
Cameo ~ She's Strange ~ (1984) The track was praised for successfully blending traditional R&B & funk with cutting-edge electronic synths & early hip-hop elements. The consensus celebrated its infectious danceability & clever vocal arrangements. #HipHop
 Vinyl Records🎱✝️🇧🇷👪🗽
Vinyl Records🎱✝️🇧🇷👪🗽
2
35
118
5,425

Jun 13
old bantengan > new gen bantengan, you can tell the difference especially when you're from Malang Raya
tapi emang kalo dari danceability, musik bantengan post-sound horeg lebih asik sih cocok buat joget
klo bantengan lawas repetitif musiknya, tapi ak suka kyk wow ritualistic gt
1
3
286

Same here! Always rated her for being the artist she wants to be. Always admired her dedication to health & fitness.
Always enjoyed her performance & danceability. Never believed she would grow old gracefully, but disappointed she succumbed to the (grozz!) plastic surgery.😧!..
1
6

- Shared memories
- Proven danceability
- The singalong factor
- Scarcity
1
4
323

comes in lilac, yellow and black!! imagine how cool it’d look with the gen tights from the aespa collection and some rick owens boots for danceability this would be my dream lollapalooza fit

1
8
371

i didn't say michael's music doesn't have profound artistry. i said that you reducing their music to danceability was dumb
1
14
568

Jun 2
My All Time 250 Favourite Albums
142. Now Playing : Ratt - Dancing Undercover
This may not be quite their very best album but boy does it have a groove on. Absolutely Ratt swinging it out of the park in the danceability stakes. Rock solid all the way through, it never lets up. Beau Hill with another fantastic production.
By the time this came out I was an avid fan and had seen them live 5 times in the UK (no mean feat as their shows over here were scarce). My most vivid memory of talking about this album was with a Scottish girl at the time. I could never forget how she told me she danced to it (nothing sinister, just a fun memory!) 🕺 💃
🎶 Loose lips, sink ships 🎶

2
19
254
Missy Elliott, 'Lose Control', ( 2005 ) Critics praised the song 4 its futuristic, pulse-pounding production & addictive danceability & lauded the track's heavy, trunk-rattling bass, old-school sampling, Cybotron electro, & vocals by Ciara & Fatman Scoop.
 culture
culture
13
49
1,630

May 27
i can agree! i think theres a fundamental danceability but could come from that new wave art punk area
2
48

May 27
Also like how she immediately went after and to his club hits which is more about the flow and production and danceability than lyrical depth or content and intentionally avoided anything from iceman that was actually lyrical
1
8
370

May 25
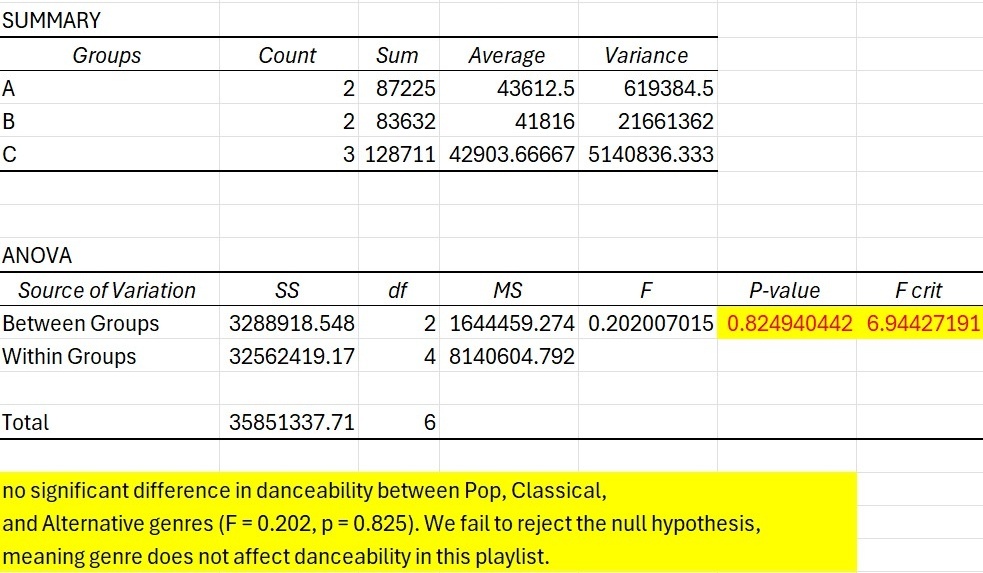
used spotify danceability data some data cleaning thank you dr khidir
May 24

just made oomf an anova table to see if their playlist is danceable, doing freelance data analysis if anyone wants
3
9
837

May 19
I built a machine learning model to answer a simple question:
Can you evaluate a song’s commercial potential before release?
Every day, independent artists upload thousands of tracks to streaming platforms without any objective feedback.
Marketing budgets get spent on songs that struggle to gain traction, while some strong records never get the attention they deserve.
I wanted to test whether data can reduce that uncertainty.
So, I built Hit Predictor - a predictive model that translates audio features into a structured signal. (huggingface.co/spaces/Prifea…)
This model is a Random Forest Classifier trained on Spotify data.
The dataset originally contained over 114,000 tracks.
But during EDA, I removed approximately 1,000 sleep tracks, representing 0.88% of the data, because they consist of ambient sounds like white noise and ocean waves and do not reflect musical structure.
This reduced the dataset to 112,999 tracks.
While exploring the data, a conversation with a friend led to an important observation.
The same song appeared multiple times.
And what looked like a data quality issue turned out to be structural.
Songs are indexed by genre, so a single track can appear across multiple genre labels.
Validation showed 32,601 duplicate track–artist combinations (29% of the dataset).
This creates two realities.
➛ For analysis, duplicates enable genre-level comparisons.
➛ For modelling, they introduce bias and risk of overfitting.
So I split the approach.
I kept the full dataset for exploration, and created a deduplicated version for training by retaining one instance per track–artist combination.
After deduplication, the model was trained on 80,398 unique tracks.
The model uses 10 key audio features, including danceability, energy, loudness, tempo, and speechiness, to classify songs into four tiers:
Viral ➛Hit ➛Mid ➛Flop
After hyperparameter tuning and resolving deployment pipeline issues, the model achieved 69% accuracy.
This is not about perfectly predicting hits, but more about introducing a data-driven checkpoint before decisions are made.
A few things stood out during the process.
➛ Genre remains the strongest predictor of performance based on feature importance.
➛Audio features alone are not enough. Artist reach, marketing, timing, and distribution all play a significant role in how a track performs.
So the model works best as a decision-support tool, not a replacement for human judgment.
From a build perspective, this was an end-to-end pipeline.
⭐︎ EDA and data hygiene using Pandas and NumPy.
⭐︎ Visualization and feature analysis with Matplotlib and Seaborn.
⭐︎ Feature engineering and scaling with Scikit-learn.
⭐︎ Model training and tuning using Random Forest classification.
⭐︎ Backend and API development with Flask.
⭐︎ Deployment on Hugging Face Spaces, including handling large files and environment setup.
You can input a track’s features and get a prediction with probability scores.
If you are an artist, manager, or just curious about how your favorite songs might perform, I have shared the link in the first comment.
I would be interested to see what results you get.
12
5
18
399

May 15
Allen Halas (@BreakinNEnterin) on "Warp Spasm":
"A moody, driving track that balances danceability with an unmistakably dark undercurrent."
Full review → breakingandentering.net/2026…




1
1
3
67

May 11
이 논문의 요약은...
어떻게 하면 히트하는 애니메이션 곡을 만들 수 있을까?
- 신나는 곡 (danceability)
- 유명한 작품 타이업
- 오프닝 테마
즉. "오타게가 박히는 유명 작품 오프닝이면 히트한다." 정도로 요약 가능할듯 ㅋㅋ
덤으로 캐릭터송이나 성우곡은 히트하기 힘들다고.

「どうやったらヒットするアニメ曲を作れるのか?」という私の論文が、日本アニメーション学会から出版されました!
近々オンラインでも公開されます!
一番の驚きは、声優が歌う曲は統計学的にヒットしにくいということです…
(余裕があれば補足資料も作ろうかなと)

27
24
2,674

May 5
3. Raw Audio Analysis ("DNA" Model)
Spotify uses CNNs to "listen" to the actual waveform of every song.
Features: The AI analyzes tempo, key, loudness & even "danceability."
Mapping: If you like songs of a particular type, the system can find a brand-new track with the same audio signature, no matter the plays.
1
4
209

Apr 24
Big fan of the energy and the messaging! Lots of danceability at 150BPM!
Believe it's in C# Min which gives tragic romance to me and that is shown in the mv
I'd love more melodic and vocal moments!
7.75/10 fun song! 🎉
#LE_SSERAFIM #르세라핌
#PUREFLOW_pt1
#CELEBRATION
Apr 24

<CELEBRATION> OFFICIAL MV
youtu.be/a2grcJdfXmY
✰ 2nd Studio Album ‘PUREFLOW’ pt.1
2026.05.22 1PM (KST) | 12AM (ET)
#LE_SSERAFIM #르세라핌
#PUREFLOW_pt1
#CELEBRATION
4
175

Apr 24
baby boy live still doesnt have a moment thats touching Cil’s live riff unfortunately and for danceability theyre about the same to me, baby boy does blend more easily but one of her best interpolations to this day still goes to cil here imo 😩 love both tho
16 May 2023

Crazy In Love live at The Beyoncé Experience (2007)
This is the most explosive performance of this song. And that’s saying a lot because she’s killed ‘Crazy In Love’ MANY TIMES. The Gnarles Barkley mashup was *chef’s kiss*
1
2
123

The Slayyyter album surpasses brat in almost every way (particularly in danceability and the raw vulnerability of all the lyrics, something that Charli tried in brat and was still very uptight and rehearsed) and in general owes very little to that album in general.
1
5
194

