
15 Jun 2025
VideoDeepResearch: Long Video Understanding With Agentic Tool Using
Overview:
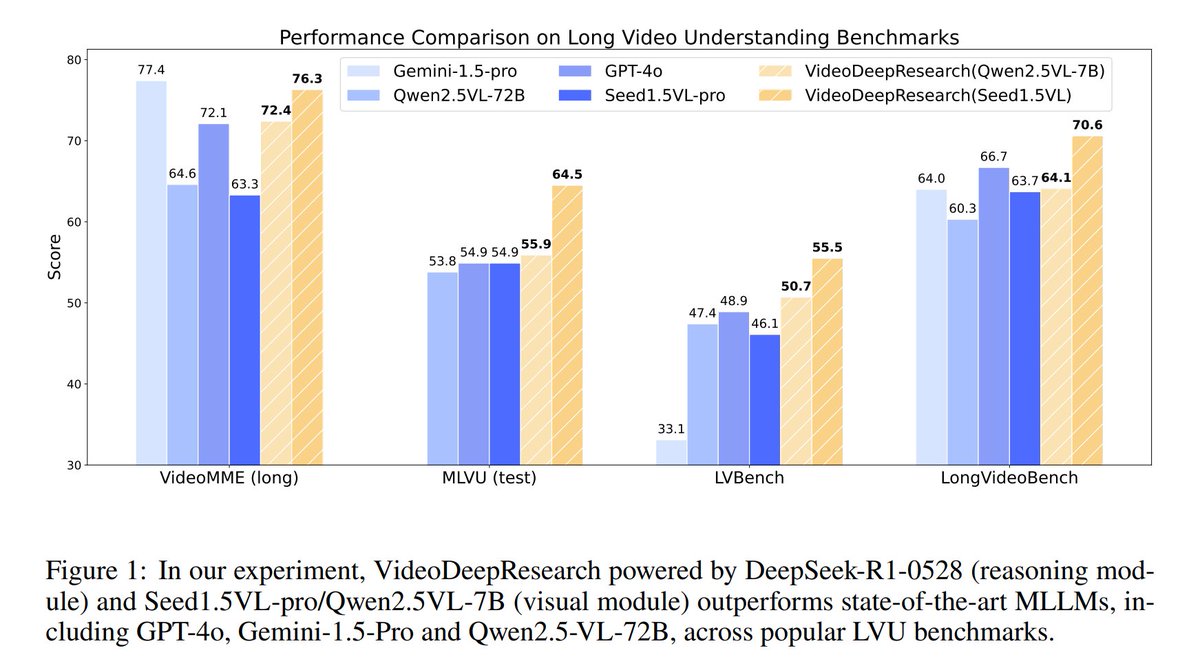
VideoDeepResearch presents an agentic framework for long video understanding, bypassing the need for extended-context MLLMs by combining a text-only large reasoning model with a modular multi-modal toolkit.
This system generates problem-solving strategies through reasoning and selective tool-based content access, yielding performance increases of 9.6% on MLVU (test), 6.6% on LVBench, and 3.9% on LongVideoBench over prior MLLM baselines.
Paper:
arxiv.org/abs/2506.10821
1
1
10
943
15 Jun 2025
🚨This week's top AI/ML research papers:
- Self-Adapting Language Models
- V-JEPA 2
- The Illusion of the Illusion of Thinking
- Magistral
- Reinforcement Pre-Training
- VideoDeepResearch
- Unsupervised Elicitation of LMs
- CoRT
- The Diffusion Duality
- Ming-Omni
- One Tokenizer To Rule Them All
- Build the web for agents, not agents for the web
- Learning What RL Can't
- Hidden in plain sight
- ViTs Don't Need Trained Registers
- Play to Generalize
- Thinking vs. Doing
- Self Forcing
- Highly Compressed Tokenizer Can Generate Without Training
- RiemannFormer
- Seedance 1.0
- Edit Flows
- Resa
- On a few pitfalls in KL divergence gradient estimation for RL
- e3
overview for each authors' explanations
read this in thread mode for the best experience

6
79
667
51,267

14 Jun 2025
13. VideoDeepResearch: Long Video Understanding With Agentic Tool Using
🔑 Keywords: Long video understanding, multi-modal large language models, VideoDeepResearch, agentic systems, reasoning model
💡 Category: Multi-Modal Learning
🌟 Research Objective:
To challenge the common assumption that long video understanding (LVU) requires multi-modal large language models (MLLMs) with extended context windows and specialized capabilities.
🛠️ Research Methods:
Introduced VideoDeepResearch, a framework utilizing a text-only large reasoning model (LRM) paired with a modular multi-modal toolkit to approach LVU tasks through reasoning and selective content access.
💬 Research Conclusions:
- VideoDeepResearch achieved notable improvements over existing MLLM baselines, with advances of 9.6%, 6.6%, and 3.9% on key benchmarks (MLVU, LVBench, LongVideoBench).
- The results indicate that agentic systems hold significant potential for addressing challenges in long video understanding.
👉 Paper link: huggingface.co/papers/2506.1…

1
4
75
14 Jun 2025
📚 AI Native Daily Paper Digest - 20250613 🌟
Follow @AINativeF for the latest insights on AI Native.
Covering AI research papers from Hugging Face, featured in the image.
💡 Stay updated with the latest research trends and dive deep into the future of AI! 🚀
#AI #HuggingFace #AIPaper #AINative #AINF
— Appendix: Today's AI research papers —
1. ReasonMed: A 370K Multi-Agent Generated Dataset for Advancing Medical
Reasoning
2. SWE-Factory: Your Automated Factory for Issue Resolution Training Data
and Evaluation Benchmarks
3. Text-Aware Image Restoration with Diffusion Models
4. VRBench: A Benchmark for Multi-Step Reasoning in Long Narrative Videos
5. AniMaker: Automated Multi-Agent Animated Storytelling with MCTS-Driven
Clip Generation
6. Magistral
7. Discrete Audio Tokens: More Than a Survey!
8. Domain2Vec: Vectorizing Datasets to Find the Optimal Data Mixture
without Training
9. Optimus-3: Towards Generalist Multimodal Minecraft Agents with Scalable
Task Experts
10. PosterCraft: Rethinking High-Quality Aesthetic Poster Generation in a
Unified Framework
11. Resa: Transparent Reasoning Models via SAEs
12. AutoMind: Adaptive Knowledgeable Agent for Automated Data Science
13. VideoDeepResearch: Long Video Understanding With Agentic Tool Using

2
8
122

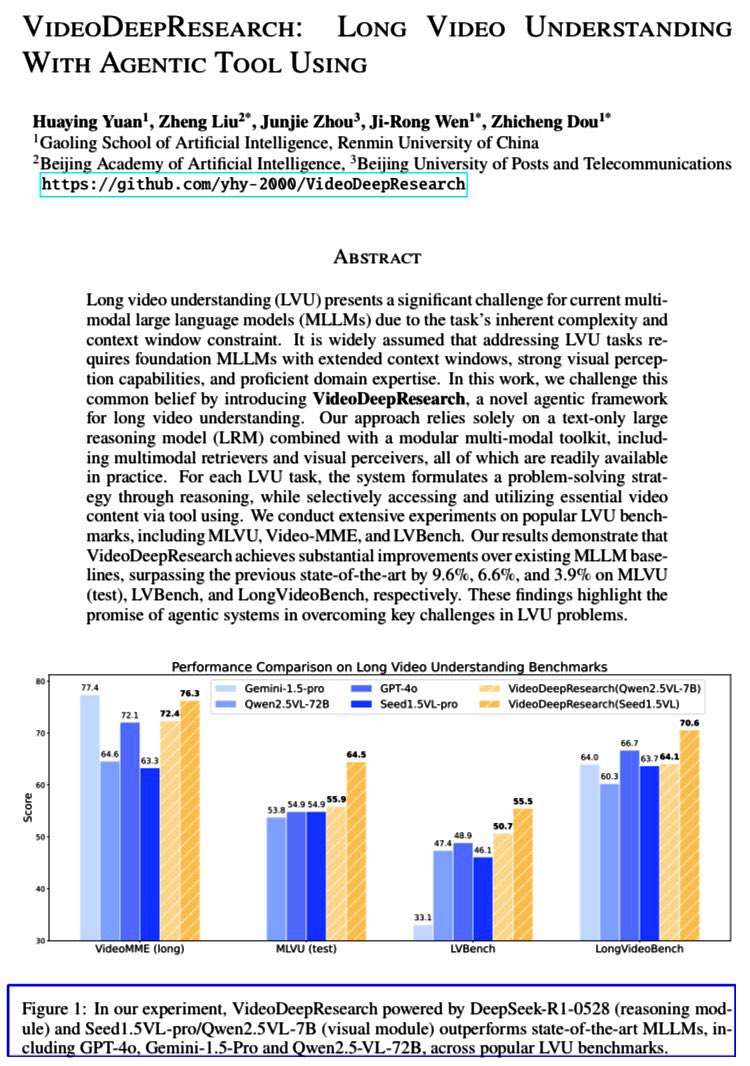
VideoDeepResearch: Long Video Understanding With Agentic Tool Using
A modular agentic framework for long video understanding that combines a text-only reasoning model (DeepSeek-R1-0528) with specialized tools such as retrievers, perceivers, and extractors to outperform large MLLMs without relying on extended context windows.
PAPER: arxiv.org/abs/2506.10821
4
24
6,420