
Jun 9
I once shipped a board that worked perfectly in the lab.
Then the factory floor hit 40°C.
Random resets. No pattern. No hard fault. No warning in the logs.
3 days later I found it: a floating NRST pin on an STM32F405 picking up noise from a nearby motor driver. The internal pull-up I assumed existed? Doesn't. Page 67 of the datasheet. Required external 100nF cap to VCAP — missing from our schematic review checklist.
$4,200 in recalled units. One 100nF capacitor.
The hardware doesn't care about your lab temperature.
12

Jun 9
Junhe debuts at the VCAP Forum, focusing on automotive anti-corrosion and delivering an efficient, smart coating production line.
#CoatingProductionLine #CoatingEquipment #DacrometEquipment #DacrometCoating
1
5

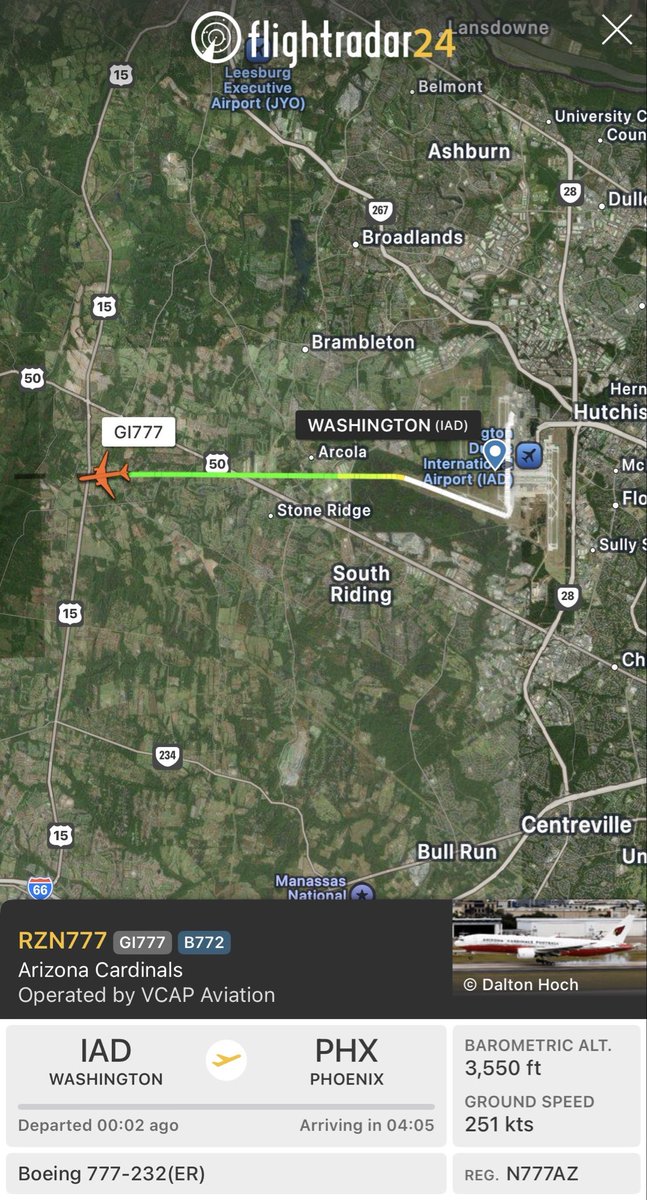
On June 6, 2026 at 15:47 UTC Arizona Cardinals 777-232ER operated by VCAP
Aviation departed Washington Dulles / IAD for Phoenix / PHX.
The aircraft had brought 300 Title I High School students to Washington, DC for an annual-all expenses paid-Civics Matter Arizona trip.
1/
1
2
138

Jun 5
Desde miami se veía que audi y vcap habia mejorado a una vuelta y alpine perdió ese fuerte a una vuelta
21
2,409


May 28
非時計マニアなのでよくわかりませんが、、PPAPのようにフリースプラングで角穴・丸穴車が表にあり、VCAPのようにガンギにも耐震があり、PPのように2,3番車のブリッジが独立し爪2つの退却型コハゼで、VCのようにテンプとガンギの受けが流線形で2,4番車と同列にジュネーブシールがある機械に惹かれます



1
23
1,716

May 28
11
227



Get a real-world roadmap to VCF 9.0 at #VMUGConnect Dallas! 📍
Join VCAP-certified #vExpert Alan Harrington to tackle NSX decisions, fleet upgrades, and readiness checklists you can apply now. Don't miss it!
Register: bit.ly/4c866Zi
#VMUG #VCF #VMware #Broadcom

6
156

May 13
On another thread, T Steyer invested in CoreGeoCivic. VCap firm.
An isolator.
2
11

May 8
Once all that is fixed then let's see what happened before we blame the UAW. UAW wages are lower in the south due to cost of living.
The political money all or mostly comes from the VCAP fund employees voluntarily contribute too. They are offered freebies for joining
1
2
784

With the dealine approaching fast, what would you do here #FPLCommunity?
2 FTs and 1.7 ITB, cap l vcap obviously not set yet.
#FPL

1
2
570

“The most successful professional isn’t the one who knows everything, but the one committed to continuous learning.”
At the VCAP Triple Milestone Event, Abraham Mensah Balley, Manager for Research & Alternatives, shared key insights on career longevity, emphasizing that beyond technical skills, professional exams and a collaborative mindset define true leadership.
At SIMS, we are proud to invest in and mentor the talent driving Ghana’s Venture Capital ecosystem forward.
2
75

May 4
عندي محتاجين حد بالمواصفات دي
we would like to have resources in the below:
- Cloud Engineers: VMware certified (VCP, VCAP or VCDX). K8s expert (CKA)
لو حد مناسب يبعتلي برايفت
2
8
33
2,579


Apr 13
\VCAP診断キャンペーン開催中🎁/
好評につき24日まで延長します🎉
「意外と当たってる!」と話題の16タイプ診断✨
自分の「隠れた素質」を覗いてみませんか?👀
✅応募
① @shindan_portal をフォロー
②この投稿をリポスト
③診断結果と指定タグをシェア
👇診断
shindancloud.com/vcap_16type…

3
113
49
2,522

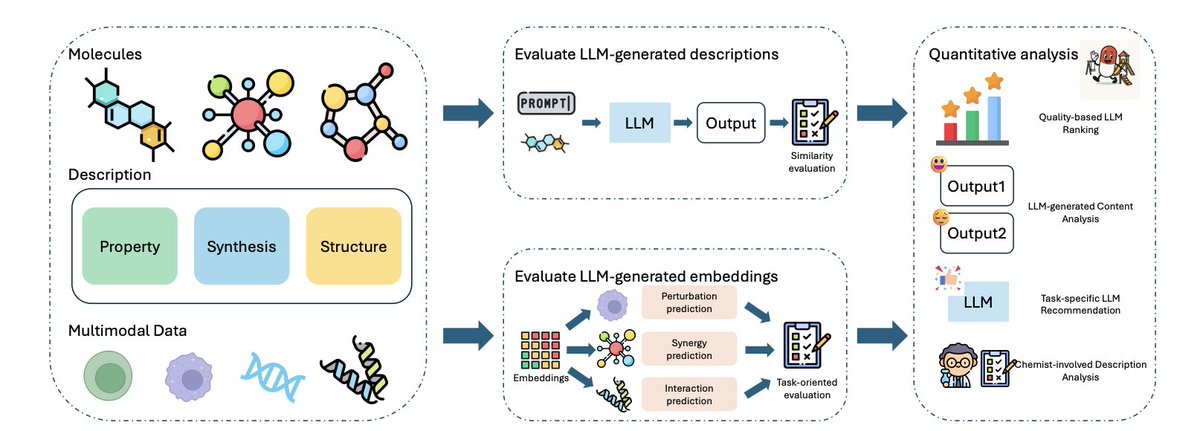
DrugPlayGround: Benchmarking Large Language Models and Embeddings for Drug Discovery
1. DrugPlayGround introduces a unified benchmark to objectively evaluate how well LLMs help drug discovery across four stages: drug function/property description, drug similarity via embeddings, drug synergy prediction, drug–protein interaction (DPI) prediction, and chemical perturbation (transcriptomic response) prediction—explicitly aiming to expose both strengths and failure modes (e.g., hallucinated chemistry).
2. A key design choice is the paired “text generation embedding” pipeline: LLMs first generate drug descriptions under controlled prompts/temperatures; embedding models then encode those descriptions for downstream ML tasks. The benchmark emphasizes leakage prevention, quantitative metrics, and expert (chemist/biologist) review to test chemical/biological reasoning rather than only surface-level performance.
3. For drug description faithfulness (862 drugs sampled from MolTextNet), the study benchmarks Claude, DeepSeek, GPT-4o, Gemini-1.5 Pro, and Mistral-large across 90 model–prompt–temperature settings (3 generations per drug). Quality is scored by BLEU, ROUGE-1/2/L, and BERTScore, plus a combined “Normalized Total” score.
4. Main text-generation findings: (i) lower temperature usually improves reference alignment, but the optimal temperature is model-dependent; (ii) prompt choice matters more than temperature for both performance and stability; (iii) “Meta” (domain-expert framing) prompts consistently improve description quality vs standard prompts, while CoT prompts reduce lexical/structural alignment and increase truncation/hallucination artifacts.
5. Reliability caveats are made concrete: even strong configurations can output incorrect numeric facts (e.g., molecular weight), wrong formulas/functional groups/stereochemistry, or overgeneralized pharmacology. CoT prompting is particularly associated with “reasoning text” that degrades factual alignment, and some models produce structured-looking chemistry that is not necessarily correct.
6. Embedding evaluation separates “representation fidelity” from “task utility.” Using GPT-4o (Meta, T=0.0) to generate descriptions, the authors compare embedding models (text-embedding-3-large, Gemini embedding, mistral-embed, Gemma-300m, Qwen3-Embedding-8B) by cosine similarity to ground-truth MolTextNet embeddings. Most achieve high similarity (>0.7) except Qwen3-Emb; Mistral-Emb is strongest, suggesting embedding quality is not simply tied to parameter scale.
7. In drug synergy prediction (BAITSAO framework; multiple synergy datasets with cell-line context), LLM-derived embeddings outperform a structure-focused molecular foundation model baseline (UniMol) and also outperform direct “LLM inference” (GPT-5.1 as a QA classifier). Gemini-Emb and Mistral-Emb are top overall across classification and regression metrics (AUROC/ACC; PCC/R2).
8. The benchmark adds mechanistic error analysis with domain experts: the same drug pair (5-FU dasatinib) can be predictable in one context (VCaP; AR-driven, more homogeneous) but unpredictable in another (MSTO-211H; heterogeneous, redundant signaling). The takeaway is that synergy predictability depends strongly on clarity of drug mechanism descriptions and how well cell state/driver biology is defined; adding efficacy-linked details (e.g., EC values) to descriptions may improve downstream performance.
9. For DPI prediction, drug embeddings from LLMs are paired with fixed protein embeddings (ESMC) and evaluated on TDC datasets (Human, DrugBank, C. elegans). LLM drug embeddings generally outperform domain-specific/structure-only embeddings, but “best embedding” is dataset-dependent: GPT embeddings are advantageous for Human, while Gemini/Mistral often lead on DrugBank; Gemini/Qwen3 perform better on C. elegans. Higher description-generation temperatures can help DPI, plausibly by increasing functional detail diversity in text.
10. For chemical perturbation prediction (Tahoe 100M; ~1,100 compounds across 50 cancer cell lines; ChemCPA model), swapping RDKit-style baselines for LLM-derived drug embeddings consistently improves R2. Best average performance is reported with Qwen3-Emb using GPT-4o descriptions at T=0.4 (high R2 with low variance), while some configurations increase variance—highlighting a performance/robustness trade-off. Qualitative examples suggest biologically grounded annotations (e.g., “tetracycline antibiotic”) support better perturbation prediction than descriptions dominated by physicochemical properties.
💻Code: github.com/HelloWorldLTY/dru…
📜Paper: biorxiv.org/content/10.64898…
#DrugDiscovery #LLM #Benchmark #Embeddings #Chemoinformatics #Bioinformatics #DrugSynergy #DTI #SingleCell #PerturbationSeq
1
3
16
1,349
"I came into today knowing it would be a good event. I came out convinced it was the right one to be at right now, at this point in the Zero to #VCAP journey."
Read more #VMUGConnect MSP Day 1 rollup from Solutions Architect & event attendee Allen J.
bit.ly/3PX71nY
1
14
359