


Jun 14
No worry, I can't send it here sadly due to certain reasons but you can type "tensorhub login" and it should pop up. Its okie! Glad to help!
1
81



Apr 21
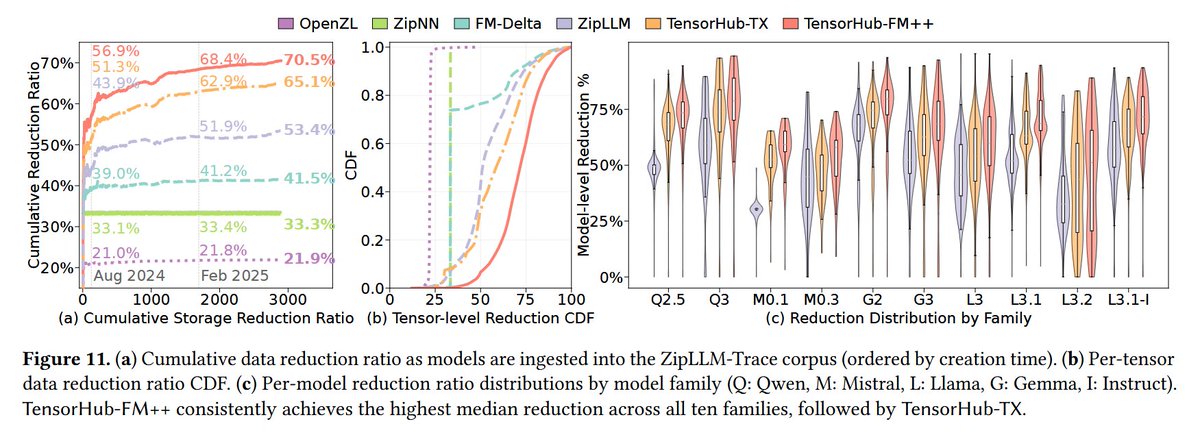
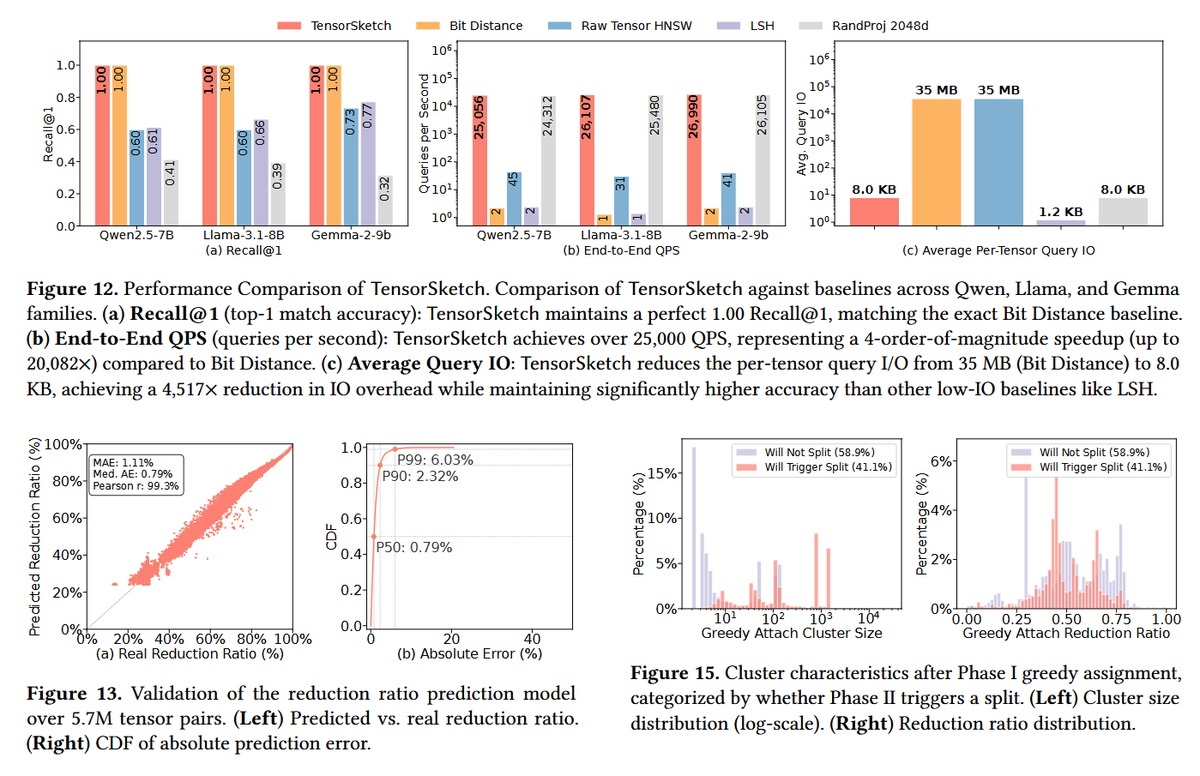
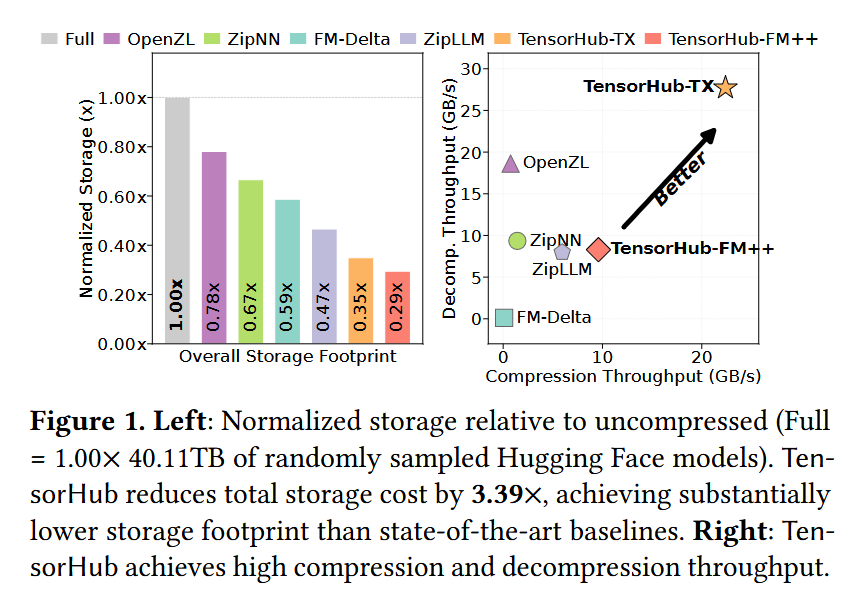
The results show that TensorHub reduces storage footprint by 70.5%, 37% lower than state-of-the-art design, and also achieves 22.9 GB/s compression and 28.4 GB/s decompression throughput, which are 3.86x and 1.49x faster than the next-best system, respectively.
1
4
430
Apr 21
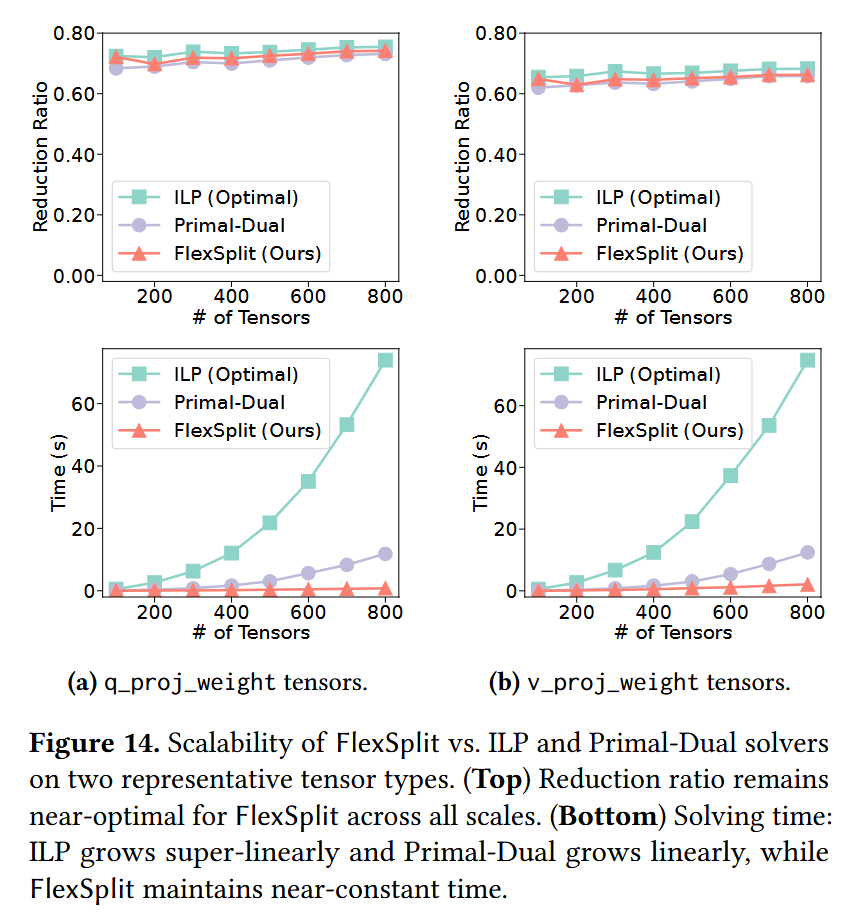
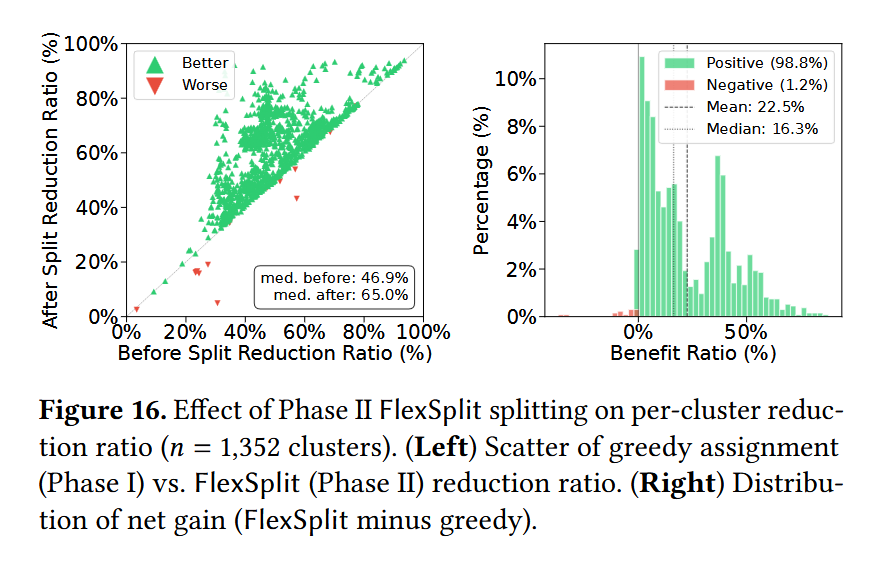
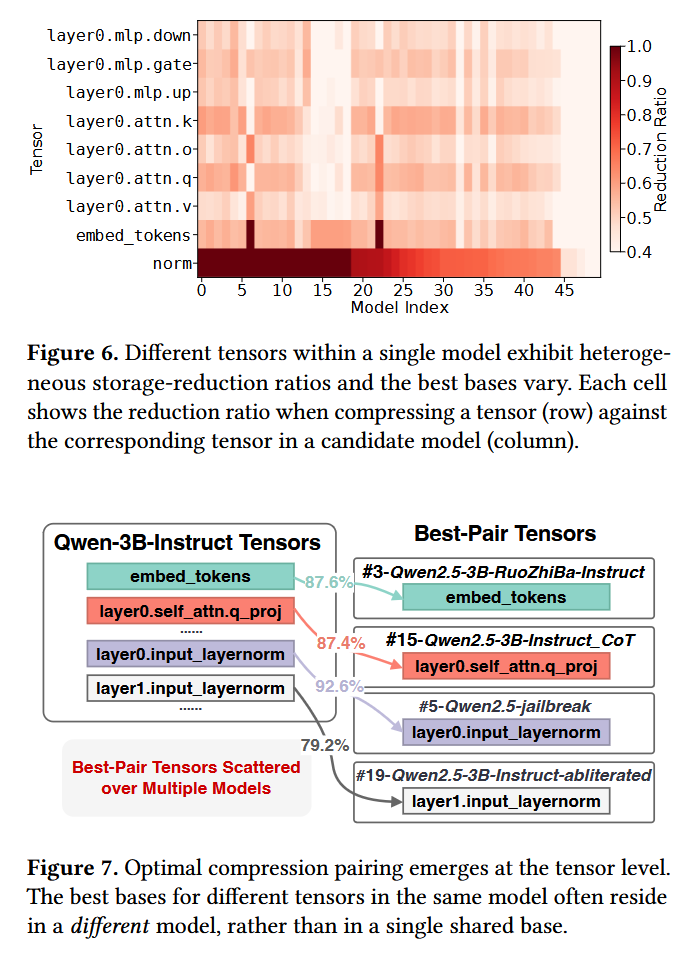
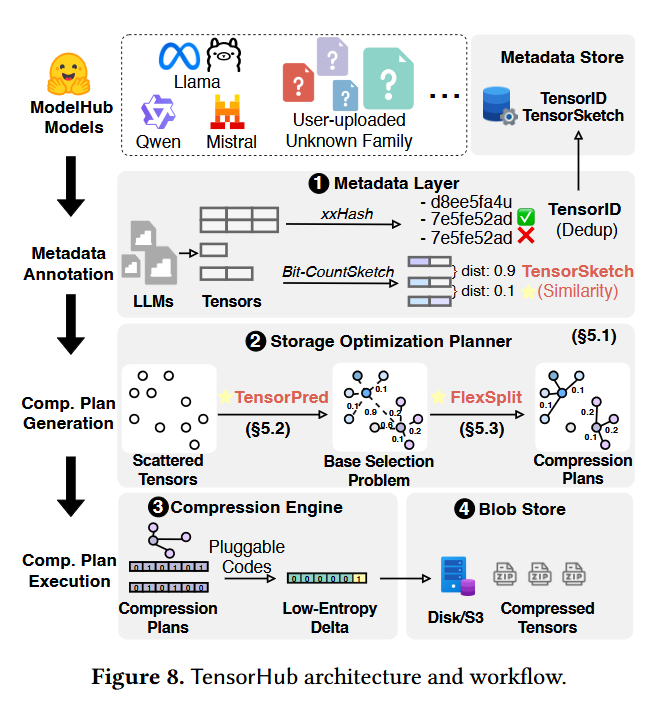
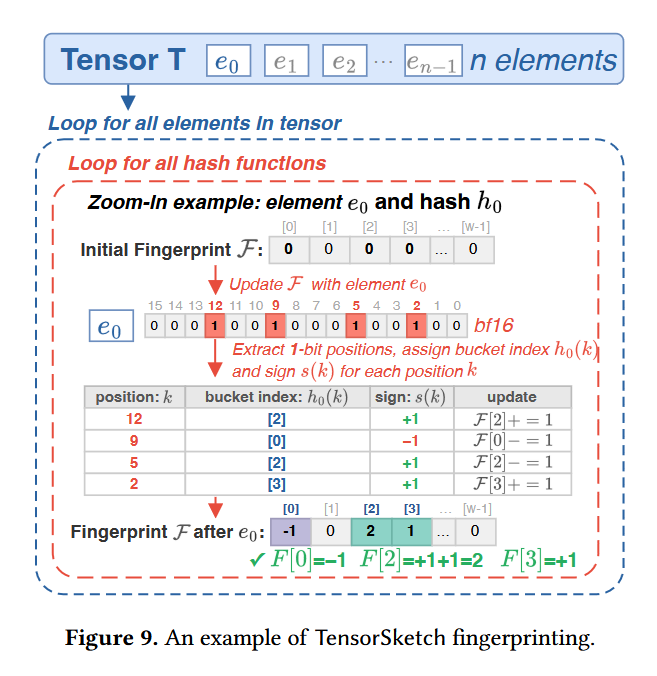
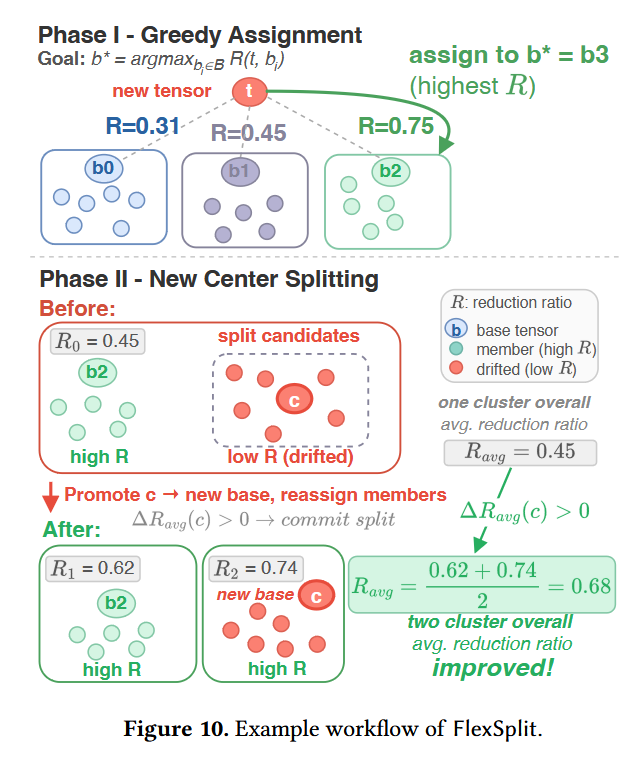
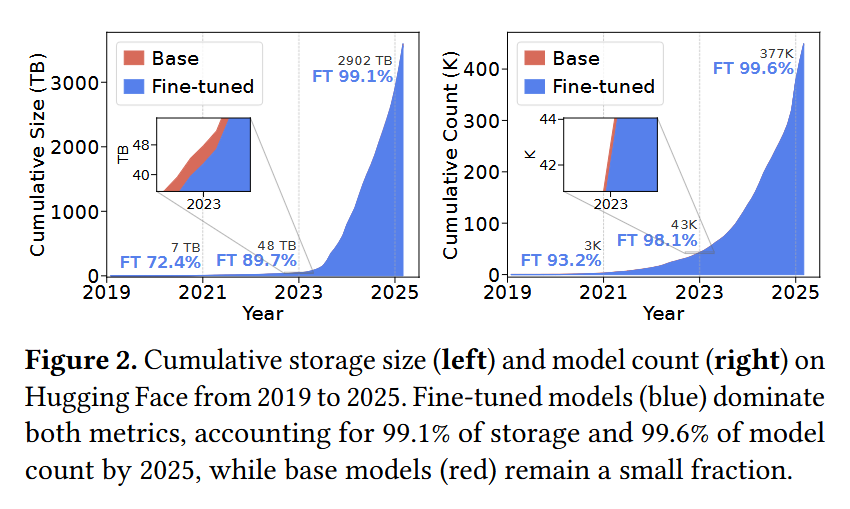
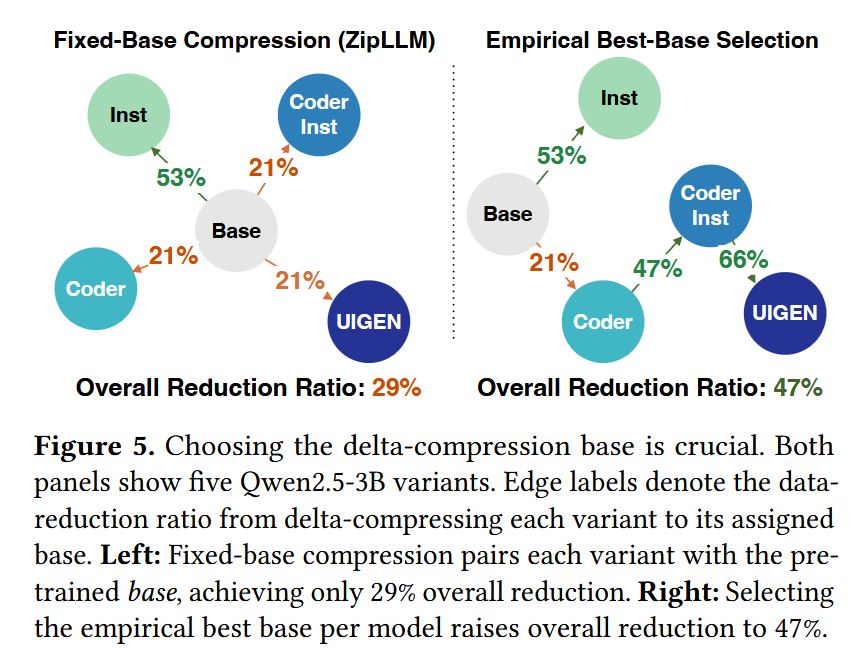
TensorHub decomposes models into tensors, predicts tensor-pairwise compressibility using compact bit-level fingerprints that capture tensor content, and incrementally organizes tensors into multi-center clusters that adapt as new models arrive.
1
2
6
585
Apr 21
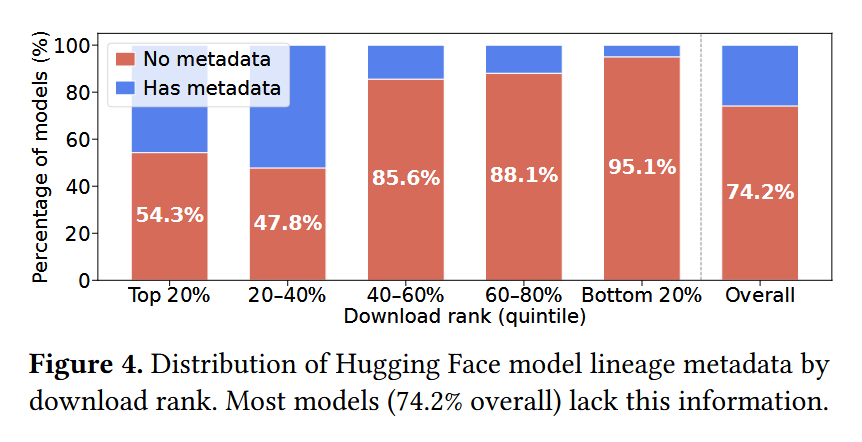
In this paper is presented TensorHub, a tensor-centric storage system that rethinks model storage compression by treating tensors as the first-class citizen for delta compression.
arxiv.org/pdf/2604.17104
1
5
24
1,633


Apr 13
Training large-scale RL has 3 clear goals: longer, faster, and more stable. That's why we built TensorHub.
- Ultra-fast RDMA performance
- Elasticity and fault tolerance
- Just 4 core APIs
High performance without sacrificing resilience.
Give it a try.

4
13
101
20,761

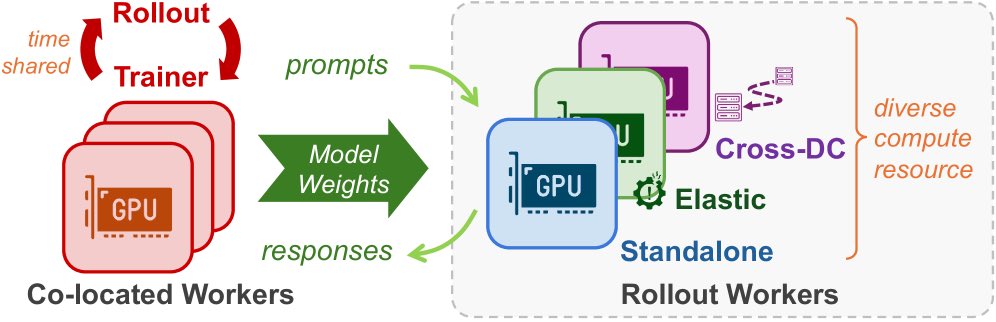
TENSORHUB: SCALABLE AND ELASTIC WEIGHT TRANSFER FOR LLM RL TRAINING
This paper is about fixing the storage vs transfer tradeoff in RL weight sync. NCCL gives you throughput, but it struggles with dynamic membership. UCX gives you flexibility, but fan-out turns the sender into the bottleneck. Storage gives you decoupling, but push-then-pull is the wrong shape once weights are huge. TensorHub’s move is to stop treating storage as something that has to own bytes. Instead of copying weights into a storage layer, it treats already-replicated live weights on GPUs as the storage substrate and serves reads from those replicas directly.
Core
Use live replicated weights as the storage layer:
- no explicit ownership of weight data
- no extra stored copies in the common case
- direct GPU-to-GPU reads
- storage-style decoupling between trainers and rollouts
- centralized scheduling with decentralized transfer
What it is
The core abstraction is Reference-Oriented Storage (ROS). ROS makes a weight version look stored and fetchable, but it never materializes an owned copy unless it has to. It just tracks which workers already hold that immutable version and routes reads to them. TensorHub is the production system on top of that idea, adding topology-aware scheduling, consistency across model-parallel shards, and failure handling.
Why this is different
The difference is in the ownership model, not just the transfer speed.
- NCCL gets bandwidth, but static groups and global coordination make it fragile under churn
- UCX avoids collectives, but sender-side uplinks collapse under fan-out
- storage systems decouple cleanly, but they pay for that abstraction with extra movement and extra memory
TensorHub is trying to keep the storage interface without paying the normal storage tax.
Key mechanisms
To make that work, they need a few systems pieces:
- a mutability contract so a worker can reuse buffers without corrupting concurrent reads
- a retention protocol so required versions do not disappear when the last live replica is about to go away
- topology-aware source selection at the server
- pipelined replication so partially updated replicas can immediately start serving downstream reads
- transactional consistency for model-parallel groups
- failure recovery across replica churn, spot loss, and server failover
Results
The numbers are strong and pretty practical:
- up to 6.7× lower total GPU stall time for standalone rollouts vs NCCL
- 4.8× faster weight update for elastic rollout vs UCX
- 19× lower GPU stall time for cross-datacenter rollout
- 50 GB shard transfer in 2.2s at 22 GB/s, about 88% of theoretical RDMA bandwidth
- Ray object store takes about 32s for a 40 GB transfer where GPU-direct RDMA takes about 0.2s
The important systems point is that they recover most of the decoupling benefits people want from storage, but without turning every weight update into push to storage then pull from storage. Once weights are already replicated for inference, copying them again into an ownership-based storage path is mostly self-inflicted overhead.
1
9
558

Mar 2
【ビーチで自撮りする青年Part1】
[Young man taking a selfie on the beach Part 1]
#AIイラスト #AIイケメン部 #AIイラスト好きと繋がりたい #AIart #tensorhub #ゲイ
#AIillustration #AIhandsomeClub #IwantToConnectWithPeopleWhoLikeAIillustrations #AIart #tensorhub #gay

14
842

Mar 1
Eh estado creando imágenes con ia de mi fursona y casi son NSFW pero de los 2 sitios ya quieren que pague para crear las versiones NSFW y solo no hago denuncias a PROFECO por no respetar la moneda MX y aun cambiando la región y salga USD (CIVITAI & TENSORHUB) De por si es caro.

1
25
383
Feb 28
【銀髪くんにつられて勃ってしまう黒髪くん】
#AIイラスト #AIイケメン部 #AIイラスト好きと繋がりたい #AIart #tensorhub #ゲイ
#AIillustration #AIhandsomeClub #IwantToConnectWithPeopleWhoLikeAIillustrations #AIart #tensorhub #gay

19
724

𝗠𝗲𝗶𝘁𝗬 𝗦𝗲𝗰𝗿𝗲𝘁𝗮𝗿𝘆 𝗜𝗻𝘁𝗲𝗿𝗮𝗰𝘁𝘀 𝘄𝗶𝘁𝗵 𝗧𝗡 𝗦𝘁𝗮𝗿𝘁𝘂𝗽𝘀
𝗶𝗧𝗡𝗧 𝗛𝘂𝗯 @ 𝗜𝗻𝗱𝗶𝗮 𝗔𝗜 𝗜𝗺𝗽𝗮𝗰𝘁 𝗦𝘂𝗺𝗺𝗶𝘁 𝟮𝟬𝟮𝟲
Thiru. S Krishnan, I.A.S., Secretary to Government of India, Ministry of Electronics and Information Technology (MeitY), graced the Tamil Nadu AI Pavilion and interacted with founders of iTNT Hub portfolio startups at the India AI Impact Summit 2026. The secretary had a hands-on experience of their innovative products, understood their solutions and gave valuable input for scaling.
iTNT Hub with its pride of 10 AI startups is participating at the week-long international summit at Bharat Mandapam, Pragati Maidan, New Delhi, till 21st February 2026, showcasing their cutting-edge solutions across #Healthcare, #SportsTech, Analytics, Enterprise AI, and other Deep & Emerging tech sectors demonstrating how applied AI is driving real-world impact.
Meet our Startups at 𝘁𝗵𝗲 𝗧𝗮𝗺𝗶𝗹 𝗡𝗮𝗱𝘂 𝗔𝗜 𝗣𝗮𝘃𝗶𝗹𝗶𝗼𝗻:
1. Diagno Intelligent Systems Private Limited
2. Exomudra Technologies Pvt Ltd
3. HealTether Health Services Private Limited
4. SCERMLIND Healthcare Innovations Pvt Ltd (ATIUM Sports)
5. White AI Analytics Pvt Ltd
6. Kenesis Labs Pvt Ltd
7. LEVELITSPORTS Technologies Pvt Ltd
8. Nodlehs AI 256 Pvt Ltd
9. truConsent
10. TensorHub Technologies Private Limited
#DeepTech #EmergingTech #Innovation #Technology #TamilNadu #Startups #InnovateInTN #BuildTheFuture #IndiaInnovation #BuildTheFuture



3
92
𝗶𝗧𝗡𝗧 𝗛𝘂𝗯 @ 𝗜𝗻𝗱𝗶𝗮 𝗔𝗜 𝗜𝗺𝗽𝗮𝗰𝘁 𝗦𝘂𝗺𝗺𝗶𝘁 𝟮𝟬𝟮𝟲
iTNT Hub and its pride of 10 AI startups is at the India AI Impact Summit 2026 at Hall No. 4, Tamil Nadu AI Pavilion, Bharat Mandapam, Pragati Maidan, New Delhi, till 21st February 2026. If you are an investor, corporate, ecosystem partner, or innovator exploring AI-led solutions, we invite you to visit the iTNT Hub Pavilion and connect directly with our startups.
Our Portfolio Startups are presenting cutting-edge solutions across #Healthcare, #SportsTech, Analytics, Enterprise AI, and other Deep & Emerging tech sectors demonstrating how applied AI is driving real-world impact.
During the Summit, Thiru. Brajendra Navnit, IAS, Principal Secretary, IT & DS Department, along with Ms. Vanitha Venugopal, CEO, iTNT Hub visited the Pavilion and interacted with the exhibiting startups.
𝗠𝗲𝗲𝘁 𝘁𝗵𝗲 𝗶𝗧𝗡𝗧 𝗛𝘂𝗯 𝗦𝘁𝗮𝗿𝘁𝘂𝗽𝘀 𝗮𝘁 𝘁𝗵𝗲 𝗧𝗮𝗺𝗶𝗹 𝗡𝗮𝗱𝘂 𝗔𝗜 𝗣𝗮𝘃𝗶𝗹𝗶𝗼𝗻:
1. Diagno Intelligent Systems Private Limited
2. Exomudra Technologies Pvt Ltd
3. HealTether Healthcare Services Private Limited
4. SCERMLIND Healthcare Innovations Pvt Ltd (ATIUM Sports)
5. White AI Analytics Pvt Ltd
6. Kenesis Labs Pvt Ltd
7. LEVELITSPORTS Technologies Pvt Ltd
8. Nodlehs AI 256 Pvt Ltd
9. Tangled Threads Technologies Private Limited
10. TensorHub Technologies Private Limited
𝗠𝗮𝗿𝗸 𝗬𝗼𝘂𝗿 𝗖𝗮𝗹𝗲𝗻𝗱𝗮𝗿
🗓️Till 21st February 2026
📍Hall No. 4, Tamil Nadu AI Pavilion, Bharat Mandapam, Pragati Maidan, New Delhi
#DeepTech #EmergingTech #Innovation #Technology #TamilNadu #Startups #InnovateInTN #BuildTheFuture #IndiaInnovation #BuildTheFuture



3
92
