


May 21
ラダイトさんからの新商品がいろいろ届きました。
今回の目玉は、#TechDraw2 用の着せ替え軸です。
本体と軸は別売り
そして、こちらも
TechDraw
LDB-MP2GB3-05
など3色
木軸のシャープペンシル
EVERDRAWシリーズも各種
ペーケースや小物入れも各種
#LUDDITE
#文具男子
#筆箱の中は男のロマン
↑
文具男子である(当時)中学生の格言です✨




1
8
33
965

May 13
Are you sure it is in the Daft WB and not the TechDraw workbench? There is a bounty on the this issue in TD WB, the team would like to see this implemented: github.com/FreeCAD/FreeCAD/i…
1
2
28

Will it optimize techdraw workbench drawing generation?
My laptop (mx linux) is a bit suffering when I generate technical drawings
Have to say it s not a beast with huge ram or powerful videocard
Just decent laptop...
2
185

May 3
I'm pumped to hear TechDraw is the target for improvements. It's probably the biggest roadblock to me using FreeCAD in any professional setting.
1
2
44

Apr 22
De Draft a TechDraw en #FreeCad ?
Pues si, lo que dibujamos en Draft lo podemos colocar en un plano en TechDraw.
youtu.be/ZDa3UNdf9iI
5
327





Apr 14
Craft Science is amazing when you master it
Part 2
Some people Struggle to cut plastic or cardboard material precisely and don't have much money to cut it by engraver. So what you can do is open CAD software (Recommend FreeCAD) and design what to make. And then after 3D design think what to take to cut and plot on A4, A3 and whatever drawing format called TechDraw Tool (in FreeCAD term).
What you need to learn is experience on CAD, not very hard. If you learn how to design like a kid then let your creativity be your muscle memory.
After the print out then cut out the object to be cut and stick on material and ready your mini saw machine or cutter and cut it with the assist of the geometric sticker.


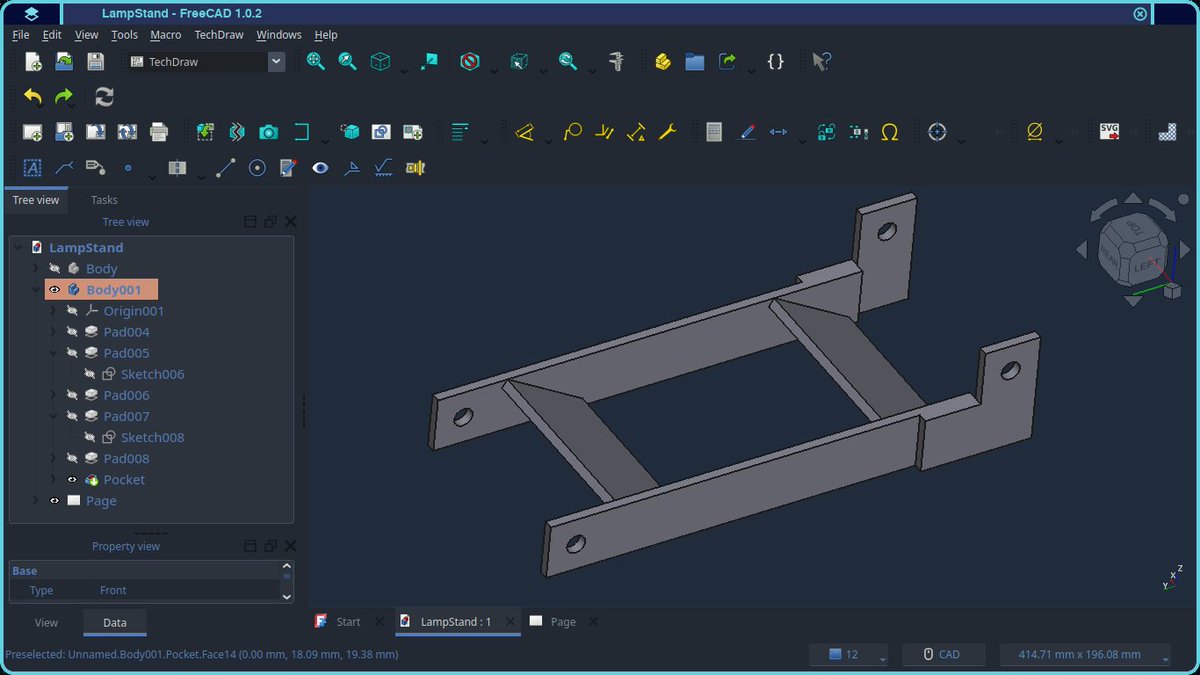
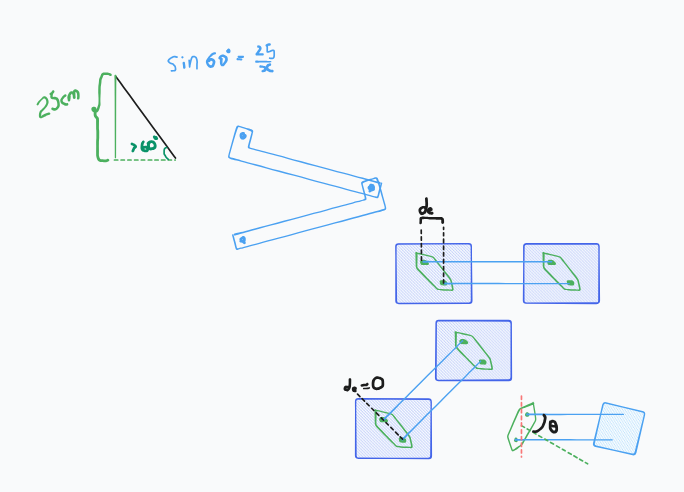
1
3
325
Apr 3
This video covers some of the new features of the #TechDraw workbench from the #FreeCAD 1.1 release:
youtu.be/2-NtCw9W9yE
My favorite new feature is the improved View Frames system.
#cad #OpenSource #FCBLounge

4
27
1,468


Mar 21
Also, prepared 2D layouts using FreeCAD's TechDraw bench to pass them along with a set of 3D-printed flat pieces to my friend who offered his help with the metal parts. Yes, metal parts. Actually can't wait to see how it going to look like in its true form.
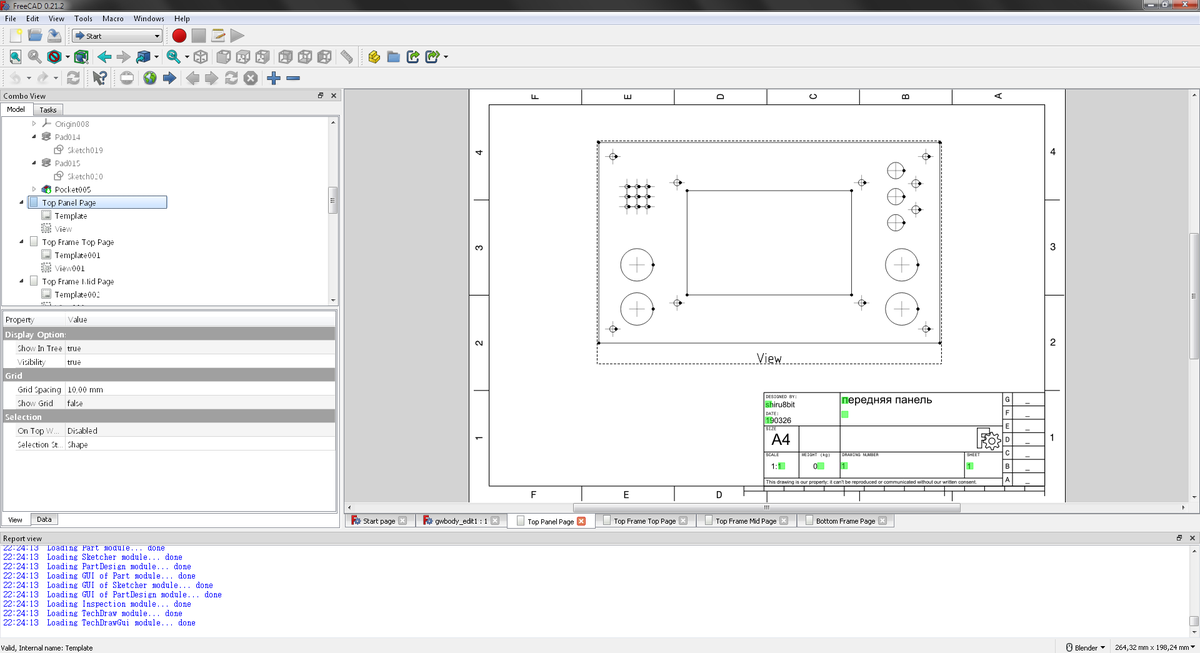
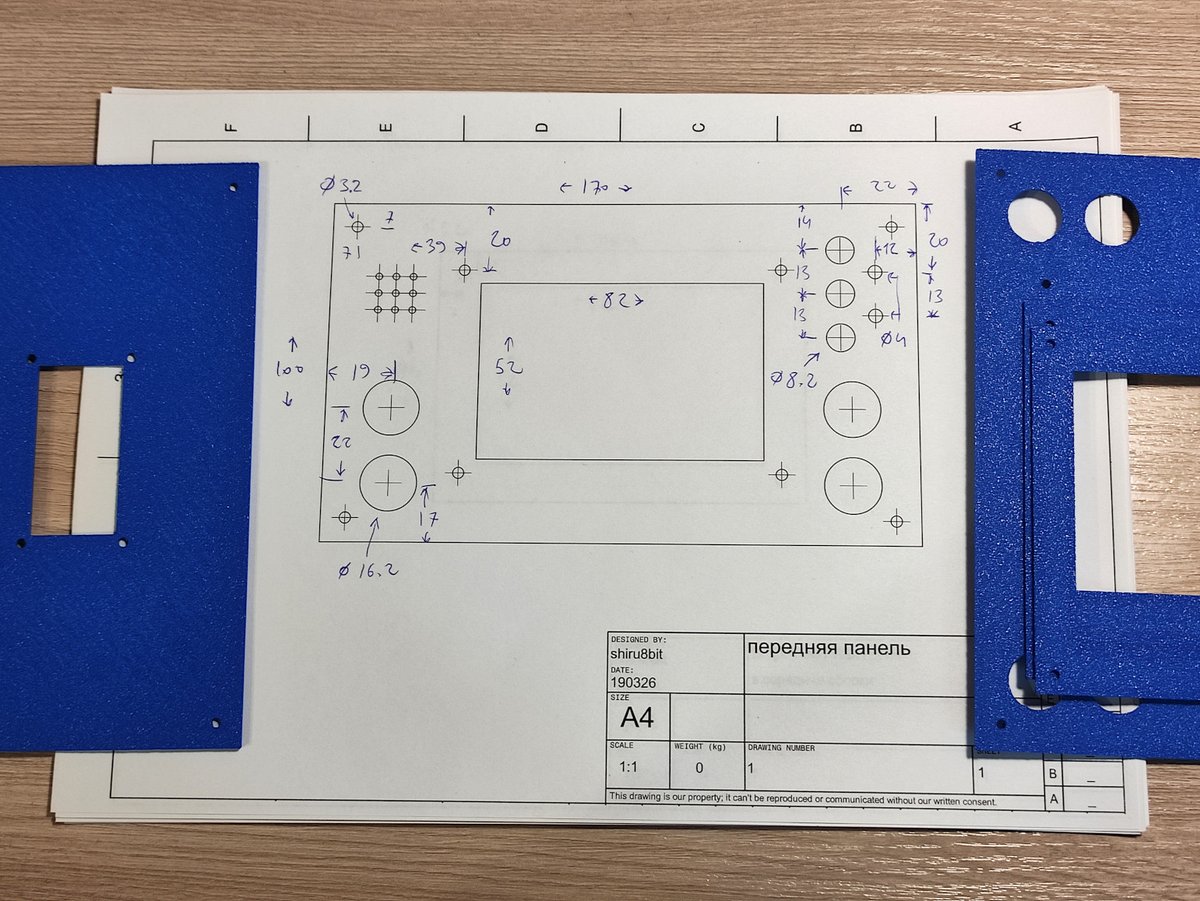


2
164

Mar 14
590さんから
TechDraw2 Custom Parts Factory Model (TQ)
を購入させて頂いたので、早速付け替えてみました✨️
ロフト限定の天冠がブルーバージョンのものに付けてみましたが、中々良い感じです😝
廣瀬鐵筆堂さんとのコラボTechDrawカスタム (真鍮六角漆焼付け/青)とともに💙

1
4
62
8,189

Mar 8

1
18
464
Mar 7
購入品3
Ludditeさん(@luddite_japan)×廣瀬鐵筆堂さん(@syake1505)
TechDrawカスタム (アルミ六角)
今回のイベントの1番の目的と言っても過言ではありません
このペンが発売されてから、ずっと憧れていたペンです
とにかくかっこいいです



2
4
41
8,981

Feb 23
Luddite TechDraw Wood Model Maple
note更新しました↓↓↓
note.com/kawekollektor/n/n95…
Luddite TechDraw Wood Modelは直径7.5mmという非常に細身の木軸を採用しています。木軸ペンとしてはかなりの細軸で、好みが分かれるサイズ感です。
一般的な木製シャープよりも明らかにスリムで、持った瞬間に「細!」と感じます。…
1
15
789



Feb 19
spent a week benchmarking code review tools on the same dataset (166 golden comments from human reviewers, 20 PRs, 9 languages). some findings:
1. triage > raw LLM. pointing GPT-5.2 at every line of a diff gives you noise. first figure out which entities changed, who depends on them, and how risky the change is, then point the LLM at just those 25 entities. recall goes up. precision goes up. the graph answers what the LLM can't: "how many things break if this changes?" deterministic, no hallucination, zero cost.
2. the coverage problem is real. on a 40-file PR, risk-based triage picked entities from src/Mod/Draft/ and src/Mod/BIM/. all 19 human comments were in src/Mod/TechDraw/, which had lower risk scores. a second pass on uncovered files fixed it. recall jumped from 36% to 39%.
3. dedup matters more than prompt engineering. tried 10 prompt variations. the one that actually moved precision from 17% to 25% was identifier-aware dedup: if two findings share 2 code identifiers, merge them. boring but effective.
4. more context is not always better. going from 3000 to 5000 chars of context per entity made things worse. the LLM found more things to comment on, most of them wrong.
5. model choice matters less than you'd think. GPT-5.2 was best. Sonnet 4.6 was most precise but too conservative. the triage dedup pipeline matters more than which model sits in the middle.
1
3
295

Feb 1
《三越文具祭り2026 出展者情報》
会場:本館7階 催物会場
<LUDDITE>
----------------------------------------
LUDDITE ~one and only~ 唯一無二でありたいという想いのもと筆記具やペンケースを中心にモノづくりをされています。
イベント中心に販売している木軸ペンはそのスリムさやデザイン性から他社にはなかなかない唯一無二の商品として特に中高生男子から人気を集めるブランドです。
----------------------------------------
-開催概要-
《三越文具祭り2026》
会期:2025/2/11(水・祝)-2/23(月・祝)
会場:日本橋三越本店
①本館7階 催物会場
2026/2/16(月)-2/23(月・祝) 10:00-19:00
※最終日閉場18:00
※5階と会期が異なります、ご注意ください。
②本館5階 STAs -STATIONERY STATION-店内
2026/2/11(水・祝)-2/23(月・祝) 10:00-19:00
③本館5階 イベント会場
2026/2/11(水・祝)-2/23(月・祝)10:00-19:00
入場料:無料
各種ホームページはこちらからご覧ください。
イベント専用HP:stationerystation.co.jp/ext/…
日本橋三越HP:mistore.jp/store/nihombashi/…
※※※注意事項※※※
■イベントのお問い合わせは下記メールアドレスまでご連絡ください。
三越文具祭り2026問い合わせ先:contact@stationerystation.co.jp
※STAs -STATIONERY STATION-(店舗)への直接またはお電話でのお問い合わせはお控えください。
■《三越文具祭り2026》での展開商品/ワークショップ/イベント/開催場所は予告なく変更となる場合がございます。
■取扱商品に関するお問い合わせにつきましてはお答えできません。
■混雑状況により会場全体また各ブースにおきまして整理券の配布/入場制限含む各種制限を行う場合がございます。
■館内は危険ですので走らずゆっくり歩いてお買い回りください。
#ラダイト
#LUDDITE
#EVERDRAW
#ALTDRAW
#Techdraw
#三越文具祭り2026
#woodpenstation
#ウッドペンステーション



3
21
3,810

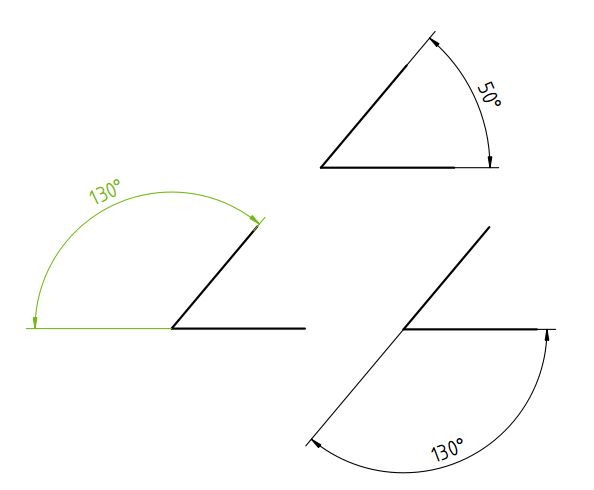
#FreeCAD #feature in the review process:
'nishendra3', new developer (unsolicited) decided to add Supplementary Angle Support to the TechDraw workbench (180° - Angle).
The beauty of the #floss #opensource process: Build it together, for everyone ✨
PR: github.com/FreeCAD/FreeCAD/p…
2
75
2,007