
Daha Az Hesapla Daha Güçlü Modeller: UltraData'nın Sundukları
OpenBMB’nin duyurduğu UltraData veri yığını güncellemesi yapay zeka modellerinin eğitiminde yeni bir yaklaşım sunuyor. Bu sistem MiniCPM5-1B modeli üzerinde test edilerek hazır hale getirildi. Bu yapı modelin hangi dönemde ne tür veriyle beslenmesi gerektiğini belirliyor. Böylece eğitim süreci daha planlı ve ekonomik bir hale geliyor. Güncellemeyle birlikte iki önemli veri seti kullanıma açıldı. Ultra-FineWeb-L3, yüksek yoğunluklu sentetik verilerle oluşturulmuş 600 milyar bilgi parçası içeren bir havuz.
Bu havuzun içinde hem Çince hem de İngilizce içerikler var. UltraData-SFT-2605 ise eğitim sonrası aşama için hazırlanmış 15 milyondan fazla örnekten oluşuyor. Bu veriler sayesinde modeller daha az hesaplama ve bellek kullanımıyla daha iyi akıl yürütme becerileri kazanıyor. Cihaz üreticileri bu açık kaynaklı yapıyı kullanarak kendi modellerini sıfırdan inşa etmek zorunda kalmadan güçlendirebilecekler. Baya bir sevilmiş diye biliyorum bende güzel gelişme olduğu için paylaşayım dedim reklam değildir.

🚀 MASSIVE upgrades for UltraData data stack! The tiered data management (L0-L4) framework has now fully battle-tested on MiniCPM5-1B and is ready for your models! No gatekeeping, just pure data power.
What’s NEW in our latest release:👇
✅ Ultra-FineWeb-L3 — 600B tokens (200B Chinese, 400B English) of high-density synthetic pre-training data, which expanded from Ultra-FineWeb via multi-style rewriting & QA generation, and has used in MiniCPM5-1B's decay stage.
🤗 huggingface.co/datasets/open…
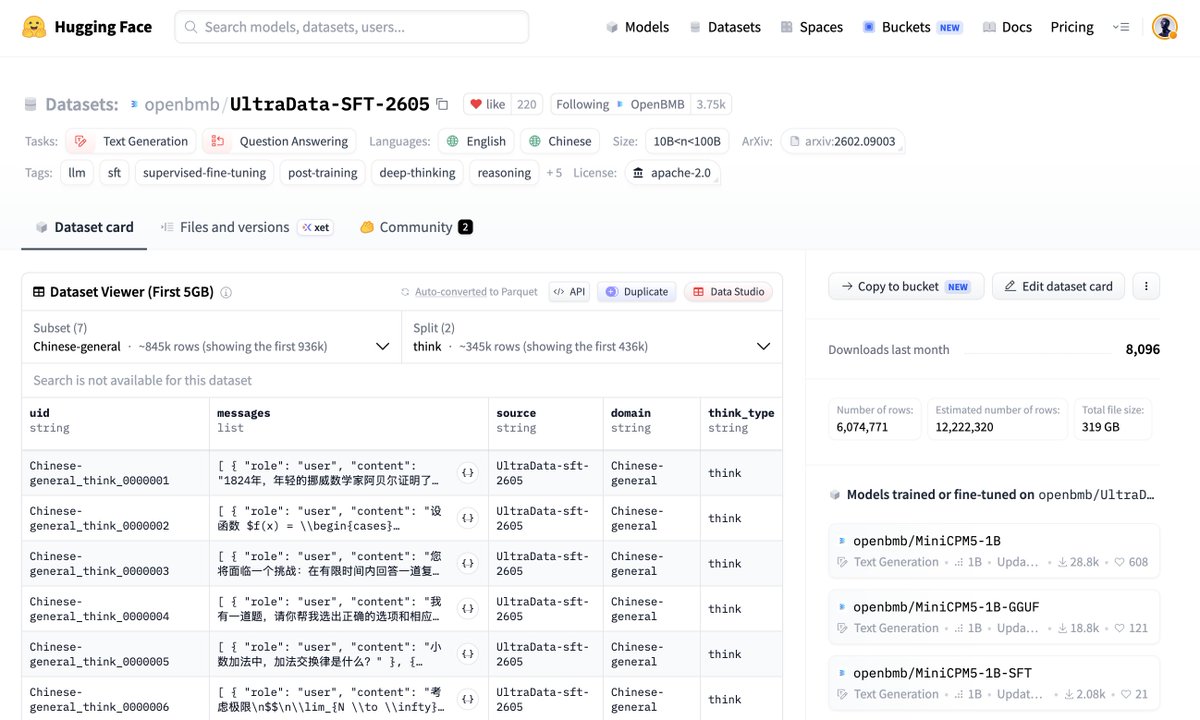
✅ UltraData-SFT-2605 — 15M post-training samples across math, code, knowledge & instruction following, with deep-thinking and non-thinking training styles, used in MiniCPM5-1B's SFT stage.
🤗 huggingface.co/datasets/open…

1
12
1,389

【LLMの思考力を爆上げ!超高品質SFTデータ「UltraData-SFT-2605」公開】
👉 x.com/AdinaYakup/status/2060…
軽量で超高性能な「MiniCPM5-1B-SFT」の裏側を支える、1500万件超のコアデータセットが無償公開されました!🚀
💡注目のポイント
・「Deep Thinking」思考プロセスを含む1500万件超のサンプル
・ベンチマーク除染を徹底した最高峰クオリティ「L3 refined data」
・軽量モデルでも驚くほど賢い「推論特化型AI」が自社で開発可能
ハイクオリティなデータを活用して、一歩先を行くAI開発に挑戦しましょう!
#生成AI #AI開発

1
9
1,050

319GB dataset SFT gratis!! 🤯
OpenBMB baru saja merilis UltraData-SFT-2605, dataset yang digunakan untuk melatih MiniCPM5-1B-SFT.
Dataset uda dipilah-pilah juga, ada yg versi think maupun non-think.
Daftar dataset:
- Matematika
- Pemrograman
- Pengetahuan Umum (mengajarkan fakta dan pemahaman dunia)
- Mengikuti Instruksi (mengajarkan cara mengikuti perintah user)
- Percakapan Umum (chinese)
- Matematika Multibahasa
- Pengetahuan Multibahasa
Totalnya lebih dari 15 juta sampel dengan ukuran sekitar 319GB.
Gunanya untuk apa?
- Fine-tuning model supaya kualitas lebih ok.
- Teacher dataset, digunakan untuk menghasilkan dataset lain.
Tapi bukankah model sekrg uda ok banget?
Benar. Namun model AI akan terus berganti.
Dataset berkualitas, dgn kurasi yang baik, dan distribusi tugas yang tepat sering kali lebih berharga dari model itu sendiri karena bisa untuk train model-model berikutnya.
1
6
18
1,057

May 30
One of the core ideas behind UltraData is that data quality requirements fundamentally change across different stages of training.
Pretraining, annealing, SFT, and RL all need different things.
Building a governance framework that explicitly maps quality levels to those stages feels like the correct architectural approach.
🚀 MASSIVE upgrades for UltraData data stack! The tiered data management (L0-L4) framework has now fully battle-tested on MiniCPM5-1B and is ready for your models! No gatekeeping, just pure data power.
What’s NEW in our latest release:👇
✅ Ultra-FineWeb-L3 — 600B tokens (200B Chinese, 400B English) of high-density synthetic pre-training data, which expanded from Ultra-FineWeb via multi-style rewriting & QA generation, and has used in MiniCPM5-1B's decay stage.
🤗 huggingface.co/datasets/open…
✅ UltraData-SFT-2605 — 15M post-training samples across math, code, knowledge & instruction following, with deep-thinking and non-thinking training styles, used in MiniCPM5-1B's SFT stage.
🤗 huggingface.co/datasets/open…
47
46
20,575

May 30
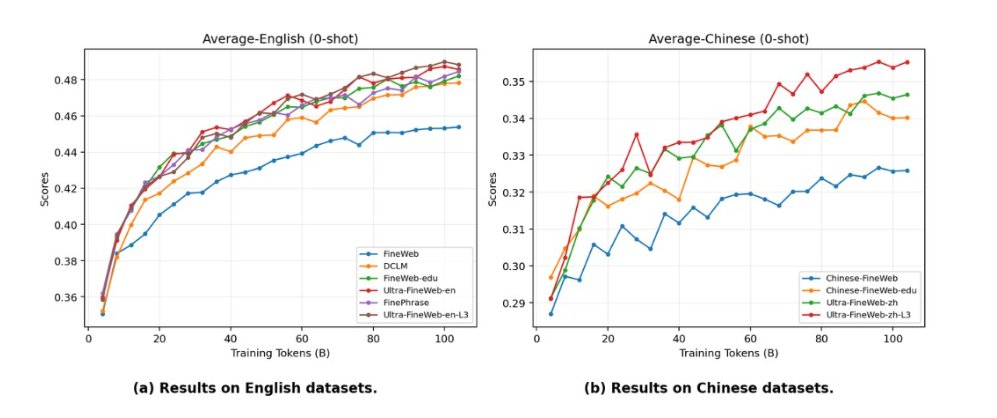
UltraData-Math-L3 outperforming Nemotron-CC, MegaMath, and FineMath across benchmarks like MATH500, GSM8K, and Math-Bench is a genuinely strong result.
The gain on MATH500 over Nemotron-CC 4plus is large enough that it really does look like the L3 refinement process is contributing meaningful improvements, rather than just overfitting benchmarks.
🚀 MASSIVE upgrades for UltraData data stack! The tiered data management (L0-L4) framework has now fully battle-tested on MiniCPM5-1B and is ready for your models! No gatekeeping, just pure data power.
What’s NEW in our latest release:👇
✅ Ultra-FineWeb-L3 — 600B tokens (200B Chinese, 400B English) of high-density synthetic pre-training data, which expanded from Ultra-FineWeb via multi-style rewriting & QA generation, and has used in MiniCPM5-1B's decay stage.
🤗 huggingface.co/datasets/open…
✅ UltraData-SFT-2605 — 15M post-training samples across math, code, knowledge & instruction following, with deep-thinking and non-thinking training styles, used in MiniCPM5-1B's SFT stage.
🤗 huggingface.co/datasets/open…
27
27
24,275

Mi conclusión es que UltraData no es “otro dataset más”.
Es una señal de hacia dónde va la IA open-source.
Menos obsesión por acumular datos, más foco en gobernarlos bien.
Quizá la próxima ventaja no esté en entrenar con más datos sino con datos que enseñan mejor.
¿Crees que la calidad del dato será la próxima gran batalla en IA?
ultradata.openbmb.cn
huggingface.co/collections/o…
1
5
8
3,202
Y UltraData-Math va todavía más al detalle.
En matemáticas no basta con extraer texto de una web. Hay fórmulas, pasos, razonamientos y estructura que se pueden romper fácilmente.
Por eso me parece interesante que el pipeline cuide desde el parsing hasta la generación de datos refinados.

1
4
6
2,319
Durante años hemos hablado de modelos más grandes, más GPUs y más tokens.
Pero UltraData apunta a otra dirección.
Convertir datos web caóticos en datos realmente útiles para entrenar modelos.
No es solo recopilar texto.
Es limpiarlo, filtrarlo, seleccionarlo y refinarlo para que el modelo aprenda mejor.
2
3
6
1,412
He estado revisando UltraData y me ha dejado una idea bastante clara.
La próxima gran ventaja en IA no será tener más datos.
Será tener datos que enseñen mejor.
Menos ruido.
Más señal.
Mejores modelos.

9
26
47
180,894

May 29
UltraData-Math-Parser is probably one of the easiest contributions here to overlook, but technically it matters a lot. If mathematical notation can’t be extracted correctly from web data, meaningful math-data refinement becomes almost impossible. The benchmark gains over trafilatura and magic-html suggest this is a real improvement rather than a tiny optimization.
🚀 MASSIVE upgrades for UltraData data stack! The tiered data management (L0-L4) framework has now fully battle-tested on MiniCPM5-1B and is ready for your models! No gatekeeping, just pure data power.
What’s NEW in our latest release:👇
✅ Ultra-FineWeb-L3 — 600B tokens (200B Chinese, 400B English) of high-density synthetic pre-training data, which expanded from Ultra-FineWeb via multi-style rewriting & QA generation, and has used in MiniCPM5-1B's decay stage.
🤗 huggingface.co/datasets/open…
✅ UltraData-SFT-2605 — 15M post-training samples across math, code, knowledge & instruction following, with deep-thinking and non-thinking training styles, used in MiniCPM5-1B's SFT stage.
🤗 huggingface.co/datasets/open…
39
40
11,297

May 29
OpenBMB just released an impressive SFT dataset
UltraData-SFT-2605 📊
✨ 15M high quality samples
✨ Deep Thinking Non-thinking data
✨ Math/ Code/ Knowledge/ IF/ Multilingual coverage
✨ Built for reasoning LLM post-training
✨ Full data pipeline: filtering/ validation/decontamination
3
21
141
7,801

May 29
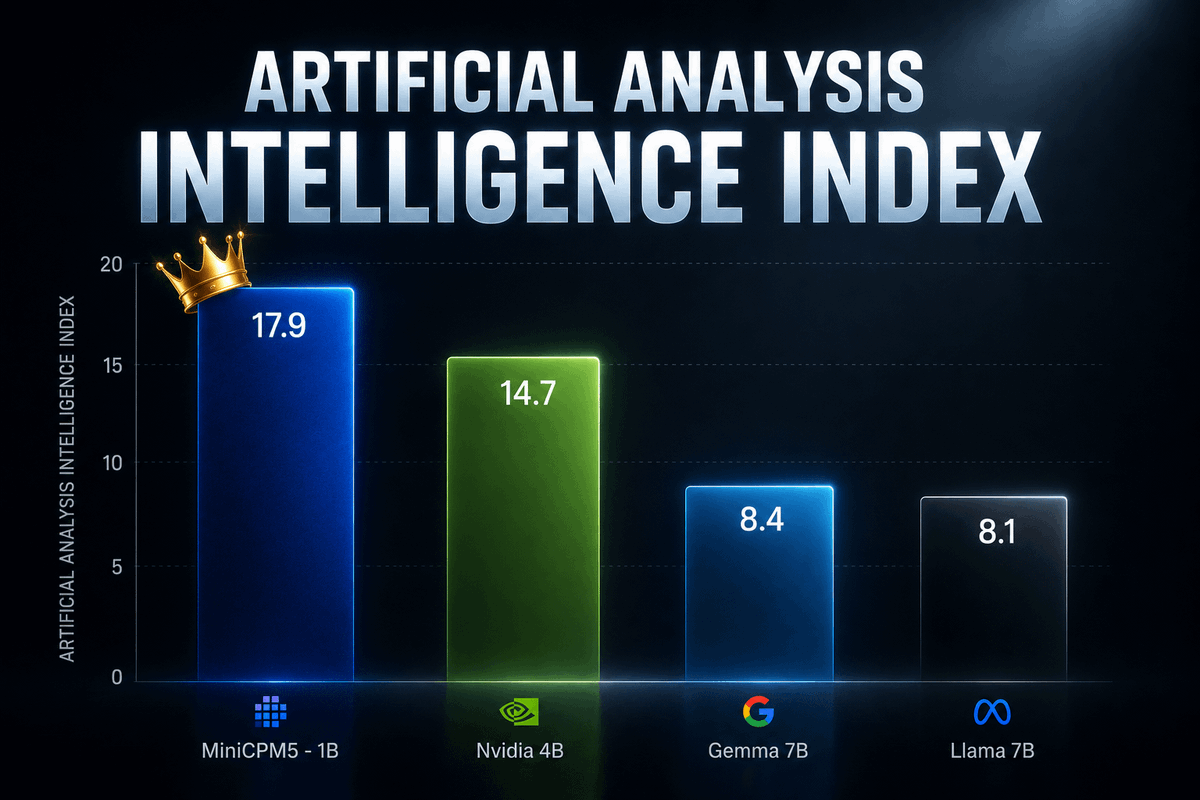
This isn't theory.
MiniCPM5-1B is living proof.
A 1 BILLION parameter model, trained on OpenBMB's UltraData-SFT-2605 dataset, now competes with Llama models 7x to 13x its size.
The right data pipeline changes everything.
1
3
806

May 29
What makes UltraData stand out isn’t just the datasets themselves.
It’s the governance system behind them.
The L0–L4 framework actually gives people a reproducible way to understand how data quality is being defined and measured instead of just asking the community to trust the final numbers.
🚀 MASSIVE upgrades for UltraData data stack! The tiered data management (L0-L4) framework has now fully battle-tested on MiniCPM5-1B and is ready for your models! No gatekeeping, just pure data power.
What’s NEW in our latest release:👇
✅ Ultra-FineWeb-L3 — 600B tokens (200B Chinese, 400B English) of high-density synthetic pre-training data, which expanded from Ultra-FineWeb via multi-style rewriting & QA generation, and has used in MiniCPM5-1B's decay stage.
🤗 huggingface.co/datasets/open…
✅ UltraData-SFT-2605 — 15M post-training samples across math, code, knowledge & instruction following, with deep-thinking and non-thinking training styles, used in MiniCPM5-1B's SFT stage.
🤗 huggingface.co/datasets/open…
41
37
23,847

May 28
The automotive AI space is about to get very interesting. On-device models for cars need to be small, fast, and genuinely capable at reasoning — that's an incredibly hard combination to hit. The insight that L3-quality synthesized data, matched to the right training stage, lets a 1B model exceed its expected performance ceiling is directly applicable here. UltraData is production infrastructure for the next wave of edge deployments.
🚀 MASSIVE upgrades for UltraData data stack! The tiered data management (L0-L4) framework has now fully battle-tested on MiniCPM5-1B and is ready for your models! No gatekeeping, just pure data power.
What’s NEW in our latest release:👇
✅ Ultra-FineWeb-L3 — 600B tokens (200B Chinese, 400B English) of high-density synthetic pre-training data, which expanded from Ultra-FineWeb via multi-style rewriting & QA generation, and has used in MiniCPM5-1B's decay stage.
🤗 huggingface.co/datasets/open…
✅ UltraData-SFT-2605 — 15M post-training samples across math, code, knowledge & instruction following, with deep-thinking and non-thinking training styles, used in MiniCPM5-1B's SFT stage.
🤗 huggingface.co/datasets/open…
15
30
7,683

May 28
One underrated implication of UltraData is that it shifts part of intelligence construction from model weights into the preprocessing pipeline itself.
In older paradigms, the model had to infer reasoning structure implicitly from noisy corpora.
Here, portions of that structure are externalized and made explicit through synthesis, rewriting, and curriculum staging.
In a sense, the pipeline is performing cognitive scaffolding before gradient descent ever starts.
🚀 MASSIVE upgrades for UltraData data stack! The tiered data management (L0-L4) framework has now fully battle-tested on MiniCPM5-1B and is ready for your models! No gatekeeping, just pure data power.
What’s NEW in our latest release:👇
✅ Ultra-FineWeb-L3 — 600B tokens (200B Chinese, 400B English) of high-density synthetic pre-training data, which expanded from Ultra-FineWeb via multi-style rewriting & QA generation, and has used in MiniCPM5-1B's decay stage.
🤗 huggingface.co/datasets/open…
✅ UltraData-SFT-2605 — 15M post-training samples across math, code, knowledge & instruction following, with deep-thinking and non-thinking training styles, used in MiniCPM5-1B's SFT stage.
🤗 huggingface.co/datasets/open…
18
32
8,959

May 28
Small models are entering a new phase. Not “how many params can you fit?”
But:
“How much intelligence can you distill from the same compute budget?”
UltraData feels aligned with that shift.
🚀 MASSIVE upgrades for UltraData data stack! The tiered data management (L0-L4) framework has now fully battle-tested on MiniCPM5-1B and is ready for your models! No gatekeeping, just pure data power.
What’s NEW in our latest release:👇
✅ Ultra-FineWeb-L3 — 600B tokens (200B Chinese, 400B English) of high-density synthetic pre-training data, which expanded from Ultra-FineWeb via multi-style rewriting & QA generation, and has used in MiniCPM5-1B's decay stage.
🤗 huggingface.co/datasets/open…
✅ UltraData-SFT-2605 — 15M post-training samples across math, code, knowledge & instruction following, with deep-thinking and non-thinking training styles, used in MiniCPM5-1B's SFT stage.
🤗 huggingface.co/datasets/open…
3
69
95
21,675

May 28
This is the argument I've been making for a while — data volume is a proxy metric, not a quality signal. What UltraData actually shows is that the same 1B parameter model behaves very differently depending on WHERE in the training pipeline you inject high-quality synthesized data. L3-tier data at annealing vs dumping everything at pretraining is not the same thing. The staged injection insight is underrated.
🚀 MASSIVE upgrades for UltraData data stack! The tiered data management (L0-L4) framework has now fully battle-tested on MiniCPM5-1B and is ready for your models! No gatekeeping, just pure data power.
What’s NEW in our latest release:👇
✅ Ultra-FineWeb-L3 — 600B tokens (200B Chinese, 400B English) of high-density synthetic pre-training data, which expanded from Ultra-FineWeb via multi-style rewriting & QA generation, and has used in MiniCPM5-1B's decay stage.
🤗 huggingface.co/datasets/open…
✅ UltraData-SFT-2605 — 15M post-training samples across math, code, knowledge & instruction following, with deep-thinking and non-thinking training styles, used in MiniCPM5-1B's SFT stage.
🤗 huggingface.co/datasets/open…
79
79
10,627

What that unlocks🔓:
🔷 Model performance consistently exceeds what parameter count alone would predict
🔷 Less compute & memory to reach strong reasoning benchmarks — device vendors can reproduce MiniCPM5-1B-level performance without rebuilding the data pipeline from scratch
Both datasets have been fully end-to-end validated through MiniCPM5-1B's entire training pipeline — a real-world proof of the UltraData tiered data management framework at scale.
🌐 ultradata.openbmb.cn
🤗 huggingface.co/collections/o…
#LLM #OpenSource #AIData #EdgeAI #UltraData #MiniCPM5
3
596
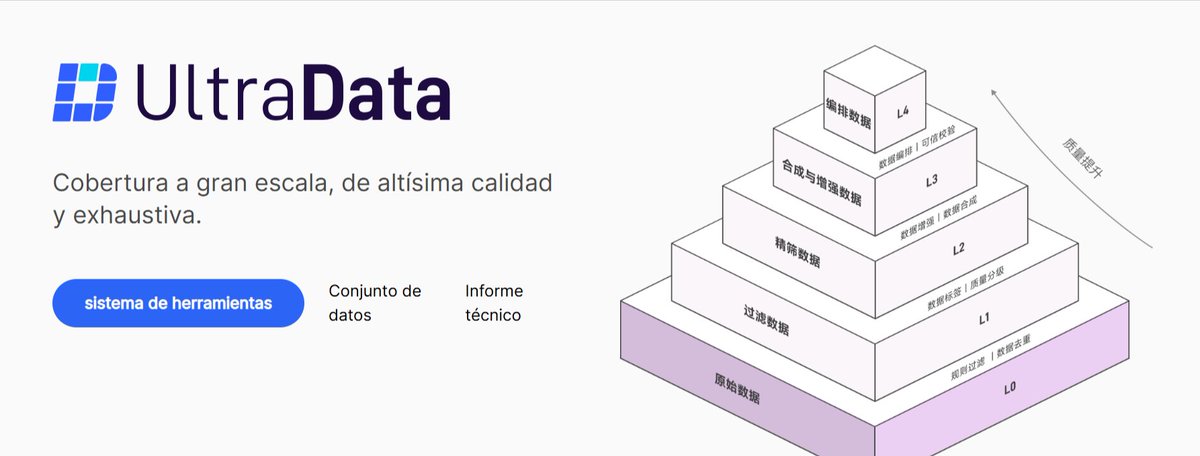
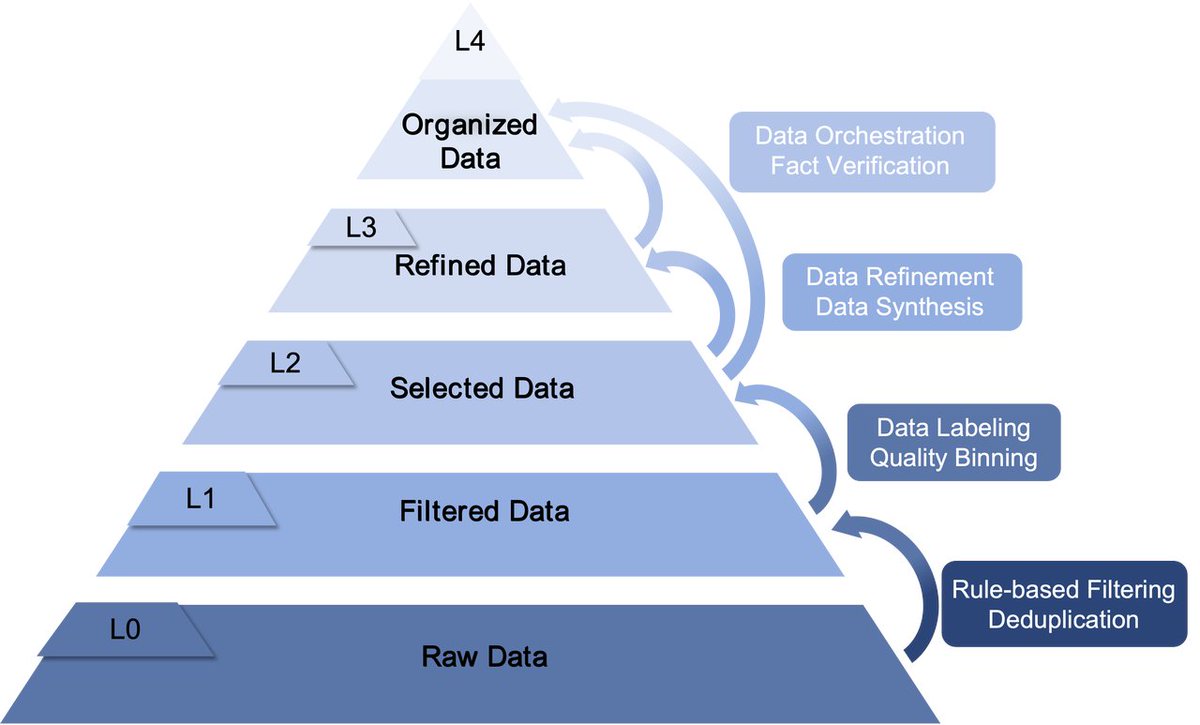
📊 Quality > Quantity From "Scaling Up" to Scientific Data Management.
LLM training is escaping the brute-force era. The key is knowing what to feed the model at right training period. UltraData re-defines data pipelines via an L0–L4 tiered framework to dynamically match data layers with optimal training stages:
- 📥 L0 (Crawling & Parsing): Raw text ingestion and structure restoration — gathering the base data pool.
- 🧼 L1 (Heuristic Filtering): Rule-based denoising, quality filtering, and deduplication — building the foundation for stable initial knowledge injection.
- 🎯 L2 (Model-based Selecting): High-dimension filtering to maximize information density — scaling up domain-relevant quality to boost core capabilities.
- 🧠 L3 (Synthesis & Rewriting): Multi-style generation and structural QA to unlock complex reasoning — fueling the decay, mid-training and SFT stages. (🔥 What we open-sourced today!)
- 🧩 L4 (RAG-ready Organizing): Advanced data orchestration and fact verification — tailoring processed data for seamless RAG and downstream application pipelines.
1
6
1,106
🚀 MASSIVE upgrades for UltraData data stack! The tiered data management (L0-L4) framework has now fully battle-tested on MiniCPM5-1B and is ready for your models! No gatekeeping, just pure data power.
What’s NEW in our latest release:👇
✅ Ultra-FineWeb-L3 — 600B tokens (200B Chinese, 400B English) of high-density synthetic pre-training data, which expanded from Ultra-FineWeb via multi-style rewriting & QA generation, and has used in MiniCPM5-1B's decay stage.
🤗 huggingface.co/datasets/open…
✅ UltraData-SFT-2605 — 15M post-training samples across math, code, knowledge & instruction following, with deep-thinking and non-thinking training styles, used in MiniCPM5-1B's SFT stage.
🤗 huggingface.co/datasets/open…
55
125
205
330,630