
Jun 9
OBSプラグイン、WindowsML使ってtensorrt-rtxをダウンロードしてくる仕組みにしたらライセンスをクリアしてtensorrt-rtx使えそうだよなー
推論が速くなって今よりもうちょっと軽くできそうではあるが、いるんかなー?
66
Feb 8
github copilotの無料枠使い切ったので、しばらく手も足も出ない素人
DirectMLがサポート打ち切ったからか、onnxruntime-DMLが難し過ぎる
腫れ物に触るような感じで触ったら大事故というか大工事
やっぱWindowsMLに移行すべきなんかなー?
2
251

Jan 5
The only platform (?) that supports Microsoft's WindowsML on CPU, NPU, and GPU.

3
169

15 Oct 2025
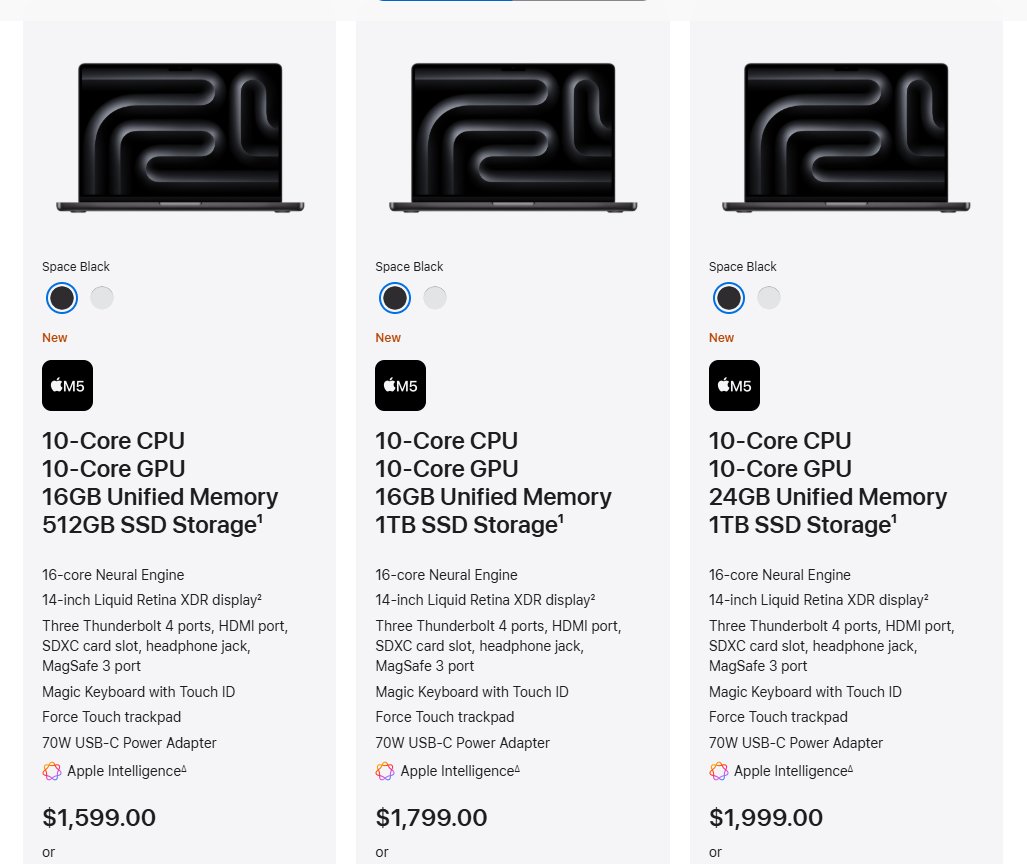
Another surprise... @Apple announces the new M5 chip and launches preorders TODAY for 14-in MacBook Pro, iPad Pro, and even Vision Pro devices using it. Prices on the 14-in MBP start at $1599 with just 16GB of memory, which might be an issue for even moderate sized AI models as we have seen. A 32GB/1TB model starts at $2199 (!!).
Some early thoughts:
🔍 Apple’s M5: A Subtle Shift Toward GPU-Driven AI
Apple’s new M5 chip puts almost all of its emphasis on AI performance, but not where some have expected. Instead of promoting a dramatically more capable “Neural Engine,” Apple has re-architected its GPU around AI compute, adding what it calls a Neural Accelerator inside each GPU core.
⚙️ The Claims, and the Questions
Apple says M5 delivers up to 4x the peak GPU compute of M4 for AI workloads. The catch? They don’t specify how that’s measured. There’s no mention of precision (FP16, INT8, FP8?), workload type, or test methodology, just “select industry-standard benchmarks.” In other words, the gain could be part architectural, part software, or even the result of changing measurement conventions.
CPU performance sees a modest lift, 10 cores (4P 6E) with up to 15% better multithreaded performance, while the Neural Engine is described only as “faster and more efficient.” Apple clearly wants the story centered on the GPU, not the CPU or NPU.
Memory bandwidth climbs to 153 GB/s, about 30% higher than M4. That’s meaningful for AI throughput, though still below the 228 GB/s figure Qualcomm quotes for its Snapdragon X2 Elite Extreme and on par with the recently announced Intel Panther Lake platform.
🧩 Reading Between the Lines
The structural change, embedding and focusing on the AI accelerators in each GPU core, suggests Apple’s view is converging with what NVIDIA and Intel are already marketing. Modern GPUs are becoming AI processors first and graphics engines second.
But the vagueness of Apple’s performance claims raises questions. “4x peak compute” doesn’t always translate to 4x real throughput in mixed workloads. Without knowing the precision or thermal limits, it’s impossible to gauge how much of this performance will show up in production AI models.
Still, this is a meaningful architectural signal. Apple seems to agree with Intel’s Panther Lake approach: prioritize GPU performance for AI inference, rather than over-invest in a standalone NPU that’s limited to fixed-function workloads.
💡 Implications for Windows and the AI PC Ecosystem
This announcement puts subtle pressure on the Copilot PC narrative. @Microsoft and @Qualcomm have all been framing the NPU as the center of local AI. Apple’s move suggests that the NPU may not remain the hero of AI compute, especially as model sizes grow and developers demand flexibility, at least for the Apple ecosystem.
If Apple’s GPU Neural Accelerator design delivers real performance and efficiency gains, it could challenge the current Copilot PC stance, where NPU performance (in TOPS) is used as the primary marketing metric. The shift may also highlight a potential gap for Windows OEMs.
For Microsoft: The Copilot PC model assumes NPU compute as the main accelerator class. If GPU-based AI becomes more relevant, the Windows runtime and APIs (like WindowsML or DirectML) will need to keep evolving quickly to distribute AI workloads more intelligently.
For OEMs (Dell, HP, Lenovo, Surface, etc.): Systems designed for AI, around lower-power NPUs, might need to pivot more to a GPU story to keep pace if Apple’s approach proves more scalable. Future AI PCs may need to lean harder into integrated GPU performance or hybrid compute models rather than relying on isolated neural blocks. Still, Apple has been the laggard in this space, so it may not be the one setting the standard going this time around.
For Qualcomm, @AMD and @intel: they already combine CPU, GPU, and NPU acceleration, but Apple’s design could still force a rethink on how GPU cores contribute to AI throughput. Intel’s Panther Lake appears to be following a similar path (based on the messaging from our time with the company earlier this month), but the execution speed will matter.
The opportunity for Windows vendors lies in software orchestration. If Microsoft can let the OS fluidly allocate AI workloads between CPU, GPU, and NPU, based on efficiency, latency, and precision, it could regain narrative control. But for now, Apple’s pitch reframes the discussion: it’s not just about how many TOPS your NPU has, it’s about where the useful AI compute actually lives.
🎯 Final Take
Apple’s M5 continues challenges the Copilot PC formula. By pushing AI acceleration deeper into the GPU, they’re implying the NPU may not be the long-term answer.
The “4x” GPU compute claim sounds huge, but without context, it’s hard to know how much of that will show up in real-world AI workloads.
For Windows and its partners, this is both a risk and an opportunity: a reminder that AI PCs will ultimately be defined not by one specialized block, but by the system’s ability to balance compute, power, and memory across all engines.


1
7
2,172
8 Oct 2025
Microsoft’s latest piece on how the NPU is shaping a more intelligent @Windows makes one thing clear: the NPU isn’t an experiment, it’s their view of the architectural anchor for local AI compute.
NPUs in Copilot PCs can perform 40 trillion operations per second, running vision, audio, and small language models locally while using less power than the CPU or GPU. As Microsoft’s Steven Bathiche notes, the Applied Sciences team want this hardware specifically to enable new AI experiences, not just accelerate existing ones.
news.microsoft.com/source/fe…
WindowsML and DirectML now intelligently route workloads between the CPU, GPU, and NPU, ensuring the right processor handles the right task. But the article reinforces that the NPU is the most efficient and scalable path forward for on-device inference, freeing other silicon for what it does best.
It’s no coincidence Microsoft built the entire Copilot PC program around NPU performance. If Microsoft is betting this hard, developers and OEMs likely will too. The NPU is where the next wave of AI user experience innovation will happen, today’s 40 TOPS is just the start.
When local agents evolve beyond assistive prompts into always-on, multimodal companions, we’ll want even more.
5
12
40
5,936

8 Oct 2025
Every 2nd Wednesday
Online #AI LT event #AIMTG
youtube.com/live/vDQ1vouSARQ
LT #5 @takabrz1 as a #MicrosoftMVP at #大阪駆動開発
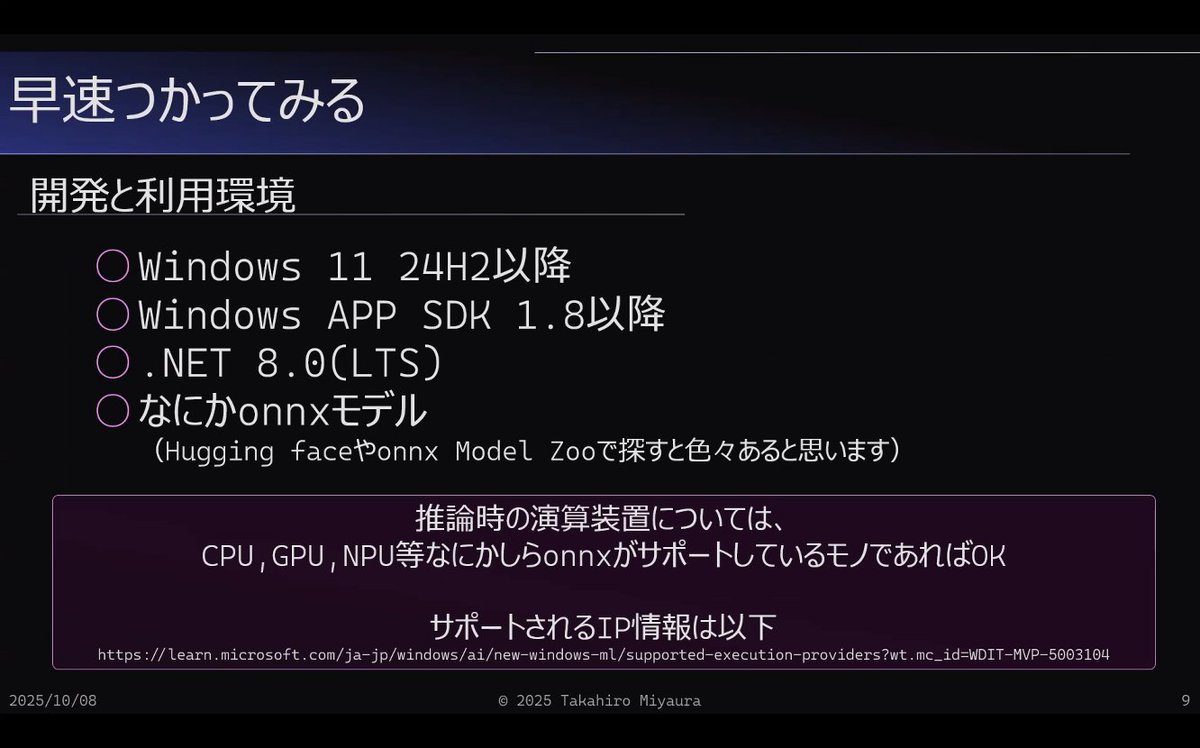
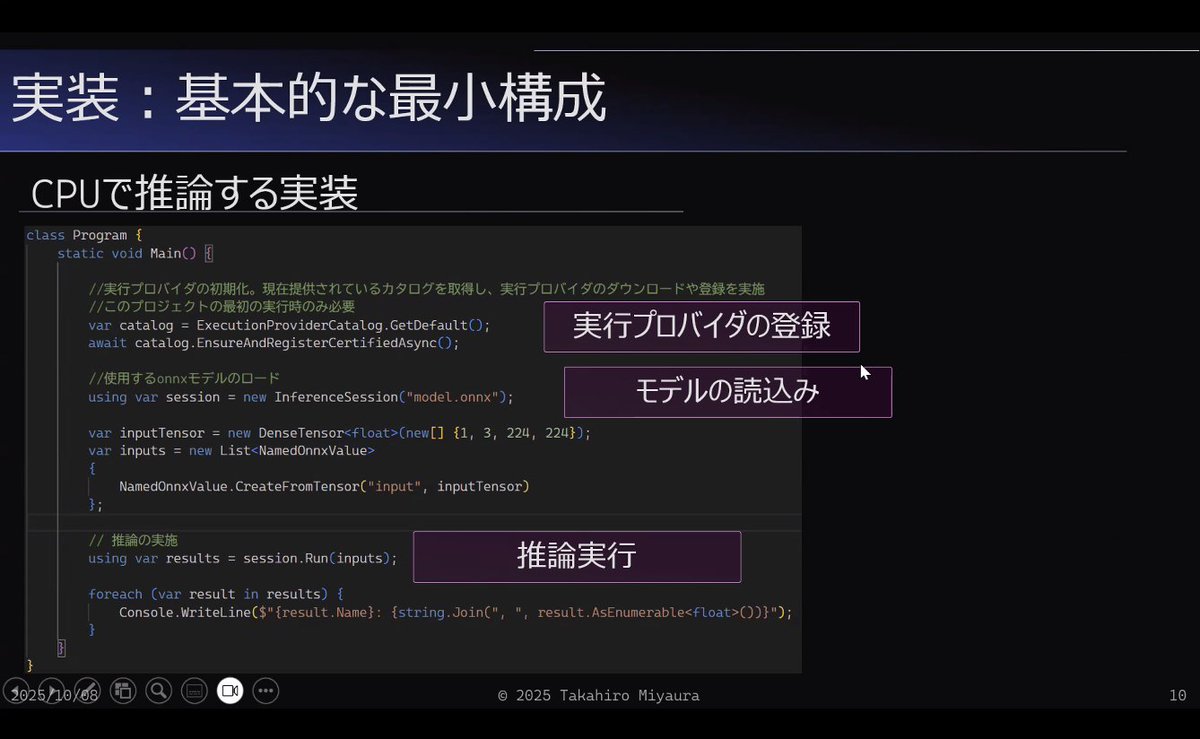
"#WindowsML is now generally available, so I gave it a try!"
#DoMCN #DeepLearningOsaka #ARFukuoka #KumaMCN #KansaiAIPub #神戸駆動開発


3
148

6 Oct 2025
While they had a bit of a slow start, with the general availability of #WindowsML, the value of NPUs to accelerate AI applications should see some big jumps forward soon. Interesting chat with @microsoft's @sbathiche: news.microsoft.com/source/fe…
4
309

26 Sep 2025
Want to run your own AI models locally on Intel hardware in Windows apps? With Windows ML now generally available— and with its new integration of the OpenVINO toolkit— developers can deploy AI across CPUs, GPUs, and NPUs. Check out our sample workflows (ResNet-50, CLIP-ViT) and VS Code tools help you get started. Try it out here:
intel.ly/3II8k6O
#WindowsML #OpenVINO #AI #AIonWindows #Developers
2
2
8
8,189

25 Sep 2025
These new NPUs are amazing. We now need to find the plethora of “must have” apps. If we get this, the market for new PCs should cook. With WindowsML out there, I’m optimistic but not overly optimistic. I want to see it. I personally want to agents on-device and tap into my local data.
25 Sep 2025

Seeing @Snapdragon position the new X2 Elite Extreme versus the comp in terms of NPU performance. 80 TOPS, 5.7x faster than Arrow Lake in Procyon AI (2.2x compared to Lunar Lake). Perf per watt is a big deal too; the main selling point of NPU over other compute options.




5
4
52
11,611

24 Sep 2025
#WindowsAppSDK 1.8.1 (1.8.250916003) has shipped!
This is a servicing release that includes new #WindowsML APIs and critical bug fixes for the 1.8 release.
Release notes: msft.it/6014sqax4
Download package: msft.it/6013sqaxN
#WinUIWednesday
1
10
19
3,020

24 Sep 2025
By @pradeepviswav - Microsoft has announced the general availability of Windows ML, a framework first previewed at Build 2025, to simplify the development of on-device AI applications. #Microsoft #WindowsML #AI neowin.net/news/microsoft-an…
1
3
739


12 Jun 2025
AMD ROCm 7 will be included in Windows, including ONNX-EP and ONNX Runtime, and likely includes WindowsML for GPU acceleration!


1
16
3,816

24 May 2025
🤖⚡ 𝘽𝙪𝙞𝙡𝙙 𝘼𝙄 𝘼𝙣𝙮𝙬𝙝𝙚𝙧𝙚 𝙬𝙞𝙩𝙝 @AMD ROCm™ & @Microsoft ⚡🤖
#for_ai_architects
#for_cloud_architects
#for_solutions_architects
#did_you_know_that @AMD @Microsoft just unlocked a true Cloud-to-Client runway?
Today, let's discover how with AMD ROCm 6.4 you can train frontier models on Azure ND MI300X GPUs, then redeploy the very same code—unchanged—on a Ryzen AI Copilot PC. One stack, zero rewrites, everywhere.
🔧 AMD 𝙍𝙊𝘾𝙢 𝙀𝙫𝙚𝙧𝙮𝙬𝙝𝙚𝙧𝙚
• Unified open-source stack for PyTorch, JAX, SGLang, Megatron-LM
• Day-0 tuned for Llama-4 Maverick, Gemma 3, DeepSeek-V3
• Windows ML ONNX Runtime EP → same operators on WSL & Azure
🚀 𝙈𝙀𝙂𝘼 𝙂𝙋𝙐𝙨 𝙤𝙣 𝘼𝙯𝙪𝙧𝙚
• ND MI300X v5 VM fits DeepSeek-R1 671B in a single node 🌟
• 192 GB HBM per GPU = extended context, richer modalities
• AITER repo drops optimized kernels straight into your pipeline
💻 𝘾𝙡𝙞𝙚𝙣𝙩 𝙎𝙪𝙥𝙚𝙧𝙘𝙝𝙖𝙧𝙜𝙚𝙧
• ROCm on Radeon RX 7900 XTX → up to 48 GB local VRAM
• Ryzen AI Copilot PC runs 70B LLMs fully offline—no RAM swapping
• Windows ML “write once, run anywhere” <> CPUs • GPUs • NPUs
🔑 𝙊𝙥𝙚𝙣 𝙀𝙘𝙤𝙨𝙮𝙨𝙩𝙚𝙢 = 𝙄𝙣𝙣𝙤𝙫𝙖𝙩𝙚 𝙬𝙞𝙩𝙝𝙤𝙪𝙩 𝘾𝙚𝙞𝙡𝙞𝙣𝙜𝙨
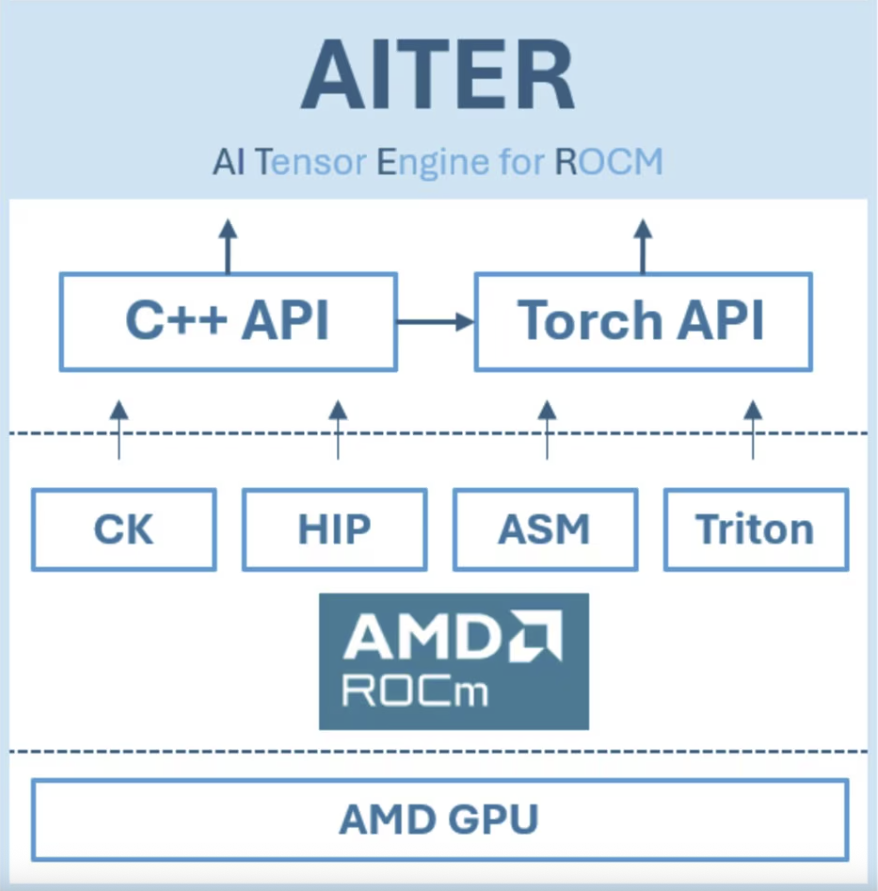
• AI Tensor Engine for ROCm (AITER) = one hub for speed-tuned ops
• Confidential Clean Rooms on Azure keep multi-party data private
• Open docs, contests & tutorials live on the AMD Developer Portal
🛤️ 𝙋𝙞𝙘𝙠 𝙔𝙤𝙪𝙧 𝙁𝙡𝙞𝙜𝙝𝙩 𝙋𝙡𝙖𝙣
(1) Cloud first – train on ND MI300X, inference on the same or down-shift to client
(2) Edge last-mile – distill > quantize > run on Radeon/Ryzen for offline UX
(3) Hybrid loop – stream low-rank updates from PC back to Azure for continuous fine-tuning
Thanks to Anush E. for his blog post:
Build AI Anywhere with ROCm™ Software: AMD and Microsoft Bring Cloud-to-Client Power to Developers
amd.com/fr/blogs/2025/amd-po…
📬 Stay tuned & subscribe
linkedin.com/newsletters/clo…
#favikon #ai #cloud #cloudcomputing #cybersecurity #security #ROCm #AMD #Microsoft #Azure #RyzenAI #Radeon #MI300X #ONNX #WindowsML #HybridAI #LLM #VectorSearch #MLOps #DevSecOps #OpenSource
1
2
71

23 May 2025
Filmora is thrilled to team up with @Microsoft at Microsoft Build to unveil the next era of AI-powered video editing! 🚀 Big thanks to Microsoft for this exciting collaboration. We’re passionate about empowering creators with smarter, more intuitive tools!
Stay tuned for our detailed video reveal!
#FilmoraXMicrosoft #MSBuild2025 #Filmora #Microsoft #AI #MSBUILD #WindowsAIFoundry
#WindowsML #Windows #CopilotPlusPC
1
9
443
20 May 2025
Wondershare Filmora teamed up with @Microsoft at #MSBuild 2025 to unveil the next-gen AI Mate 🎬
🔹 Natural language editing with RAG semantic search
🔹 Offline AI chatbot powered by Phi Silica on Copilot PCs
🔹 Local AI features including Video Enhancer for NPU GPU configurations
Smarter. Faster. More private.
#WondershareFilmora #MicrosoftBuild2025 #AIEditing #CopilotPlusPC #VideoEditing #Wondershare #MicrosoftPartner #CreativeTech #MSBUILD #EmpowerCreators #WindowsAIFoundry #WindowsML #Windows

1
2
8
3,755

20 May 2025
Powder joined Microsoft on stage at #MSBuild 2025!
We showcased how we brought our AI models to Windows using Windows ML — powering real-time video editing for gamers across AMD, Intel & Qualcomm.
Big thanks to the Windows team!
#WindowsML #AIFoundry #AIOnWindows #BYOM #Powder
1
5
449

20 May 2025
RTX向けNVIDIA TensorRTがデスクトップPCのパフォーマンスを2倍向上、すべてのRTX GPUに対応
TensorRTに対応したのはWindowsMLです。
生成AIはとっくに対応しています。
1
1
2
819
19 May 2025
Exciting news! 🎉 Filmora is showcasing new AI experiences powered by @Windows Windows ML and Windows AI APIs this week at #MSBUILD !
Thanks to our partnership with @Microsoft , we’re making video editing faster, smarter, and more intuitive for creators everywhere.
#Filmora #Microsoft #AI #MSBUILD #WindowsAIFoundry
#WindowsML #Windows #CopilotPlusPC
3
2
8
592

19 May 2025
WindowsML is built upon ONNX and gives the flexibility to the vendor to use their preferred EP.
But yea it's much higher layer than DML
4
138