
Jun 3
⚡️ ZAYA1-8B proves small can dominate—8B total, <1B active, outperforms larger models in math, coding & reasoning. 🚀 Like, comment, and join Newline AI Accelerator today!
#ai #efficientAI #smallLLM #reasoningAI #MoE
3
75

Ok enough of this qwen27b 3090 posts
Youll have that 3090 and then what?
Build, not focus on inference,
Cause otherwise youll become a product, same as openai user but without goofy ahh subscription sticker.
This narrative that youll have to get own gpu rigs to infer locally is not optimal for most of us. Most of us cannot afford it and we shoild focus on search in smallllm area distill and speedup on train site
1
4
143

15 Sep 2025
I’ve said it in 2024, I repeat it in 2025, and I’ll say it again in 2026: the future of AI is Tiny 🤏, Nano ⚡ & Pico 🔬 LLMs.
⚡ Fast inference
✅ Accurate enough
💾 Low memory
🔋 Minimal energy
@Microsoft #BitNet is proving it.
@Future_Frontend #AI #SmallLLM #TinyLLM #LLM
1
1
3
103

12 Jul 2025
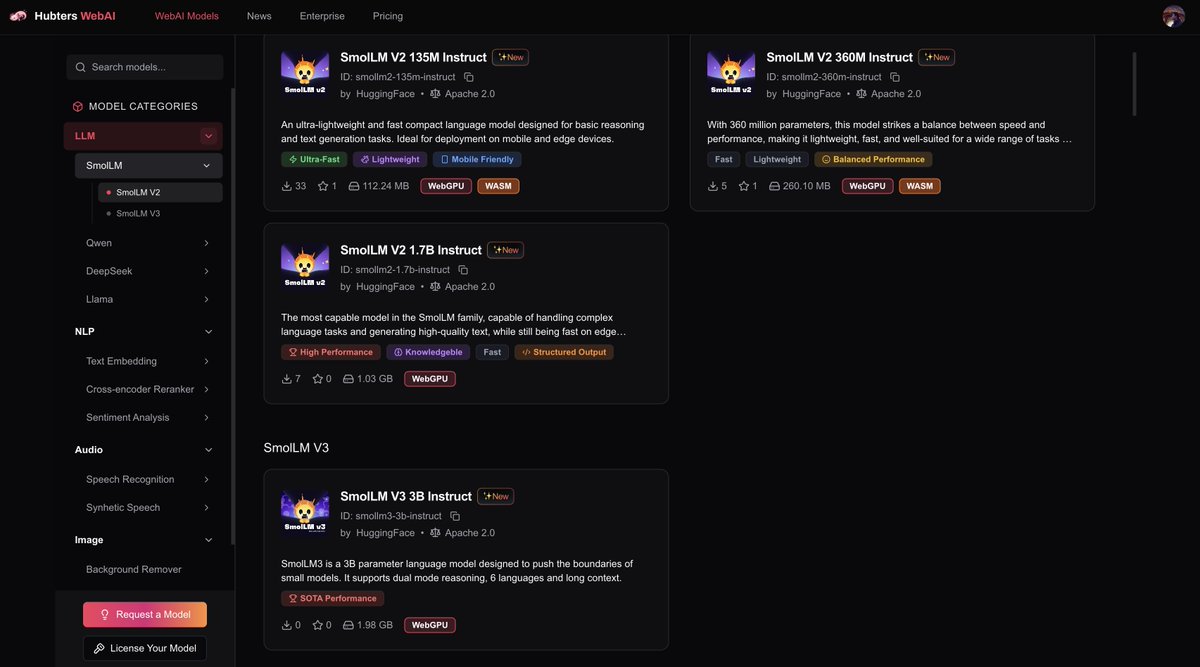
Hugging Face newest SmoLlm3 3B is now live on our WebAI platform, now locally runnable inside your user's browser. #SmallLLM
1
4
185

23 Jan 2025
I am not a big fan of Large Language Models.
In fact, India should not adopt the approach of developing a LARGE language model. Instead, we should focus on SMALL language models—very specific and designed for special purposes, capable of answering complex queries and solving critical problems within a particular industry.
For example, we could create a law-specific language model or, even more precisely, a science language model, or perhaps a physics language model. If we cluster all these small language models together and, instead of building a massive knowledge graph, create a simple directory or index for these models, users could select the respective language model to get specific answers.
There will be some limitations, though.
Such models may not answer questions that are very broad or cut across multiple language models. However, if we use RAG to frame user queries in a way that breaks the query into smaller components, these components can retrieve answers from the relevant small language models. This approach provides a strategic advantage for India.
First of all, it doesn’t require very high computational bandwidth, so we can rely on indigenously built, low-cost memory and computing infrastructure. Second, there is less dependency on external data.
These models will be built using data generated in India, making them more capable of providing better answers in the Indian context. We should adopt a Digital Public Goods (DPG) approach to LLMs as well, focusing on solving real problems with resources developed indigenously.
We should work with a minimalistic approach and adhere to the principle of single responsibility. The goal should not be to create a tech monopoly but to solve specific problems in specific industries.
I believe we should avoid the trap of large language models. Even if we solve business problems using large language models, we would end up giving away more than 50% of the revenue to tech monopolies, whether they are LLM companies or hardware providers. India should carve its own path instead of falling into the trap of digital monopolies again.
@simpler_today
@aravindsrinivas @RajeevRC_X @GramPanchayatHQ @EasyGov @reliancejio @perplexity_ai @deepseek_ai
#SmallLLM #SimplerToday #AI4People
21 Jan 2025

Re India training its foundation models debate: I feel like India fell into the same trap I did while running Perplexity. Thinking models are going to cost a shit ton of money to train. But India must show the world that it's capable of ISRO-like feet for AI. Elon Musk appreciated ISRO (not even Blue Origin) because he respects when people can get stuff done by not spending a lot. That's how he operates. I think that's possible for AI, given the recent achievements of DeepSeek. So, I hope India changes its stance from wanting to reuse models from open-source and instead trying to build muscle to train their models that are not just good for Indic languages but are globally competitive on all benchmarks. I'm not in a position to run a DeepSeek-like company for India, but I'm happy to help anyone obsessed enough to do it and open-source the models.
2
4
390

25 Nov 2024
NVIDIA Launches Hymba, its New Hybrid Architecture for Small LLMs
analyticsindiamag.com/ai-new…
#Nvidia #AI #ArtificialIntelligence #LLMs #LLM #GenAI #GenerativeAI #smallllm #rt #technology #TechRevolution #tech #Engineering
1
1
2
140

🚀 Excited to release pip-code-bandit! A 1.3b param AI model, Apache 2.0 licensed, for complex planning, code generation, and function calling. RL-tuned for agentic workflows.
Huggingface - huggingface.co/PipableAI/pip…
#OpenSource #AI #LLM #AI #OpenSource #SmallLLM #LLama
2
3
222




