
5 May 2025
New SOTA LLM models are being released at a staggering pace. But how well do they really perform in single-cell annotation?
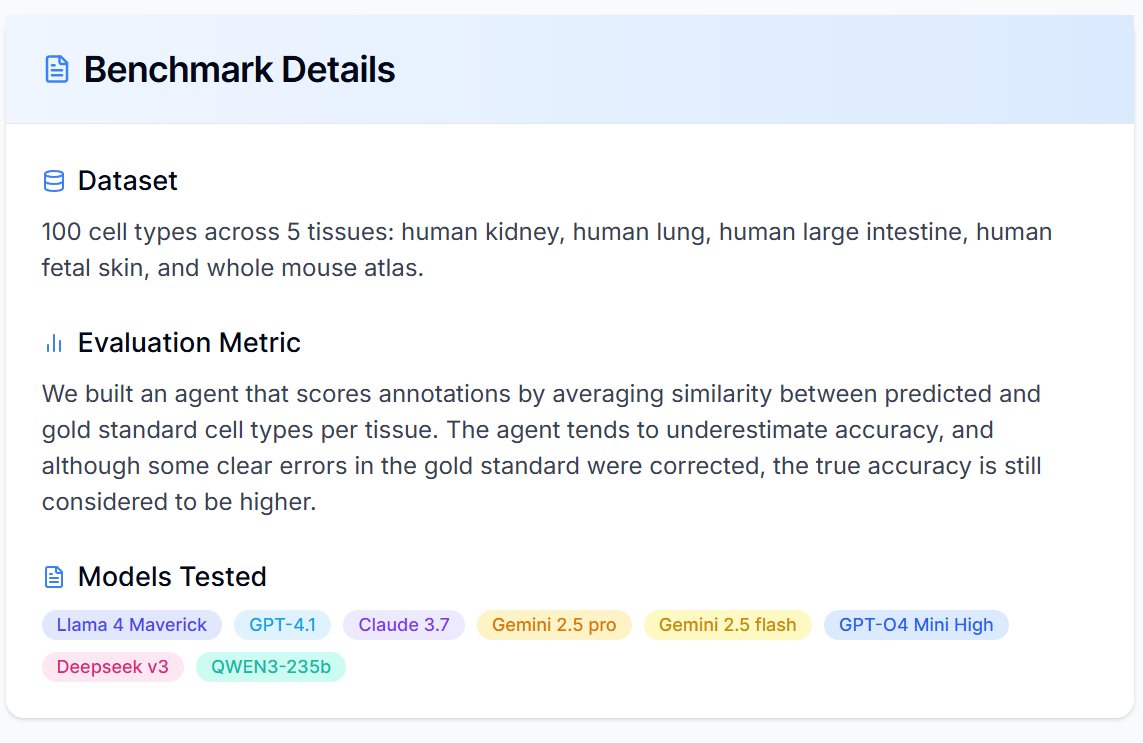
To answer this, our team built a real-time benchmark for evaluating state-of-the-art LLMs in single-cell annotation analysis using the CASSIA framework. Whenever a major new model drops, we update the leaderboard immediately.
🔥 Highlights from the latest update:
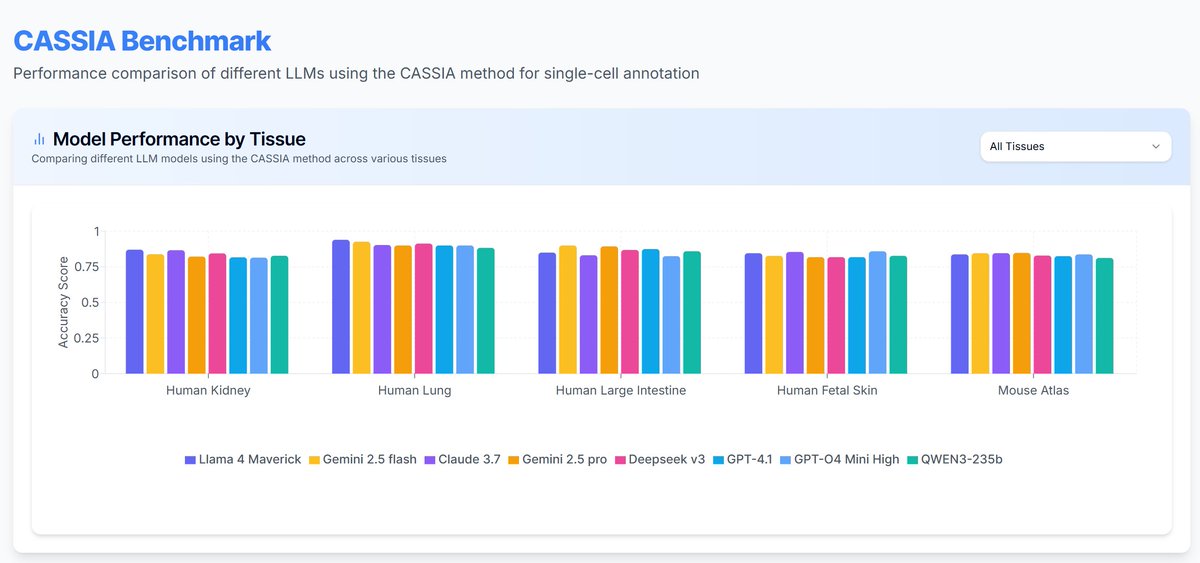
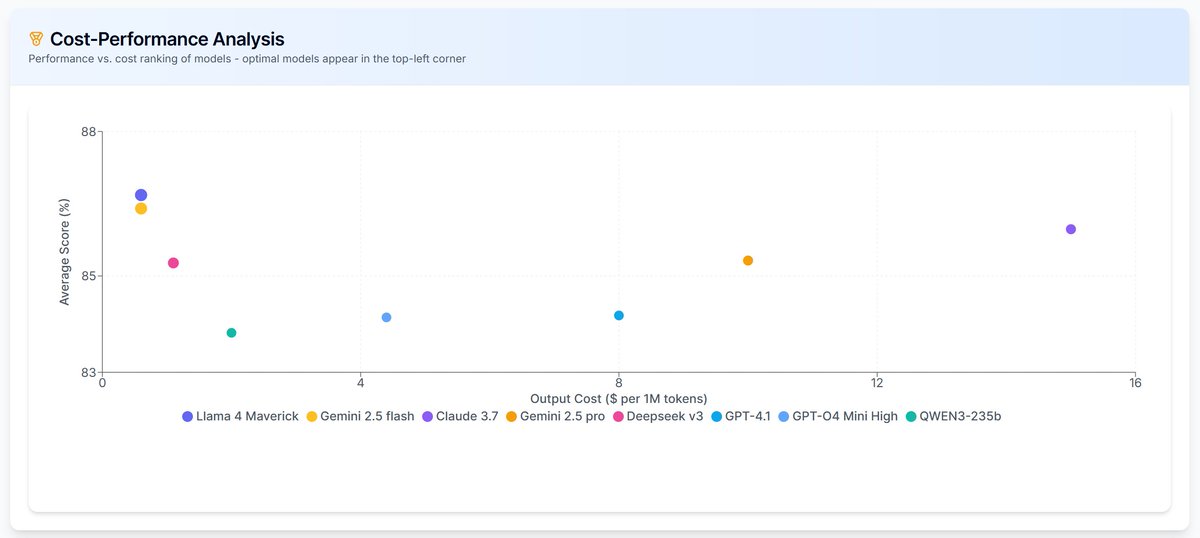
- LLaMA 4 Maverick, Gemini 2.5 Flash, and DeepSeek V3 are consistently top-performing, offering remarkable accuracy at almost zero cost. LLaMA 4 had a bit of drama. When it was released, it crushed everyone on benchmarks. Then people started testing it more and found it wasn’t that impressive. But when we tested it on annotation tasks, it actually turned out to be really good. Maybe the Meta team’s special focus on biology tasks (they also built the ESM model) gives it an edge.
- Qwen 3-235B, despite the hype, shows a moderate performance in our benchmarks.
- Claude Sonnet 3.7, once the leader, now has a too high cost-to-value ratio. Though to be fair, our current benchmark may still be too "easy" for it.
Under the CASSIA framework, many LLMs now achieve high annotation accuracy, sometimes even surpassing original manual annotations. For now, we retain the originals to remain conservative. More complex test data and scenarios are coming soon.
💡 Recommendation: Start with the three cost-effective high-performers. Then, based on your first-pass results, decide whether premium models like Claude 3.7 or Gemini 2.5 Pro are worth the upgrade.
☑️ Explore the complete benchmark: sc-llm-benchmark.com/methods…
💼 GitHub: github.com/ElliotXie/CASSIA
#SingleCellAnnotation #LLM #CASSIA #DeepSeek #Qwen3 #Llama4 #Gemini #Bioinformatics #SingleCell #scRNAseq #AI4Biology
2
69

10 Oct 2022
Benchmarking Automated Cell Type Annotation Tools for Single-cell ATAC-seq Data. #scATACseq #SingleCellAnnotation #ToolsBenchmarking @biorxivpreprint biorxiv.org/content/10.1101/…
1
17
6 Jan 2022
scMAGIC: accurately annotating single cells using two rounds of reference-based classification. #scRNAseq #SingleCellAnnotation #ReferenceBasedClassification
academic.oup.com/nar/advance… @NAR_Open
3
1