
Jun 12
Aha takze raz mozno asi nieco... Nebojis sa rano vstat z postele a vyjst von? Nebat se a nekrast povedal TGM.
Co sa tyka chudoby, pod ficom sa zvacsuje. Teraz sa mam bat ze buduca vlada nieco s tym ne/urobi? Ja sa bojim teraz tejto hrozovlady.
7
June Suk Choi retweeted

Jun 3
Can MLLMs actually track what's happening in a video?
Introducing VSTAT 🎯, our new benchmark for visual state tracking.
The tasks are simple: count cups, read typed words, count page flips. Humans solve them easily. MLLMs don't.
vision-x-nyu.github.io/vstat…
🧵 [1/11]
10
66
236
160,072


Jun 11
Evo, ena že danes ponoči. Se splača vstat ob štirih in si ogledat enega od vrhuncev prvenstva: Južna Koreja-Češka.
1
4
126

Jun 10
Žgurčka z Poslancem Ž.Mahnič se moraš prej vstat ,da boš lahko orehe,ki so zate pretrdi trla.Leftardka.

Ko ne-pravnik razloži pravnici kaj v ustavi pomeni beseda 'lahko'.
Neprecenljivo.
👍 @ZanMahnic
👎 #LucijaTacer
12


Jun 10
Vy mate stesti, ze ti tri mrtvi nemuzou vstat z hrobu, proroze kdyby se to stalo, tak by si pred vami nejspis odplivli a Havlicek by vam nejspis dal po tlame, vy antisysteme.
17


Jun 4
VSTAT is a new video benchmark that tests whether AI models can continuously track changing visual states over time, and it’s impressive because humans score about 90.5% while the best current model only reaches 44.4%, exposing a huge weakness in today’s multimodal AI.
vision-x-nyu.github.io/vstat…
2
4
21
1,952

Jun 3
Understanding a video isn’t just about digesting each scene. It’s about tracking how the state evolves frame to frame.
Surprisingly, VSTAT shows that even cutting-edge models and agents fail at exactly this.
It was an honor to be part of this work with such a great team.
Jun 3

Can MLLMs actually track what's happening in a video?
Introducing VSTAT 🎯, our new benchmark for visual state tracking.
The tasks are simple: count cups, read typed words, count page flips. Humans solve them easily. MLLMs don't.
vision-x-nyu.github.io/vstat…
🧵 [1/11]
4
103

Jun 3
State tracking is a core pillar of video understanding: it requires identifying entities and events, and mapping how their states evolve over time.
Frontier multimodal models are surprisingly bad at it, so we built a benchmark to measure it.
Meet VSTAT!
Jun 3
Can MLLMs actually track what's happening in a video?
Introducing VSTAT 🎯, our new benchmark for visual state tracking.
The tasks are simple: count cups, read typed words, count page flips. Humans solve them easily. MLLMs don't.
vision-x-nyu.github.io/vstat…
🧵 [1/11]
2
6
31
67,018

VSTAT highlights the substantial perceptual gap between humans and MLLMs, but it goes far beyond that. Its diverse tasks are designed not merely to assess simple pixel-space tracking, but to evaluate how well models capture and understand evolving world states in the latent space of videos. Text is only one way to probe this capability, and we are excited to see future evaluations explore new modalities such as pixels, actions, and beyond!
Working on this benchmark has been a lot of fun along the way—huge shout-out to my amazing collaborators!
Jun 3
Can MLLMs actually track what's happening in a video?
Introducing VSTAT 🎯, our new benchmark for visual state tracking.
The tasks are simple: count cups, read typed words, count page flips. Humans solve them easily. MLLMs don't.
vision-x-nyu.github.io/vstat…
🧵 [1/11]
9
31
5,793
Jun 3
The second hypothesis: maybe the bottleneck is visual perception, not reasoning.
We ran a small diagnostic. For a few simple Blender tasks where the visible state can be manually transcribed, we fed Gemini a per-frame text transcript instead of the video. Gemini, which struggles on the video version, now solves the same task near perfectly.
Note: This isn't a fix. Most VSTAT tasks, especially real-world ones, can't be hand-transcribed at all. But as a probe, it isolates the bottleneck: perception, not reasoning.
[5/11]

1
1
7
756
Jun 3
Why do MLLMs fail on VSTAT?
We considered two hypotheses. The first: maybe frame subsampling causes models to miss brief events. To test this, we temporally stretched the video so every event is fully visible at the model's frame rate. However, it showed only marginal improvements.
[4/11]
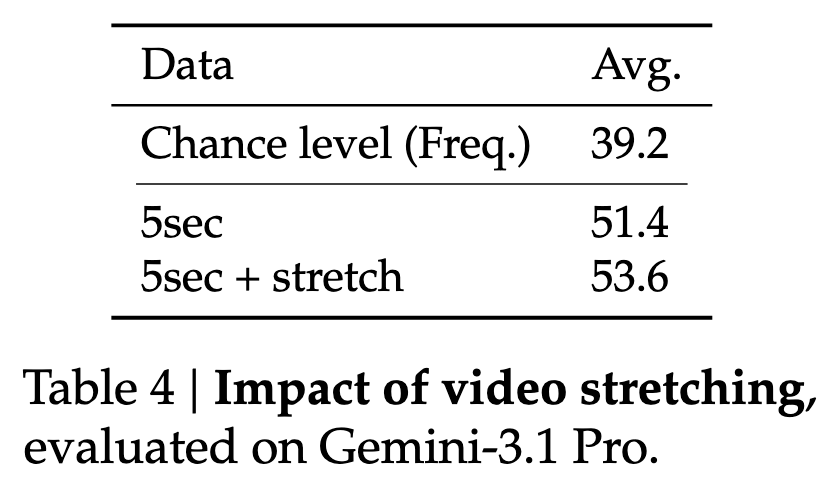
1
1
7
881
Jun 3
The gap between humans and current MLLMs is large:
Humans: 90.5%Gemini-3.1 Pro: 44.4�st open-source (LLaVA-OV-2-8B): 35.1%Frequency baseline: 37.8%
Strong performance on existing video benchmarks doesn't transfer to VSTAT.
[3/11]
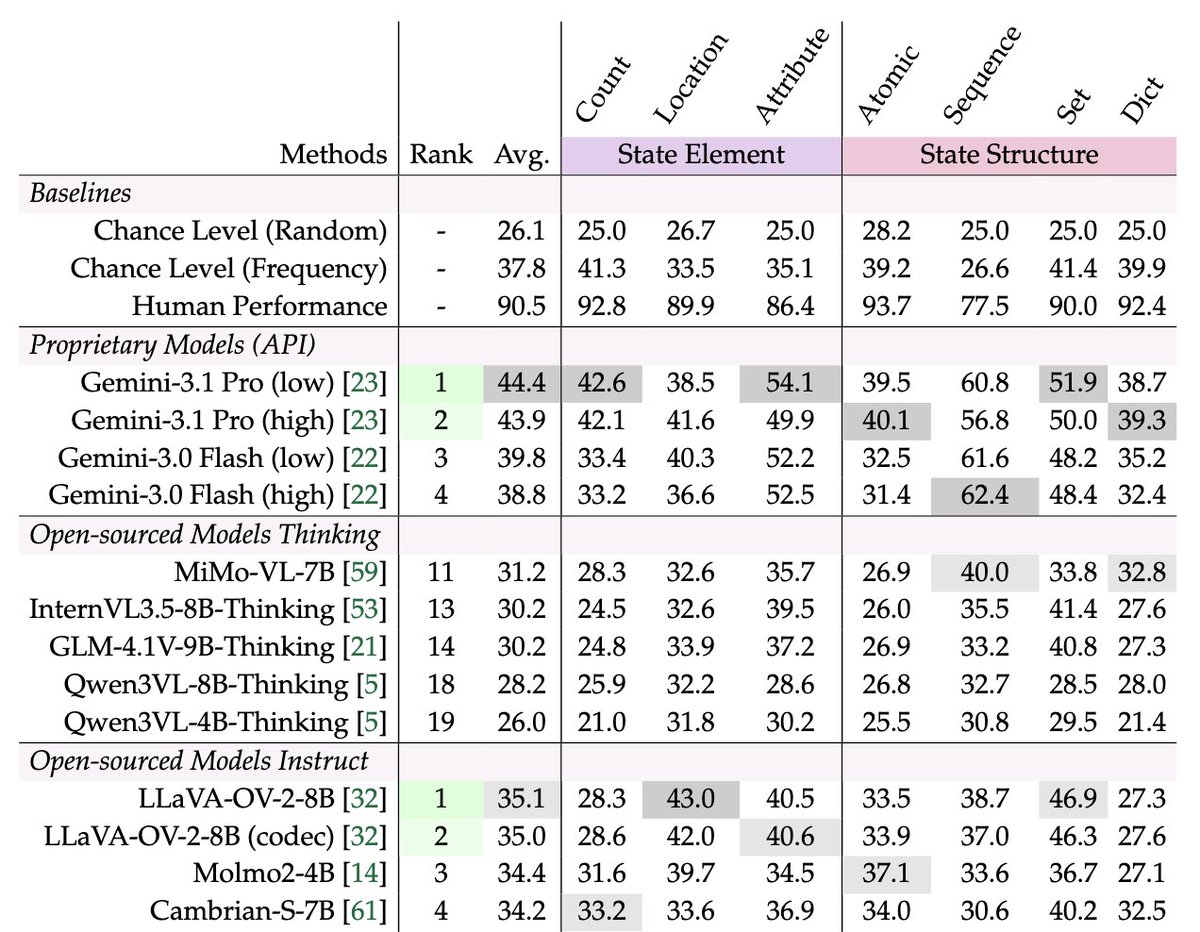
1
1
11
1,451
Jun 3
VSTAT consists of 834 videos and 1,500 questions, drawn from Blender-synthesized scenes, self-recorded clips, and YouTube videos.
Every task is designed so the answer can't be read off any keyframe or short segment. Models have to integrate events across the entire video.
[2/11]

1
8
1,899




May 30
Jako vstat rano z postele a bez hrebenu jit rovnou “do akce”…to je bud odvaha nebo absence soudnosti🤡🤣
4
46