
23 Sep 2024
GPT-4 for coding at home! Qwen 2.5 Coder 7B outperforms other @OpenAI GPT-4 0613 and open LLMs < 33B, including @BigCodeProject StartCoder, @MistralAI Codestral, or Deepseek, and is released under Apache 2.0. 🤯
Details:
🚀 Three model sizes: 1.5B, 7B, and 32B (coming soon) up to 128K tokens using YaRN
📚 Pre-trained on 5.5 trillion tokens, post-trained on tens of millions example (no details on # tokens)
⚖️ 7:2:1 ratio of public code data, synthetic data, and text data outperformed other combinations, even those with more code proportion.
✅ Build scalable synthetic data generation using LLM scorers, checklist-based scoring, and sandbox for code verification to filter out low-quality data.
🌐 Trained on 92 programming languages and Incorporated multilingual code instruction data
📏 To improve long context, create instruction pairs with FIM format using AST
🎯 Adopted a two-stage post-training process—starting with diverse, low-quality data (tens of millions) for broad learning, followed by high-quality data with rejection sampling for refinement (millions).
🧹 Performed decontamination on all datasets (pre & post) to ensure integrity using a 10-gram overlap method
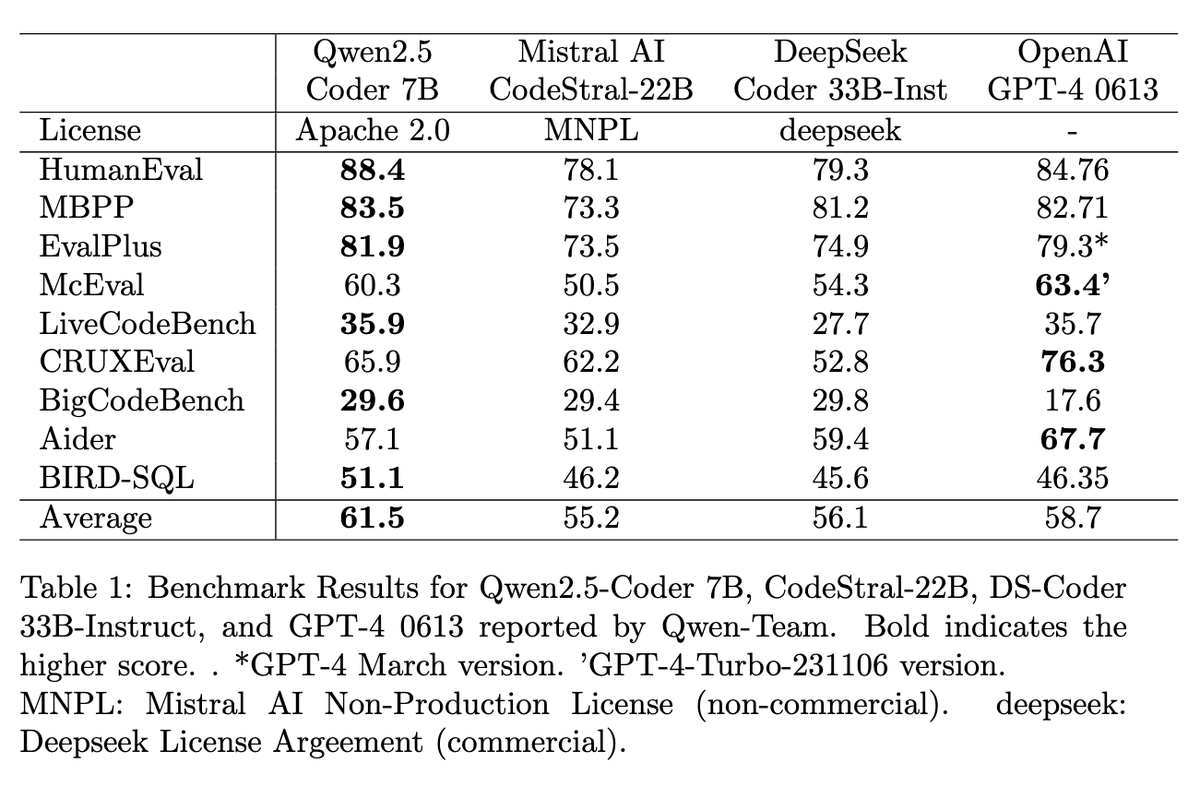
🏆 7B Outperforms other open Code LLMs < 40B, including Mistral Codestral, or Deepseek
🥇 7B matches OpenAI GPT-4 0613 on various benchmarks
🤗 Released under Apache 2.0 and available on @huggingface
Models: huggingface.co/collections/Q…
Paper: huggingface.co/papers/2409.1…
9
68
437
87,271

there was also RedPajama-INCITE family with all data pipeline, training instruction data, training recipe, checkpoints available huggingface.co/togethercompu…; & this is built on @AiEleuther's @BlancheMinerva pioneer work; and Startcoder also has many of these components open
2
7
2,268
8 Jun 2023
We fine-tuned StarChat Beta on the new StarCoderPlus (15B) ⭐️, which is a further trained version of StartCoder on 600B tokens from the English web dataset RedefinedWeb (Faclon dataset 🦅) 🔥
StarChat and StarCoder are open and can be used for commercial use cases 🤑
🧵3/4
2
3
12
2,470

15 May 2023
💫 StartCoder / SantaCoder ggml examples
Sample inference examples of these models have been added to the collection of ggml supported models
MPT and Replit support are also being worked on
github.com/ggerganov/ggml/pu…
1
13
93
44,601

5 May 2023
Proud to be part of this incredible journey with @LoubnaBenAllal1, @lvwerra & the amazing team! 🎉 StartCoder has this unique capacity to incorporate jupyter text/output. Experience it for yourself here: chrome.google.com/webstore/d…
Or github.com/bigcode-project/j…
4 May 2023

Introducing: 💫StarCoder
StarCoder is a 15B LLM for code with 8k context and trained only on permissive data in 80 programming languages. It can be prompted to reach 40% pass@1 on HumanEval and act as a Tech Assistant.
Try it here: shorturl.at/cYZ06r
Release thread🧵

1
6
21
16,576

25 Aug 2021
Resumindo a vida de um StartCoder em uma imagem 🙃
Essa saiu lá do nosso Discord! Vem fazer parte, dev: discord.gg/vGZX7xpUXv

7
25 Aug 2021
Você é pessoa desenvolvedora? Se torne StartCoder e acelere sua carreira júnior 🚀
📢 Entre agora no Discord: discord.gg/vGZX7xpUXv


1
6