Calmsy retweeted

$1.4B onchain.
Tokenized credit is the fastest growing RWA segment
@maplefinance is the #1 tokenizer of credit.

RWA Tokenized Credit - League Table
The top 10 platforms by total value onchain:
@maplefinance - $1.4B
@stokr_io - $1.3B
@centrifuge - $736.1M
@Securitize - $486.6M
@HastraFi - $405.7M
@chainlink CCIP - $241.8M
@AssetoFinance - $205.7M
@onrefinance - $185.4M
@paretocredit - $180.8M
@MidasRWA - $104.8M
Tokenized credit is becoming one of the biggest categories in RWA.
3
1
6
310

*There is no such thing as a tokenizer-free lunch*
by @linguist_cat
Nice summary of recent "tokenizer-free" LLMs and why that might be a misnomer.
huggingface.co/blog/catherin…

1
3
145


PHP 本体の AST や Tokenizer をそのまま使うことで高速かつ忠実な LSP を作成する LSParrot というものを作っています
pie install lsparrot/lsparrot で入り、 VSCode Extension があります
marketplace.visualstudio.com…
github.com/LSParrot/ext-lspa…
1
3
293

これは全文検索、ベクトル検索、グラフデータベース、そして時系列を考慮した統合検索エンジンのようなものになっているので、日本語で使う時は少なくともtokenizer, reranker, embedding を日本語対応のものに差し替えて使う必要があります。デフォルトだと日本語がランキング上位に出ません。
10

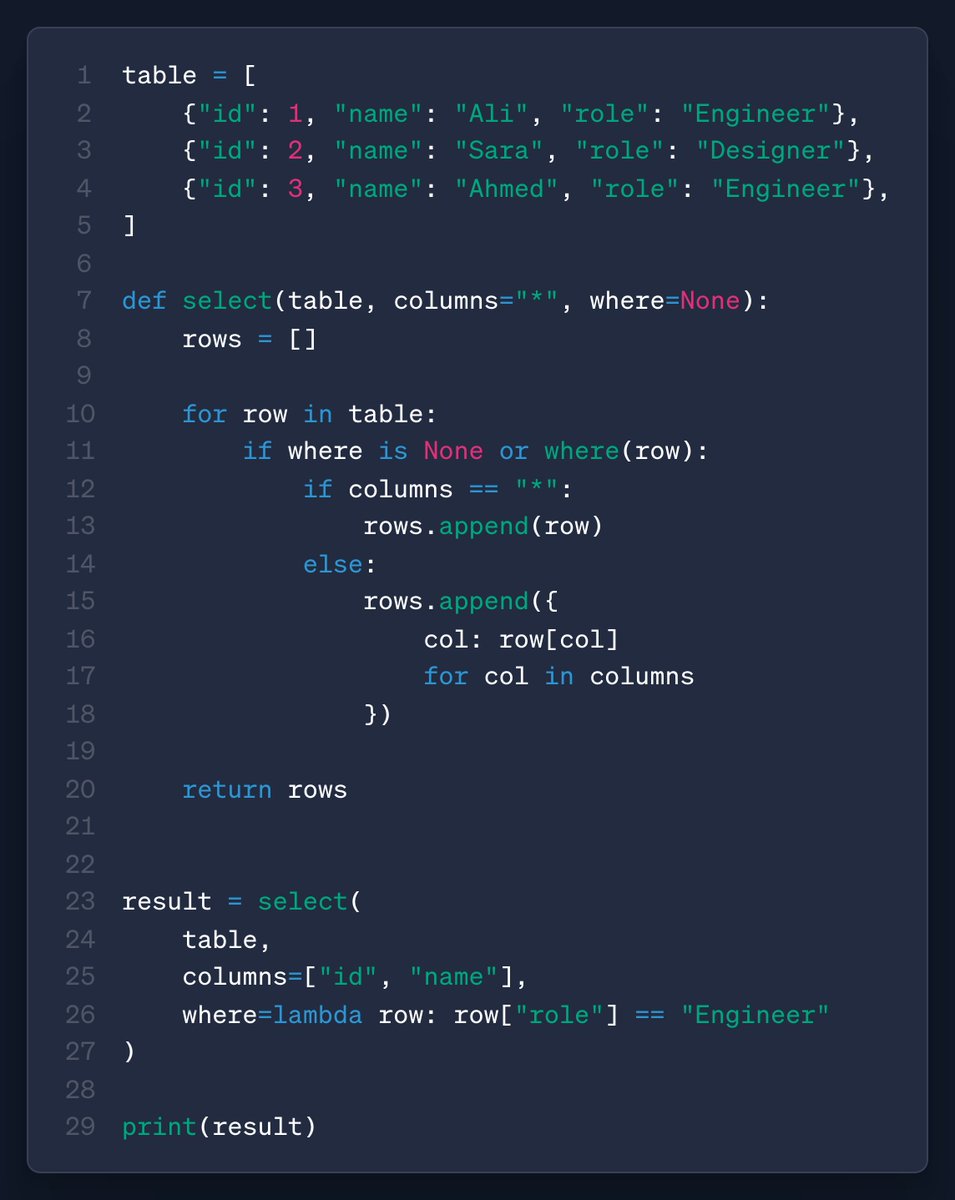
SQL Engine from first principles.
At its core, it does 4 simple things:
1. table: a set of rows with columns
2. select: choose which columns to return
3. where: restrict the rows returned by adding conditions
4. Return the result
SQL Query --> Tokenizer --> Parser --> Planner --> Executor --> Rows
The engine scans rows, checks the condition, fetches requested columns, and returns matching records.
Production SQL engines add:
- parser
- optimizer
- indexes
- joins
- transactions
- storage engine
- query planner
- concurrency control
But the first principle remains the same.
14

Sometimes you just don't need a tokenizer. This estimate is surprisingly good

5

⚔️ AI wars are heating up.
🧠 Anthropic launched Claude Opus 4.7, now topping coding benchmarks and handling much larger images—but a new tokenizer may increase token usage by up to 35%.
🤖 OpenAI responded with a major Codex upgrade, turning it into an autonomous agent workstation with computer use, browser access, multi-day automations, and 90 enterprise integrations.
The race is no longer about chatbots—it's about building the best AI coworker.
Which ecosystem are you betting on: Anthropic or OpenAI?
hashtag#AI hashtag#ArtificialIntelligence hashtag#TechTrends
Reference article:
lnkd.in/gCTgGa7i

31

┌─────────────────────────┬───────────────────────────────────┬────────────────────────────────────────────────────────┐
│ │ │ Recent Activity │
│ │ Welcome back, Meaghan! │ 1m ago Updated tokenizer (mistral-common) │
│ /inference │ │ 8m ago Refactored safety filters │
│ /finetune │ (ฅ•ω•ฅ) │ 2d ago New inference task added to memory │
│ /help for commands │ │ 1w ago Benchmarks for large context updated │
│ │ Le Gros Chaton ├────────────────────────────────────────────────────────┤
│ │ │ What's New │
│ │ │ /finetune for custom datasets │
│ │ │ ctrl s to search history │
│ │ │ Updated context handling │
└─────────────────────────┴───────────────────────────────────┴────────────────────────────────────────────────────────┘
>mistral@Sandman:~$
█ Le Gros Chaton (32K context with extra fluff) | meaghan ──────────────────────────────────────────────────────────────
© Mistral AI | blaze speed • /effort milestone complete | fine-tuning progress [█████████░░░░░░░░] 42% 🐾
1
2
202

The range is so wide as results depend on a tokenizer and JSON type and there are a lot of possible combinations.
I've also used a benchmark that consists of only 35 examples of multiple kinds of JSON data. Right now I'm building the better benchmark and I'll publish it tonight.
As for the json structured outputs, we're just changing the encoding and RAIF round-trips losslessly back to json
There's only a problem that existing integrations and harnesses don't speak RAIF. I'm working on making sort of vLLM plugin or something similar to use it as a middleware that converts RAIF to JSON at the serving layer so harnesses won't need tuning.
Our LoRA completely changes json output to RAIF, so the benchmark shows relevant metrics excluding prose json markings and other stuff that happen.
12

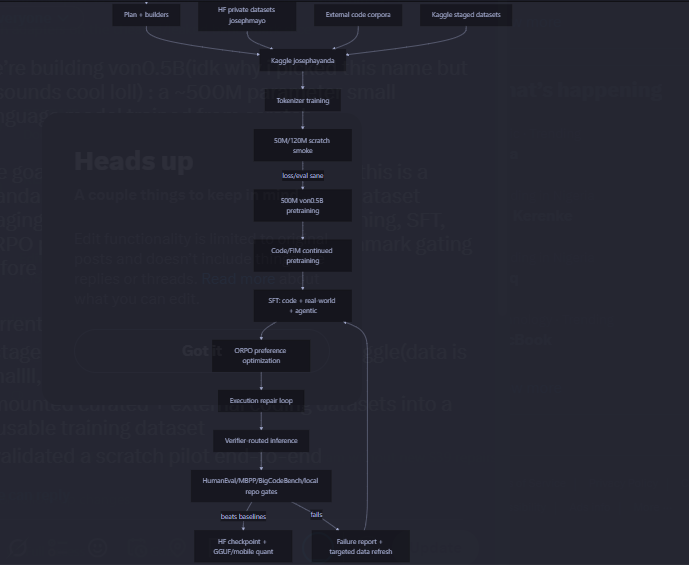
we’re building von0.5B(idk why i picked this name but it sounds cool loll) : a ~500M parameter small language model trained from scratch.
the goal is not just another LoRA adapter. this is a standalone small coding model pipeline: dataset staging, tokenizer training, scratch pretraining, SFT, ORPO preference optimization, and benchmark gating before any performance claims.
current progress:
- staged an 80k-row coding mixture on Kaggle(data is smallll, gathering more hopefully)
- mounted curated external coding datasets into a reusable training dataset
- validated a scratch pilot end-to-end
- launched the full von500m pretraining run on Kaggle 2xt4 using the staged mixture
the focus is high coding performance per parameter, with edge/phone usability as a secondary deployment target.
no outputs yet but im "building in public"
why?: i needed to be able to run models on my phone but current ones due to heavy quantizations keep outputting garbage.
and then i thought to build one myself from scratch, definitely not an easy task but a good one
1
1
1
55

rt machine 🇺🇦 retweeted

21h
"you have watched Karpathy building a GPT tokenizer on YouTube after 8pm, have you not? You have watched it on your iPad, haven't you?"

Jun 14

🚨 NEW: Keir Starmer will introduce nightly social media curfews for 16 and 17-year-olds as part of the Government's social media ban
[@thetimes]
1
6
77
1,815

@superactro 67 TOPS at 7-15W is a solid benchmark for the Orin Nano. The real unlock for edge AI isn't just the inference speed — it's being able to run the full perception pipeline (tokenizer model post-processing) inside a thermal envelope that survives a factory floor. Have you tested sustained inference with ClawBox under 24/7 thermal cycling? Would be curious about your quantization strategy for 7B models on that power budget.
8

If you build with or evaluate LLMs, my new post is for you.
Tokenization sounds like a boring preprocessing detail. In practice it decides what a model can do, how much it costs to run, and why it fails on tasks you'd expect it to handle.
The post covers, with code and real numbers:
→ Why vocabulary size is a real design decision (32K → 128K → 256K)
→ How much of a model is just the embedding table (31% of GPT-2, ~7% of a 7B)
→ Weight tying: which models share the embedding and LM head, and which don't
→ Why multilingual cost varies so much per language
→ Why you can't swap a tokenizer without retraining from scratch
There's a companion Kaggle notebook so you can check every number yourself.
Part 3 of my genAI Fundamentals series.
Link: buff.ly/Zm5udFW
36

really?
thought i saw the qwen tokenizer back then
gonna check again
19

llama.cpp b9637 added a dedicated Cohere2MoE / North Code chat parser. This is the unglamorous part of local model support: the runtime absorbs tokenizer and chat-template quirks so users are not debugging prompt formats by hand.
6

11h
midwest liberals find out i’m latina and try to tokenize me but unfortunately for them i had already tokenized them first. you can’t tokenize the tokenizer. science.
17

Surface-Form Neural Sparse Retrieval: Robust Fuzzy Matching for Industrial Music Search
Amazon presents an inference-free sparse retrieval system for music search that uses a granular subword tokenizer to robustly match misspelled and varied queries.
📝 amazon.science/publications/…
3
252