

Jun 12
Collaboration drives innovation. Kevin Robinson, President & CEO of Wi-Fi Alliance, joins leaders from @csaiot, @BluetoothSIG, and @ThreadGroup at #UNIFY to discuss the future of secure, interoperable, and globally connected IoT experiences.
csa-iot.org/unify/

1
1
123


We're proud to see Tom Sciorilli representing #Inventures client, @TheThreadGroup, at #Unify2026!
As a certification expert, Tom help clients develop and manage certification programs that drive interoperability, quality, and industry adoption.
@csaiot #ThreadGroup #IoT

Coming to #Unify2026? Don't miss our VP of Certification, Tom Sciorilli, talk all things certification and the path to interoperability and market readiness!
It's not too late to register: csa-iot.org/unify/
#ThreadGroup #ThreadCertification #IoT #BuiltOnThread @csaiot

2
3
595

May 31
局所的なAgentig レンダリング最適化のレポートはこのような形
- try01: Wave集約Atomicへ置換(同一書き込み先をWave内で統合して代表laneのみInterlockedOr)→ 0.063447
ms(baseline比 54.90%)
- try02: world offset計算をview-space化(変換回数削減)→ 0.0592153 ms(51.24%)
- try03: Perspective向け再構築の高速化案を追加 → 0.0614399 ms(53.16%、悪化寄りで不採用)
- try04: 正規化をrsqrtベースにして分岐削減 → 0.0588845 ms(50.95%)
- try05: try04系コードを再計測(分散確認)→ 0.0585595 ms(50.67%)
- try06: ballot補助処理を簡略化 → 0.0603319 ms(52.20%、不採用)
- try07: near-plane view_zをCPU前計算してCB渡し → 0.0586666 ms(50.76%)
- try08: threadgroupを16x16→8x8へ調整(Wave集約方式と相性改善)→ 0.0571343 ms(49.44%、目標達成)

2
534

[483751167][reward: $16000] WebGPU (Dawn/Tint Metal) SubstituteOverrides integer overflow causes threadgroup OOB read/write
crbug.com/483751167
1
9
760

May 12
Join us in Austin for @csaiot's Unify Event! As a sponsor, #ThreadGroup has a lot planned:
Stop by our booth, hear from our president, & don’t miss our session: “Why Thread, Why Now: Designing the Future of IoT."
Register here: account.canapii.com/events/u…
#CSAUnify #SmartHome

1
2
446
Spotlighting #ThreadCertified Product from @GLiNetWiFi, the All-in-One Wireless Human Presence Sensor!
Learn more about these #BuiltOnThread products here: threadgroup.org/Certified-Pr…
#ThreadGroup #GLiNet #SmartHomeDevices #IoT

1
5
398

Apr 27
Agility SDK 1.720-preview has been released with Linear Algebra Matrix support which replaces Cooperative Vectors and WaveMMA for hardware accelerated matrix operations, access to wave threadgroup index, and increased groupshared memory among others.
devblogs.microsoft.com/direc…
1
5
24
2,299

Apr 27
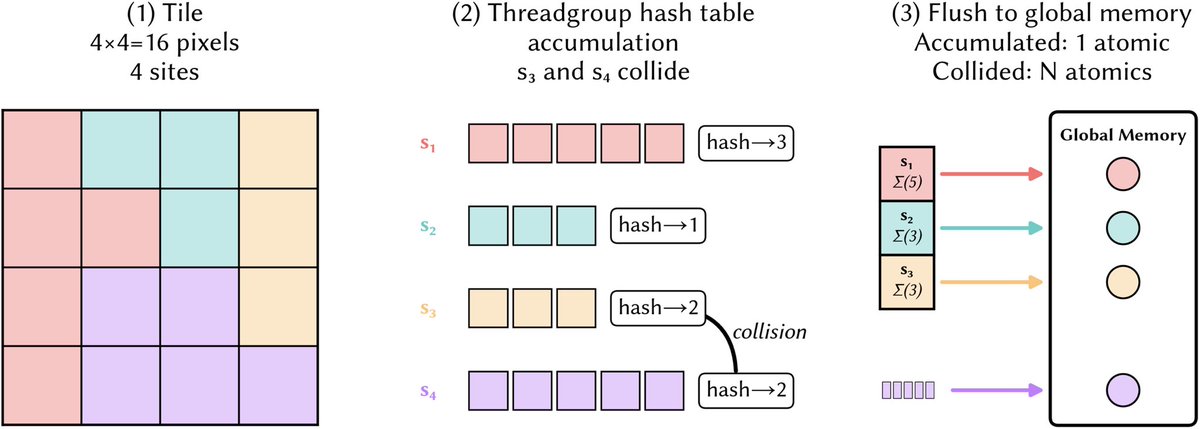
To make this architecture viable, we designed two algorithms: temporal top-k for encoding amortization and threadgroup hashing for efficient gradient accumulation

1
7
818
Apr 27
That's a wrap! Another successful #ThreadGroup #MembersMeeting has come to a close. Thank you to all who joined and participated in the sessions this past week. See you in October!
To learn more about #ThreadGroupMembership, visit threadgroup.org/thread-group…
#IoT #Thread

1
3
338

Apr 21
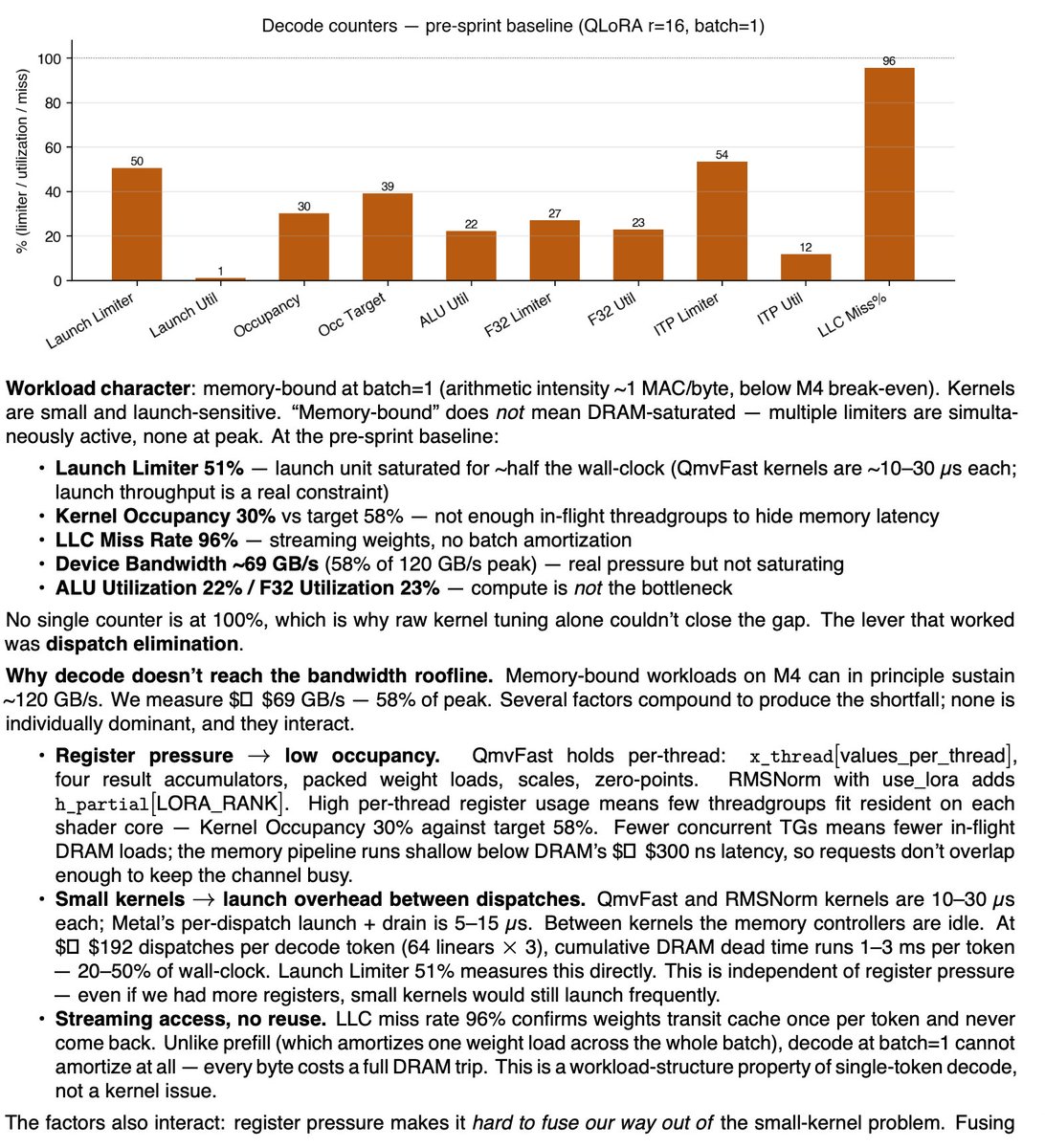
A very counterintuitive thing I recently learned is that LoRA adapters are quite inefficient for batch-size 1 inference, especially on Apple GPUs which don't have cross-threadgroup barriers and you can't do fancy megakernel-style fusion
(This is from our internal document)


3
2
32
3,232
Apr 13
One week left until our Spring #MembersMeeting in Vienna, Austria! Haven't had a chance to sign up? It's not too late! Join us for o a deep dive into the world of #IoT! See the link below to learn more about our member benefits.
threadgroup.org/thread-group…
#ThreadGroup #SmartHome

2
314

클로드와 같이 분석한 결과 이런 결론을 냈습니다.
"Gemma 4 26B의 128-expert MoE gather_mm 디스패치가 base M4 칩(10 GPU 코어)에서 비정상 동작한다.
Gemma4 MoE는 mlx_lm.SwitchGLU mx.gather_mm을 사용하여 128개 expert 중 top-8을 선택하여 연산한다.
이 연산의 Metal 커널이 GPU 코어 수에 따라 다른 threadgroup/SIMD 디스패치 경로를 탈 수 있으며, 10코어 GPU에서 정확도 문제가 발생하는 것으로 추정된다."
1
1
34
4,447
Spotlighting #ThreadCertified Product from @Yeelight, Pro Smart Home Hub!
Learn more about these #BuiltOnThread products here: threadgroup.org/Certified-Pr…
#ThreadGroup #Yeelight #SmartHomeDevices #IoT

2
4
497

Apr 8
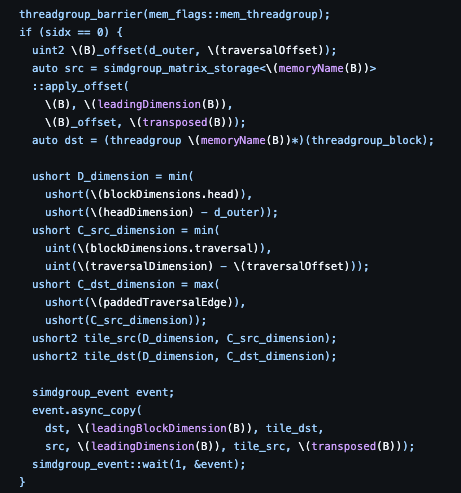
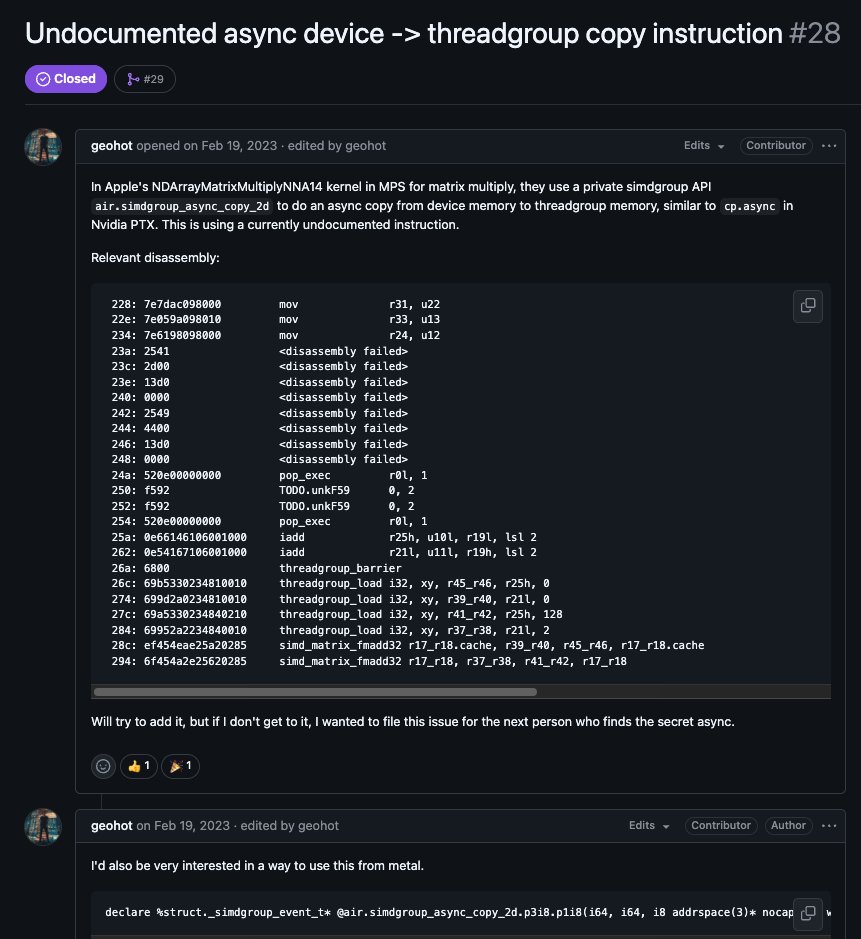
@Apple never publicly released async device→threadgroup copies for user kernels leaving a lot of performance on the table. But it leaked briefly in Xcode 14.2 as simdgroup_event::async_copy, then got pulled before 14.3.
So with the help of claude, I tried to reverse engineer Apple's private Metal async copy API hiding inside MPSMatrix.framework on my M4 Mac.
Turns out Apple evolved the API internally. Running strings c filt on the MPS metallib reveals the current private signature -
metal::simdgroup_future<void>
metal::simdgroup_async_copy<float, void>(
float threadgroup* dst,
ulong, ulong, ulong2, // dst stride tile
float const device* src,
ulong, ulong, ulong2, // src stride tile
long2, // offset
metal::simdgroup_async_copy_clamp_mode
)
Instantiated for float, half, short, signed char.
The AIR intrinsics confirm it's real:
air.simdgroup_async_copy_2d.p3i8.p1i8
air.wait_simdgroup_events
Your M4 can do it. MPS does it. You can't.
3
12
564

It's not too late to register for Thread Group's semi-annual Members Meeting on April 21-23! Hear more from our committees while doing a deep dive into the world of IoT! See the link below to learn more about our member benefits.
threadgroup.org/thread-group…
#ThreadGroup #IoT

2
322
Apr 5
Have been learning metal shaders this weekend and implemented histogram based topk, same idea by @AlpinDale
Metal has some very similar ideas to CUDA like SIMD groups (warps in cuda) or threadgroup mem (shared space in cuda), the idea for topk here is simple -
Bit every value, do a prefix sum, find threshold which is O(1), collect and sort the remaining,
Now since we can't use CUB sort here, I implemented bitonic sort on the threshold buffer and the results looks good, more kernels maybe incoming including megakernels for qwen but I need to get familiar more with sdpa and matmul optims. I will also be working on compute and render shaders for simulations in future.

1
21
1,364