
I've been in a weird place when it comes to my new game in terms of showing it in the early stages like I did with SBVR
Should I be more professional and not show the games progress if it looks bad?
We aren't focused on polish just gameplay. So I'm glad people liked it
May 20

Would love to see more of the jank
3
2
22
4,478

Apr 1
Usei um Squad do AIOX para varrer todo código do Claude Code que vazou hoje, tem MUITA coisa interessante e vou fazer vários posts falando sobre isso.
Tomara que eu não seja banido... rs Primeiro 👇:
Usei um squad chmado domain-decoder. Ele praticamente vira de cabeça pra baixo qualquer OpenSource e descobre como ele funciona a nivel "atômico".
Deliverables
outputs/domain-decoder/claude-code-cli/
├── phase-0/context-map.md — 25 bounded contexts
├── phase-0/rule-taxonomy.md — Taxonomia heat map
├── phase-1/seam-map.md — 43 seams 17 test candidates
├── phase-1/pattern-catalog.md — 7 patterns 7 code smells
├── phase-2/rule-catalog-bashtool.md — 106 regras (BashTool)
├── phase-2/rule-catalog-permissions.md — 106 regras (Permissions)
├── phase-3/decision-models.md — 5 Decision Models DRD
├── phase-4/rule-expressions.md — 50 regras em linguagem natural
└── phase-5/sbvr-validation.md — Validação SBVR final
Descobertas Principais
1. BashTool é o módulo mais denso em regras — 200-300 regras de segurança em 9,190 LOC, incluindo 38 validators contra exploits de parser differential (shell-quote vs Bash)
2. Permission pipeline é priority-ordered com 20 steps — deny > ask > allow, safety checks são bypass-immune
3. 6 gaps críticos identificados — compound command limit behavior, dontAsk auto coexistence, sandbox scope
4. 3 conflitos documentados — acceptEdits safety, allowlist/regex overlap, dontAsk auto
5. 74% das regras TOP 50 têm ambiguidade zero — expressas em linguagem natural controlada com vocabulário de 36 termos
4
45
3,446

On October 3, 2023, a South Branch Valley Railroad (SBVR) local freight train struck a white pickup truck hauling a trailer with a large spindle (a spool of heavy cable) at the Route 50 crossing in Vanderlip, just outside Romney, West Virginia.  The incident occurred around 11:19 a.m. while the train was heading to Petersburg.
1
4
104

3 Oct 2025
❓Heard of Will Duffy’s Final Experiment — 12 “proofs” Antarctica shows Earth is a SPINNING SPACEBALL?
Tonight we pull them apart one by one. Craig (FTFE) & McToon agreed to defend… then quit.
▶️ youtube.com/live/ECrsq8Olujw…
#SBVR #SpaceballExposed #DebateTheThirdOption

8
464

3 Oct 2025
诞生于前 LLM 时代的 Rule as Code,让我最震撼的一点在于,它对人类规则本质的解读——规则的核心并不在文字,而在共识。RaC 从来不只是“法律自动化”,而是对“规则是什么”这个根本问题的一次重新定义。
在没有大模型的年代,RaC 提出了一个激进的设想:共识可以被编译——从模糊的文字转化为精确的、可执行的逻辑。它依赖一整套确定性的标准,如 DMN、SBVR、LegalRuleML,把规则想象成一种软件构件:可测试、可审计、可部署。
然而,RaC 的假设本身——确定性、手工形式化、专家驱动的编码——也极大限制了它的扩展性。大多数项目停留在试点阶段,翻译的人工成本过高,无法真正规模化。它的悖论在于:在愿景上极具前瞻性,但在实践上并不完整。
大语言模型的出现,让边界发生了根本性的转变。机器如今能够直接从自然语言解析和生成类法律结构,为 RaC 的确定性骨架提供了一种概率性的补充。RaC 强调的是可审计性与合法性,而 LLM 带来的是可用性与规模化。 下一个范式不在于非此即彼,而是如何结合两者:RaC 作为硬脊梁,提供形式化和合法性;LLM 作为软肌肉,提供解释力与推理的灵活度。
二者结合指向的将远远超越“法律自动化”。它预示着 Consensus-as-Code(共识即代码) 的可能性:社会一旦达成共识,就能够被编译进既可验证又可适应的系统之中。这已经不再只是法律与软件的桥接问题,而是走向一条更深远的道路——为文明本身构建运行时。
open.substack.com/pub/sstem/…
1
2
14
4,707

27 Sep 2025
Congratulations to all the SBVR college students who have been appointed as Teachers in the recently declared DSC results.
I wish you all the success for future endeavours.

1
2
209

21 Aug 2025
The pressurized pizza dome is a CIA psyop to hide the truth. It is setup as a straw man argument, then they try and tie the Bible to this easily debunkable model discrediting both in the process. This credits a false dichotomy between the pressurized pizza dome and the spinning space ball. For atheism to work, people cannot believe this world is created.
We live in a Stereographic Biblical Virtual Reality #SBVR, Awake Souls on you tube has hundreds more f hours of proofs and a working model that can predict the path and location of the luminaries anywhere in the realm accurate to 100th of a degree per second.
3
245

# 要点总结
### 1. 为什么需要“符号层”
* 语义鸿沟:自然语言规则(模糊、含文化与价值判断)与代码(严格、可执行)之间存在巨大差异,直接转化会导致信息损失与理解偏差。
* 人机共读:代码只对程序员友好,而符号层能同时被业务人员理解、被机器执行。
* 范式独立:代码依赖特定执行环境,难以移植;符号层基于开放标准,可跨平台运行。
* 可追溯性:符号层能保留条款来源、版本信息,支持审计与验证。
* 演化友好:规则不断修订,硬编码难以维护;符号层能低成本迭代。
* 社会契约属性:规则首先是社会共识,其次才是可执行逻辑。符号层保障共识与执行并存。
一句话:代码层意味着“能跑”,符号层意味着“能共识且能跑”。
### 2. 符号层的核心特征
1. 双可读性:人类可验证,机器可执行。
2. 结构化与可组合:规则拆解为输入、条件、输出、例外、元数据等模块,像 API 一样复用。
3. 范式不依赖:不绑定平台或技术,依托开放标准(DMN、BPMN、LegalRuleML、SBVR 等)。
4. 溯源与可验证:符号化规则保留原始条文及版本信息,支持逻辑完整性测试。
5. 跨文化与跨领域:支持语义映射与行业逻辑模式的复用。
### 3. 为什么不直接转化为代码
* 自然语言模糊性 → 被代码强行压缩,丢失原意。
* 代码只对程序员友好 → 规则垄断,缺乏社会共识。
* 代码绑定平台 → 难以长期移植与通用。
* 代码难以溯源 → 无法满足法律、金融、医疗等高风险领域的审计需求。
* 规则需迭代 → 代码重写代价高,符号层能快速更新。
* 价值差别 → 符号化=透明契约 可执行,代码化=仅可执行。
### 4. 现有可参考范式 —— 以 DMN 为例
* 使命:统一语言,打通业务人员与开发者,规则人机共读。
* 三大组件:
* DRD(决策需求图)——展示依赖关系。
* 决策表(Decision Table)——表格化逻辑,业务直观理解。
* FEEL(表达语言)——简洁条件表达式。
* 特点:标准化、跨平台、人机共读、可执行、透明可审计。
* 应用:法律与合规(Regulation-as-Code)、金融审批、医疗决策、公共服务资格判定等。
一句话:DMN 是把规则符号化的标准工具箱。
### 5. 更宏观的视角
* 协议即权力:谁制定协议,谁掌握结构文明的主动权。
* 历史规律:每一次生产力飞跃,都伴随生产关系的巨大变革。符号层正是新一轮生产关系调整的技术基石。
👉 最简一句话总结:
符号层是连接人类社会规则与机器执行逻辑的必然桥梁,它保障规则既能透明共识,又能被机器执行,从而推动新一轮生产关系变革。
3
208
17 Aug 2025
我为什么认为在规则层与代码层之间,一定会出现一个符号层?
原因很简单,因为自然语言规则与机器代码之间存在着巨大的语义鸿沟。规则是人类制定的社会契约,以自然文字表达,承载了文化、价值和制度约束;而代码是机器运行的逻辑,必须是清晰、严格、可执行的指令。如果没有中间层,直接从规则跳到代码,势必会带来巨大的信息损耗和理解偏差。符号层正是那个必要的桥梁。它是一种位于自然语言规则与机器执行逻辑之间的结构化表示层,用统一的形式化符号体系,将法律、标准、流程、政策等转化为既能被人类直接理解,又能被机器直接执行的中间表达。
总的来说,人类社会目前制定的、用于协调生产和生产关系的所有自然语言规则,都需要先被转化为一个符号层。继我之前在“结构文明”“as code”“规则代码”等一系列讨论中铺垫的思考之后:我坚信符号层必然会出现,并且我个人愿意投入完全属于自己的一万个小时,专注于开发、学习和研究这个符号层,彻底肝这个方面的内容。这与我的理论体系高度相关——“语言即世界”。如果我要真正彻底研究并提取语言的结构,那就必须通过亲身参与和实践来搭建这个中间层,不能只停留在概念层面。
这个符号层具有几个核心特征。首先,它具备双可读性:人类可以直接阅读和验证符号层的内容,理解规则逻辑;机器也可以直接解析、调用符号层来执行规则或进行推理。其次,它是结构化且可组合的:规则被拆解为明确的输入、条件、输出、例外、元数据等结构单元(如 DMN 决策表、BPMN 流程、LegalRuleML 标注),这些单元能够像模块化 API 一样被组合、复用和迁移到不同场景和系统中。再次,它具有范式不依赖性:不绑定任何特定技术平台、厂商或 AI 范式,而是基于开放标准(DMN、BPMN、LegalRuleML、SBVR、C2PA 等)来表达,保证长期的可移植性和可用性。第四,它强调溯源与可验证:每条符号化规则都必须保留原始来源(如法规条文、政策文件)的链接与版本信息,确保随时可以追溯和审计,同时符号层本身也能被测试和验证逻辑完整性。最后,它必须具备跨文化与跨领域的适用性:能够为不同语言、不同法域建立语义映射,让同一结构逻辑在全球范围内复用,并且让行业内外通用的逻辑模式(例如“阈值触发→审批→执行”)能够在多个场景中重用。
解答几个疑问
为什么不直接把规则转化为代码?
最核心的原因是规则与代码之间存在着根本的语义鸿沟。自然语言规则往往充满模糊性、例外、歧义和价值判断,而代码必须是严格的逻辑,所有模糊都要被强行消解。结果就是,如果直接写成代码,就会把许多语义上的不确定性压缩掉,导致规则与原文之间的信息丢失,甚至扭曲原意。
此外,代码只能被程序员看懂,大多数立法者、律师、业务人员完全无法理解。而符号层通过决策表、逻辑链、协议素片等形式,成为人机共读的中间形态,让业务专家可以看懂、验证,机器也能直接执行。缺少符号层,规则就会被程序员“垄断”,无法形成社会层面的广泛共识与信任。
再者,直接写代码通常绑定在某个执行环境中,比如 Drools、OPA 或 Python 脚本,跨平台难以移植;而符号层基于 DMN、LegalRuleML、BPMN 等开放标准,可以在多个引擎运行,具备长期可用性。换句话说,符号层是范式不依赖的,而代码是范式绑定的。
代码层还有一个问题:难以溯源和审计。很难让一段代码一一对应回具体的法律条文或政策原文。而符号层天然会保留元数据,比如条款编号、来源、版本、边界条件,这样可以随时溯源和比对。在法律、金融、医疗等高风险领域,必须要有这样一条可追溯的“规则证据链”,否则无法被法院或监管机构接受。
更进一步,规则不是一次性产物,而是不断修订和演化的。如果每次修订都要重写代码,成本高而且极易出错;符号层的价值就在于可以低摩擦地迭代——修改决策表的一行即可,所有系统即刻同步,而硬编码的代码则迭代极慢。
最后,符号层和代码在价值层面也存在差别。代码化只是“能跑”,符号化却意味着“能共识”。规则首先是社会契约,其次才是机器逻辑。符号层保证了契约的透明和机器的可用,而不是让代码悄悄取代契约。
一句话总结:直接写代码意味着可执行但不可共识,而引入符号层则是可执行且可共识。符号层之所以必要,是因为规则不是纯粹的技术对象,而是社会—技术的双重产物。
目前存在哪些可以参考的范式?
以DMN举例。
DMN(Decision Model and Notation,决策模型与标注)是由 OMG(Object Management Group)制定的国际标准,用来描述、建模和执行业务决策逻辑。它的核心使命在于建立一套统一语言,使业务人员(如政策制定者、合规专家)和技术人员(开发者、系统集成商)能够用相同的方式定义规则,让规则既能被人直观理解,又能被机器直接执行。
DMN 的核心由三个部分构成。首先是 DRD(Decision Requirements Diagram,决策需求图),它以图形化方式展示决策与输入之间的依赖关系,例如“是否批准贷款”这个决策,需要依赖“申请人信用等级”和“基准利率”两个子决策。其次是 Decision Table(决策表),用表格来表示规则,即输入条件对应输出结果,形式类似 Excel 表,业务人员一眼就能理解。例如,若收入小于等于 30,000 且信用评分大于等于 700,则贷款资格为“是”,否则为“否”。最后是 FEEL(Friendly Enough Expression Language),这是 DMN 内置的表达语言,用来在表格单元格或逻辑节点中编写条件,语法简洁,类似 Excel 公式,如:
if income < 50000 and creditScore >= 700 then "eligible" else "not eligible"
DMN 的主要特点在于:它是人机共读的,业务专家可以通过图表和表格来维护规则,而开发者则能通过标准引擎直接执行;它是可执行的,模型可以在 Drools、Camunda、Trisotech 等支持 DMN 的引擎中直接运行;它是跨平台的,采用标准化 XML 格式,便于在不同厂商工具之间移植;它同时具有透明可审计的特性,比黑箱 AI 更适合法律、合规等对可追溯性要求极高的场景。
在实际应用中,DMN 已广泛用于多个领域:在法律与合规方面,它可以将法规条款转化为可执行的决策表,实现“Regulation-as-Code”;在金融领域,它常用于贷款审批、信用评分、反洗钱检查等业务;在医疗中,可支持病历分诊、临床决策以及医保报销条件判定;在公共服务中,DMN 则能为社会福利资格判定、税收计算、许可审批等提供可执行模型。
一句话总结:DMN 就是一套把规则符号化的标准工具箱,通过决策图、决策表和简洁的表达式,将自然语言规则转化为既能被人理解又能被机器执行的模型。
omg.org/dmn/#:~:text=Decisio…
又是一个“协议”。所以我说啊,你放一万个心,只要有需求的协议,都会被填补,你不填,别人就填了。千万别把协议当成什么自然规则,你就是这么想的。谁制定协议,谁就掌控了结构文明的主动权。
写在最后:
人类历史以来,哪一次生产力发生飞跃的之后,生产关系不产生巨大变革的?你说。
27
20
84
27,851
21 Jun 2025
11 వ అంతర్జాతీయ యోగా దినోత్సవం లో భాగంగా బద్వేల్ లోని SBVR కళాశాల మైదానంలో నిర్వహించిన యోగా కార్యక్రమంలో పాల్గొని యోగా చేయడం జరిగింది. మనస్సును ఆత్మను ఏకం చేసే సాధనం యోగ మనిషి మానసిక ప్రశాంతతకు ఉపకరిస్తుంది.
#YogaDay2025
#YogaDay #YogaForOneEarthOneHealth
1
2
10
141
18 Jun 2025
ఈరోజు బద్వేల్ లోని SBVR డిగ్రీ కళాశాల మైదాన ప్రాంగణంలో నిర్వహించిన యోగాంధ్ర కార్యక్రమంలో యోగాసనాలు వేయడం జరిగింది. మన నిత్య జీవన విధానంలో యోగా అంతర్భాగం కావాలి. మానసిక ప్రశాంతత, శారీరక ఆరోగ్యం యోగా ద్వారానే సాధ్యమవుతుంది. యోగాను ప్రతి ఒక్కరు తమ జీవితంలో బాగం చేయడం ద్వారా ఉత్తమ
1
2
5
188

23 May 2025
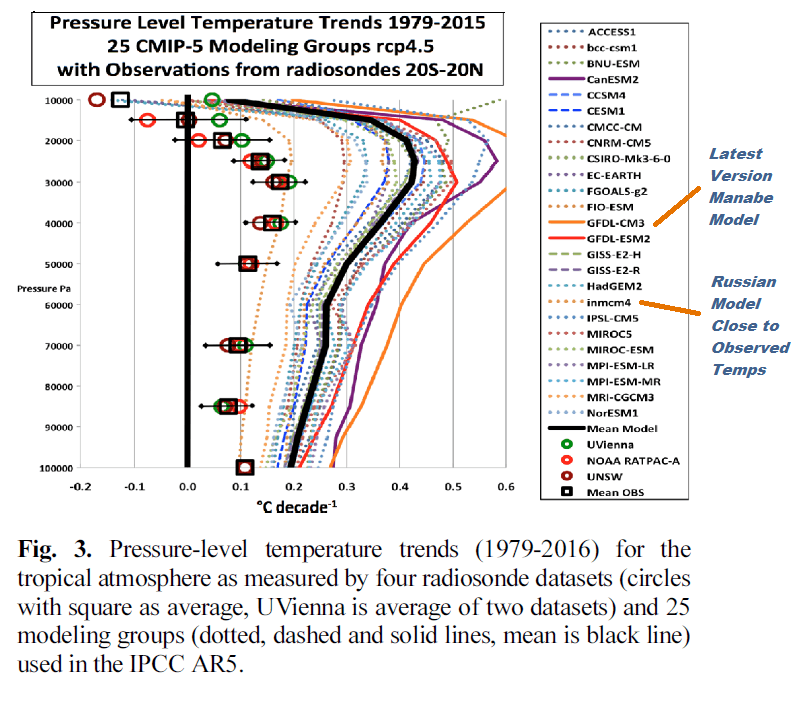
IPCC Climate Models Proven to Lack Predictive Ability | Ron Clutz, Science Matters
The recently published paper is Are Climate Model Forecasts Useful for Policy Making? by Kesten C. Green and Willie Soon.
Abstract
For a model to be useful for policy decisions, statistical fit is insufficient. Evidence that the model provides out-of-estimation-sample forecasts that are more accurate and reliable than those from plausible alternative models, including a simple benchmark, is necessary.
The UN’s IPCC advises governments with forecasts of global average temperature drawn from models based on hypotheses of causality. Specifically, manmade warming principally from carbon dioxide emissions (Anthro) tempered by the effects of volcanic eruptions (Volcanic) and by variations in the Sun’s energy (Solar). Out-of-sample forecasts from that model, with and without the IPCC’s favoured measure of Solar, were compared with forecasts from models that excluded human influence and included Volcanic and one of two independent measures of Solar. The models were used to forecast Northern Hemisphere land temperatures and—to avoid urban heat island effects—rural only temperatures. Benchmark forecasts were obtained by extrapolating estimation sample median temperatures.
The independent solar models reduced forecast errors relative to those of the benchmark model for all eight combinations of four estimation periods and the two temperature variables tested. The models that included the IPCC’s Anthro variable reduced errors for only three of the eight combinations and produced extreme forecast errors from most model estimation periods. The correlation between estimation sample statistical fit and forecast accuracy was -0.26. Further tests might identify better models: Only one extrapolation model and only two of many possible independent solar models were tested, and combinations of forecasts from different methods were not examined.
The anthropogenic models’ unreliability would appear to void policy relevance. In practice, even
the models validated in this study may fail to improve accuracy relative to naïve forecasts due to
uncertainty over the future causal variable values. Our findings emphasize that out-of-sample
forecast errors, not statistical fit, should be used to choose between models (hypotheses).
Background
In their attempts to achieve the IPCC objective of identifying a human cause for temperature changes—specifically “global warming”—the IPCC researchers have framed the problem as one of “attributing” changes in the Earth’s temperature to the respective contributions of putative anthropogenic (“Anthro”) principally carbon dioxide emissions altering the composition of the atmosphere—and natural influences—principally aerosols from volcanic eruptions altering the composition of the atmosphere (“Volcanic”), and total solar irradiance, or TSI, variations (“Solar”).
Given the task they were set, the IPCC researchers have devoted much of their efforts into developing estimates of the Anthro variable.
The IPCC’s most recent, AR6, report (IPCC, 2021) only considered one estimate of Solar for the purpose of attribution (Matthes et al., 2017) and made no allowance for the effect of urban heat islands on the temperature measures they used (Connolly et al., 2021, 2023; Soon et al., 2023). Moreover, a study of the statistical attribution or “fingerprinting” approach used by IPCC researchers (e.g., Allen and Tett, 1999; Hasselmann, et al., 1995; Hegerl et al., 1997; Santer et al.,1995) concluded that the approach was invalid (McKitrick, 2022). The IPCC authors’ analyses failed to meet the assumptions of the method they used, and they failed to correctly implement the method.
In sum, the objective given to the IPCC researchers and the approach that they have taken suggests that plausible alternative hypotheses on the causes of terrestrial temperature changes may not have been adequately tested, as is required by the scientific method (Armstrong and Green, 2022). That concern is consistent with Armstrong and Green’s (2022) observation that government sponsorship of research can create incentives that may influence researchers’ choices of hypotheses to test and how they test them.
1.1 Alternative hypotheses on Solar
To address the first of the foregoing limitations in the IPCC attribution studies—failure to fairly test alternative TSI estimates—Connolly et al. (2021, 2023) comprehensively reviewed alternative estimates of TSI covering the 169 years from 1850 to 2018. In addition to the Matthes, et al. (2017) TSI estimates series used by the IPCC (2021)—henceforth “IPCC Solar”—Connolly et al. (2023) identified 27 alternative Solar time series.
The alternative estimates of Solar correlate quite well with the TSI used in the AR6 report—Pearson’s r values range between 0.39 and 0.97 with a median of 0.82—but the degree of TSI variation in Watts per square metre (Wm-2) differs considerably between the estimates. The ranges of the individual alternative TSI estimate series vary between 0.49 and 4.64 Wm-2, with a median range of 1.77 Wm-2, while IPCC Solar has a range of only 0.19 Wm-2.
In this study, we consider two plausible TSI reconstructions from Connolly et al. (2023). Those from Hoyt and Schatten (1993) and from Bard et al. (2000), which Connolly et al. (2023) updated to the year 20182. The former TSI record (“H1993 Solar”) was based on the so-called multiproxy—i.e., equatorial solar rotation rate, sunspot structure, the decay rate of individual sunspots, the number of sunspots without umbrae, and the length and decay rate of the 11-yr sunspot activity cycle—reconstruction of the solar irradiance history.
1.2 Alternative hypotheses on temperature estimation
The IPCC’s attribution studies do not account for the direct effects of human activities on local temperatures (heat islands)—the second weakness addressed in this study. For example, heating and cooling of building interiors, electricity generation, manufacturing, freight and transport, asphalt and concrete, and where vegetation and open water have been removed or added. Where temperature readings are taken close to such human sources of heat or absence of natural cooling, they cannot properly reflect the individual effects of human emissions of carbon dioxide, etc., that the IPCC are concerned about (their Anthro variable), the Volcanic variable, and TSI.
To address this second limitation in the IPCC attribution studies, Connolly et al. (2021, 2023) developed four alternative estimates of surface temperatures that were intended to avoid heat island effects. They were based on rural only weather station readings, sea surface temperature readings, tree-ring width measurements, and glacier length measurements. For comparison with the approach used by the IPCC, they also developed an all-land temperature estimates series for the Northern Hemisphere.
1.5 Hypotheses tested
The foregoing discussion suggests the following hypotheses, which are tested in this study.
- H1. Forecasts from causal models will [will not] be usefully more accurate than forecasts from a naïve no-change model.
- H2. Models using variable measures developed independently of the IPCC dangerous manmade global warming hypothesis will [will not] have greater predictive validity.
- H3. The statistical fit of the models (adjusted-R2) will not [will] be substantively positively related to their predictive validity.
- H4. Models using variable measures developed independently of the IPCC dangerous manmade global warming hypothesis will [will not] be more reliable.
Findings
3.1 Predictive validity of causal models versus naïve model [H1]
Forecast errors were larger than the benchmark errors (UMBRAE) for the IPCC Anthro models AVL and AVSL estimated with data from 1850 to 1949 and from 1850 to 1969, and for the AVR and AVSR models estimated with data from 1850 to 1899, 1850 to 1949, and 1850 to 1969. The anthropogenic warming models showed predictive validity relative the naïve model (UMBRAE less than 1.0) for only three of the eight combinations of forecast variable and estimation sample period.
3.2 Predictive validity of independent versus IPCC models [H2]
The MdAEs (median absolute error) of the forecasts from the models with IPCC’s anthropogenic and volcanic series as causal variables (AVL and AVR) and from the models that also included IPCC’s solar series (AVSL and AVSR) were greater than 1°C (roughly 2°F) for five of the eight combinations tested. The MdAEs of the forecasts from the models with B2000 solar and the volcanic series as causal variables (SBVL and SBVR) were less than 0.55°C (1°F) for all eight of the estimation periods used and temperature series being forecast combinations and for seven of the eight in the case of the models with H1993 as the solar variable (SHVL and SHVR).
3.3 Relationship between predictive validity and statistical fit of models [H3]
The correlations (sign-reversed Pearson’s r) between the accuracy of out-of-sample forecasts, as measured by UMBRAE (an error measure, hence the sign reversal), and the statistical fit of the models to the estimation data (adjusted-R2) for the causal models tested were large and negative for six (6) of the eight (8) combinations of estimation period (1850 to 1899, 1949, 1969, and 1999) used—and hence maximum forecast horizon of 119, 69, 49, and 19 years, respectively—and temperature series (NH Land and NH Rural) forecast.
3.4 Reliability of independent versus IPCC models [H4]
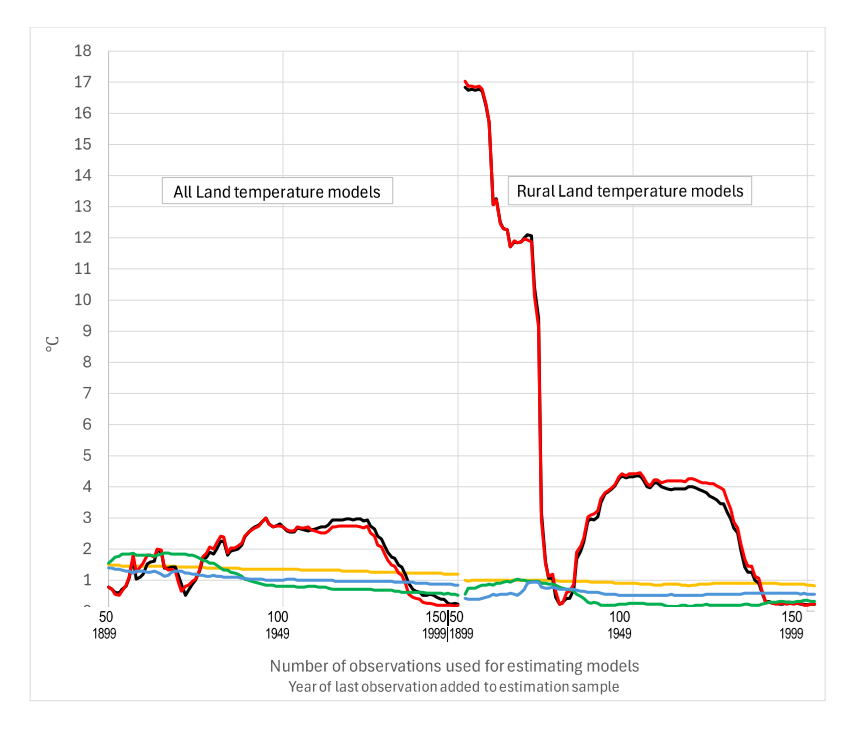
Charts of the results of Test 2 are presented in Figure 2 and are discussed below.
The independent solar models—SBVL and SHVL, and SBVR and SHVR—perform largely as one
would expect of causal models when forecasting using known values of the causal variables.
In the case of the AVR and AVSR models—forecasting the rural land temperatures, on the right of Figure 2—the MdAEs decreased rapidly from roughly 17 times the corresponding naïve forecast errors to beat the naïve MdAE when the 76th observation (1925) was added to the estimation samples. After that observation was added, the MdAEs for the AVR and AVSR model forecasts increased rapidly with each extra observation then stayed high before rapidly declining again after the 116th observation (1965) was added to the estimation samples.
When a model of causal relationships is estimated from empirical data on valid causal variables reliably measured, one would expect forecast errors to get smaller as more observations are used in the estimation of the model’s parameters. That is what the charts in Figure 2 show in the case of the naïve benchmark model forecasts and, broadly, what can be seen in the case of the independent models SBVL, SHVL, SBVR, and SHVR, but is not seen in the case of the models using the IPCC variables: AVL, AVSL, AVR, and AVSR.
The errors of the Anthro models’ forecast errors explode well beyond 1 °C and the benchmark model errors for forecast years beyond the mid-1970s, with puzzling exceptions. Namely, forecasts from Anthro models estimated from the largest sample size in the chart—1850 to 1999—and from models estimated from the smallest sample—1850 to 1899—forecasting All Land temperatures. In those cases, involving three of the eight charts, the Anthro model errors are less than the median historical temperature benchmark model errors, and mostly less than the errors of the independent models in later years.
The explosion in Anthro model errors from the 1970s is more extreme for models estimated to forecast Rural Land temperatures. Moreover, for the models estimated using only 1850 to 1899 data, errors are larger than those of the benchmark and independent models from 1920 and, prior to 1970, without any obvious pattern.
5. Conclusions
The IPCC’s models of anthropogenic climate change lack predictive validity. The IPCC models’ forecast errors were greater for most estimation samples —often many times greater—than those from a benchmark model that simply predicts that future years’ temperatures will be the same as the historical median. The size of the forecast errors and unreliability of the models’ forecasts in response to additional observations in the estimation sample implies that the anthropogenic models fail to realistically capture and represent the causes of Earth’s surface temperature changes. In practice, the IPCC models’ relative forecast errors would be still greater due to the uncertainty in forecasting the models’ causal variables, particularly Volcanic and IPCC Solar.
The independent solar models of climate change—which did not include a variable representing the IPCC postulated anthropogenic influence—do have predictive validity. The models reduced errors of forecasts for the years 2000 to 2018 relative to the benchmark errors for all, and all but one of 101 estimation samples tested for each of the two models. One of the models (B2000 Solar) reduced errors by more than 75 percent for forecasts from models estimated from 35 of the samples—a particularly impressive improvement given that the benchmark errors were no greater than 1 °C for all but one of the estimation samples.
The independent solar models provide realistic representations of the causal relationships with surface temperatures. The question of whether the independent solar variables can be forecast with sufficient accuracy to improve on the benchmark model forecasts in practice, however, remains relevant. All in all, and contra to the IPCC reports, there is insufficient evidential basis for the use of carbon dioxide, et cetera, emissions—taken together, the IPCC’s Anthro—as climate policy variables.
Read more:
rclutz.com/2025/05/22/ipcc-c…
57
105
346
244,723
14 Apr 2025
మహిళలు ఆర్థికంగా ఏదగడానికి తోడ్పాటు అందివ్వాలని సంకల్పించింది మన కూటమి ప్రభుత్వం. ఉచితంగా కుట్టు శిక్షణతో పాటు మిషన్ కూడా ఇచ్చేందుకు నిర్ణయించింది, అందులో భాగంగానే ఈ రోజు SBVR కళాశాల నందు ఉచిత కుట్టు శిక్షణ తరగతులను ప్రారంభించడం జరిగింది.
#IdhiManchiPrabhutvam
#AndhraPradesh




1
5
100

19 Mar 2025
It’s even better with the sbvr mod so it feels like I’m actually hanging out there
1
57
3,010

13 Mar 2025
APPEAL to @naralokesh garu & @PawanKalyan garu! As 2023 passouts of SBVR Agricultural College, Badvel(@ANGRAU), we're still awaiting our caution deposit (₹10,000) & RAWEP stipend (₹9,000) Despite repeated requests to college management for 2 YEARS, we've got NO PROPER RESPONSE!
1
3
740


