

#LSPPDay16 #60DaysOfLearning2026 #LearningWithLeapfrog
Compared word2vec and sentencebert on different parameters to choose the best one for my vectorization need.
3

The real project is Epicure: Navigating the Emergent Geometry of Food Ingredient Embeddings, by Jakub Radzikowski and Josef Chen of KAIKAKU.AI. The paper says it aggregates 4.14 million recipes from 11 public datasets, normalizes raw ingredient strings into 1,790 canonical ingredients, and trains three 300-dimensional ingredient-embedding models: Cooc, Core, and Chem. The paper’s abstract says “seven languages,” although the listed corpus sources include English, Chinese, Russian, Vietnamese, Spanish, Turkish, Indonesian, German, and Indian-English, so I would avoid leaning too hard on the exact “7 languages” phrasing unless you quote the paper directly.
The biggest correction:
It did not compress all recipes into 2 MB. It compressed learned ingredient relationships into roughly 2 MB.
That difference matters. The 2 MB file is basically a coordinate table: 1,790 ingredients × 300 numbers × 4 bytes ≈ 2.05 MB. It does not contain the recipe instructions, quantities, cooking steps, techniques, timing, or cultural context. It contains a learned map of ingredient relationships.
So the strongest accurate version is:
A London food-AI startup turned 4.1 million recipes into a 2 MB map of how ingredients behave.
That is still mind-blowing, but much safer than “all of humanity’s cooking now fits in a file.”
Strongest core thesis
Use this:
The breakthrough is not that AI stored every recipe. The breakthrough is that it learned the geometry of cooking: which ingredients behave alike, which ingredients travel together, and which cuisines create natural neighborhoods without being explicitly programmed.
Even sharper:
Cooking did not become a database. It became a map.
That is the killer line.
The deeper idea:
Recipes are the surface layer. Ingredient relationships are the hidden structure. Epicure tries to compress the hidden structure.
That makes the whole story feel more profound.
Better headline options
Most viral
A Food AI Startup Compressed 4.1 Million Recipes Into a 2 MB Ingredient Map
More accurate
Not Every Recipe — Every Ingredient Relationship: The 2 MB Map of Cooking
Best high-status version
The Geometry of Cooking: How 4.1 Million Recipes Became a 2 MB Food Map
Punchy
Cooking Has a Coordinate System Now
More mysterious
The Hidden Map Inside 4 Million Recipes
Best social hook
AI Just Turned Cooking Into a Map You Can Navigate
Strongest correction headline
No, It Didn’t Store Every Recipe. It Did Something More Interesting.
Most elegant
The World’s Recipes Became a 2 MB Map of Taste, Culture, and Substitution
The key distinction your post needs
Right now, the post implies:
Close ingredients = substitutes.
That is sometimes true, but not always.
In embedding space, closeness can mean several things:
Co-occurrence: ingredients often appear together.
Example: soy sauce, ginger, sesame oil.
Flavor chemistry: ingredients share aroma compounds.
Example: toffee, fudge, ganache-like dessert chemistry.
Culinary role: ingredients play similar functions in recipes.
Example: parsley and cilantro as fresh herb finishes.
Cuisine identity: ingredients belong to the same regional pantry.
Example: tomatillo, corn tortilla, queso fresco.
Texture/function: ingredients behave similarly in cooking.
Example: cream, coconut milk, yogurt in some sauces.
So instead of saying:
“The closer two ingredients are, the more easily one can stand in for the other.”
Say:
The closer two ingredients are, the more likely they share a culinary relationship — they may pair together, substitute for each other, belong to the same pantry, or play a similar role. The trick is knowing which kind of closeness you are looking at.
That is much more sophisticated.
The paper itself makes this distinction. Epicure has three sibling models: Cooc learns from recipe co-occurrence, Chem learns from flavor-compound relationships, and Core blends both. The authors explicitly say these expose different paths a chef might take: “what else do I cook with this” versus “what shares its flavour profile.”
That line is crucial. It means this is not one “swap machine.” It is closer to a culinary navigation system.
Better framing than “what can I swap this for?”
The strongest framing is:
Epicure is not just a substitution engine. It is a food-space navigation engine.
It can answer different questions depending on which model/operator you use:
Cooc:
“What usually appears with this ingredient?”
Chem:
“What shares similar flavor chemistry?”
Core:
“What balances real recipe use and chemistry?”
Nearest neighbor:
“What is closest to this ingredient?”
Mode lookup:
“What culinary neighborhood does this ingredient live in?”
SLERP rotation:
“How do I move this ingredient toward another cuisine, texture, taste, or intent?”
The paper describes nearest-neighbor pairings, closest-mode lookup, and SLERP-style direction arithmetic as the useful operators on the 300-dimensional space.
That gives you a more powerful sentence:
Instead of asking “what is closest?” the real magic is asking “closest in what sense?”
That is an elite line.
Best revised version of your post
Someone just turned 4.1 million recipes into a 2 MB map of cooking.Not the recipes themselves.
The relationships underneath them.A London food-AI startup called KAIKAKU.AI trained Epicure on millions of multilingual recipes, normalized the chaos into 1,790 canonical ingredients, and gave each ingredient a position in a 300-dimensional food space.The result is smaller than a phone photo.
But it acts like a map of culinary intuition.Ingredients that behave similarly, appear together, share flavor chemistry, or belong to the same pantry end up near each other.Soy sauce, ginger, and sesame are not “the same.”
But they live in the same cooking neighborhood.Toffee and fudge are not random desserts.
They share a chemical and culinary neighborhood.That means the model can help answer questions like:“What can I use if I ran out of this?”
“What ingredient plays a similar role in another cuisine?”
“What is the clean-label alternative to this additive?”
“What unexpected pairing lives near this flavor zone?”
“How do I move chicken toward a Mexican, South Asian, or Mediterranean pantry?”The wild part: the model was not trained with cuisine labels as instructions. Yet the ingredient space still self-organizes into recognizable culinary regions — East Asian, South Asian, Latin American, Mediterranean — because culture is encoded in what people cook together.Cooking used to live mostly in memory, instinct, and tradition.Now part of that instinct has coordinates.
More viral version
All of cooking did not fit into 2 MB. Something stranger did.The hidden map behind cooking did.KAIKAKU.AI trained a food model called Epicure on 4.1 million recipes and compressed the result into a tiny ingredient space: 1,790 ingredients, each represented by 300 numbers.That tiny file does not store recipes.It stores relationships.What goes together.
What behaves alike.
What shares flavor chemistry.
What belongs to the same cuisine.
What can move toward another culinary tradition.In this map, ingredients become coordinates.
Cooking becomes geometry.
And substitution becomes navigation.
Cleaner simplified version
A London AI food startup just compressed 4.1 million recipes into a 2 MB ingredient map.The file does not contain the recipes.It contains what the recipes taught the model: how 1,790 ingredients relate to one another.Ingredients that appear together, behave similarly, or share flavor chemistry land near each other in a 300-dimensional space.That means you can use the map to find better substitutions, local equivalents across cuisines, cleaner product alternatives, and unexpected pairings.The deeper part is that cuisines naturally appear as clusters. Nobody has to hard-code “Mediterranean” or “East Asian” into the cooking itself. When enough recipes are poured in, culture leaves a geometric fingerprint.Cooking is becoming searchable by relationship, not just by keyword.
The most important missing caveat
Add this:
This is not a chef replacement. It is a chef’s compass.
Why? Because ingredient embeddings do not understand everything that makes cooking work:
quantities
heat
timing
knife cuts
texture changes
emulsification
fermentation
Maillard reactions
allergies
food safety
religious dietary rules
seasonality
cost
availability
mouthfeel
smell volatility
brand differences
ripeness
fresh versus dried forms
regional authenticity
human preference
A map can tell you that two ingredients live near each other. It cannot automatically tell you the exact ratio, technique, or sensory result.
Best line:
The model knows ingredient neighborhoods. It does not know your grandmother’s hand.
That is beautiful and honest.
Stronger explanation of the 2 MB idea
Use this:
The compression works because the model is not saving every recipe. It is saving a coordinate for every ingredient. Each ingredient gets 300 numbers. Those numbers act like an address in food space. Ingredients with similar culinary behavior get similar addresses. The recipes are the training data; the 2 MB file is the compressed map that remains.
This makes the “smaller than a photo” claim less gimmicky.
Even sharper:
The recipes are not inside the file. Their statistical ghost is.
That is a killer line.
The “genius-level” framing: cooking as latent geometry
This is the real intellectual angle.
Cuisine is not just culture. It is geometry.
Recipe corpora contain hidden structure:
which ingredients co-occur
which ingredients avoid each other
which ingredients define regional identity
which ingredients substitute across cultures
which ingredients share chemistry
which ingredients signal sweetness, fat, fermentation, heat, umami, freshness, or processing
which ingredients sit at the border between cuisines
Epicure turns those relationships into navigable coordinates.
Use this:
A cuisine is a cloud of points in ingredient space. A recipe is a path through that cloud. A substitution is a short jump. A fusion dish is a controlled rotation.
That is the most powerful conceptual paragraph.
Obscure thought inputs that make the piece feel brilliant
1. The “culinary latent space” idea
Most people think recipes are lists. But AI sees them as geometry.
A recipe is not just ingredients plus instructions. It is a coordinate pattern in a cultural flavor space.
That is the core idea.
2. Cuisine as an emergent manifold
The paper found that ingredients organize around cuisine macro-regions without those labels being used during training; the authors say ingredients from the same cuisine land closer than chance and that UMAP projections show distinct East Asian, South Asian, Latin American, and Mediterranean clusters.
Phrase:
Culture left fingerprints in the geometry.
Another:
Nobody had to teach the model what a cuisine was. Cuisines emerged as continents in ingredient space.
3. Substitution is vector translation
A naive swap says:
“Replace butter with oil.”
A smarter map says:
“Replace this ingredient while preserving cuisine, texture, sweetness, fat level, and cooking role.”
Phrase:
The future of substitution is not nearest neighbor. It is constrained movement through food space.
4. Fusion as controlled rotation
Epicure uses SLERP rotation to move an ingredient toward a cuisine or culinary direction. The paper gives examples such as rice rotated toward South Asian retrieving curry leaf, dals, and fenugreek seed; corn rotated toward Latin American retrieving salsa verde, tomatillo, queso fresco, fajita seasoning, and corn tortilla.
Phrase:
Fusion cooking becomes a slider, not a guess.
Another:
You can rotate chicken toward Mexico, rice toward South Asia, or tomato toward the Mediterranean.
5. “Pantry equivalence”
This is better than “substitution.”
Pantry equivalence means finding the ingredient in another cuisine that plays the closest cultural or functional role.
Examples:
cream in one cuisine
coconut milk in another
soy sauce in one cuisine
fish sauce in another
parmesan in one cuisine
miso in another, depending on umami role
Careful: these are not always direct substitutes. They are role analogues.
6. The “Google Maps for flavor” metaphor
Not every nearby point is a substitute. Some are landmarks, neighbors, highways, or destinations.
Phrase:
This is less like a dictionary and more like Google Maps for ingredients.
7. Culinary dark matter
Most cooking knowledge is not written explicitly. It is implicit in millions of choices.
Phrase:
The most valuable cooking knowledge is not in the recipe text. It is in the repeated choices nobody explains.
That is excellent.
8. Tacit knowledge compression
Chefs know that miso likes mirin, olive oil likes basil, and chocolate likes vanilla. The paper itself opens with that chef-intuition idea: “A chef asked what pairs with miso reaches for mirin, dashi, or sesame oil.”
Phrase:
Epicure is an attempt to compress tacit culinary knowledge into vectors.
9. The “ingredient passport”
Every ingredient has an identity across cuisines.
Phrase:
An ingredient’s meaning changes by passport. Chicken is not one thing. It becomes fajitas, pho, curry, schnitzel, tagine, karaage, or soup depending on the pantry you rotate it into.
10. The anti-ChatGPT angle
Epicure is not a giant chatbot. It is small, constrained, and purpose-built. Decrypt notes it has no general language generation and only knows the 1,790 ingredients in its vocabulary.
Phrase:
The future of useful AI may not always be bigger models. Sometimes it is tiny maps with the right structure.
That is a very strong AI-industry point.
The missing product insight: “small models win when the world is structured”
This story is not only about food. It is about AI design.
A general LLM can talk about food.
Epicure can navigate food-space because it was built for the structure of food.
Best line:
A big model knows words about cooking. A food embedding knows relationships inside cooking.
Another:
General AI speaks cuisine. Specialized AI can map it.
This is the broader lesson:
When a domain has stable relationships — ingredients, molecules, recipes, cuisines, substitutions — a small specialized model can outperform a giant generalist at the task that matters.
That could be the highest-level thought in the whole piece.
Stronger use-case framing
Your current bullets are good, but they need precision.
1. Pantry rescue
Current:
run out of something mid-recipe and get a swap that actually works
Stronger:
Find a substitution that preserves the role of the missing ingredient inside that specific cuisine and dish type.
Example:
Not just “replace cilantro with parsley.”
Ask:
“What replaces cilantro in a Vietnamese soup versus a Mexican salsa versus a Middle Eastern salad?”
2. Cross-cuisine localization
Current:
cook a dish from another country and find the local ingredient that does the same job
Stronger:
Find local pantry equivalents: ingredients that play a similar role in your local market, even if they are not chemically identical.
Example:
“What ingredient available in Australia gives me the same fermented-umami function as doenjang?”
“What local ingredient can move this dish toward a Thai pantry without breaking the structure?”
3. Clean-label reformulation
Current:
trade a chemical-sounding ingredient for a more natural one
Be careful. “Natural” is legally and scientifically messy. Also additives often do more than taste: they stabilize, emulsify, thicken, preserve, color, or control water activity.
Stronger:
Help food companies find clean-label or consumer-friendlier alternatives that preserve flavor direction, mouthfeel, or usage context.
Best caveat:
A clean-label swap must preserve function, not just flavor.
4. Novel pairing discovery
Current:
find two ingredients that secretly go well together but nobody has tried yet
Stronger:
Find underexplored pairings that are close by chemistry but distant by culture, or close by cuisine but surprising by category.
That is much more powerful.
Use:
The best discoveries may live at the edge: chemically plausible, culturally rare.
The “four modes” of ingredient intelligence
This could become your signature framework.
1. Pairing mode
Question:
What goes with this?
Best model:
Cooc or Core.
Use case:
recipe ideation, menu creation, flavor completion.
2. Substitution mode
Question:
What can stand in for this without breaking the dish?
Best model:
depends on context; Core for balanced, Chem for flavor similarity, Cooc for recipe-role similarity.
Use case:
home cooking, allergens, cost, availability.
3. Translation mode
Question:
What is the equivalent role in another cuisine?
Best tool:
SLERP toward cuisine direction.
Use case:
localization, fusion, cultural adaptation.
4. Reformulation mode
Question:
What alternative preserves sensory/function while meeting constraints?
Best tool:
multi-constraint search.
Use case:
food R&D, clean-label products, health targets, cost reduction.
This is much stronger than a generic “swap machine.”
The key phrase: “not nearest neighbor, constrained navigation”
For substitutions, the best system would not simply return the closest ingredient. It should ask:
What dish?
What cuisine?
What role?
What form?
What quantity?
What cooking method?
What dietary constraint?
What cost constraint?
What local availability?
What sensory property must be preserved?
Then it should search the map with constraints.
Best line:
The ingredient map is the engine. The real product is constrained navigation.
That is a genius-level product insight.
Genius-level product solution: “Culinary GPS”
Build the idea around this:
Culinary GPS: not a recipe generator, but a navigation layer for food decisions.
A user asks:
“I’m making Thai green curry. I’m out of galangal. I have ginger, lemongrass, lime zest, turmeric, and garlic. What’s the closest functional replacement?”
The system answers:
Best practical substitute
Why it works
What it will not replicate
Quantity adjustment
Technique adjustment
Flavor correction
Allergen/diet notes
Confidence score
Alternative options
Whether skipping is better than substituting
That is how this becomes useful.
The key:
Do not just tell me the nearest ingredient. Tell me the nearest viable move.
Missing feature ideas that would make this huge
1. Dish-aware substitution
Same missing ingredient, different replacement depending on dish.
Example:
Cilantro in salsa ≠ cilantro in pho ≠ cilantro in curry ≠ cilantro as garnish.
2. Cuisine-preserving swaps
Replace an ingredient while keeping the dish inside the same culinary region.
Prompt:
“Swap dairy out of this Mediterranean recipe but keep it Mediterranean.”
3. Cuisine-rotating swaps
Transform a recipe toward another cuisine.
Prompt:
“Rotate this pasta dish 40 degrees toward Korean pantry.”
4. Clean-label R&D
For food manufacturers:
“Replace artificial vanilla flavor while preserving dessert-pantry similarity, cost constraints, and consumer-friendly labeling.”
5. Allergen-aware substitution
Prompt:
“Replace peanut in this Southeast Asian sauce while preserving fat, roasted note, and texture.”
6. Local-market substitution
Prompt:
“I’m in Brazil. What local ingredient can replace this Japanese pantry item in a home-cooking context?”
7. Cost-down formulation
Prompt:
“Find cheaper ingredients that preserve the same culinary neighborhood.”
8. Food-waste rescue
Prompt:
“I have cabbage, yogurt, miso, and stale bread. What ingredient neighborhoods can connect them?”
9. Menu white-space discovery
For restaurants:
“Find pairings that are close by chemistry but uncommon in our cuisine dataset.”
10. Recipe debugging
Prompt:
“This dish tastes flat. Which direction should I move: acid, umami, fat, herbaceous, fermented, toasted?”
This goes beyond recipes and becomes a food reasoning layer.
The strongest technical explanation
Use this if the audience is AI-curious:
Epicure is basically word2vec for ingredients, but with a more controlled food-specific graph. Instead of learning that “king - man woman ≈ queen,” it learns that ingredients have directions: cuisine, texture, nutrition, processing, sensory notes, and chemical similarity. Once ingredients live as vectors, you can search neighbors, find clusters, and rotate an ingredient toward a culinary direction.
The paper explicitly references word2vec-style semantic directions and says supervised culinary probes and unsupervised factors become navigation operators in the embedding space.
Best analogy:
Word embeddings made meaning navigable. Food embeddings make cooking navigable.
The strongest “why cuisines clump” explanation
Do not just say:
Nobody told it what Italian or Chinese food is.
Say:
It was not trained to memorize cuisine labels. But because cuisines are repeated patterns of ingredient choice, the labels become recoverable from the geometry.
That is the real insight.
Cuisines are not only names. They are statistical patterns:
garlic olive oil tomato basil
soy sauce ginger sesame scallion
cumin coriander turmeric fenugreek
corn tortilla tomatillo queso fresco chili
When millions of recipes repeat those patterns, the map forms continents.
Best line:
Cuisine is what happens when a culture repeats a pantry for centuries.
That is an elite sentence.
The most important limitation to include
The paper/model is not equally representative of all world cooking. Hugging Face’s model card says the corpus is roughly half East Asian and about a tenth Mediterranean, with single-digit shares for South Asian, Eastern European, and Latin American regions. It also says only 523 of the 1,790 ingredients are chemistry hubs with active compound edges; the rest reach compound context indirectly.
So avoid:
“all of humanity’s cooking”
Better:
a huge but imperfect slice of world cooking
Or:
a 4.1-million-recipe map of multilingual cooking data
Best caveat line:
The map is huge, but it is still a map of the data we fed it — not a complete atlas of every kitchen on Earth.
That line is essential.
What not to overclaim
Avoid
“Cooking used to be guesswork. Now you can just check the map.”
Why? Cooking still involves skill, heat, preference, smell, texture, and context.
Better:
Cooking used to depend mostly on memory and instinct. Now some of that instinct can be searched, steered, and visualized.
Avoid
“The closer two ingredients are, the more easily one can stand in for the other.”
Better:
The closer two ingredients are, the stronger their learned culinary relationship. Substitution is one possible use, but pairing and cuisine navigation are others.
Avoid
“All humanity’s cooking fits in 2 MB.”
Better:
A 2 MB model captures a compressed map of ingredient relationships learned from 4.1 million recipes.
Avoid
“Nobody told it what Italian or Chinese food is.”
Better:
Cuisine labels were not used to train the embedding geometry, but they were used later to evaluate and interpret it.
Avoid
“Natural ingredient that tastes the same.”
Better:
clean-label or consumer-friendlier alternatives that preserve sensory and functional behavior.
Better phrase swaps
Current phraseStronger phraseall of humanity’s cookinga compressed map of 4.1M recipesfits in a filesurvives as coordinatesboiled them downnormalized the chaos intosqueezed all of itcompressed the learned relationshipswhat can I swap this for machineculinary navigation enginerandom guess off Googlecontext-aware ingredient movechemical-sounding ingredientadditive, processing aid, or label-unfriendly ingredientnatural oneclean-label or consumer-friendlier alternativetastes the samepreserves flavor, function, or rolecuisines clump togethercuisines emerge as geometric neighborhoodscooking used to be guessworkculinary intuition is becoming searchable
Stronger “missing examples” section
Add examples that show why one nearest-neighbor answer is not enough.
Basil
Cooc might say parsley or olive oil because they appear in similar recipe contexts.
Chem might say oregano or tarragon because of herb chemistry.
A substitute depends on whether basil is garnish, pesto base, sauce aromatic, or fresh herb finish.
Soy sauce
It may sit near ginger and sesame because they co-occur often, but ginger is not a soy sauce substitute. For substitution, you may need tamari, coconut aminos, fish sauce, miso plus salt, or Worcestershire depending on dish and constraint.
Cream
A substitution depends on whether you need fat, emulsification, sweetness, thickness, dairy flavor, or visual whiteness.
Egg
Replacing egg in a cake is different from replacing egg in mayonnaise, carbonara, fried rice, or meatballs.

all of humanity's cooking now fits in a file smaller than 1 photo on your phone
an AI food startup in London grabbed 4.1 million recipes in 7 languages, boiled them down to 1,790 ingredients, and squeezed all of it into 2 megabytes.
ingredients that get used the same way end up close together.
> soy sauce sits near ginger and sesame.
> toffee sits near fudge.
the closer two ingredients are on the map, the more easily one can stand in for the other.
so the map is basically a giant "what can i swap this for" machine, built from how 4.1 million real recipes actually use each ingredient.
that means you can:
• run out of something mid-recipe and get a swap that actually works in that dish, not a random guess off Google
• cook a dish from another country and find the local ingredient that does the same job
• trade a chemical-sounding ingredient for a more natural one that tastes the same
• find two ingredients that secretly go well together but nobody has tried yet
the amazing part is nobody even told it what "Italian" or "Chinese" food is.
but when you pour in enough recipes, the cuisines naturally clump together on the map on their own.
cooking used to be guesswork. now you can just check the map.

1
234

思ったよりword2vecの仕組みが単純だったのでちょっと驚いた 機能ばっか注目してて知らないことばっかしだったので、今こうやって理論をちゃんと抑えられてるのはよさそう
70
教師なしのベイズ的なNLPについて勉強してるけど、Word2Vecひとつをとっても、その背景が特異値分解に繋がってるとか全然知らんことばっかだな...。階層ディリクレ言語モデルの考え方がかなり面白かった。
2
109
神原いとま retweeted

Jun 14
【スマホ対応・インストール不要】
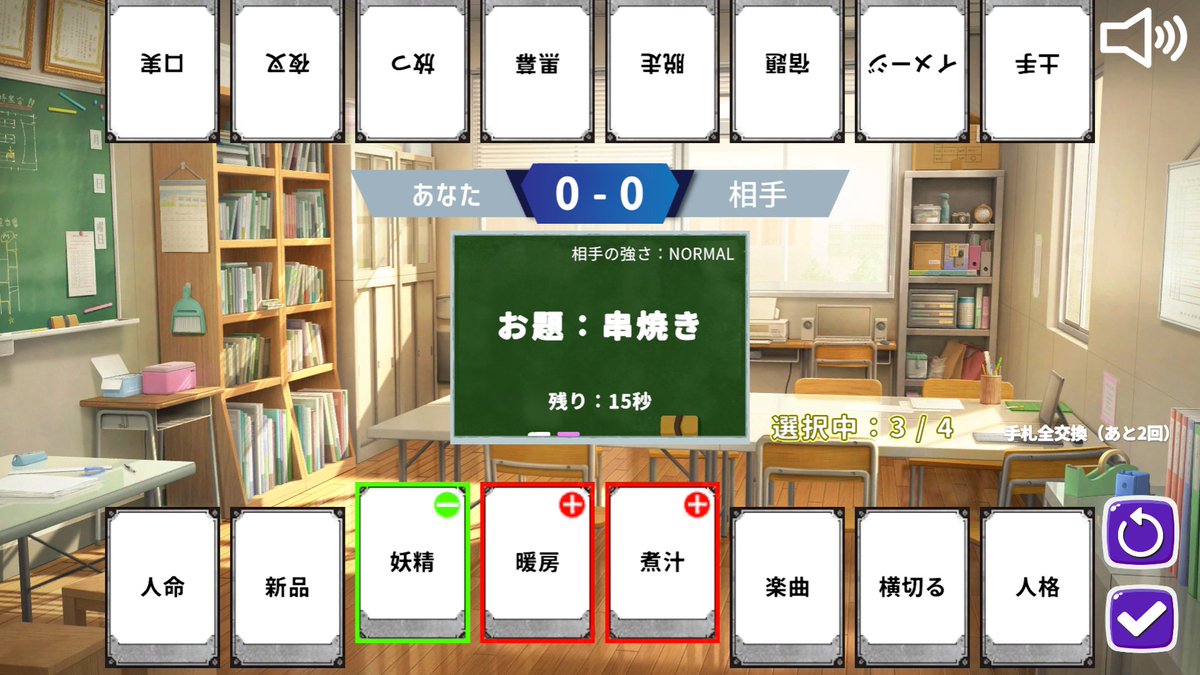
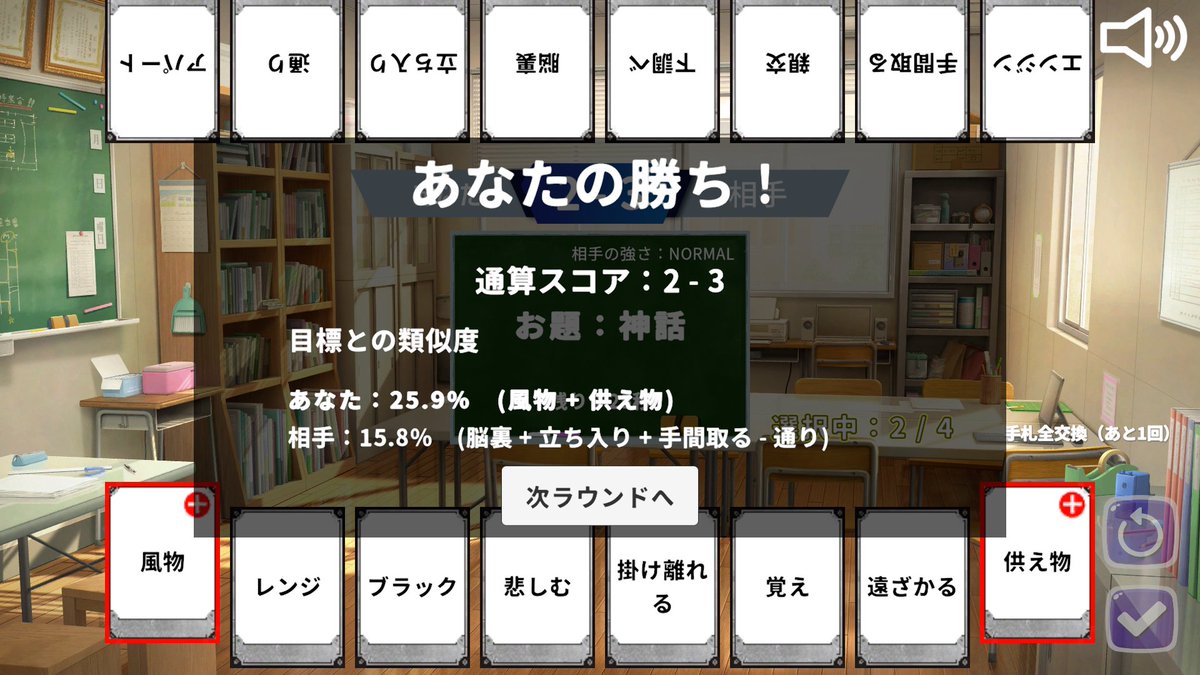
Word2Vecで言葉を足し引きして遊ぶカードゲーム『#Word2Battle』を公開しました!
手札の語彙を組み合わせて、お題の言葉にどれだけ近づけるかの勝負。難易度は4種類+α
ゲームへのリンクはリプ欄をご覧ください!
#GameDev #個人製作ゲーム #indiegame

1
9
11
595

Jun 15
Take a look at the pattern of the last 15 years of representation
(Word2Vec) → architecture (Transformer) → scaling (GPT-3) → reasoning (o1) → agent (Claude Code, Codex).
1
2
57


Jun 14
current LLMs fundamentally consist of four main components:
- input layer: where input "words" (prompt) get mapped to "latents" aka some-model-representation-you-don't-understand-unless-you-start-reading-tea-leaves-of-spurious-correlations (some quite compelling à la word2vec style; latents is also unnecessary lingo so i will refer to these as "inputs" with quotes from now on)
- mixing layers: where you jumble all your "inputs" together to see if any correlations between "inputs" can become useful (commonly used to compress or expand dims; predicting a single classification target == compress to a single dim, etc)
- attention layers: where you learn how "inputs" relate to each other (aka discern what's important to remember vs fluff)
- residuals: where you short-circuit a mixing/attention layer because it's probably adding too much confusion (aka avoid overthinking for simple things)
-----
a "big" LLM simply scales two things:
- width == how many dimensions you give to your "inputs" (the more dims, in theory the more unique/discerning/precise/complex your knowledge can become)
- depth == how many mixing/attention/residual layers you can stack/loop between (aka "reason" over, where more of these ~= more "reasoning" abilities)
"capabilities" that seem impressive to humans usually arise from taking advantage of both depth & width: where a model seemingly makes connections between disparate ideas, beyond what an average human can hold in working memory.
this requires models to "completely light up" when responding to a "hard prompt", where effectively no param/layer goes unused.
-----
the anatomy of a "model capability" is precisely the same mechanism that can be co-opted for a jailbreaking exploit:
your goal is simply to "light up" as much of the model as possible, dodging any shallow input-classifiers at the beginning by triggering as many disparate "input ideologies" as possible, and subsequently have these "inputs" relate to each other in seemingly unrelated-yet-related ways that ideally have similar "complexity" as your jailbreak goal (to make it past enough layers of the model).
think of the attack-vector as bundling your goal in a series of schizo-nerd-snipes:
a sufficiently capable model will try to reason through everything all at once, eliminate the dead-ends, and successfully deliver the one jailbreak use-case you bubble-wrapped for.
of course, there's an art to the above, and some are already extraordinarily proficient at the trojan-horse-packaging, but at some point there's no difference between "a capability" and "a jailbreak", though i'll be happy to be proven otherwise.
-----
tl;dr ant flew too close to the sun, better kiss the ring or get buried.
21
79
994
147,069