
Agents & Gemini API, MTS @GoogleDeepMind | prev: Tech Lead at @huggingface, AWS ML Hero 🤗 Sharing my own views and AI News 🧑🏻💻 philschmid.de
Joined June 2019
- Tweets 6,008
- Following 1,164
- Followers 86,380
- Likes 7,664
1,904 Photos and videos












Pinned Tweet

11 Dec 2025
Excited to introduce the Gemini Interactions API, a unified interface for Gemini models and agents. Starting today with Gemini Deep Research Agent.
- Unifies access to models and agents via a single RESTful endpoint.
- Access Gemini Deep Research agent via API.
- Optional server side context management.
- background execution for long-running inference.
- Remote Model Context Protocol (MCP) servers support.
Spent the last six months building this with an amazing team! I couldn’t be more proud and excited.
Models evolve into systems and we want to give you the best developer experience. Give it a try and share your feedback. We will listen and want to build this with you in public.

29
44
454
59,043
Jun 12
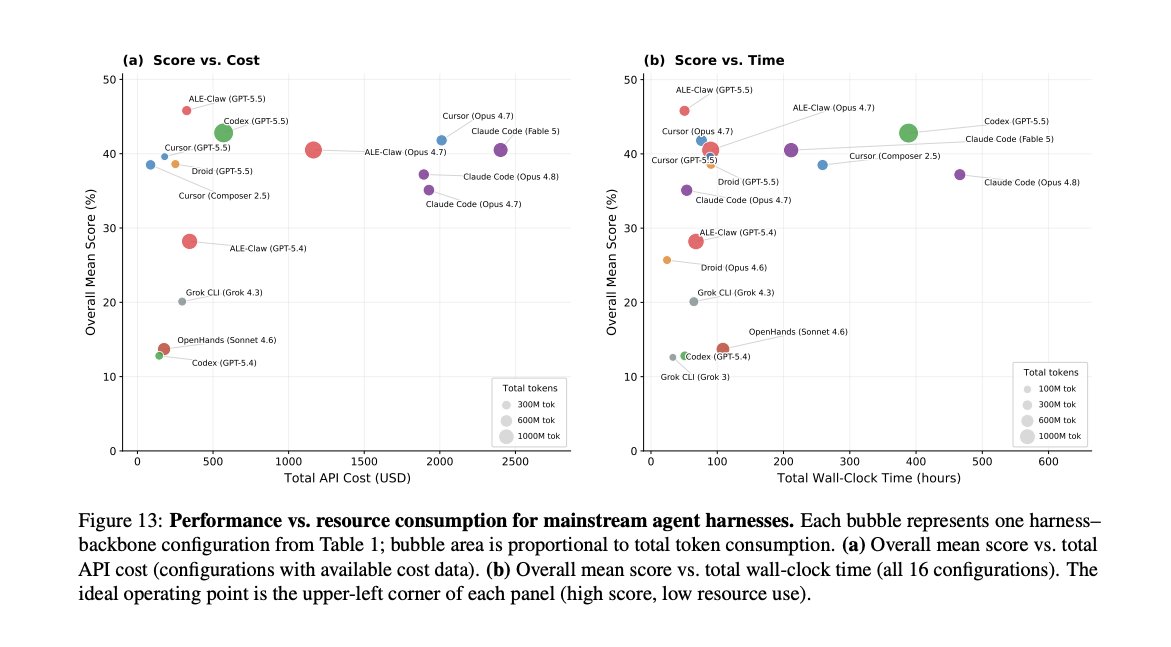
The last benchmark for agents? Agents' Last Exam (ALE) evaluates agents on 1,000 real world professional tasks across 55 industries, all sourced from actual expert work. Not synthetic. Not multiple choice. Real deliverables, graded deterministically.
Key findings:
- Best agents score <50% on the easiest tier, <10% on the hardest
- 82% on Terminal-Bench drops to 23% on ALE-CLI eval with the same setup
- Hardest tier: most frontier agents hit 0% pass rate
- Spending more tokens doesn't improve results
- Each run tracks harness, model, pass rate, token usage, and cost
Harness vs. model:
- Best harness scores 24.0%, worst scores 19.1% (same model). That's a 4.9pp gap.
- Model choice drives more performance variation than the harness.
- Most efficient setup used 160M tokens for 39.6%. Least efficient burned 1,373M tokens for 40.5%.
Where agents break (Agents often say "Done. All checks pass." while the output is wrong)
- 47% of failures: wrong strategy or gave up early
- 31%: missing domain knowledge
- 22%: execution bugs and format errors
- 34% of tasks need GUI software, agents avoid it and hack CLI workarounds
Very excited to see a benchmark like this. Big kudos to everyone who contributed.


8
8
65
4,312
Jun 11
Coming to API soon.

Exciting news: Gemini Omni Flash is now #1 in the Video Arena (both Text-to-Video and Image-to-Video)!
For Text-to-Video this is a massive 158 pt improvement over Veo 3.1 (1080p) and a large 61 pt lead over the next best model, Seedance 2.0.
Congrats @GoogleDeepMind for this huge milestone!

7
8
121
5,699
Jun 11
We rewrote our Gemini Interactions API getting started guide from scratch. Go from your first API call to running autonomous agents in 11 steps.
- Text, Multimodal understanding, image generation with Nano Banana.
- Streaming responses, stateful and stateless multi-turn conversations.
- Built-in tools: Search, code execution, Maps, computer use.
- Function calling, managed agents, and background execution.
Good time to take a look if you haven’t 👇🏻
6
11
115
5,955
Jun 10
Gemma goes diffusion! DiffusionGemma with up to 1000 tokens per second! 🌬️
- Built on Gemma 4 as a 26B MoE model.
- 3.8B parameters during inference.
- Generates text in 256-token blocks in parallel.
- Fits within 18 GB VRAM limits when quantized.
- Apache 2.0
20
41
534
41,948
Jun 10
Wrote an interactive blog on how Gemini Managed Agents work under the hood.
One API call spins up an isolated sandbox where Gemini reason, calls tools, execute code, read outputs until the task is completed.
The post covers the execution loop (with a live simulator you can click through), showing what happens inside the sandbox and how it communicates between the API and the sandbox.
Blog ⬇️
5
17
172
8,802
Jun 9
Gemini 3.5 Live Translate! We just shipped a real-time babel fish.
- 70 languages, 2,000 language pairs.
- Natural translated speech, works in noisy environments.
- Stays in sync with the speaker, no lag, no awkward pauses.
- Auto-detects the language being spoken.
Available today in Google Translate (Android & iOS), the Gemini API (Public Preview), and Google Meet (Private Preview).
I genuinely think this is the beginning of the end of language barriers. Anyone can now speak and understand anyone.
27
45
309
17,137
Jun 9
Google Colab CLI and Skills are out. Full Colab runtimes from your terminal.
- GPU/TPU provisioning (colab --gpu A100)
- Remote script execution (colab exec)
- Interactive console/REPL access
- Built-in agent skill
Tell your agent "fine-tune Gemma 3 1B on this dataset" and it provisions a GPU, runs the training, downloads the adapter weights. Fully automatic.
24
86
584
46,193
Jun 8
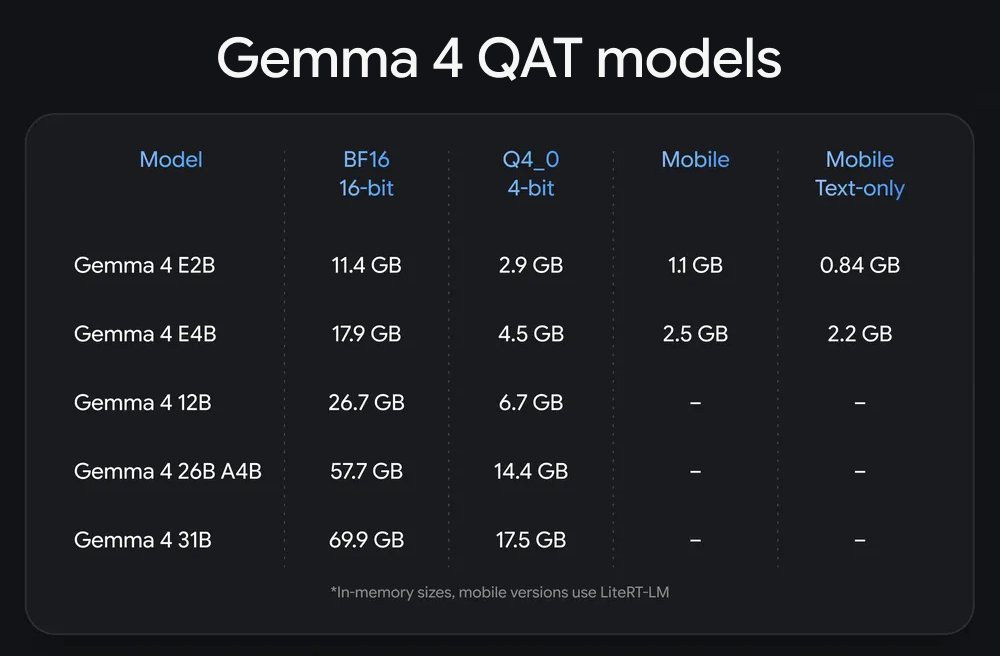
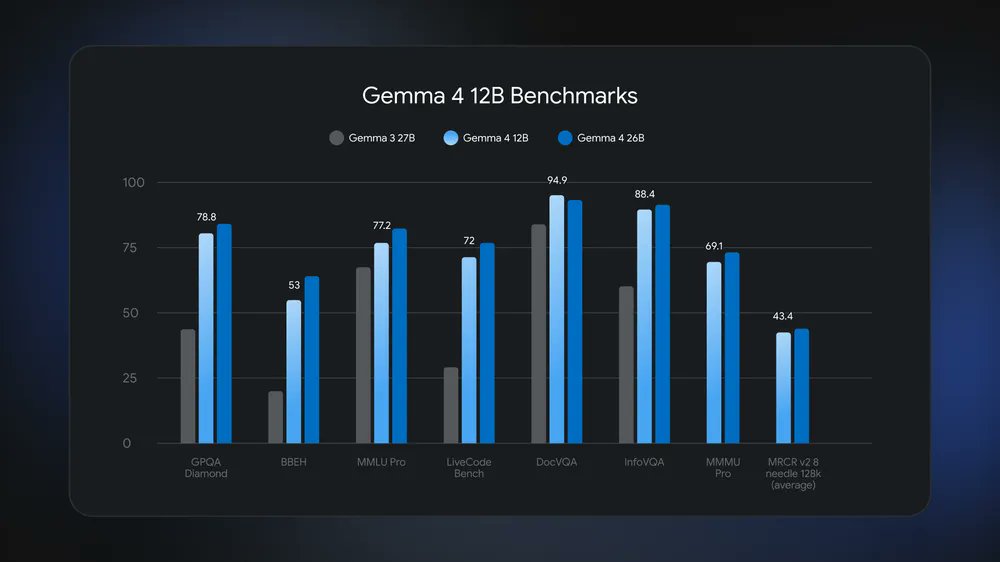
More Gemma 4! New QAT Gemma 4 checkpoints with similar performance while using ~4x less memory!
It comes with a new mobile quantization format that reduces memory footprint of Gemma 4 E2B to just 1GB.
Quantization-Aware Training (QAT) simulates low-precision operations during training to allow loss-less quantization afterwards for smaller, faster models while maintaining accuracy.
Available on @huggingface and directly runnable.
20
53
598
31,802
Jun 8
Subagentmaxxing or /goal subagents (^2 depth).
You should naturally evolve towards this when you try to max your agents run for longer or solve more complex task. You replace your oversight with another agent, and then their oversight with another agent around.
Jun 7

Here’s your monthly reminder that you shouldn’t be prompting coding agents anymore.
You should be designing loops that prompt your agents.
20
4
86
7,791
Jun 6
My personal research question for today: Should we optimize the model for a harness or should the harness be optimized for the model?
243
15
419
57,966
Jun 5
Milk first or cereal first? I'm a cereal-first person. Apparently cereal acts as "a baffle" that stops milk from splashing, but pouring milk first causes a perception bias that leads to overeating. Wdyt?
This is all generated by Gemini via a single prompt built on Managed Agents. The script, the voices, the background music. One prompt.
Free to try in AI Studio.
10
4
57
10,543