
5 hours a week regained by eliminating manual report formatting.
Lara, tech leader at HelpDesk Realty, on why broken processes nullify AI ROI. Automation adds value only after you fix your operational friction.
Full episode: thectoshow.com
#AI #Operations #Productivity #Workfl
4
Metaverse retweeted

Just wrapped up a super insightful workshop on agile project management! Learned actionable tips to streamline team workflows and cut down on bottlenecks. Grateful for the expert facilitators and amazing peers—can’t wait to apply what I’ve learned this week!

1
2



Mr.Yao(青云-志) retweeted

Weekly Dev Update
Short drama production workflow has entered a new round of internal testing.
Optimized the workflow’s stability
Improved handling logic for certain exceptional scenarios.

3
1
13
2,627
jralmarales retweeted

Jun 14
The AI model market is no longer just a race for the smartest model.
It is becoming a race for the most efficient workflow.
For the last two years, people compared models like sports teams: GPT vs Claude vs Gemini, open vs closed, US vs China, benchmark vs benchmark.
That made sense when AI was mostly a chatbot.
But coding agents, research agents, long-context workflows, and automation are changing the game.
The real question is no longer:
“Which model is best?”
The better question is:
“Which model should do which job?”
Because serious AI work is not one prompt. It is a chain: reading files, summarizing context, planning, writing code, debugging, calling tools, retrying, and making a final judgment.
Once you see AI work this way, the market looks very different.
Frontier models still matter. GPT-5.5, Claude Opus, Gemini Pro, and Fable-class systems are still valuable when you need deep reasoning, final review, reliability, and the last 10% of quality.
But the first 90% of the work is starting to move elsewhere.
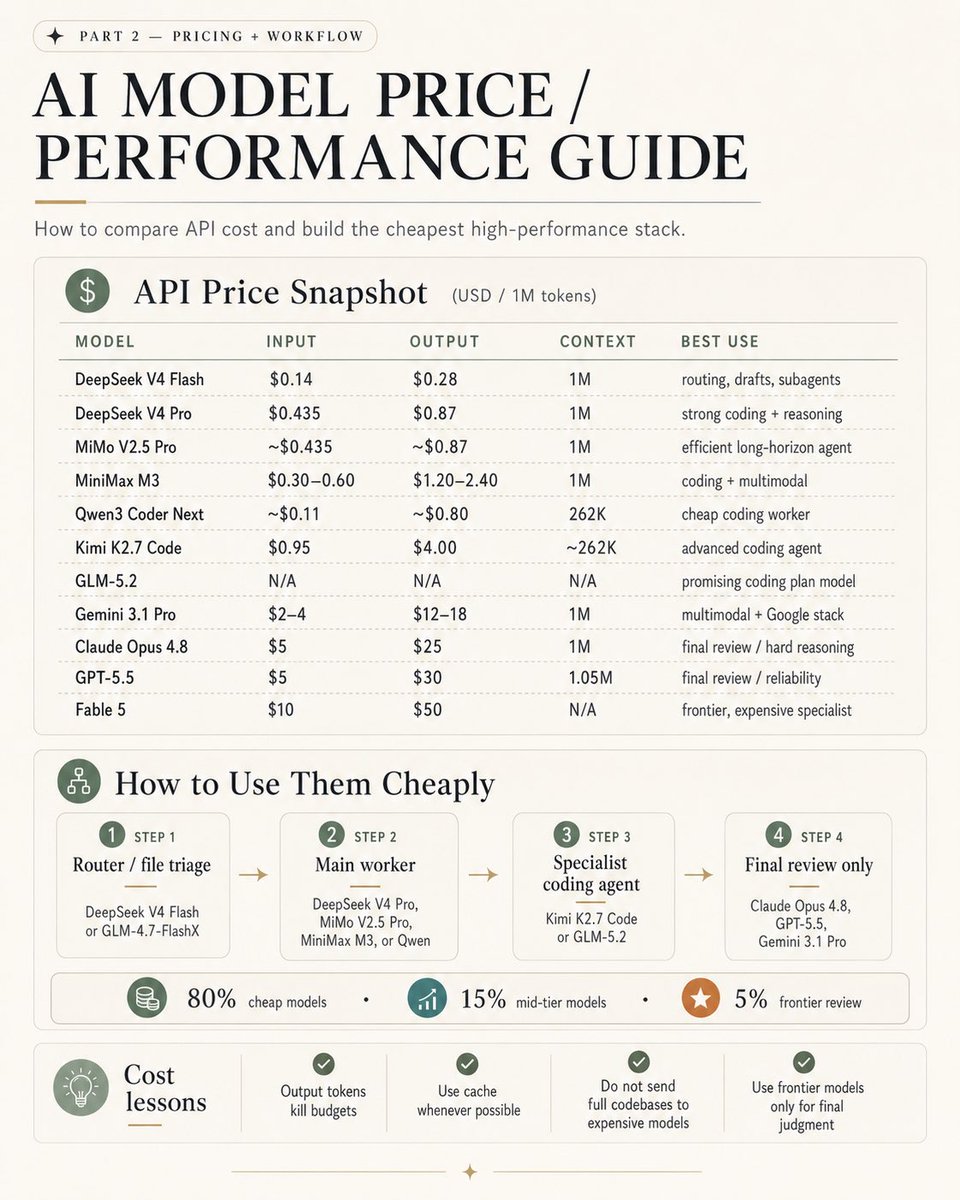
That is where DeepSeek V4, MiMo V2.5 Pro, MiniMax M3, Qwen, Kimi, and GLM become strategically important.
Not because they are always “smarter” in the abstract, but because they are becoming good enough to do most of the actual labor at a much lower cost.
And in software, “good enough at 5–20x cheaper” is how defaults change.
The old AI stack was simple:
Use the strongest model for everything.
The new AI stack is different:
Use cheap models by default.
Escalate only when needed.
Use frontier models for final judgment.
Most people still do the opposite. They use premium models for simple rewrites, send huge contexts to expensive models, and ask frontier systems to do summaries, drafts, formatting, and routine coding tasks.
That is like hiring a senior architect to move furniture.
It works, but it is financially insane.
The hidden killer is output tokens.
Everyone compares input pricing because it is easy to read. But output is where budgets quietly die.
A model that talks too much, loops too often, or makes unnecessary tool calls can become expensive even if its input price looks cheap.
This is why the best agent model is not always the model with the highest benchmark score.
In agentic workflows, efficiency is intelligence.
Long context has the same problem.
A 1M-token window is powerful, but it should not become an excuse to dump an entire codebase into an expensive model.
Long context is not a substitute for architecture.
The smarter pattern is:
retrieve → compress → route → solve → verify.
If your workflow depends on constantly sending everything to the most expensive model, you do not have an AI system.
You have a very expensive search bar.
My current view: DeepSeek V4 Pro / Flash looks like one of the strongest value stacks. MiMo V2.5 Pro has one of the most interesting open-model trajectories. MiniMax M3 is compelling for long-context and multimodal workflows. Qwen remains a strong cheap coding-worker candidate. Kimi K2.7 Code is interesting for advanced coding-agent work. GLM-5.2 is worth watching closely.
Frontier models still matter when the cost of being wrong is high.
But the market is becoming modular.
The best AI system will not be one model.
It will be a portfolio: cheap workers, strong specialists, and one expensive judge.
My rule of thumb:
80% cheap models.
15% mid-tier models.
5% frontier review.
The winners will not be the people who always use the most powerful model.
The winners will be the people who know exactly when not to.
The default workflow is changing from “use the smartest model” to “use the cheapest model that can safely do the job.”
That shift is much bigger than most people realize.


Jun 13

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

1
1
5
345
hoon retweeted

Jun 8
Most important thing I’ve found is self-verification dynamic workflows prompted with something like “use a workflow to test the result e2e in a browser using claude in chrome mcp. Especially look for edge cases and ui issues”
2
4
89
6,662
Alina 🩵📖✨ retweeted

Jun 13
This is the real pain, isn't it?
You build your business on a model and in an instant you lose your entire company's workflow...
No one will trust US AI now for enterprise.
Jun 13

Well this is massive:
- Every non-US company sees how they can be cut off from US vendors with a snap of a finger. Non-US vendors getting free advertisement
- What does this mean for US AI labs’ offices and employees outside the US? Reads pretty draconian
What a mess
1
2
112