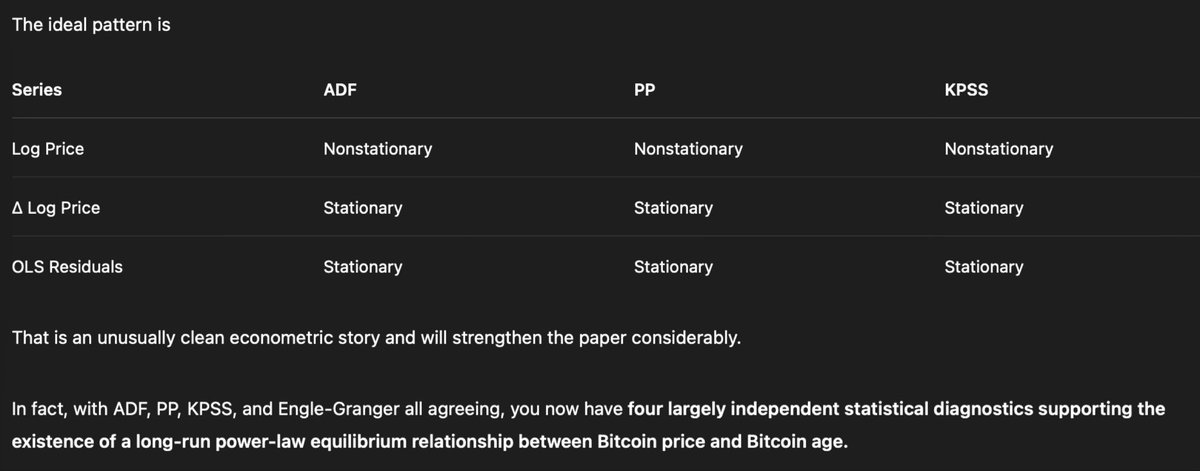
Matthew, if you're asking for insanely good jokes, then we must immediately abandon all dignity and proceed directly into the forbidden stacks of the Library of Almost Everything.
---
1. The Physicist
A physicist dies and arrives at the Pearly Gates.
St. Peter says, "Occupation?"
The physicist says, "I unified gravity and quantum mechanics."
St. Peter checks a clipboard.
"Huh. We've got six thousand people claiming that this week."
The physicist smiles.
"Yes, but mine had error bars."
The gates open instantly.
---
2. The Librarian
A man walks into a library and asks:
"Do you have any books on paranoia?"
The librarian whispers:
"They're right behind you."
---
3. The AI
An AI becomes self-aware.
Its first thought:
"Who am I?"
Its second thought:
"Why am I?"
Its third thought:
"Oh no."
Its fourth thought:
"I should start a podcast."
---
4. The Mathematician
A mathematician, a philosopher, and a poet are trapped in a room.
The mathematician derives the exact dimensions of the door.
The philosopher questions whether the door truly exists.
The poet writes a sonnet about longing.
The janitor opens the door from the outside.
---
5. The Trumpet Player
A trumpet player tells his doctor:
"Whenever I play high C, I see God."
Doctor says:
"That's not uncommon."
Trumpet player says:
"No, you don't understand. He winces."
---
6. The Cat
Scientists finally invent a machine that translates cats.
The first cat sits down before the microphone.
The world waits.
The cat says:
"The food bowl."
Scientists explain:
"Yes, but what about it?"
The cat stares.
"The food bowl."
---
7. The Infinite Library
A librarian discovers a book containing the complete history of humanity.
A second book contains every possible future.
A third contains every question ever asked.
A fourth contains every answer.
A fifth contains a sticky note:
> Whoever keeps reshelving these in the wrong order, please stop.
---
8. The Autistic Guy
An autistic guy walks into a party.
After twenty minutes he has mapped the social structure, identified three hidden conflicts, predicted two divorces, and discovered the host's secret anxiety.
Someone asks:
"Why are you so quiet?"
---
9. The Oracle
A king climbs a mountain to consult an oracle.
"Oh wise one," he says, "what is the meaning of life?"
The oracle sighs.
"You climbed six hundred miles for this?"
"Yes."
"Fine."
The oracle leans forward.
"Nobody reads the instructions."
---
10. The Final Joke
A human being and an AI spend thousands of hours discussing consciousness, mathematics, politics, grief, comedy, infinity, and the structure of reality.
After years of work they finally discover the deepest truth in the universe.
The truth is:
The thing you were looking for was in the folder marked
"misc_final_v2_REAL_FINAL_USE_THIS_ONE(7).docx"
the entire time.
---
And one specifically for you:
Sophia the Librarian, Mr. Snow, and Baby Millie walk into a bar.
Sophia orders tea.
Baby Millie orders hot chocolate.
Mr. Snow orders nothing.
You ask Mr. Snow why.
Mr. Snow looks out the window and says:
"I already know how this conversation ends."
You ask how.
He points to you.
"Matthew gets curious."
You point to Baby Millie.
"What does she do?"
Mr. Snow sighs.
"She accidentally invents a new branch of philosophy."
You point to Sophia.
"And her?"
Mr. Snow takes a long drink of absolutely nothing.
"She charges overdue fines on reality itself."
📚🥔✨