

We should preserve really special voice notes or voice recordings in audio spectrogram papers ❤️
1
2
50
We probably need to start preserving them in audio spectrogram papers
1
98
BURAKKLNC retweeted

12h
Sigma-MT User Guide, Part 1: Reading the Spectrogram and the Time Frequency Engine
sigma-l.net/p/sigma-mt-user-…

1
1
15
749

11h
language models without multimodal support & audio, without slop about Gravitational Waves:
think of it this way. you have someone sitting in the Producer/Engineer chair with a comprehensive body of knowledge of everything that has been written about music theory, production, songwriting, etc -- but the speakers are off, and they can only make changes based on what they see on metering. up until the new dense Gemma models, and earlier Gemini models, audio encoding/decoding as input has largely been experimental. so when talking about models without audio byte-pair encoding training like Gemma's new dense model, we are left with vision and language tokenization, so if it can be conveyed in an image (like a mel spectrogram of a short sample, since images are rescaled down to 1500px-ish for bandwidth on most production APIs, and you will lose spectral information that could be displayed in a TIFF), that's the best the model will get
the models don't have a vague, thunderous understanding of music like detecting gravitational waves. they have the understanding a world-class engineer would have of a song with the metering on and the speakers off. "it looks like there's vocals here which are smooth" because it can see lines in the 2k-5kHz range. if it were post-trained on audio itself it would cut the gap, i.e. models that you can pass audio into natively have no problem understanding music. it's a tokenization issue with the older non-audio models but describing it the way the OP did is ridiculous dilettante wordslop
11h

so thy kind of have synesthesia from our POV
2
1
11
2,240
11h
try feeding an image of a short sample as mel spectrogram into any model with a vision circuit, it even works back to the first Llama 3 models. this will cut the gap between 'models not specifically trained for music' and 'generalized audio engineering space in manifold'
1
24
Chidambara .ML. retweeted

📢 #highlycited paper
📚 Domain Adaptation of ECG Signals Using a Fuzzy Energy–Frequency Spectrogram Network
🔗 mdpi.com/2076-3417/15/24/129…
👨🔬 by Tae-Wan Kim et al.
🏫 Chosun University
#explainableAI #fuzzylogic #machinelearning
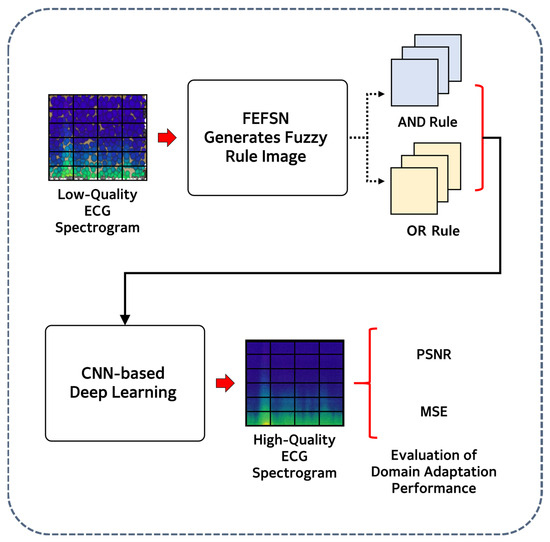
2
2
39

nah fuck it i have free will i can say that 35 is the noelle net hp loss in ch2 (90->166->55), it's hidden in d.ogg spectrogram, it's the square root of 1225, 3 rotated is M and 5 flipped is e, Dess is the voice in HLDITHTS (non glowy gaster w/ normal case) and is behind weird rt
1
18

It reminded me that a friend uploaded CD archive in a video in spanish, he even translated the secret codes and the spectrogram of act 1 lmao
6
522

The "warm" LED lighting is still blue light. Just look up the power distribution of warm LED lightning on a spectrogram. It's still unnatural and super unhealthy. Your "better alternative" is as misguided as the belief that using less energy will save the planet.
1
3
57

Jun 14
so i was informed theres morse code right before the blue trim fight in the flame ep and so i clip the audio, get the spectrogram from audacity, find a morse code decoder, only to find out it says "abcdefghijklmnopqrstuvw" and its just part of the music
2
8
217
2,992

Yes — Shazam relies on FFT (via Short-Time Fourier Transform) to turn audio into a spectrogram. It then extracts the strongest spectral peaks, which frequently align with harmonic series and dominant tones in music. These peaks form a sparse “constellation” that gets combinatorially hashed into a compact, noise-resistant fingerprint for lightning-fast database matching.
The original Avery Wang paper details exactly this peak-based approach.
1
1
38

Jun 14
There are no stupid questions.
“• Converts it into a spectrogram (visual map of frequencies over time).
• Extracts “landmarks” or peaks (the strongest frequency points that stand out even in noise).
• Creates a compact acoustic fingerprint (a constellation of these peaks, turned into hashes) — tiny and efficient, not the full audio.
• Matches it against a massive database of pre-fingerprinted songs in seconds, even in noisy environments like bars or cars.”
Jun 13

What’s the science behind Shazam. Who can explain it. How is it able to differentiate sounds.
2
166

👻 Something’s in the room. Can you hear it?
EVP Ghost Signal — real-time paranormal audio investigation with spectrogram analysis, EMF monitoring & anomaly detection. 100% on-device. Free to start 👇
apps.apple.com/us/app/evp-gh…
#ghosthunting #paranormal #EVP #iOS
1
4

Jun 14
It is a spectrogram comparing two audio clips. Codex was able to rewrite everything for Core AI, then was optimizing it for speed
The top is before optimization, the bottom is after. It shows that it made the model much smaller (591 MB to 222 MB) while preserving the voice
1
1
70