May 25
Yoo, Finally completing it
Most modern sharded database (like Apache ShardedSphere, PgDog) rely on distributed consensus to coordinate cross shard transaction but standard 2 phase commit has high latency under wide area replication ...
In standard 2PC we have : Preparing ---> Prepared ---> committing ---> committed
So I built a transaction coordinator which has a speculative mode ... we add three new shard level states : SPEC_EXECUTING ---> SPEC_COMMITTED --> SPEC_ROLLED_BACK (in simple words a control panel in between of sql aware router and different mysql and postgres shards)
the coordinator tracks a speculation log in etcd same CAS protected state transition as the transition log ... this is done so that two coordinator don't mug up each other .... The undo log in MySQL captures the pre image delta before speculative write and the rollback is stored in procedure soo if a shard crashes mid-speculation, it reads the undo log on recovery and restores state.
This project is my major step to help see why speculative consensus can cut distributed transaction latency
Tech stack : [[ golang ]] for the coordinator engine, [[mysql-8.0-instance]] shards (a, b, c), [[ etcd ]] for service discovery, [[ sysbench ]] so its obvious I cannot have 20k to 30k as a scale on my own at this stage I need to first simulate it ... so sysbench helps me with it... [[ prometheus & grafana ]] for latency histogram .. [[ innoDB ]] for row level locking ... [[ toxiproxy ]] for packet loss injection
6
5
148
9,775

May 24
BUG NET Tokyo Performance VPS 🇯🇵
High-performance KVM VPS in Tokyo, Japan, powered by AMD Ryzen 9 7950X3D.
Plans from £6.99/mo:
Tokyo VPS Chlorine
1 vCore / 2GB DDR5 ECC / 30GB NVMe
4TB traffic @ 2Gbps
1 IPv4 /64 IPv6
Tokyo VPS Bromine
2 vCore / 4GB DDR5 ECC / 45GB NVMe
8TB traffic @ 2Gbps
1 IPv4 /64 IPv6
Tokyo VPS Iodine
4 vCore / 8GB DDR5 ECC / 75GB NVMe
16TB traffic @ 2Gbps
1 IPv4 /64 IPv6
Good for:
Website hosting
Self-hosted apps
Docker workloads
Game servers
Bots
VPN / WireGuard
Code compiling
Lightweight production services
Port 25 is blocked by default.
Extra traffic can be requested by ticket at £1.5/TB.
Free offsite backup can also be requested by ticket.
Benchmark sample from an older 60GB disk config:
Sysbench single-core: 6390.80
Sysbench multi-core: 23279.07
4K Q1 read/write: 102 MB/s / 97.1 MB/s
4K Q32 read/write: 1033 MB/s / 620 MB/s
Sequential read up to 16GB/s
Sequential write around 3GB/s–4GB/s
Small provider, real hardware-focused VPS, Tokyo location.
Order here:
bug.pw/products/japan-tokyo-…
6
9
141
May 24
I actually love to build my side project using go, etcd, sysbench, toxiproxy, grpc and grafana
8
3
205
8,367

May 6
Sysbench is too damn slow for this project. I have to port the tests to Rust and run them inline in the server by simulating connections.
1
10
893

May 5
Thank you. I just learned a lot more about sysbench-tpcc. It’s honestly so different that it feels like the only thing it shares is the schema. Feels very lazy/dangerous to call that “TPC-C-like” without the full caveat.
It looks like CockroachDB just uses actual TPC-C?
1
2
91

TPC-C is a meaningful, well-defined standard. "TPC-C Like" is not.
Happy to benchmark with Percona-Lab/sysbench-tpcc's TPC-C Like benchmark as well. Removing the keying time is music to @spacetime_db's ears.
3
227

May 2
各一回ずつしか回してないけど sysbench でCPUのベンチ取ってみた
それぞれ60sの実行でCore i9とXEON GoldはProxmox-veで、他のはWSL上のDebianで計測した


3
122

这是我在 2025年 12月公司内部 AI Agent 使用实战演示45 分钟精华的总结,这些经验在半年后仍然适用,这就是 AI Native,比大家领先了一个世纪😀
主题:从一个 DBA/SRE 的视角,演示 Claude Code / Amazon Q CLI 这类"终端 Agent 型AI"怎么用,他们和打开 Web 聊天窗口问 AI是两回事
下面文章中的 “他” 都是说的我,这部分内容是 AI 根据我的分享视频提取总结的:
一、贯穿全场的核心论点
1. Web 聊天 ≠ Agent,这是两种工具
大部分人用 AI 的姿势是:打开网页 → 问问题 → 复制代码 → 本地跑 →
出错再回去贴。这种模式下 AI 只是"更聪明的搜索"。
真正的量变来自 CLI Agent(Claude Code /kiro CLI):AI
直接读你本地文件、调你本地命令、登你的 AWS、连你的 SSH、写配置、跑程序、看报错、自己 debug、重试——整条链路闭环。
2. 产出效率量级提升
他在团队里强推这套工具的效果:
- 最近 3 个月基本没自己写过代码
- 但这 3 个月的产出相当于过去 一整年的工作量
- 所以对团队提了条硬规定:周报里不要再写"这个代码进度 30% / 50% / 90%"这种话术,以后不存在了——一个运维类的任务一天之内就该喝着茶搞完
3. AI 不挑平台,不绑死AWS——那个时间点同事们不理解 Agent 是什么
听众多次追问"这工具是不是只能适配 AWS",他反复澄清:跟 AWS 零关系。同一个 Agent 可以操阿里云、操 IDC 机房、操 macOS 本地容器——关键在你本地把凭证/权限打通。
---
二、4 个实操案例(递进关系)
#: 1
任务: AWS RDS MySQL vs Aurora MySQL 对比压测
关键动作: 一句 prompt → AI 自己建 VPC/子网/安全组/两种实例/EC2、装 sysbench、跑 96个场景、存原始数据、生成对比报告
看点: AI 自己把任务分解成 8步,像模像样;参数给错(内存/实例规格不支持性能指标)能自己读 error 改对
────────────────────────────────────────
#: 2
任务: macOS 本地搭 MySQL HAProxy 压测环境
关键动作: AI 用陌生的 Limacon tool 起容器、配网络、改密码、画出网络拓扑图
看点: 不会用的工具让 AI搭完,顺便问它"网络怎么通的"——它输出的架构图比人工写的文档还清楚
────────────────────────────────────────
#: 3
任务: 中间件健康检查 Web 工具(Redis / Kafka / RabbitMQ / MQ)
关键动作: 起因是同事反复找 DBA 排查"连不上"的问题。让 AI 写检查脚本 → 扩展 Web界面 → 加端口参数 → 做成 systemd 服务 → 加日志 rolling
看点: 从 0 到上万行代码没亲手写过一行;关键是"拆成一个个小任务"让 AI 迭代做
────────────────────────────────────────
#: 4
任务: 跨云综合对比报告(IDC / 华为 / 阿里云 / AWS)
关键动作: 让 AI 把多次压测原始数据汇总成 P95/平均时延对比、64 线程瓶颈分析、摘要 详细场景分
看点: "我自己测能比他测得好,但我没耐心写出这么漂亮的报告。AI 没有耐心问题。"
---
三、散落但重要的经验(给要上手的人)
1. Prompt 不是一句话,是逐轮迭代:开始给粗指令,看 AI跑的过程中补细节(比如"每个场景压 10 秒而不是 300 秒"、"每 10 秒输出一次数据"、"给我完整的 AWS 命令参数方便我复现/验证")
2. 给正反馈,不只给纠错:AI写对的时候要告诉它"这段写得对"——否则它下一轮改着改着会把对的改坏
3. 过程要盯,不能只看报告(听众抛出的好问题):漂亮的测试报告不代表测得对;过程中要看它采用的策略是否符合你的预期
4. 环境安全第一:绝不让 AI 碰生产。先隔离到安全环境,凭证、profile、SSH key 提前在本地配好
5. 任务粒度:复杂系统别指望一次性生成。10 万行代码会失控(上下文跟不上),Web 工具那种"拆成小任务滚动迭代"才稳
6. AI 比 AWS 专家靠谱的地方:专家讲的都很"飘"、只精一个点、没耐心;AI知识面广、耐心无限、能陪你一步步拆
7. 对 QA 的适用边界(现场问答):
- ✅ 纯 API / 接口自动化:非常擅长,告诉它接口语义和编排就行
- ❌ Web UI 点击式自动化:CLI Agent 干不了,得用 Manus 这类浏览器 Agent
---
四、一句话总结他想传达的
▎ "别老把 AI 当成 Web 聊天框里那个会写代码的助手。把它接到你的终端、你的凭证、你的机器上,让它替你执行闭环任务——你的工作方式和产出上限都会变。"
27
1
39
4,649

Apr 17
I managed to get the server to work with Sysbench insert tests. My carefully crafted WAL implementation had a TLA specification and was correct but performance was underwhelming. I had to abandon the spec to improve the performance.
14
1,635

Co-Founder Aaron Son reviewed DoltLite's code; Tim fixed issues in 6 hours, added remote support and SQLite attach in a week. Sysbench near SQLite, 5.7M queries pass, remote support live. Try it! Vibe coders unite! 🔗 dolthub.com/blog/2026-04-09-…

2
101

Feb 25
Is spacetime cool tech? Yes
Are these good benchmarks? No
I've done a lot of database benchmarking. It's fun. I like benchmarks! But these were poorly conducted.
- So many missing details. What cache warming was done? What region was each database and client in? What were the underlying instance types? Are we benchmarking databases or network latencies?
- Anyone create a narrow benchmark that makes a particular database look good. It's better to use widely-used standards (tpcc, sysbench workloads, etc)
- AFAICT the spacetime requests are heavily pipelined vs the Postgres options.
- Why does spacetime get a custom rust client (rust is fast!) and all the others have to run slow js clients with an ORM middleman over http/rpc?
Ultimately it's a big case of apples-to-oranges. Again, spacetime seems like cool tech! But comparing it to a 3-node HA semi-sync pg cluster is... an interesting choice.
Feb 24

Introducing SpacetimeDB 2.0.
Web development at the speed of light.
Come learn what fast really means.
21
11
325
45,884


Feb 9
Many DBAs use sysbench to decide which database is faster. Sadly, this kind of test reflects only a special case. If you truly understand networking and databases, you wouldn’t rely on it.
2
17
3,056
We just hit MySQL-level performance with Dolt (0.99x on Sysbench)! 🚀
Full benchmarks: ow.ly/S9FV50XCZT3
#DatabaseEngineering #DevOps #MySQL #DatabasePerformance #OpenSourceDatabase #DataOps

7
883
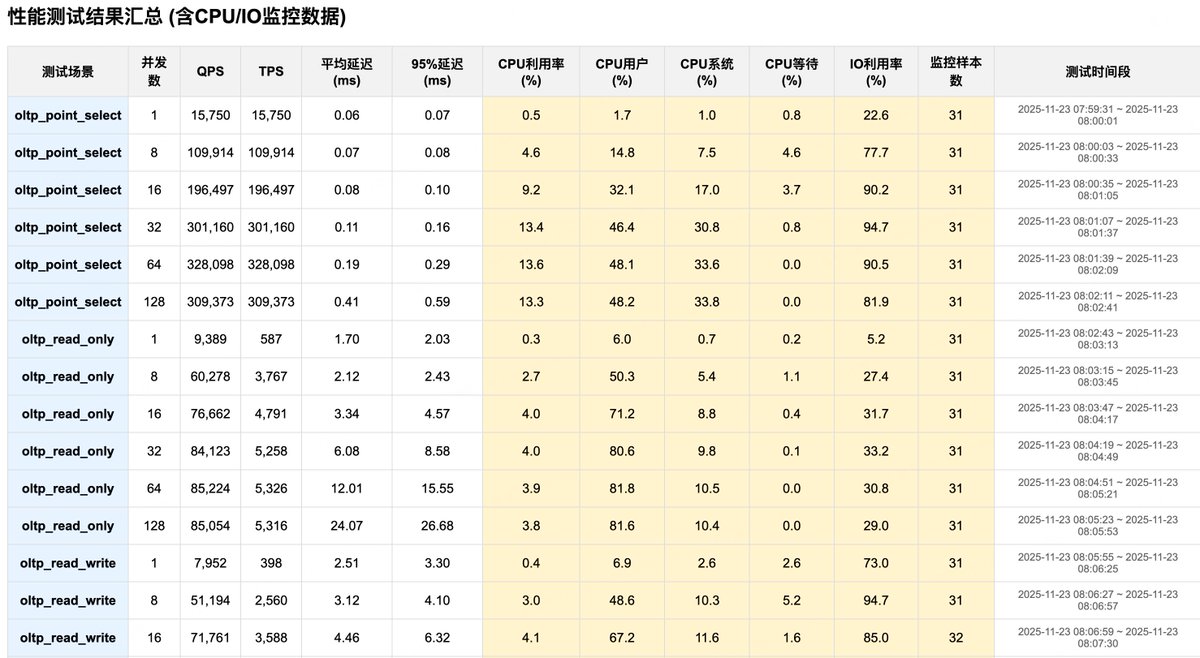
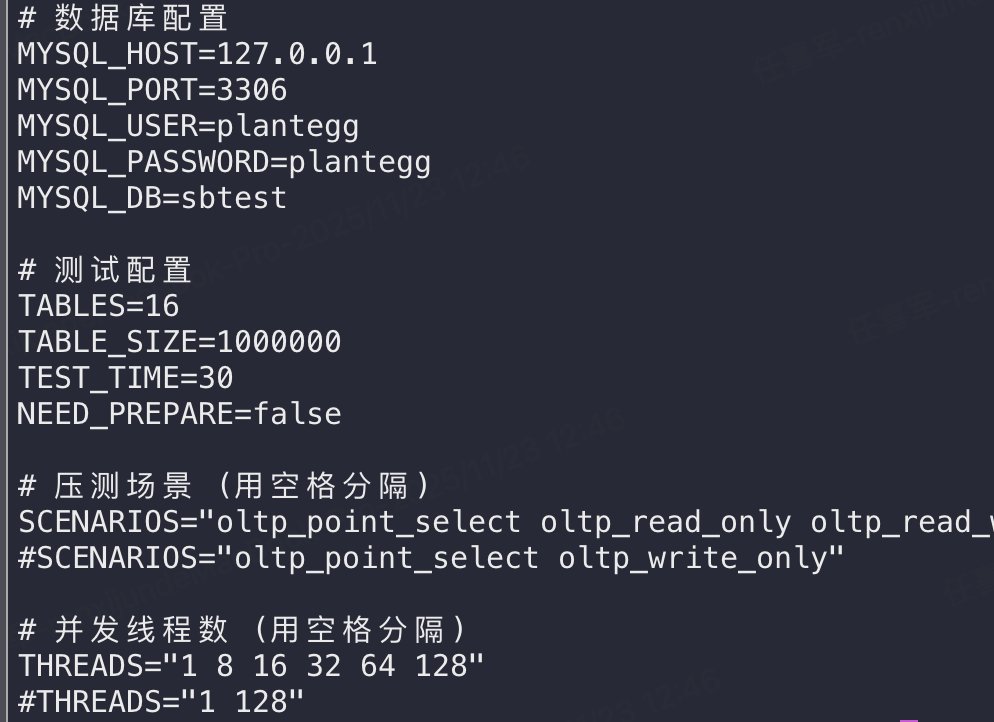
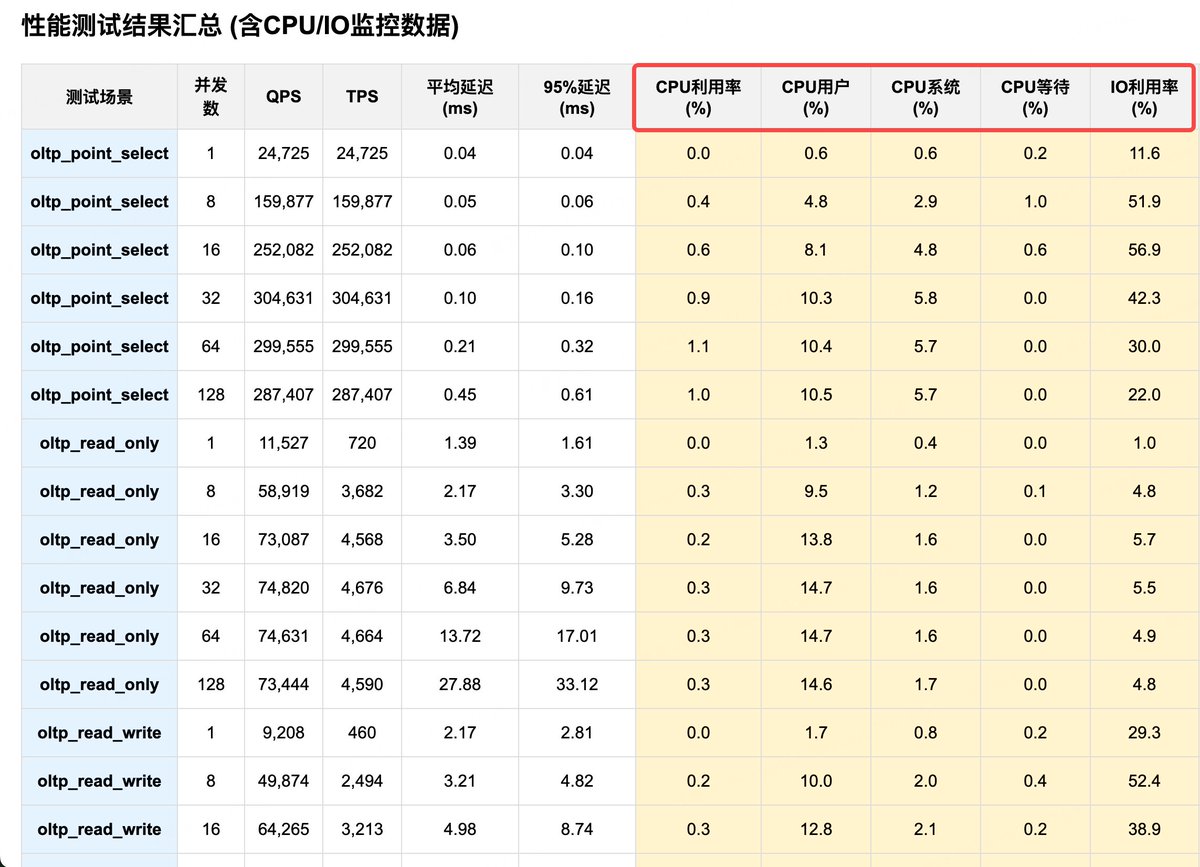
以我老司机的视角做了一个 sysbench 压测自动化工具github.com/plantegg/sysbench… 主要是后期报告生成,压测容易收集数据写报告太头疼了,图 2 是生成的压测报告和原始数据,一旦对数据有怀疑可以随时打开原始数据,图 3 将 CPU/磁盘指标加到了对照列,瓶颈点在哪一目了然

5
6
66
7,921

Linuxの改善でPostgreSQLのsysbenchの結果が18%向上の話、
128コアマシンでやっててロック競合等で性能サチった状況になってそうなので、ややミスリード感が…
(この辺ベンチマーク詳しい人に聞いてみたい)
lore.kernel.org/lkml/2025101…
25 Nov 2025

カーネル内のスケジューラがフィールド更新する時間を削った結果postgresqlのスループットが最大18%向上って、直感的にマジでってなる
2
817

24 Nov 2025
"pgbench-tpcc-like" is probably the easiest way to run TPCC-like workload on Postgres.
pgbench (bundled with PG) was always the simplest way to benchmark PG. But it defaults to TPCB workload.
sysbench with Percona's TPCC workload is not difficult to use, but requires more setup.
github.com/kmoppel/pgbench-t… is pgbench few scripts and you get TPCC-like workload.
6
1,438