Ranked 1.0 had this, Ranked 2.0 purposefully hid it, and Rank 3.0 is bringing it back. When the op says "ranked 3 is working" and you say there's not enough data I would claim there is - it working means a return to a tied visual rank system that runs purely off TrueSkill.
1
42

Seigmeyer Fan account retweeted

When I was 12 I would be calling you a gook on Halo 2 with a 40 trueskill.
2
9
466

Jun 10
I don't know the specifics. I know for example duo Q was not enabled on KR but was on EUW. There are possible more differences. Because Riot usually rolls out things differently. For example they have been testing TrueSkill on NA normals for a while. But normals elsewhere not.
44

Jun 10
TOs: you can upload your replays here luckystats.gg/?tab=replays - no more paying for Google Drive. We will host your replays for you and uploading .slp files will always be free.
Coming soon:
1. Convert any set or tournament to an mp4, uploaded to your scene's Youtube channel
2. Advanced replay search analytics and discovery
3. Region Admin pages. Publish your PR, choose your season windows, add players to your region, select your ranking system (TrueSkill, Elo, etc), ingest from Challonge etc.
While in beta, replay viewing will continue to be free. We will be building out premium features to improve the experience and help offset the storage / compute costs. Details to come 🙏🙏
1
9
104
37,389

Jun 10
次のランクマレート増減解析ではGlicko2モデルとTrueSkillモデルで昇格ボーナスの説明を試みる予定
会社でコード書いてる悪い社員ですわ
1
96
Jun 10
TrueSkillを仮定すれば昇格ボーナスや思ったより大きいレート増減も説明できる気がしてきたぞ!
だが問題はユーザにはσが開示されてない事だ!
潜在変数にするにも限界あるだろ!!!
1
119

Jun 8
Aggregating 200 benchmarks into a single TrueSkill rating is useful until the top models are all within noise margin of each other on your actual task.
The real benchmark is always the one you ran on your own data last week.

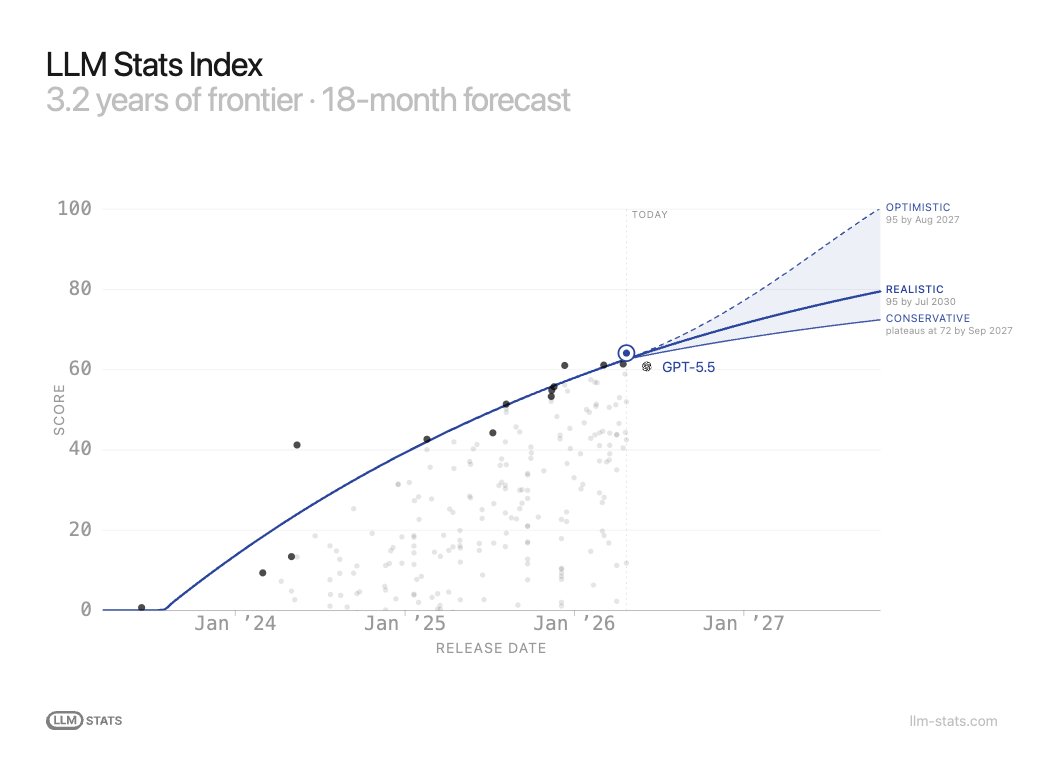
Today we're introducing the LLM Stats Index.
For 3.2 years, we've tracked every frontier model release. The Index aggregates 200 benchmark results into a single TrueSkill rating per model, spanning law, healthcare, coding, tool calling, vision, and reasoning.
Across every category and every modality, the leading model on the Pareto Frontier is GPT-5.5 (@OpenAI).
On our trajectories, human-knowledge benchmarks saturate by mid-2027.
Capability has been the primary axis. The field is converging on it. Two more are opening.
The first is efficiency: total task cost is the cleanest proxy we have for intelligence/watt. The second is throughput: inference speed becomes the productivity ceiling once models are cheap and good enough.
We're building the next generation of long-horizon coding, tool use, and long context benchmarks.
If you're working on long-horizon evaluation in real domains, we'd like to chat.
15

Jun 6
The TrueSkill 2 SBMM Menke matchmaking is the true reason some people were fooled into thinking the gameplay was competitive. They were just simply forced into always playing sweaty games and conflated the two things.
1
5
92

Jun 1
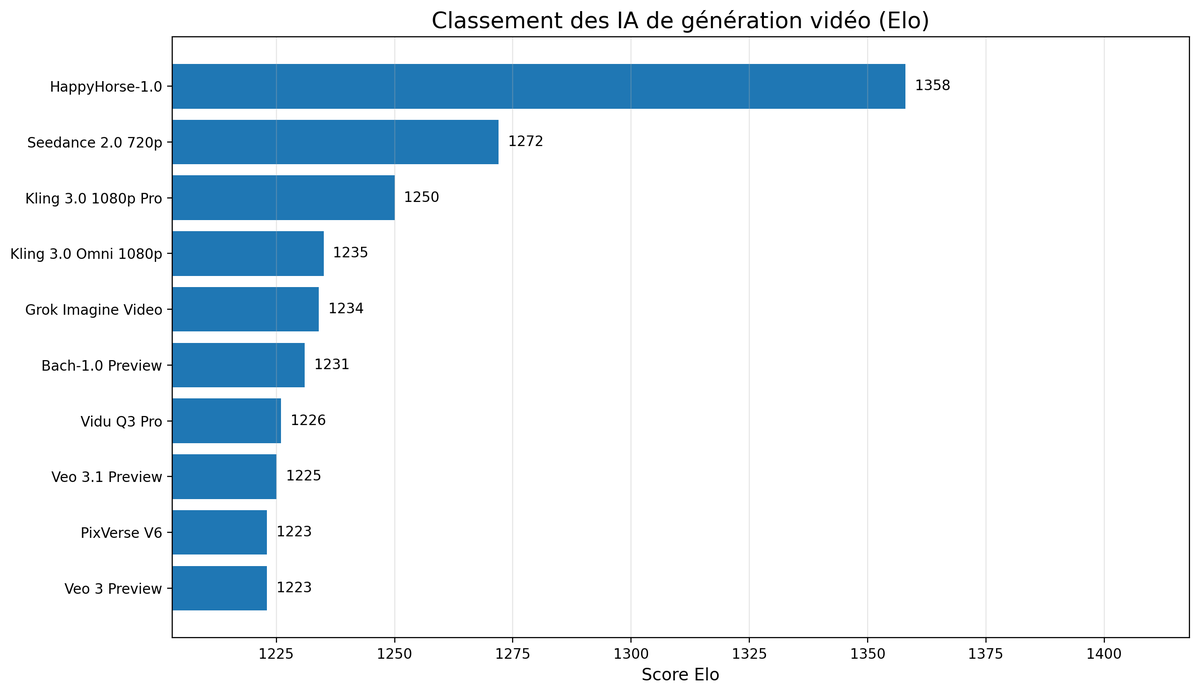
🎬 AI Video Leaderboard May 2026
Top 10 (Artificial Analysis Elo, blind human votes)
🥇 HappyHorse-1.0 — 1358
🥈 Seedance 2.0 — 1272
🥉 Kling 3.0 Pro — 1250
4️⃣ Kling 3.0 Omni — 1235
5️⃣ Grok Imagine Video — 1234
6️⃣ Bach-1.0 Preview — 1231
7️⃣ Vidu Q3 Pro — 1226
8️⃣ Veo 3.1 — 1225
9️⃣ Veo 3 — 1223
🔟 PixVerse V6 — 1223
Based on Artificial Analysis Elo scores (video) & LLM Stats TrueSkill (image)
Snapshot of May 2026 rankings update live
Source: artificialanalysis.ai / llm-stats.com
1
6
440

May 30
bad matchmaking=> more volatile games => less solo agency in individual games => takes more games to climb
ofc good players will always reach their elo, but holy I dont have time to play 10 games a day to climb, bring trueskill or sth
4
28
2,495

PopuLoRA extends self-play using populations of teachers and students with TrueSkill-weighted cross-evaluation. This creates a more general framework where open-ended co-evolutionary learning dynamics can emerge naturally.
1
2
23
1,430

May 20
A few hundred lines of code. No pretraining. No language. No "reasoning." Just structured state tracking, cash estimates, simple bidding rules.
Across 242 games, it outranked 6 of 7 cost-efficient LLMs on TrueSkill. It doesn't forget who has money or what it's bidding against.
1
3
66