Jun 12
Believe it or not, “He’s actually so smart, and you wouldn’t believe what he reads!” has been said, mutatis mutandis, about every Boomer president, with the possible exception of W (for whom it was patently implausible).
Clinton was supposedly a speedreader; Obama was a clever intellectual; Trump is a stable genius; Biden totally wasn’t senile because he could play “Stump The Chump” (never mind that that itself is a sign of senility).
It’s never enough to just get something done - whoever it is has to also be brilliant.
Tbf, it probably started with Kennedy, who was cast as an intellectual who wrote serious books and liked to sit alone reading the paper on Sundays - no matter how much evidence of ghostwriting emerged and how otherwise implausible the characterization was. But it then skipped quite a few.

‘Obama kept up w the latest literary fiction.’
Lol.
It’s impossible to overstate how recessionary our intellectual standards became starting around 2010.
Obama was callow and performatively intellectual and libs, whose intellectual and cognitive capacity has declined precipitously in the past 25 years, loved having their vanity reflected off him and didn’t care how obviously shallow he was.
Obama was an extraordinary talent in flattering people and making them feel a certain way about themselves. The guy came out of nowhere to become president of the Harvard Law Review (although of course he never published anything of note there) and he had a true genius for understanding the psychological needs of the public as a political performer.
Libs get very touchy when you bring up Obama’s superficiality and shallowness because it implicates their own shallowness and lack of discernment and how they’ve also been coasting on the social performance of ‘intelligence’ rather than anything approaching intellectual rigor for quite a long time.
4
18
2,180




Jun 12
Copy url >paste I to brave>enable speedreader> read, learn from a good content creator who probably just wants to self - publish without a bunch of costs > get on with my day.
13


You can anyway read it for free, using Brave Browser Speedreader.
But good, they are atleast making it accessible for once.
Jun 11

NYT-owned The Athletic, normally paywalled, says it is making its World Cup coverage free to read in its app until the day of the final on 19 July.
1
216

แต่ฝั่งที่ไม่เห็นด้วยก็เยอะไม่แพ้กัน ประเด็นหลักคือ Brave ปกติก็เข้าไปปิดฟีเจอร์พวกนี้ได้ฟรีอยู่แล้ว PCMag ถึงกับพาดหัวว่า "Why I'm Not Buying It" บอกว่าจ่ายเงินเพื่อแทน process ปิดฟีเจอร์ที่ทำได้ฟรีด้วย process จ่ายเงิน activation ซะงั้น แถมบางคนมองว่าตัดของมีประโยชน์ไปด้วย เช่น Speedreader, Tor, Wayback Machine แล้วบน Reddit ก็มีถกกันเรื่อง activation ว่าถ้าใช้ครบโควต้าแล้วต้องจ่ายใหม่อีก 60 ไหม
1
144
ฟีเจอร์ที่ตัด/ปิดได้มีตั้งแต่ Leo (AI assistant), Rewards กับ Brave Ads, Wallet (crypto), VPN, News, Playlist, Talk, Speedreader, Tor, Wayback Machine, Web Discovery Project ไปจนถึง Email aliases แถมปิด telemetry อย่าง daily ping, crash logs, product analytics ให้ด้วย ส่วนเรื่องการจ่ายเงิน Brave ใช้ blind token protocol อิงจาก Privacy Pass เพื่อแยก payment identity ออกจาก service usage ไม่ให้โยงกันได้
1
45

Jun 8
Speedreader TTS on desktop is impressive and easy to use. Would love it on Android.
1
41

I played the whole damn game and missed that he had a crush on a girl. The way he acted around Sunny led me to believe they had something. Rip speedreader me.
2
3
321

A picture ofSeyed Ali Khamenei's personal library.
Many don't know this but he was a SpeedReader and was fluent in 3 languages (Persian Arabic and English) so he could read books in their original author's language.

Jun 7

When Ayatollah Ali Khamenei met with the Lebanese leader Saad Hariri in 2010 in Tehran, Hariri wanted to talk about the disarmament of Hezbollah.
Khamenei asked Hariri if he had read Victor Hugo's 1831 novel, The Hunchback of Notre Dame. Hariri had not.
Khamenei told him that the character Esmeralda always carried a knife or a dagger to protect herself. Esmeralda is wanted, just as Lebanon is, by everyone, including Israel.
Hezbollah, Khamenei said, is Esmeralda's dagger. Why would you want to remove it from her?

1
32
1,255

Jun 7
Local OS solutions on Mac are definitely better than their Windows counterparts too. Brave uses local TTS services in the Speedreader view. Have you tried it?



2
3
72
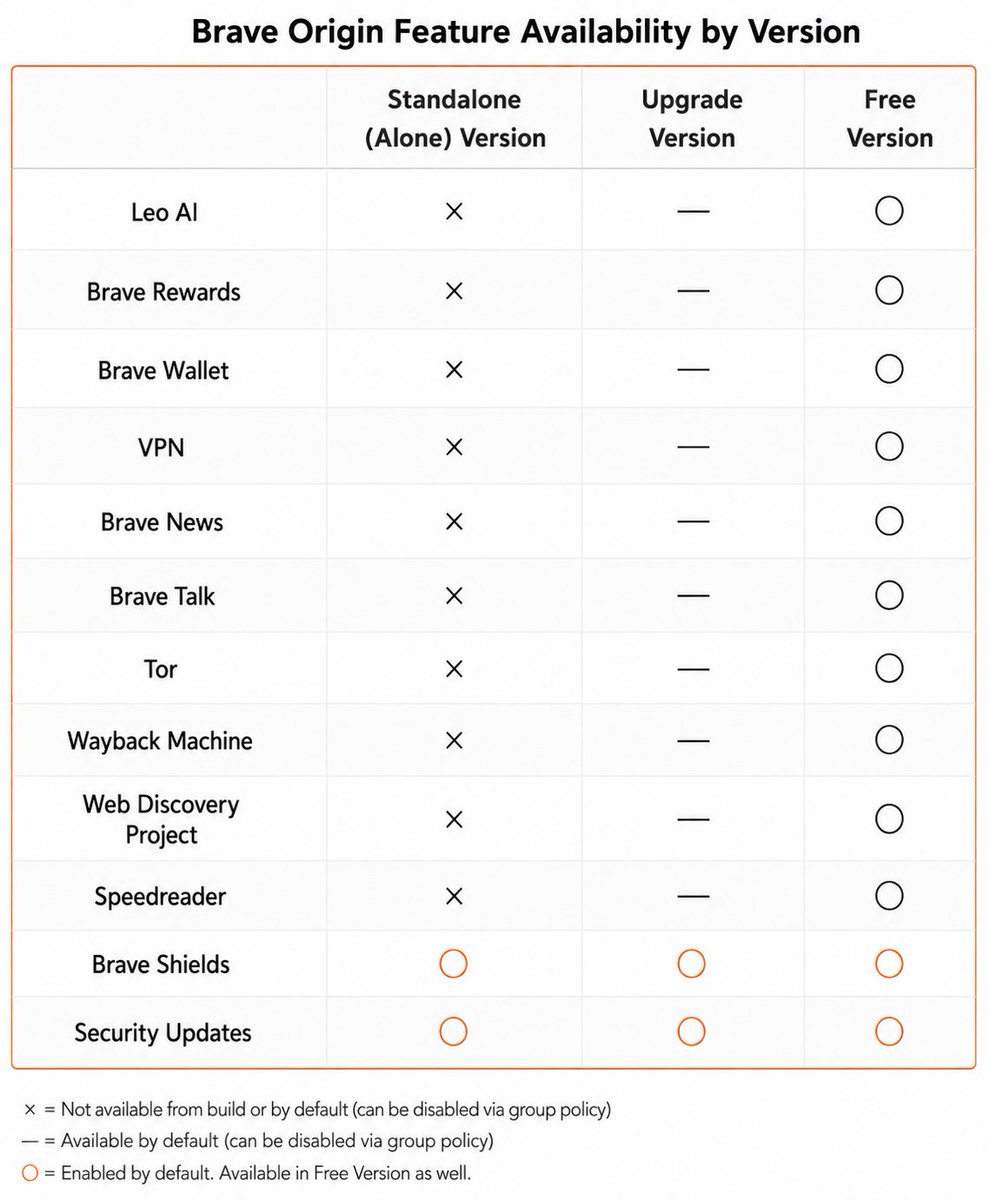
Brave just did something most software companies would never do.
They launched a paid browser that removes features.
Brave Origin strips out:
• Leo AI
• Rewards
• Wallet
• VPN
• News
• Talk
• Tor
• Wayback Machine
• Web Discovery Project
• Speedreader
What's left?
• Brave Shields
• Ad blocking
• Tracker blocking
• Security updates
• Chromium updates
The goal is simple:
Keep Brave's privacy protections while removing everything many users never touch.
The most interesting part is the pricing.
A $59.99 one-time purchase for a browser that's intentionally smaller than the free version.
While most browsers are racing to add AI, crypto, rewards, shopping tools, and new services, Brave is betting that some users want the exact opposite.
Less browser.
More browsing.
Would you pay for a minimalist browser?

48
15
251
24,215

Speedometer 3.1 shows a slight speed increase over the "newer Brave" and a larger one over Helium. I too find the launch faster. I too wanted speedreader enabled and it now is. So I am pleased with it.
1
2
143

Jun 3
I was thinking maybe speedreader and playlist could be not compiled out but treated like the upgrade path on brave where it can be enabled via admin policy management.
1
3
154



May 26
"Imagine if someone photocopied every book in the public library, burned the library down, and then opened a subscription service for the copies. That's the metered intelligence business model."
Sorry but this is retarded. That is not the business model at all.
The AI companies aren't selling the data they used to train their models. Training their models didn't require the destruction of the data. For the most part those data are just as available as they always were. More or less anything you want to read is available for free, if you know where to look. There are 64 million books on Anna's archive, along with 95 million scientific papers.
The problem is that you are not going to read 65 million books and 95 million scientific papers. An especially dedicated reader might read one book a week, on average. A real speedreader might get through a book a day. At that rate the speedreader would take about 200,000 years to read Anna's Archive. Which would be a painful experience, because 99.99% of books are shit.
It hasn't been possible for humans to read everything that's ever been written for several centuries. There's just too much of it. And the problem is just getting worse. There's more stuff to read every year.
Unlike a human, an LLM actually can read everything that's been written, in the sense that the corpus can be compressed into a single set of model weights. Better yet, that model can then be interrogated using natural language. It's a library containing all human knowledge, which you can talk to like a person, and which will formulate its answers to your queries based upon its entire knowledge base. The sheer scope of knowledge that's been produced already makes this technology invaluable, probably even essential. The business model isn't access to data, it's access to an interrogable model. To use the utility metaphor, they aren't claiming to have invented water; they're claiming to have built an aqueduct.
OK, so, should the AI companies have paid copyright-holders for the data?
This is the same copyright-trolling that's been used to artificially hobble the Internet since Napster was dismantled by the music labels for undermining their distribution and curation oligopoly. Remember Google Books? That was supposed to be a free Library of Alexandria, until the publishing houses shut it down because making the long tail of their out-of-print back catalogues freely available was going to cost them money somehow; result, Google Books is useless. Then there's the scientific publishing industry putting every single peer-reviewed paper behind a $30 paywall, despite not having paid for either the research or the peer-reviewing. Insofar as the data aren't easily available, it isn't the fault of the AI companies. It's due to artificial restrictions demanded by copyright-holders. The OP's 'burning down the library to open a subscription service' characterization isn't what the AI companies are doing, it's what the copyright corporations have already been doing for decades.
AI companies aren't selling or providing copyrighted works. Their models are generally prevented from reproducing published works at all, precisely to prevent them from being used for wholesale copyright circumvention (which is retarded, because you can still find those works for free, but anyhow). Tracking down every single rights-holder for every single byte would be a Herculean task, and for a lot of it (e.g. Reddit posts) there's no one to pay (they already got paid in Reddit gold). Are the companies supposed to obtain positive consent from every individual redditor who ever got an updoot for every single post they scraped? Posts that were made on the open Internet, for anyone to read? When all they are essentially doing is performing a mathematical operation to compress that data into an unindexed model?
That would simply be impossible, the same way it was impossible to legally fill a 100 GB iPod using $1 mp3s purchased from the iTunes music store (unless you were willing to spend $30,000 on mp3s, which no one was, and which Apple understood quite well). It would stop the development of this technology dead in its tracks.
Which is the real point here.
May 26

Let me trace the timeline here because nobody's connecting it.
Step 1: Scrape the entire internet. Every book, every article, every conversation, every piece of art, every forum post. Do it without asking. Do it without paying.
Step 2: Train a model on all of it. Call it "artificial intelligence."
Step 3: Go to BlackRock's Infrastructure Summit and announce: "We see a future where intelligence is a utility, like electricity or water, and people buy it from us on a meter."
Step 3 is where you sell people's own knowledge back to them. On a meter.
They took the collective output of human thought, compressed it into a model, and now they want to charge you by the token to access a version of what you and everyone you know already created.
One Reddit user put it perfectly: "They stole all this data from us, the people, our life's work, creativity, art, by devouring the internet and blowing through all copyright laws. Now they want to sell it back to us in the form of a utility."
Imagine if someone photocopied every book in the public library, burned the library down, and then opened a subscription service for the copies.
That's the metered intelligence business model.
And they're pitching it to infrastructure investors as though they invented water.
14
26
200
7,518

Her mother was pathologically late to everything. The story her brothers told is that Princess May read all three volumes of Motley's The Dutch Republic waiting on her mother to come out to go to a play.
I looked it up. That's a long wait!! Or maybe Queen Mary was a speedreader?

2
19
549

May 3
not sure,i read absolutely tonnes of old books(speedreader) n take pics of pages ,sometimes i remember to take a pic of the books name n sometimes i did not ,this was one of those times ,lol i thought id remember what the names were .just goin thru a few old pics on my laptop
2
11
2,721

Apr 24
Brave Origin is basically Brave…
with everything unnecessary removed.
What’s gone:
• Rewards Brave Ads system
• VPN, Wallet, Leo AI
• News, Playlist, Speedreader
• Tor, Talk, Web Discovery
• telemetry, usage pings, crash logs, analytics
What stays:
• Brave Shields (adblock tracker blocking)
• Chromium engine security patches
• fast, private browsing core
Platforms:
• Android
• iOS
• Windows
• macOS
• Linux (free)
How it works:
• standalone minimal browser
• or upgrade with features toggled off by default
• future features disabled automatically
Access:
• one-time purchase
• works across multiple devices
No growth features. No tracking.
Just browsing.

42
18
375
48,327