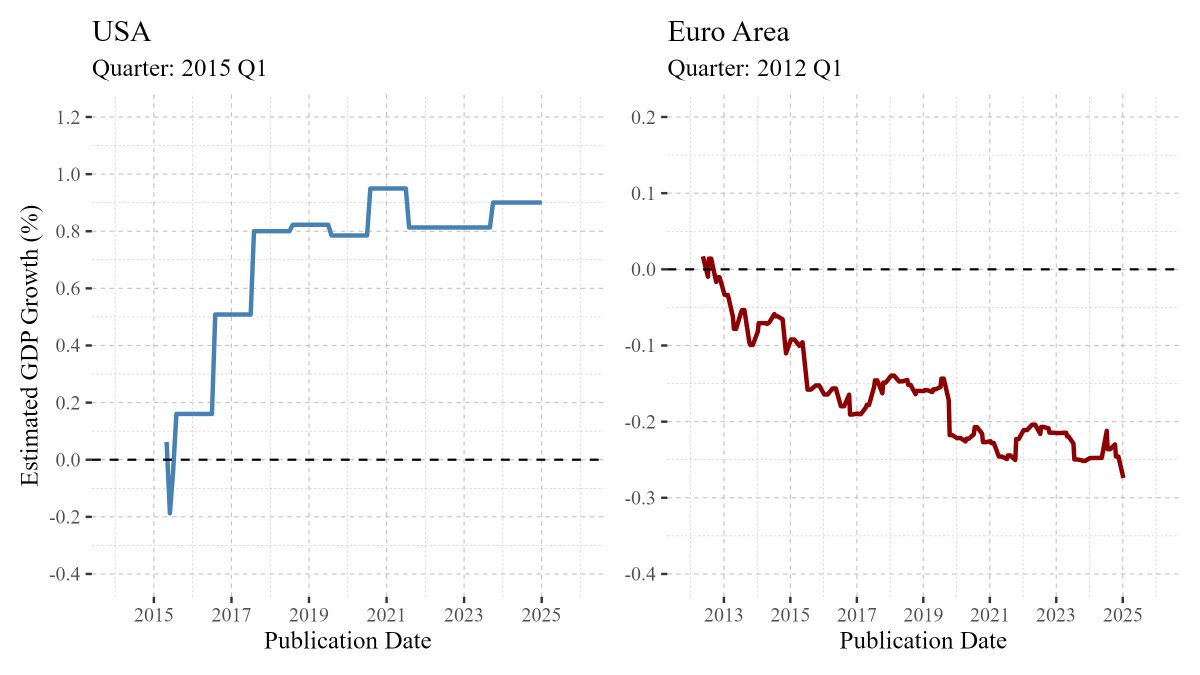
[Tip de R] · [Paquete 📦] · reviser: herramientas para limpiar, analizar y visualizar la revisión de series de tiempo.
¿Te frustra que los datos económicos clave cambien después de su publicación inicial? Esos "ajustes" o revisiones pueden alterar completamente tu análisis o decisiones.
El paquete reviser está diseñado para que analices y entiendas el impacto de estas revisiones en series de tiempo, especialmente en datos económicos. Te ayuda a limpiar, visualizar y evaluar cómo y por qué cambian los datos con el tiempo, lo cual es fundamental para analistas y responsables de políticas.
✔️ Te permite convertir entre diferentes formatos de datos de vintages (triángulos de revisión wide y vintages long) para que trabajes cómodo y sin fricciones.
✔️ Extrae versiones específicas de las series (releases) para que compares y entiendas los cambios puntuales sin esfuerzo.
✔️ Calcula series de revisiones para que cuantifiques la magnitud y dirección de los ajustes de forma precisa.
✔️ Visualiza rutas de vintages para que veas la evolución de los datos a lo largo del tiempo de forma clara e intuitiva.
✔️ Resume propiedades clave de las revisiones como el sesgo, la dispersión o la autocorrelación, dándote un diagnóstico completo de la calidad de los datos.
✔️ Identifica releases eficientes y estima modelos de espacio de estados para hacer nowcasting de revisiones, mejorando tus pronósticos.
💡 Tip
Cuando trabajes con datos sujetos a revisiones, usá reviser no solo para detectarlas, sino para incorporarlas en tu análisis de forma estructurada. Entender el sesgo o la volatilidad de las revisiones puede mejorar significativamente la robustez de tus modelos predictivos y la solidez de tus decisiones.
✍️ Christoph Sax (a través de rOpenSci)
🔗 docs.ropensci.org/reviser/
#RStats #RStatsES #Rtips #DataScience


1
20
107
4,017
May 13
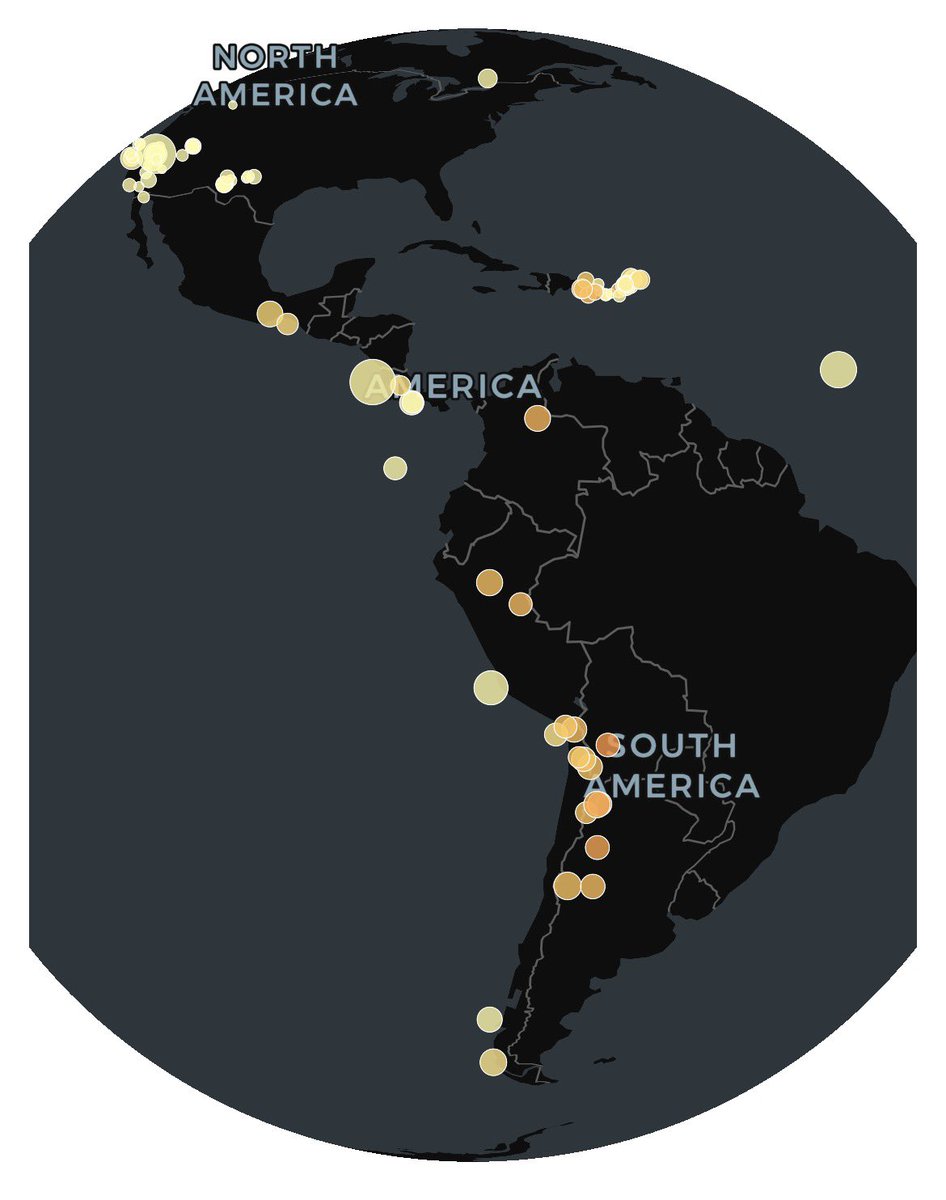
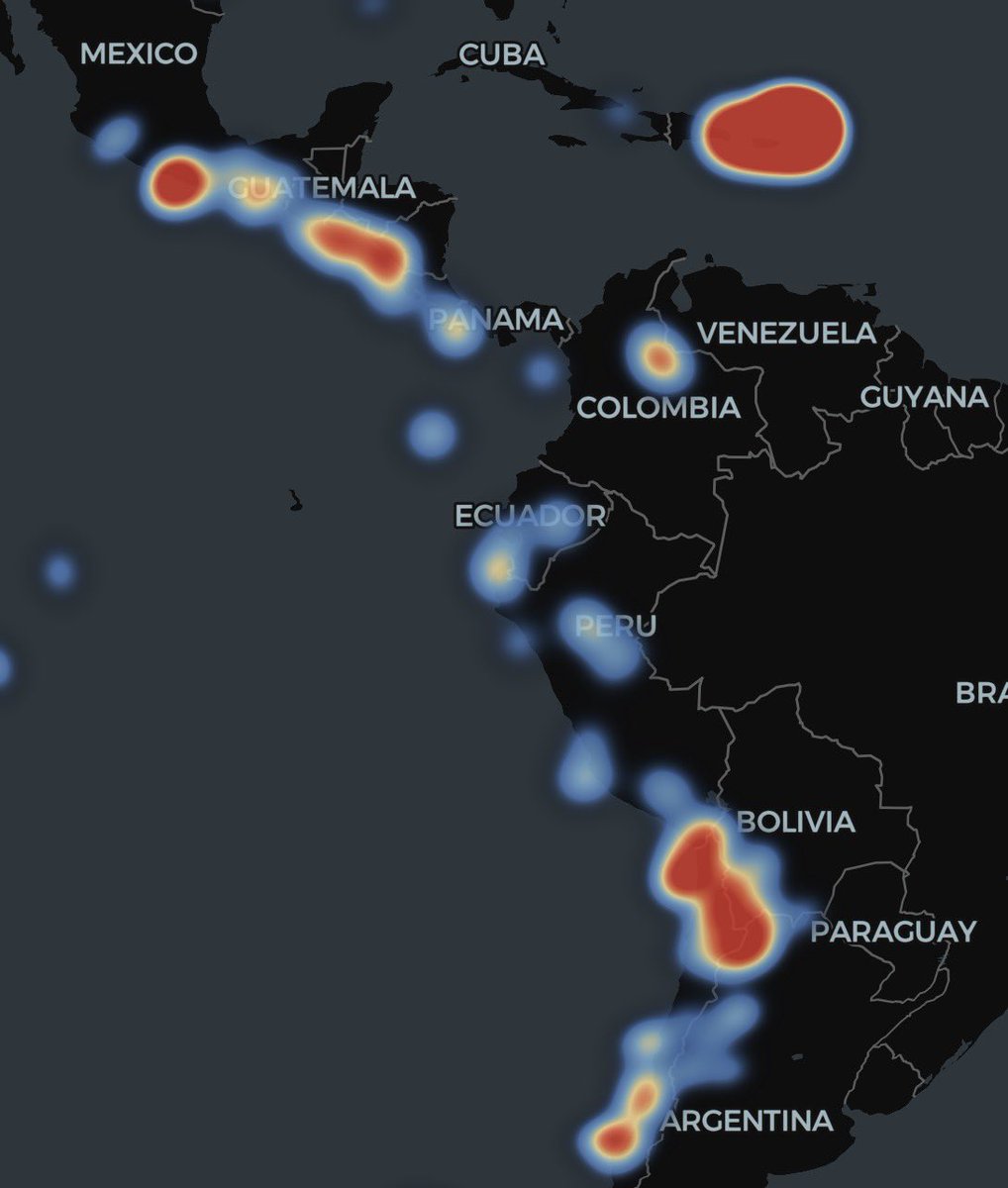
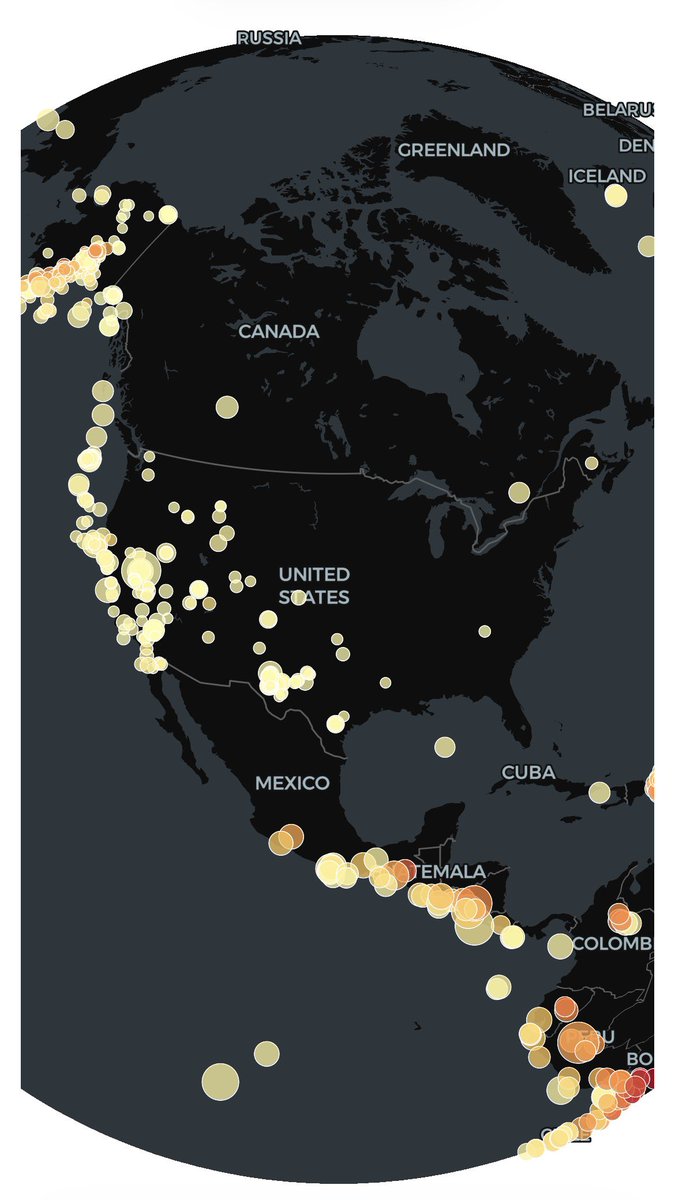
🎯 [TIP de R] - [PAQUETE 📦] - ¿Necesitás analizar datos de terremotos en R y querés integrarlos en tus mapas espaciales sin dolores de cabeza?
Te presentamos `eqr`, el paquete que te conecta directamente con los datos de terremotos del USGS (U.S. Geological Survey) desde R.
`eqr` es un envoltorio (wrapper) de R super ligero que se conecta con el servicio web FDSN de USGS. Lo más copado es que te devuelve los resultados como objetos `sf` (simple features), ¡lo que significa que los podés usar directamente en tus flujos de trabajo espaciales para hacer mapas espectaculares o análisis geográficos sin una línea extra de conversión!
¿Te preocupan los límites de datos? `eqr` se encarga automáticamente del límite de 20.000 eventos de USGS. Usa una paginación inteligente por bloques, así que vos solo pedís los datos y el paquete se encarga de traer todo lo que necesitás, incluso si son muchísimos eventos.
✔️ Beneficios:
✔️ Integración espacial perfecta: Los datos ya vienen como `sf`, listos para tus mapas y análisis geoespaciales con paquetes como `ggplot2`, `leaflet`, o `tmap`, sin necesidad de transformar nada.
✔️ Acceso directo a datos USGS: Olvidate de descargar archivos manualmente; obtené la información sísmica más reciente y oficial directamente en tu sesión de R con una sola función.
✔️ Manejo automático de grandes volúmenes: No te estreses por los límites de eventos o la paginación de APIs; `eqr` los gestiona por vos, trayéndote todos los datos que pedís de forma eficiente.
🔥 Tip: Si querés traer solo terremotos recientes y con una magnitud mínima, combiná los argumentos `start_time`, `end_time` y `min_magnitude`. Por ejemplo:
```R
library(eqr)
# Terremotos M4 del último mes
terremotos_recientes <- get_quakes(
start_time = Sys.time() - 30 * 86400,
end_time = Sys.time(),
min_magnitude = 4.0
)
print(terremotos_recientes)
```
¿Qué tipo de análisis espacial harías vos con datos de terremotos? ¡Contanos en los comentarios!
🌐 eqr-98e563.gitlab.io/index.h…
#RStats #RStatsES #Rtips #DataScience

8
38
1,331
May 12
[Tip de R] · [Recurso 🎯] · ¡Descubrí cómo la IA de Claude puede potenciar tu trabajo con R!
Si sos usuario de R y te sentís un poco perdido entre tantas herramientas de Inteligencia Artificial para programar, este recurso te va a venir bárbaro. Isabella Velásquez armó un compilado muy útil de "Skills" para Claude AI, creadas por la propia comunidad, y pensadas especialmente para quienes usamos R.
Este post es un atajo directo a las habilidades de Claude AI que son más relevantes para los desarrolladores de R. No esperes ver outputs de Claude, sino más bien una guía que te lleva directo a las mejores "Skills" ya desarrolladas. Esto te permite explorar y probar por tu cuenta, adaptándolas a tus necesidades específicas.
✔️ Beneficios:
✔️ Ahorrás tiempo: Olvidate de buscar entre miles de prompts, acá tenés un atajo a lo más útil y probado por la comunidad.
✔️ Soluciones a medida para R: Las "Skills" están pensadas específicamente para tu flujo de trabajo con R, resolviendo problemas reales.
✔️ Exploración guiada: Te da los puntos de partida para que pruebes y adaptes la IA a tus proyectos, sin sentirte abrumado.
🔥 Tip: No te quedes solo con lo que ves; usá estas "Skills" como base para crear las tuyas propias y compartilas con la comunidad. ¡Así crecemos todos y la IA se vuelve más nuestra!
¿Ya probaste alguna herramienta de IA para R? ¡Contanos tu experiencia y cuál te resultó más útil!
🌐 rworks.dev/posts/claude-skil…
✍🏼 Isabella Velásquez
#RStats #RStatsES #Rtips #DataScience
1
8
66
2,640
May 8
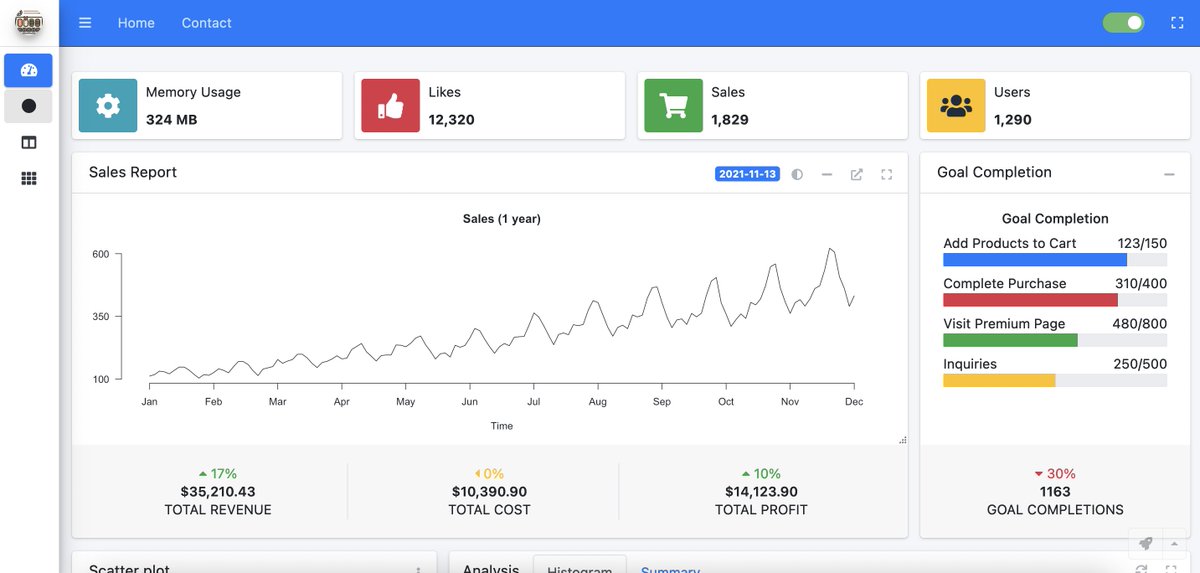
[Tip de R] · [Recurso 🎯] · ¿Cansado de dashboards Shiny que siempre se ven igual y sin funcionalidades extra? Descubrí shidashi, un sistema de plantillas modular que va a llevar tus apps al siguiente nivel.
shidashi es un paquete revolucionario que te permite crear dashboards Shiny con una estética moderna y funcionalidades avanzadas sin que tengas que ser un experto en CSS o JavaScript. Olvidate de arrancar de cero con el diseño, shidashi te da una base sólida y flexible para que tus aplicaciones no solo sean potentes, sino también visualmente impactantes.
Este sistema viene con plantillas por defecto (basadas en AdminLTE) que incluyen temas claro y oscuro, y un montón de widgets HTML listos para usar. Lo más genial es que también integra soporte para agentes de IA tipo chatbot, notificaciones, barras de progreso súper cancheras y paneles que se "dan vuelta" para mostrar información adicional. Además, facilita la sincronización de inputs entre sesiones y el redimensionamiento de gráficos, todo pensado para una mejor experiencia de usuario.
✔️ Beneficios:
✔️ **Diseño profesional instantáneo**: Dale a tus dashboards Shiny una apariencia moderna y pulida con muy poco esfuerzo, sin necesidad de escribir código CSS complejo.
✔️ **Funcionalidades avanzadas listas para usar**: Ahorrá tiempo implementando características como temas claro/oscuro, redimensionamiento de gráficos o sistemas de notificación, ya que shidashi las incluye por defecto.
✔️ **Desarrollo ágil y enfocado**: Usá las plantillas modulares para armar tu aplicación más rápido, permitiéndote concentrarte en la lógica y los datos de tu proyecto.
🔥 Tip: Podés instalar shidashi desde CRAN con install.packages("shidashi"). ¡Después explorá sus demos para ver todas las posibilidades y usá el asistente de proyectos de RStudio para empezar un nuevo dashboard con sus plantillas!
↪ dipterix.org/shidashi/
¿Cuál es la característica que más te cuesta implementar en tus dashboards Shiny y te gustaría que viniera "de fábrica"? ¡Contanos!
#RStats #RStatsES #Rtips #DataScience

7
41
1,662
May 7
[Tip de R] · [Paquete 📦] · overlay: Creá imágenes atractivas y con estilo de tus gráficos y tablas de R.
¿Cansado/a de copiar y pegar tus gráficos de R en PowerPoint o editarlos manualmente para un look más "pro"? El paquete overlay te permite transformar tus objetos de ggplot2, tablas de gt y hasta fragmentos de código en imágenes dinámicas, con efectos de perspectiva y transparencia, ¡todo desde R! Es ideal para presentaciones, publicaciones y redes sociales que buscan impactar visualmente.
✔️ overlay_plot() y overlay_gt(): Convertí tus gráficos de ggplot2 y tablas de gt en imágenes magick listas para editar.
✔️ overlay_code(): Mostrá tu código de forma estética, como si fuera una imagen de Carbon.sh, pero integrada en tu flujo de trabajo.
✔️ overlay_composite(): Combiná tus elementos con imágenes de fondo, aplicá distorsiones de perspectiva y ajustá la transparencia para un efecto visual único y profesional.
💡 Tip
Integrá overlay en tus scripts de R Markdown o Quarto para generar automáticamente materiales visuales de alta calidad y reproducibles para tus informes o posts. Olvidate del trabajo manual y repetitivo y concentrate en la creación de contenido.
✍️ Luis D. Verde Arregoitia
- luisdva.github.io/overlay/
#RStats #RStatsES #Rtips #DataScience


15
64
2,934
May 6
📬 Salió la edición #11 del newsletter de Estación R.
Algunos highlights de esta semana:
✔️ Apache Arrow 24.0.0 ya está disponible: 259 issues resueltos y mejor manejo de CSVs esparsos. Si laburás con datos grandes, no te lo saltees.
✔️ El R Consortium confirmó que en 2026 financia useR!, LatinR, Rencontres R y más. La comunidad sigue creciendo y eso se nota.
✔️ {logrittr}: un operador que loguea cada paso de tu pipeline {dplyr} (filas, columnas, tiempo de ejecución). Oro puro para auditoría y producción.
✔️ Referente de la semana: Andrew Heiss , profesor en Georgia State. Sus cursos abiertos de ggplot2 y análisis causal con R están entre lo mejor que vas a encontrar online (y son gratis).
✔️ Y los eventos que se vienen: Rencontres R, useR! - The R User Conference 2026 y el LatinR
¿Querés recibirlo cada semana en tu correo? ¡Sumate! 📪 estacion-r.com/newsletter
#RStats #RStatsES #Rtips

1
5
552
May 5
[Tip de R] · [Paquete 📦] · datadrivencv: Creá CVs personalizados desde hojas de cálculo con R.
¿Estás cansado de que tu CV se desarme cada vez que agregás una nueva experiencia o querés cambiar el formato? ¡Uf! Es un garrón. El paquete datadrivencv te permite mantener el contenido de tu CV en un formato estructurado (como una planilla de cálculo) y luego generar distintas versiones con diseños personalizados, sin dolores de cabeza.
✔️ Separación de contenido y formato: Mantené tus datos (experiencia, educación, habilidades) en un archivo simple (CSV, Google Sheet) y el diseño en otro. ¡Así, los cambios de formato no arruinan nada!
✔️ Generación flexible: Desde los mismos datos, podés generar diferentes versiones de tu CV (ej. una más corta para una postulación, otra completa para tu web) ajustando solo el template.
✔️ Automatización: Olvidate de copiar y pegar. Una vez configurado, solo actualizás tu planilla y generás el CV actualizado con un solo comando.
💡 Tip
Pensá en tu CV como una base de datos. Usá Google Sheets o un CSV para guardar toda tu información. Cuando necesites actualizar, solo editás esa planilla y listo. datadrivencv hará el resto. Explorá las plantillas que trae el paquete o creá las tuyas propias usando R Markdown para una personalización total.
🌐 github.com/nstrayer/datadriv…
✍🏼 nstrayer
#RStats #RStatsES #Rtips #DataScience



14
69
2,689
Apr 30
[Tip de R] · [Paquete 📦] · logrittr: Un operador de pipe verboso para registrar tus pipelines de dplyr.
¿Alguna vez sentiste que tus pipelines de dplyr son una "caja negra"? Hacés un montón de transformaciones y solo ves el resultado final, pero te preguntás: ¿qué pasó en cada paso? ¿Se perdieron filas? ¿Se agregaron columnas inesperadas?
El paquete logrittr te trae una solución genial. Inspirado en los logs de SAS DATA step, introduce un nuevo operador de pipe, %>=%, que te da un feedback detallado de cada etapa de tu pipeline. Es como tener un supervisor en cada transformación que hacés.
✔️ Registra recuentos de filas: Sabés exactamente cuántas filas tenés después de cada mutate, filter o join. ¡Adiós a las pérdidas misteriosas!
✔️ Monitorea columnas: Registra cuántas columnas tenés y si se agregaron o eliminaron en cada paso. Ideal para depurar y entender la estructura de tus datos.
✔️ Mide tiempos: Ves cuánto tarda cada operación, ayudándote a identificar cuellos de botella y optimizar tu código.
✔️ Soporte para pipelines anidados: No importa lo compleja que sea tu lógica, logrittr te sigue el ritmo.
✔️ Opciones configurables: Podés ajustar el ancho de visualización, el formato de los números y hasta el idioma del log.
💡 Tip
Para empezar a usarlo, simplemente reemplazá tus pipes %>% (o |>) por %>=% en tus pipelines de dplyr. Es un cambio mínimo con un impacto enorme en la claridad y depuración de tu código. ¡Tu yo del futuro te lo va a agradecer!
info en el 🧵
✍️ Guillaume Pressiat
#RStats #RStatsES #Rtips #DataScience

1
11
66
1,876
Apr 29
[Tip de R] · [Paquete 📦] · pkgmatch: Encontrá paquetes de R que coincidan con descripciones de texto o con otros paquetes existentes.
¿Necesitás encontrar un paquete de R pero no recordás el nombre exacto? ¿O querés saber qué otros paquetes hacen algo similar a uno que ya conocés?
¡El paquete pkgmatch es tu solución! Te ayuda a descubrir herramientas en CRAN, rOpenSci o Bioconductor, usando modelos de lenguaje para encontrar las mejores coincidencias.
✔️ Buscá paquetes con una descripción de texto: ingresá lo que querés hacer y pkgmatch te sugiere opciones relevantes.
✔️ Encontrá paquetes similares a los que ya usás: ideal para descubrir alternativas o complementos a tus herramientas favoritas.
✔️ Accedé a un catálogo inmenso de CRAN, rOpenSci y Bioconductor, todo de forma inteligente y rápida.
💡 Tip
Usá pkgmatch cuando estés explorando un nuevo dominio en R o buscando maneras más eficientes de hacer algo. Es como tener un experto en paquetes siempre disponible para ayudarte a navegar el ecosistema de R.
🔗 docs.ropensci.org/pkgmatch/
✍️ rOpenSci
#RStats #RStatsES #Rtips #DataScience
4
19
704
Apr 27
[Tip de R] · [Paquete 📦] · duckh3: Integrá el sistema de indexación H3 de Uber con R y DuckDB para análisis geoespacial rápido y escalable.
¿Trabajás con datos geoespaciales gigantes y sentís que R se arrastra? ¿O quizás necesitás la eficiencia de H3 y DuckDB sin dejar tu ambiente de R?
El paquete duckh3 es la solución que conecta el potente sistema de indexación jerárquica H3 de Uber y la velocidad de DuckDB directamente en R, sin complicarte la vida. Te permite analizar y manipular grandes datasets espaciales (y no espaciales) de forma súper eficiente.
✔️ Análisis H3 escalable Te da funciones rápidas y eficientes para manejar grandes volúmenes de datos espaciales y no espaciales usando el sistema de indexación H3.
✔️ Integración fluida Conecta el poder de la extensión H3 de DuckDB con tu ecosistema R (dplyr, sf, duckspatial), para que no tengas que cambiar de herramienta.
✔️ Rendimiento optimizado Acelerá tus consultas y manipulaciones de datos geoespaciales aprovechando la potencia analítica de DuckDB sin salir de R. Es compatible con data frames, tibbles y objetos dbplyr.
💡 Tip
Si ya usás {duckspatial}, te va a resultar súper familiar, ya que {duckh3} sigue una API similar. Es ideal para cuando buscás rendimiento a la hora de trabajar con celdas H3 y grandes bases de datos directamente desde R.
🌐 github.com/Cidree/duckh3
✍🏼 Cidree
#RStats #RStatsES #Rtips #DataScience

14
59
2,079
Apr 24
[PAQUETE 📦] - [Tip de R] · shinydataviewer: Un módulo de Shiny para visualizar datos tabulares de forma interactiva.
¿Necesitás mostrar tus datos en una app de Shiny de forma prolija y con funcionalidades avanzadas, pero no querés armar todo desde cero? El paquete shinydataviewer te trae un módulo reutilizable para que tus usuarios puedan explorar tablas de datos como un pro.
✔️ data_viewer_ui() y data_viewer_server(): Integrá fácilmente un visualizador de tablas interactivas en tu app Shiny, con funcionalidades listas para usar y una estética moderna.
✔️ Tablas interactivas con reactable y bslib: Tus datos se verán geniales y serán fáciles de explorar, con búsqueda, filtrado y paginación que mejoran la experiencia de usuario.
✔️ Resumen de variables en sidebar: Tus usuarios pueden obtener un pantallazo rápido de cada columna (tipo de dato, valores únicos, distribución) sin salir de la vista principal.
💡 Tip
Usá este módulo en diferentes partes de tu app para mostrar distintos datasets sin reinventar la rueda. Es ideal para dashboards que requieren exploración de datos.
🌐 ryan-w-harrison.github.io/sh…
✍️ Ryan W. Harrison
#RStats #RStatsES #Rtips #DataScience


16
76
1,848