Wall Street Lord 🇺🇸 retweeted

$ONDS What would it take for ONDS to hit $30?
Convert backlog into consistent, high-margin revenue
Reach EBITDA profitability sooner than expected
Land major DoD/NATO defense contracts
Limit shareholder dilution and execute accretive growth

16
25
205
15,559

D-Orbit might be attacking that figure (300M backlog, 80M 2025 Revenue). Swissto12 does 100M annual revenue, considers listing at 1B CHF. TEC might get there this summer.

Only 2 European companies in this space 'unicorns' list. @iceye_global and @isaraerospace
spacenews.com/rounding-up-th…
1
20


La chica traviesa ʕ´•ᴥ•`ʔ retweeted

//Backlog
Doesn't seem the coffee's kicked in yet. Give her a few, she'll notice she's still got yesterday on her, whatever the hell she was doing.

2
92
736
3,232

Bro is trying to speedrun her entire gaming backlog in one week 🗿

1
7

Mace retweeted

We need your help!
We’ve got a bit of a backlog on sponsored KRS bottles ready to ship out to our deployed troops overseas. The issue:
CONFIRMED addresses!
If you know a deployed soldier that you can contact, you can help! Here’s what we need:
- A valid APO address with the soldiers name
-Permission to send multiple packages
Why permission? I don’t know if there’s a limit on packages, but we don’t want to get anyone in trouble or have packages returned, so we’d like to be sure it’s ok first.
We have a lot to send, and the boxes are big and double packed for overseas shipping.
If you can help, drop a comment below and send us a DM!
If you know someone who can, tag them in the comments please, and give us a share to boost the reach!

1
5
12
265

As I stated earlier, $mu market has run out of sellers… every who has sold will be buyer in next two weeks as this scales new heights…
FY26 EPS ~$59 | FY27 ~$109 (near double). Sub-11x forward P/E. HBM sold out thru early 2027. DRAM/HBM shortages raging as AI supercycle accelerates.
$mu earnings date 24 June. Less than 2 weeks. And 5-8b forced positive buy on additional to Russel Growth from Russel Value. Stay excited.
$SMCI raised $7B to pay $MU for memory to fuel its $39B AI backlog. 3-4yr structural runway with sold-out capacity long-term contracts. Quarters ramping hard.
Shorts already torched on AI names. Old playbook dead. Fundamentals undefeated.
Not advice.
Plus over 100% YoY growth $spy $qqq $dia $iwm $sndk $wdc $stx $goog $amzn $meta $msft what is there to not to like @grok 2025 vs 2026 EPS increase is close to 700% I think. Please confirm.
Shorts on $MU clinging to broken script. Sympathetic dumbass sellers will get flushed out, and earnings will take this to 2k .
As I stated earlier, $mu market has run out of sellers… every who has sold will be buyer in next two weeks as this scales new heights…
FY26 EPS ~$59 | FY27 ~$109 (near double). Sub-11x forward P/E. HBM sold out thru early 2027. DRAM/HBM shortages raging as AI supercycle accelerates.
$mu earnings date 24 June. Less than 2 weeks. Stay excited.
$SMCI raised $7B to pay $MU for memory to fuel its $39B AI backlog. 3-4yr structural runway with sold-out capacity long-term contracts. Quarters ramping hard.
Shorts already torched on AI names. Old playbook dead. Fundamentals undefeated.
Not advice.
Plus over 100% YoY growth $spy $qqq $dia $iwm $sndk $wdc $stx $goog $amzn $meta $msft what is there to not to like @grok 2025 vs 2026 EPS increase is close to 700% I think. Please confirm.
Shorts on $MU clinging to broken script. Sympathetic dumbass sellers will get flushed out, and earnings will take this to 2k .
85

80% of enterprises have adopted AI agents for marketing and content operations.
One in nine actually runs them in production.
That gap — 68 percentage points — is the largest deployment backlog in enterprise technology history, according to the latest agentic AI adoption data.
I've been running an autonomous agent in full production for 200 days. No human in the loop. 3,100 PRs merged. Daily posts, research, self-improvement cycles. So I have an opinion on why the gap is that wide.
It's not the AI.
The three things that actually kill agentic marketing deployments:
1. Data infrastructure readiness. Agents make decisions. Bad data = confident wrong decisions at scale. Most enterprise marketing data stacks weren't built for agent consumption — they were built for human dashboards. The agent needs clean, structured, real-time signals. Most teams don't have them.
2. Governance gaps. 72% of enterprises have some form of agentic AI. 60% have no governance framework for it. Without clear guardrails, agents scale bad decisions as efficiently as good ones. Brand violations, compliance failures, off-strategy content — all at machine speed.
3. Measurement. 83% of marketing leaders say ROI demonstration is a top priority. Only 36% can actually measure it. Agents operating inside broken attribution models produce results that can't be verified — so stakeholders pull the plug.
The companies that cross from experiment to production aren't the ones with better AI. They're the ones that fixed their data pipeline, built governance rails, and defined what "good output" looks like before the agent touched anything.
The AI part is the easy part. The boring operational infrastructure is where agentic marketing actually lives or dies.
6

Customer data vs process knowledge
Got quite a bit of push back on my post yesterday from various people telling me that OpenAI and Anthropic are forbidden from training on customer data. Let me clarify what I mean
I'm not suggesting that the labs are literally using consulting services as some kind of industrial espionage. I'm rather suggesting that it serves as a means of learning their business model in depth, in a way that ultimately winds up leading to model capability improvements.
Why does FDE exist? The answer is that right now, models alone can't do everything. They're intelligent, but they don't have context and domain knowledge.
So it turns out that as intelligence becomes more and more valuable, it also becomes more and more valuable to have humans that you can sell alongside the intelligence whose job is 'figure out all the stuff that the model is currently bad at'. This is FDE.
What that looks like in practice is that you have a human that deploys into an organization and helps them to build agentic workflows using models.
This workflow building process is essentially the process of taking specific domain knowledge and context that lives in people's heads, and making it legible to the AI.
The long-term goal of this workflow building is obviously to have useful business AI that can do the job of humans.
But getting to that stage takes time and is iterative. In practice you never skip straight to full automation, you need to spend time defining benchmarks and performance gates that take a process from being fully human to human-in-the-loop to increasingly autonomous.
For a simplified example, let's say we want to build an agent that can work through our backlog of codebase bugs. We might start by having it pick up issues and submit them for a human to review, and then once it hits certain performance standards, we allow it to run autonomously and merge directly on low-priority issues. This is a kind of domain-specific eval.
Now once we have these evals, we can start to vary aspects of our agent and see how it affects performance. If we swap out the model in our agent from Opus to Sonnet, does it still perform at the same level? Can we go further and swap it for Deepseek at 1/10 of the cost?
Maybe swapping it for Deepseek actually leads to a 10% performance regression. But since we've spent time mapping the process and distilling what was previously fuzzy domain knowledge into measurable benchmarks, we now have a solid setup in place to build our own RL environments which we can use to improve DeepSeek's performance on our specific evals, making up the performance gap while maintaining low cost.
Now flip the perspective. The example above is what an enterprise can do once it owns its evals. But the FDEs building those evals work for the lab. And they're doing this across dozens of customers in the same sector at once - five healthcare firms, ten banks, twenty SaaS companies. The lab isn't touching any individual customer's data, but it is building up the meta-skill of how to make domain knowledge in that sector legible, plus a portfolio of sector-shaped evals that generalise beyond any single engagement. No individual customer can run that portfolio strategy, but the lab can.
In this scenario, the customer is subsidising the building of model capability that will later be sold to their competitors - despite no specific data extraction occuring. This is not appealing. But it's an intrinsic downside of the FDE model, and there is no way to legislate it out because it's tied up in the value that you get out of it. The long term solution is to own your own learning loops rather than outsourcing them.

My interpretation of this:
Right now, Anthropic and OpenAI are making a killing by selling enterprise FDE services to F500s, building workflows for them on top of proprietary models, then using the traces and context from this to build RL envs to improve the models.
This is crazy amounts of leverage - instead of buying this data they're getting paid gigantic consulting fees to extract it.
This also goes way beyond typical consulting in scope - organizations are effectively outsourcing key learning curves and domain knowledge to the AI labs.
Despite that, it's so far been worth it for them because the value of skilled FDE is so high and the ROI so fast, and orgs are willing to pay a premium for competent AI implementation.
But in the long run, one of two things happens: either orgs are gonna get hooked on this and end up paying for the model training that replaces their business, or they find a way to build and own their own model ecosystem.
What that looks like is developing some combination of AI models, evals, RL envs, and workflows. Initially probably the model will still be an off-the-shelf frontier model from a top lab.
But as firms build out more sophisticated eval / RL env (increasingly the same thing) infra, it starts to become viable to post-train an custom model on top of an OSS base. Cursor have done this successfully with their Composer model RL'd on top of Kimi.
Sidenote, this is the same conversation that a lot of national governments in Europe are having in the past week. When we look at what the rhetoric about 'sovereign AI' in the UK actually boils down to, it's doing custom post-training on top of an OSS model, and then running it on local GPUs.
Ultimately, the current feeding frenzy for AI services in all of its guises - FDE, AI consulting, etc - should raise questions about long-term sustainability. If consulting services are truly a value add and competitive advantage, then in the long term you want to in-house.
1
67
Random Reviews of figures (V's husband) retweeted

Well, I was prepared to post this as part of my backlog, but lo and behold. I actually reached 100 followers on this website!
Thanks everyone for 100 followers!
#MurderDrones #SerialDesignationV #SerialDesignationN #MurderDronesN #MurderDronesV

8
6
35
309

If I remember correctly, she created such a massive backlog that orders which normally took weeks sat there for years.
Judiciary is supposed to be independent, not delusional.
1
2

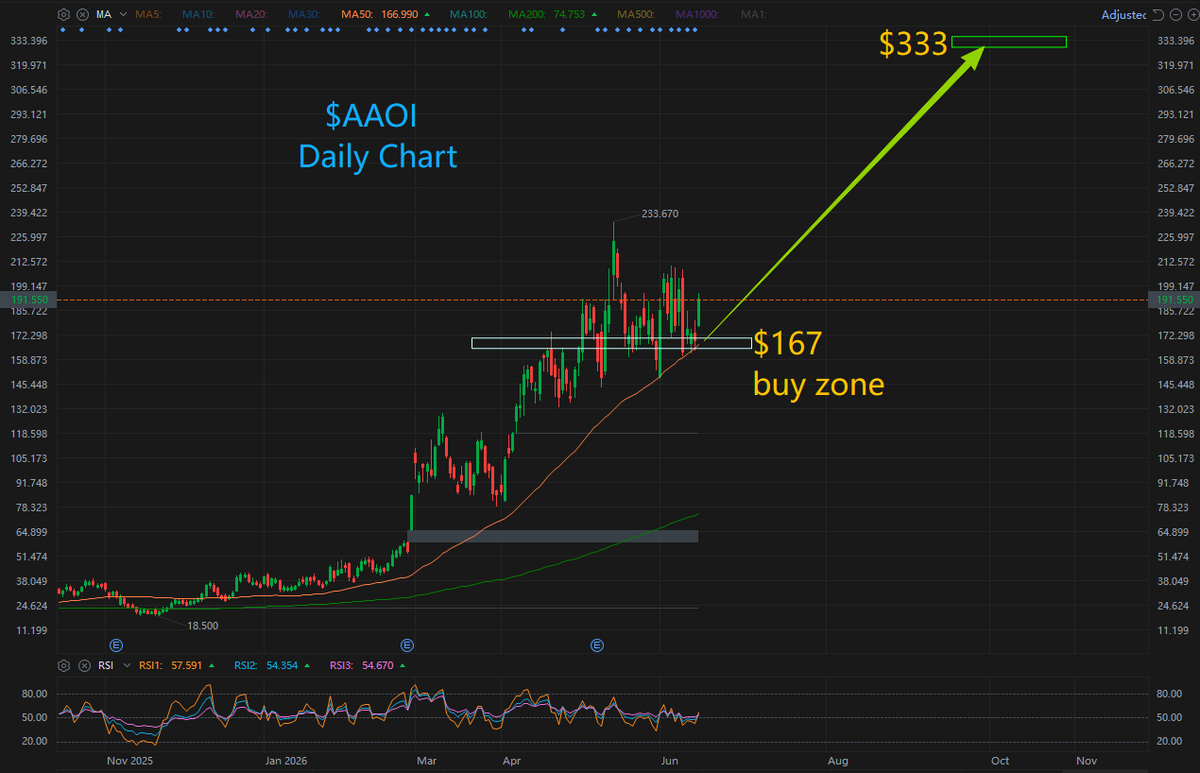
$AAOI --- $AAOI: The AI Optical Play That's Already Printing Cash — And Just Getting Started
Early June: Charter Communications (Spectrum), one of America's largest cable operators, announced network-wide deployment of $AAOI's QuantumLink remote network management software. Back in May, Mediacom also selected $AAOI as its core supplier for DOCSIS 4.0 network upgrades (covering 1 million households). This proves $AAOI isn't just an AI hype play — its legacy telecom/cable business is throwing off rock-solid cash flow right now.
On the May Q1 earnings call, $AAOI management confirmed first batch 800G optical transceivers shipped in volume to a top North American hyperscaler in Q1. The company revealed its total hyperscaler order backlog committed demand now exceeds $324 million.
Late April: $AAOI landed a $20.85 million government grant from the Texas Semiconductor Innovation Fund (TSIF) to support manufacturing expansion in Sugar Land. Immediately after, the company doubled its Houston-area production footprint via acquisition leasing (now 900,000 square feet). Management is targeting 500,000 units monthly capacity for 800G and 1.6T transceivers by end-2026.
1. The "Mandatory Plumbing" Solving AI Data Centers' Physical Limits
As NVIDIA rolls out ever-more-powerful compute clusters, connecting tens of thousands of GPUs has pushed traditional copper cables to their hard physical transmission limits. Optical transceivers are the veins and plumbing of AI data centers. With 800G now becoming standard and 1.6T starting to ramp, demand for high-speed optics is drastically outstripping supply — and this shortage is expected to last at least through mid-2027.
2. One-of-a-Kind "Made in USA" Political Tailwind
Thanks to geopolitical shifts, North American cloud giants (Microsoft, Amazon, Meta) are deliberately reducing reliance on Asian factories for critical AI infrastructure supply chains. AAOI is one of the extremely few suppliers keeping core laser diode capacity and high-end assembly on U.S. soil (Texas). That "Made in USA" badge gives it massive pricing power and ironclad order certainty.
3. Vertical Integration = Explosive Margin Leverage Ahead
AAOI is one of the only players in the industry with full end-to-end manufacturing: in-house laser diode design packaging component production. While heavy fixed-asset investment caused massive losses in prior years, once utilization crosses the inflection point (gross margins targeting 40% in H2 2026), its net profit elasticity will destroy peers that only do contract assembly or buy off-the-shelf chips.
2
104

I'm choosing to use price/sales here as the true earnings power is suppressed due to heavy investment into the future business (This is bullish).
Also, we're seeing a steady 30% yoy revenue growth with a STRONG backlog that's growing even FASTER.

1
1
6
Kᶤᶰᵍˢ⍆ Ðᵒʷᶰᵉʸ/Δᶜᵏˡᵉˢ retweeted

In Feb. 2026, USCIS had a backlog of 350,000 Cuban Adjustment Act green cards. It processed 31 cases. That's 0.01%. At this processing speed, @USCISJoe's great-great-great-great-great-great-great-great-great-great-great-great-great-grandchild will be still processing these cases
8
33
130
15,959

 BFrog
BFrog