
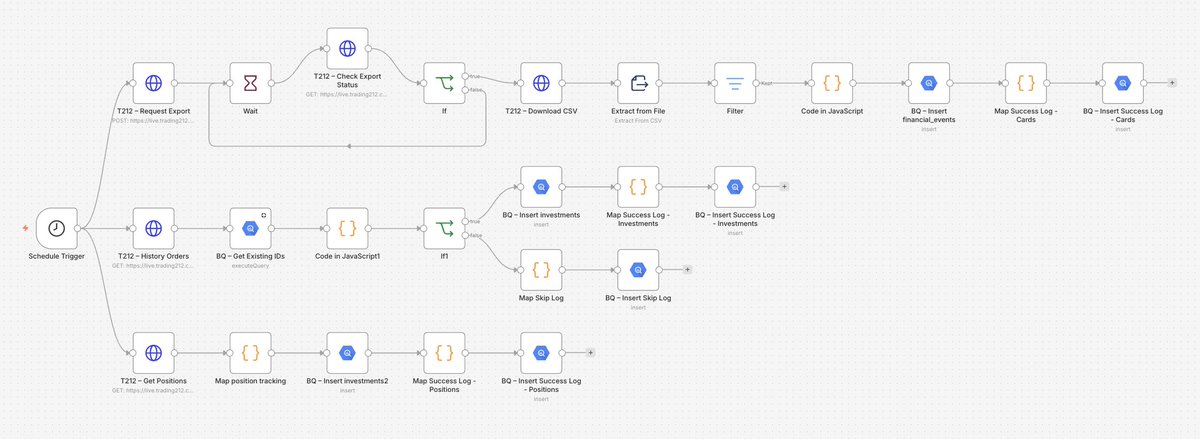
I use #trading212 heavily for investing and payments.
I built myself an #n8n workflow through #Docker to budget and monitor my spending & trade earnings.
It extracts and normalises data from #t212 to #bigquery.
#aiagent #fintech #ladydebug
4

Data Engineering becomes easier when you stop learning tools randomly.
SQL.
Python.
Spark.
Airflow.
Snowflake.
Kafka.
Cloud.
All of them matter.
But they only make sense when you understand the system behind them.
A real data engineering roadmap is built in layers.
𝗣𝗿𝗼𝗴𝗿𝗮𝗺𝗺𝗶𝗻𝗴 𝗙𝗼𝘂𝗻𝗱𝗮𝘁𝗶𝗼𝗻𝘀
SQL, Python, Bash, Git, APIs, and data structures.
𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲𝘀
PostgreSQL, MySQL, MongoDB, Cassandra, data modeling, and query optimization.
𝗗𝗮𝘁𝗮 𝗪𝗮𝗿𝗲𝗵𝗼𝘂𝘀𝗶𝗻𝗴
Snowflake, BigQuery, Redshift, star schema, snowflake schema, and OLAP systems.
𝗗𝗮𝘁𝗮 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲𝘀
ETL, ELT, Airflow, Dagster, Prefect, and workflow orchestration.
𝗕𝗶𝗴 𝗗𝗮𝘁𝗮
Hadoop, Spark, Databricks, Hive, distributed storage, and parallel processing.
𝗦𝘁𝗿𝗲𝗮𝗺𝗶𝗻𝗴 𝗦𝘆𝘀𝘁𝗲𝗺𝘀
Kafka, Flink, Spark Streaming, event-driven architecture, CDC, and real-time analytics.
𝗗𝗮𝘁𝗮 𝗤𝘂𝗮𝗹𝗶𝘁𝘆
Validation, deduplication, lineage, Great Expectations, monitoring, and alerting.
𝗖𝗹𝗼𝘂𝗱 𝗗𝗮𝘁𝗮 𝗦𝘁𝗮𝗰𝗸
AWS, Azure, GCP, S3, lakehouse architecture, and data lakes.
𝗔𝗻𝗮𝗹𝘆𝘁𝗶𝗰𝘀 𝗟𝗮𝘆𝗲𝗿
Power BI, Tableau, Looker, dbt, metrics layer, and business intelligence.
𝗙𝘂𝘁𝘂𝗿𝗲 𝗼𝗳 𝗗𝗮𝘁𝗮
Data Mesh, AI-native pipelines, vector databases, real-time AI analytics, and autonomous data platforms.
The goal is not to memorize every tool.
The goal is to understand how data moves from source to insight.
Learn the tools.
Understand the systems.
Build the pipelines.
Own the impact.
Save this master tree if you are building your data engineering roadmap.

2
5
15
500


أيام الدراسة كنا بنتفرم من ال course projects لانه مكنش مشروع واحد فقط، من اول سنة تانية كانت المشاريع بتتحدف علينا يمين وشمال، حقولك على الكلام اللي فاكره من الدكاتره اللي انقال لي زمان:
عشان تجيب فكرة مشروع تخرج "جامدة" وتطلع برة الصندوق المكرر، لازم تبعد عن الأفكار التقليدية (زي سيستم إدارة مستشفيات أو تطبيق بيع وشراء عادي) وتركز على تجميعة بين حاجة السوق الحقيقية والتقنيات الجديد
عشان الفكرة تطلع بـ Architecture قوي وتلفت نظر الـ Tech Leads والشركات الكبيرة، دلوقت فيه أفكار مشاريع متوزعة على مجالات الـ Data Engineering، الـ Systems، والـ AI، ومبنية على مشاكل حقيقية في السوق:
1. الـ Real-Time IoT Data Pipeline لـ Smart Grids
الفكرة:بناء Pipeline متكامل يستقبل Streams ضخمة من البيانات اللحظية الجاية من Smart Meters (زي عدادات البيوت الذكية، أنظمة الطاقة الشمسية، أو مستشعرات الفلترة والمياه)، وتحليلها لحظياً للتنبؤ بالاستهلاك أو كشف الأعطال.
📌الـ Tech Stack المقترح:
- الـ Ingestion عن طريق Kafka أو Redpanda.
- الـ Stream Processing باستخدام Apache Flink أو Spark Streaming.
- تخزين البيانات في Time-Series Database زي TimescaleDB أو InfluxDB.
- الـ Visualization وعرض الـ Metrics عن طريق Grafana.
2. الـ Agentic AI Platform لمراجعة العقود الهندسية والإنشائية
📌 الفكرة: بناء نظام ذكي مخصص للشركات اللي بتدير مشاريع ضخمة (زي شركات المقاولات أو الـ Real Estate)، بحيث يرفعوا عليه العقود، المقايسات، ودفاتر الشروط، والـ Agents تشتغل مع بعضها لمراجعة الأوراق دي وتحديد نسب المخاطرة أو الأخطاء في المواصفات.
📌 الـ Tech Stack المقترح:
- الـ Framework الأساسي لبناء الـ Agents والـ Workflows المعقدة هو LangGraph أو CrewAI.
- تطبيق الـ Advanced RAG باستخدام Vector Databases زي Pinecone أو Milvus أو Chroma.
- الـ LLMs عن طريق APIs لـ OpenAI أو استخدام Open-Source Models زي Llama 3 باستخدام Ollama.
3. الـ Automated FinOps Dashboard للـ Cloud Infrastructure
📌 الفكرة: مشروع بيحل مشكلة بتعاني منها كل الشركات الكبيرة حالياً، وهي مصاريف الـ Cloud العالية. السيستم بيعمل Ingestion للـ Cost Metrics والـ Usage Logs من منصات زي AWS أو Google Cloud، وبيستخدم خوارزميات لمعرفة الـ Idle Resources وتقديم توصيات أوتوماتيكية لتقليل التكلفة.
- 📌 الـ Tech Stack المقترح:
- سحب البيانات عبر الـ Cloud APIs ووضعها في Data Warehouse زي Snowflake أو BigQuery.
- عمل الـ ETL/ELT Pipelines باستخدام dbt (Data Build Tool) وApache Airflow للـ Orchestration.
- بناء Predictive Models للتنبؤ بالمصاريف الجاية (Cost Forecasting).
4. الـ High-Throughput E-Commerce Event Sourcing Engine
📌 الفكرة: لو عايز تروح أكتر ناحية الـ Back-End والـ Distributed Systems، ممكن تبني Engine قوي جداً للـ Event Sourcing والـ CQRS Pattern، يتحمل ملايين الـ Requests في نفس اللحظة (بدون ما يحصل Race Conditions أو مشاكل في الـ Inventory والـ Concurrency أثناء الـ Peak Times).
📌 الـ Tech Stack المقترح:
- لغة البرمجة: Go (Golang) أو Java (Spring Boot) لضمان الـ High Performance والـ Concurrency.
- الـ Database Split: استخدام PostgreSQL للـ Write Operations وElasticsearch للـ Read/Search Operations.
- الـ Messaging standard: استخدام RabbitMQ أو Kafka لتمرير الـ Events بين الـ Microservices.
- الـ Caching عن طريق Redis Cluster.
كل فكرة من دول لو اتنفذت بـ Production-Ready Mindset وتم التركيز فيها على الـ Scalability والـ Error Handling، هتكون مشروع تخرج قوي جداً وتضمن الـ Technical Background اللي يفتح أبواب كبرى الشركات.

1
194

The largest Insurance and Financial company wanted business users to drag flat files from their desktop to the cloud using Nexus.
youtu.be/2Ig31IxAKug
#googlecloud #bigquery #databricks #snowflake #teradata #oracle #snowflake #redshift #postgres #yellowbrick #mysql #db2

16

Python, excel, power bi, bigquery,google analytics ....ohoo çok şey bilip birbirine bağlamak gerekiyor 🚬
1
1
9

Gw disuruh ngambil data dai bigquery anjay pake vscode ngolahnya

klo ini kurang tau ya krena biasa klo pake vsc ya vsc aja gt, kalo mau pak google colab lgsg di chrome aja
1
369

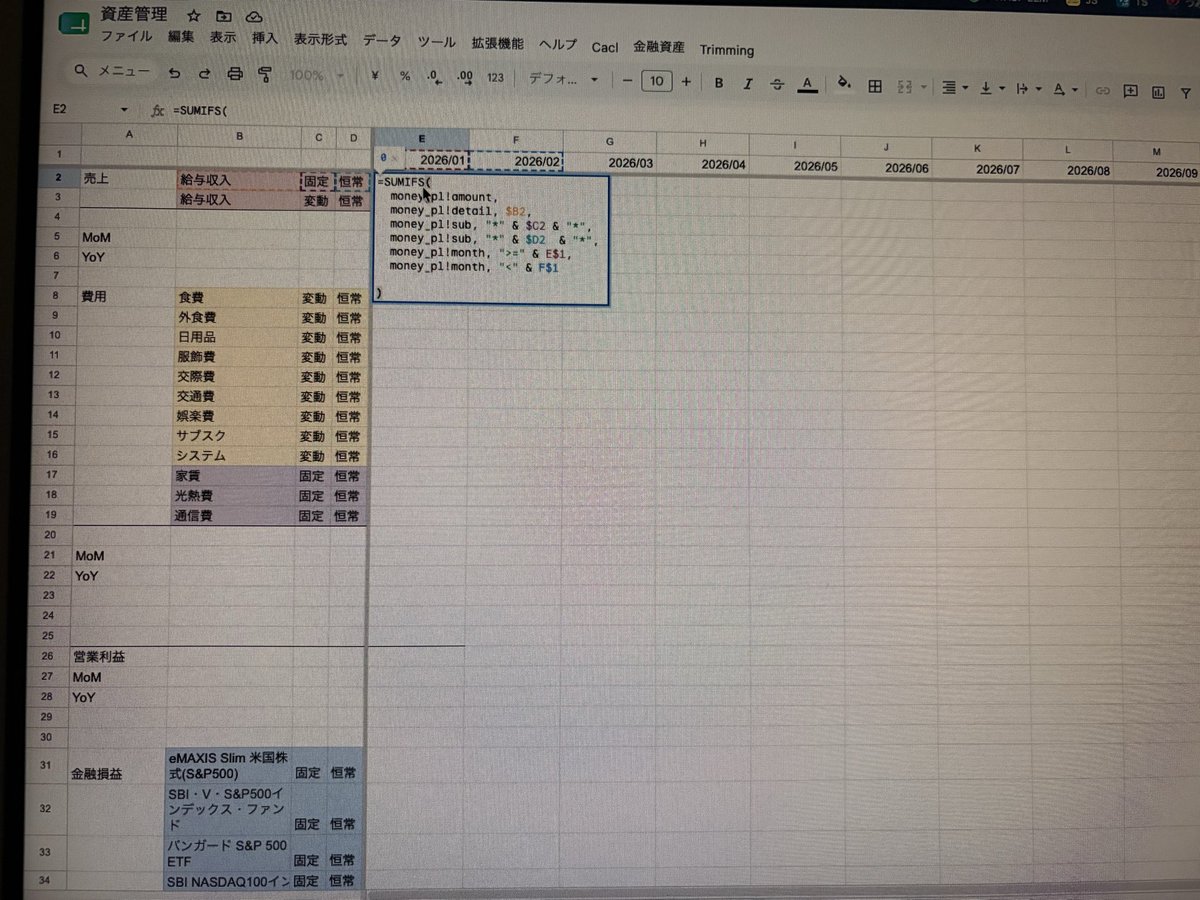
資産管理をスプシ×Bigqueryで実践すべく構築中です。こんな感じで、月次推移とか分かると管理しやすそう😊
「おっ、前よりも給料も手残りも増えてる!」的なモチベーションにもしたいです💪
4

Learn to build smarter, resilient AI agents. Join our webinar for a deep dive into graph algorithms and see how Spanner Graph, integrated with BigQuery, reveals intricate data relationships for explainable AI. Secure your spot today. google.smh.re/5Y0y
4

GA4公式のMCPサーバー、試してみた。
BigQuery介さずClaudeが直接GA4を読む。
手軽さは公式MCP、大量データはBigQuery経由。
"AIにデータ分析を任せる"の入口がまた一段下がりました。
1
11

4/
The semantic layer is almost entirely unspecified, and the spec says so explicitly. The "type" field is required but unregistered, so one producer writes "BigQuery Table" and another writes "table" for the same concept. Links are untyped: they assert that two things are related without saying how. Two fully conformant bundles can share no common vocabulary, which means conformance does not guarantee that an agent reading one can make sense of the other.
1
3/
The vendor-neutral framing deserves a close read. The file format is genuinely open, but the reference implementation runs on Gemini, reads from BigQuery, and points toward Google Cloud's own Knowledge Catalog as the natural ingestion path. The license is not Google's. The gravity of the ecosystem still is.
1
5


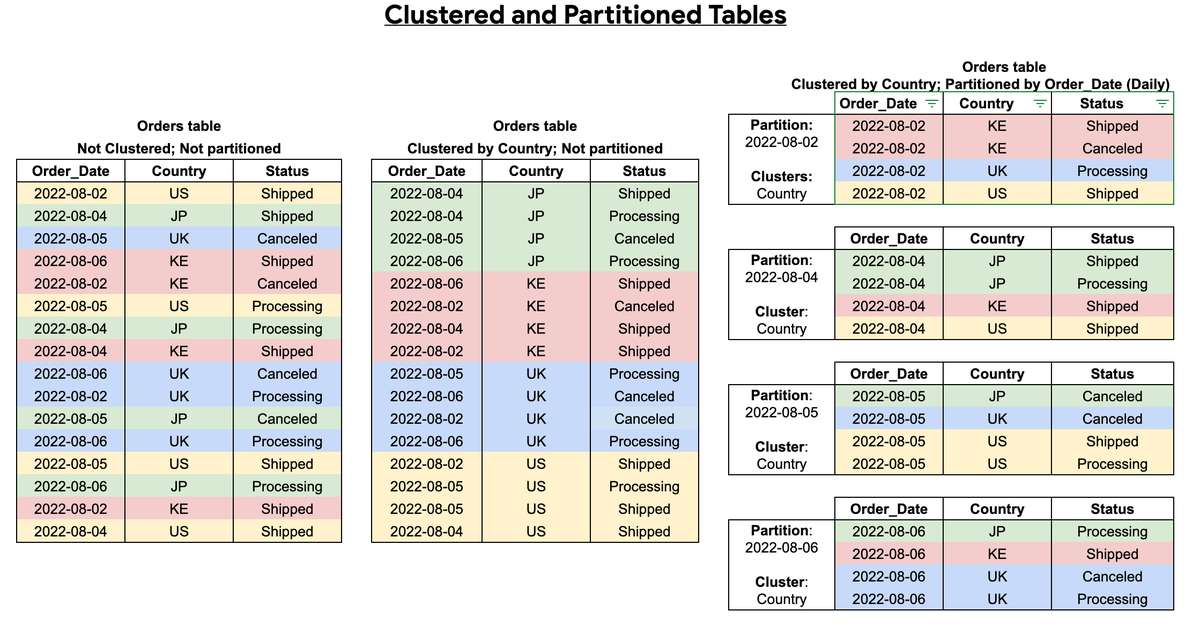
🚀 BigQuery slow? You're missing Partitioning & Clustering.
Partitioning = scan less data = lower costs ✅
Clustering = sort by columns = faster filters ✅
Pro tip: Combine both for maximum performance 💡
#BigQuery #GCP #DataEngineering
4

Google Cloud published the Open Knowledge Format (OKF) specification on June 12, 2026, introducing a vendor-neutral standard for representing organisational knowledge as a directory of Markdown files with YAML frontmatter.
The only required field per concept document is "type". Concepts link to each other through standard Markdown links, forming a traversable knowledge graph. Google simultaneously released reference implementations including an enrichment agent that crawls BigQuery datasets and generates an OKF document for each table, and updated its Knowledge Catalog product to ingest OKF natively.
The specification and all reference code are available on GitHub. The format is designed to address the problem that organisational knowledge is currently scattered across metadata catalogs, wikis, code comments, and shared drives in mutually incompatible formats.
Full details via Google Cloud Blog / cloud.google.com/blog/produc…
1
13


BigQuery等を使ってハブとなるページ、CVに貢献するページを細かく分析しようとしている。ここまでやるか?
弊社の場合通常はGA4探索を使ってるのが実情。それで事足りる。

42
myokota retweeted

🎥今年の Google Cloud Next や Google I/O における、DA / AI の最新アップデートをお届け!
データのつながりを解き明かす BigQuery Graph、正確な指標を標準化する BigQuery Measures、文脈を自動生成する Knowledge Catalog など、注目のデータ基盤の進化を学びましょう✏️
x.com/i/broadcasts/1YxNrrQEj…
1
1
8
2,528

谷歌推出了OKF规范,OKF 的设计初衷是为了打通“知识的产生”与“知识的使用”:
谁来生产(Produce)? 任何人或机器都可以生成 OKF。可以是人类手动编写,也可以是由 Google ADK 或 LangChain 构建的 Agent 自动抓取生成(正如文档中提到的“数据增强 Agent”),或者是从现有的数据库(如 BigQuery、Dataplex)中导出的脚本。
谁来消费(Consume)? 任何人或系统都可以读取它。可以是一个静态文件服务器、一个知识管理软件(如 Obsidian)、一个正在读取上下文的 LLM、一个搜索引擎,或者是一个将知识可视化为互联节点图的图谱浏览器。
cloud.google.com/blog/produc…
19

Google Cloud Releases Open Knowledge Format v0.1
Google Cloud has introduced the Open Knowledge Format (OKF) v0.1 a spec that stores organizational knowledge as Markdown files with YAML frontmatter.
The format builds on the LLM Wiki pattern popularized by Andrej Karpathy.
OKF represents knowledge as a directory of Markdown files linked through standard Markdown links to form a knowledge graph.
The spec requires only one field called type with optional fields for title description resource tags and timestamps.
Bundles render on GitHub and can be indexed by any search tool.
Google Cloud released reference implementations including an enrichment agent that crawls BigQuery datasets and a static HTML visualizer.
Three sample bundles cover GA4 e-commerce Stack Overflow and Bitcoin datasets. Google Cloud also updated its Knowledge Catalog to ingest OKF and serve it to AI agents.

44