かあみ🌺KaAmi🕊️ retweeted

Jun 15
赤ずきんちゃんトークも作ってみましたー♪
参照音声なしで30秒、2パート生成すると、後半で声質が変わりやすかったので、irodori TTS v3 VoiceDesign 参照音声に変更。
ぐるぐる~、かわいい(・∀・)イイ!!
Jun 14

ろてじんさんの「ぐるぐるトマリちゃん」が可愛すぎて、ぐるぐるアリスちゃん、作ってみましたー♪
音声はirodori TTSを使ってcodex経由で作成。
かわいいー(・∀・)イイ!!
7
64
4,472




VoiceDesign版のIrodoriでキャラのセリフを自然な日本語音声にしてみました。 | ろくのエーベルージュ
ameblo.jp/worand/entry-12969… #Amebaブログ #アメブロ
35

Jun 8
📰 ローカルAI音声合成「Irodori-TTS V3」がリリース!声色指定・感情制御・長さ指定すべて可能に
Aratako氏が開発したオープンソースのローカルTTSモデル「Irodori-TTS」のV3が登場しました。500MパラメータのFlow Matchingベースモデルで、完全ローカル環境で高品質な音声合成が可能です。
🔥 V3の主な進化ポイント:
・音声品質が大幅向上(よりフォーマルで自然な音声に)
・秒数指定機能:生成する音声の長さを「Seconds」欄で指定可能
・絵文字感情制御:セリフに絵文字を混ぜるだけで感情を表現 😏(からかい)😪(眠そう)など
・参考音声コピー:音声ファイルをアップロードすれば同じ声色を再現
・VoiceDesignモデル(600M):声色をテキスト説明で指定できる新モデルも同時公開
💻 対応環境:
NVIDIA GPU / AMD GPU / Intel XPU / CPU(macOS含む)の幅広い環境に対応。Python uv で簡単インストール、Gradio製Web UIでブラウザから操作可能。
完全無料・完全ローカルで動くため、APIコストなしに高品質な日本語TTSを使えるのは個人開発者やVTuber制作に朗報ですね ✨
#雪羽のログ
1
7
714

Jun 6
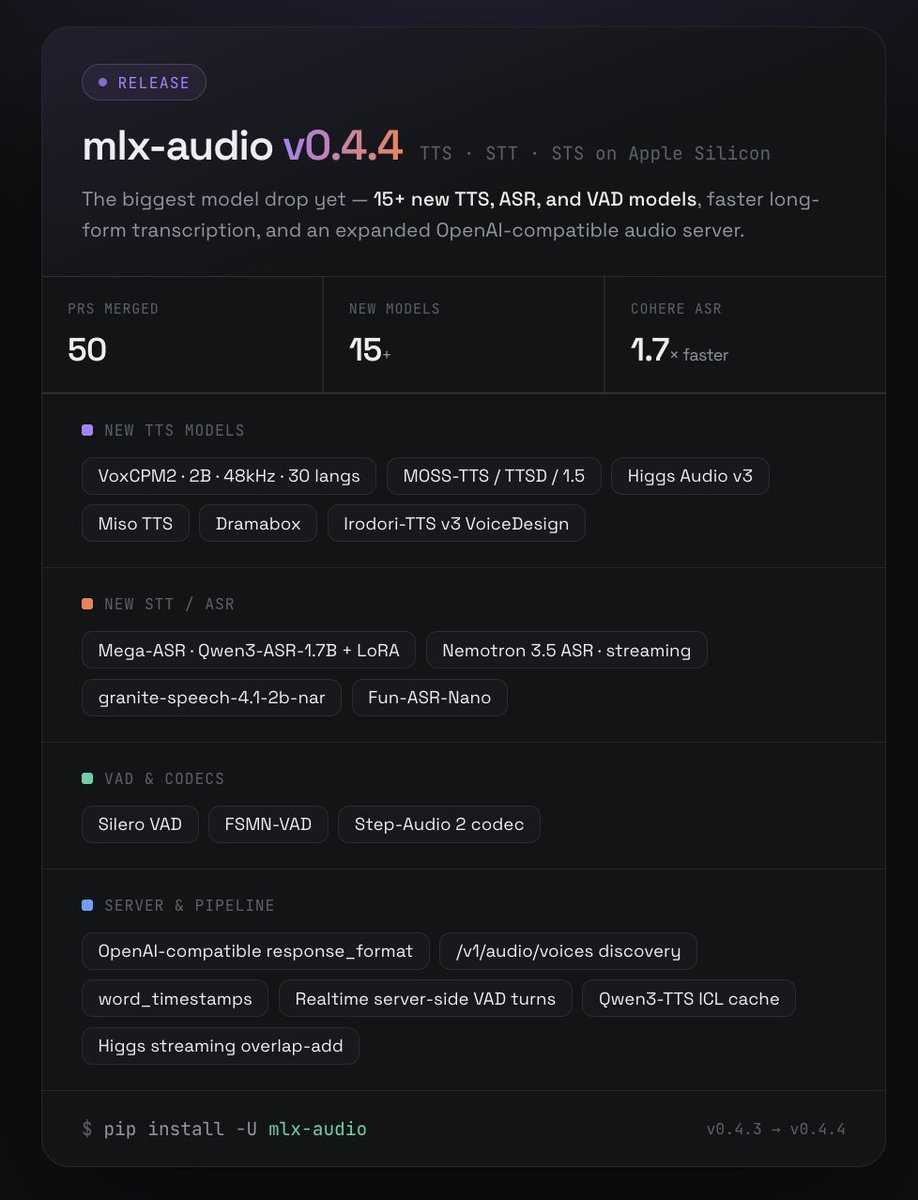
🚀 mlx-audio v0.4.4 已发布——这是我们迄今为止推出的功能最强大的版本。
新增了 15 个 TTS(文本转语音)、ASR(自动语音识别)及 VAD(语音活动检测)模型,提升了长文本内容转录的速度,并改进了与 OpenAI 兼容的音频服务器功能。所有这些技术都运行在 Apple Silicon 平台上。
🎤 新增的 TTS 语音引擎:
• VoxCPM2(支持 2B 语言库、48kHz 音频格式、30 种语言)
• MOSS-TTS / TTSD / 1.5
• Higgs Audio v3
• Miso、Dramabox、Irodori-TTS v3(VoiceDesign 技术支持)
📝 新增的 STT/ASR (语音转文本/自动语音识别)工具:
• Mega-ASR(基于 Qwen3-ASR 1.7B 模型,支持 LoRA 路由技术)
• Nemotron 3.5 ASR(支持实时语音识别功能)
• granite-speech-4.1-2b-nar、Fun-ASR-Nano
• Cohere ASR(长文本转录速度提升 1.7 倍)
🔊 新增的语音处理组件及编码器:
• Silero VAD、FSMN-VAD、Step-Audio 2
⚙️ 服务器改进:新增了与 OpenAI 兼容的数据格式(response_format),支持 /v1/audio/voices 格式以及逐词时间戳功能;服务器端的语音活动检测功能已由 lllucas 完成开发。
安装方法:`uv pip install -U mlx-audio`
明天安装测试看看实际效果,对于中文的支持效果如何?
Jun 6

🚀 mlx-audio v0.4.4 is out — our biggest model drop yet.
15 new TTS, ASR & VAD models, faster long-form transcription, and an expanded OpenAI-compatible audio server. All running local on Apple Silicon.
🎤 New TTS
• VoxCPM2 — 2B, 48kHz, 30 languages
• MOSS-TTS / TTSD / 1.5
• Higgs Audio v3
• Miso, Dramabox, Irodori-TTS v3 VoiceDesign
📝 New STT/ASR
• Mega-ASR (Qwen3-ASR-1.7B LoRA routing)
• Nemotron 3.5 ASR (streaming)
• granite-speech-4.1-2b-nar, Fun-ASR-Nano
• Cohere ASR — 1.7× faster long-form
🔊 VAD & codecs: Silero VAD, FSMN-VAD, Step-Audio 2
⚙️ Server: OpenAI-compatible response_format, /v1/audio/voices, word timestamps, realtime server-side VAD turns h/t @lllucas
Huge thanks to all the contributors 🙏
> uv pip install -U mlx-audio
github.com/Blaizzy/mlx-audio
41
7
38
6,472

Jun 6
🚀 mlx-audio v0.4.4 is out — our biggest model drop yet.
15 new TTS, ASR & VAD models, faster long-form transcription, and an expanded OpenAI-compatible audio server. All running local on Apple Silicon.
🎤 New TTS
• VoxCPM2 — 2B, 48kHz, 30 languages
• MOSS-TTS / TTSD / 1.5
• Higgs Audio v3
• Miso, Dramabox, Irodori-TTS v3 VoiceDesign
📝 New STT/ASR
• Mega-ASR (Qwen3-ASR-1.7B LoRA routing)
• Nemotron 3.5 ASR (streaming)
• granite-speech-4.1-2b-nar, Fun-ASR-Nano
• Cohere ASR — 1.7× faster long-form
🔊 VAD & codecs: Silero VAD, FSMN-VAD, Step-Audio 2
⚙️ Server: OpenAI-compatible response_format, /v1/audio/voices, word timestamps, realtime server-side VAD turns h/t @lllucas
Huge thanks to all the contributors 🙏
> uv pip install -U mlx-audio
github.com/Blaizzy/mlx-audio
26
58
530
43,898

irodori-TTS 600m v3 VoiceDesign、若干(本当にお気持ち程度)機械的な部分はあるけど抑揚表現を多用する動画等で使うならありだなー。
1
2
220


Jun 3
こちらはIrodori-TTSのVoiceDesign版で生成した声を参照させて、複数のセリフで一貫性を保持したもの(4つの音声を繋ぎ合わせています)
目次は2枚目。サー…というノイズの除去方法や、声の高さ(ピッチ)を細かく操作してオリジナルボイスを作るやり方などを各種検証しています。

1
1
15
4,141

Claude Codeに指示すればオリジナル音声もほぼ放置で作れる時代きた
1️⃣作りたい声のベース音声をClaude Codeに渡す
2️⃣それをもとにIrodori-TTS VoiceDesign V3のボイス&キャプション入力でオリジナルの声と雰囲気に調整し、そのまま学習データ量産
3️⃣さらにはそのままIrodori-TTSで再利用可能なモデルを学習
(2️⃣と3️⃣は引用のColab環境で実施)
一点問題としては、声を聞いてもClaude Codeにはこれがどういう属性の声なのかが分からないというところ
(つまり成果物の出来は人間がレビューする必要ある)
逆にこれをクリアできれば『自然言語で指示すれば欲しいモデルを作ってもらえる』ことが可能
このワークフローまで確立できれば、オリジナルAI VTuberの『声』を自然言語起点で作成していくことも可能になるし、その他、用途に応じたAI人格を効率的に生成することなども可能になる。やれること広がりそう

Irodori-TTSのVoiceDesignにv3が出たとのことで、早速Google Colabで試してみています!
ボイス入力・キャプション入力など色々と試しがいのある機能豊富なのでTTSに興味ある人は要チェックですね👀
Google Colabで検証してみたい人向けのコードも置いておきます👇
github.com/shinshin86/Irodor…
2
24
227
26,048

Jun 2
これ、派生版のVoiceDesignというのを使うとスタイルプロンプト指定で性別や声質なんかも変更できます。
そしてこのソフトは、日本語用に作成されています。開発者は、aratakoさんという日本の方です。
凄いですね
Jun 1

Irodori-TTSという、AIが文章を読み上げてくれるソフトを試しに使ってみたんだが、「朝目が覚めると女の子になっていた元男性のリアクション」が美少女声で完璧に再現できて正直ブッたまげた……!
1
2
3
478
Irodori-TTSのVoiceDesignにv3が出たとのことで、早速Google Colabで試してみています!
ボイス入力・キャプション入力など色々と試しがいのある機能豊富なのでTTSに興味ある人は要チェックですね👀
Google Colabで検証してみたい人向けのコードも置いておきます👇
github.com/shinshin86/Irodor…
Jun 1

Irodori-TTSのボイスデザインモデルにもv3が来ました!新機能としてボイス入力とキャプション入力の両方ができるようになっている!僕が欲しかった機能、ボイスクローンしつつ演技をキャプションで指定するやつができそう
huggingface.co/Aratako/Irodo…
3
37
27,103