
Your Papa no get sense na why I dentry teach you small sense.
Now skeddadle out of my mentions.
1
1
14

Jun 12
Le retweet de mon amis dentry ne fonctionne pas ,aidez nous.

1
24

May 30
3 days after launch and DENTRY is collecting some @MaxPalmer666 medals
Happy Saturday to Framer creators, reviewers, DIY website builders and everyone else!

4
16
472
May 28
Built Dentry for dental clinics that want a premium website.
Focus on: Fast to launch. Easy to edit.
Then I added a scroll reveal to Section 04.
Unnecessary? Maybe.
But damn, it fits.
100% free on Framer Marketplace right now.
3
13
290
May 27
Dentry is live in Framer Marketplace.
A free Framer template for boutique dental clinics.
Clean layout.
Premium feel.
Built for trust.
Ready to launch in Framer.
Dare you to tell me this is not sleek?
Details link below.

1
1
9
282

May 17
All AntiIndians withOCIcards/Passports shd b cancelled immediately. India shd NOT allow dEntry&Exit "Free4AllNationalities" anymore!
Entry2India shd b restricted2only those countries who allows our Citizens free entry, reciprocally!
@MEAIndia shd Act2improve Acceptability of Indian Passports worldover&try2make it#1/ #2/#3, Each Year shd try2get upgraded&shd Include it as MEA, KPI
2
27
2,044

Apr 25
8020 兼松 東証1部
日本株、その中でも商社株は今年も来年も狙われることになりそう。元来日本株を買わなかった世界一の投資家であるウォーレン・バフェットさんが日本の商社株を日柄かけてしっかり買ってきた。伊藤忠商事、三菱商事、三井物産、住友商事、丸紅をバフェットさんの関連会社が5社を5%ずつ保有。ケースによっては買い増しもあるという話です。商社株はバフェットさん買いから世界の注目を受けて、今後は中期、長期でさらにしっかりした相場になりそう。安い金利のところから資金を持ってきて、日本株の商社株に資金投入すると、高配当であることと、今後は長期で株価浮上の期待があり、効率よい投資ができる。本命は三菱商事となるが、バフェットさんが狙わないまでも、他の商社株にも買いが回る可能性があり、兼松と双日なども下値から株高発生がありそう。兼松は電子・デバイス、食料から鉄鋼、素材、プラント、車両、航空と幅広い事業展開。さらに穀物、飼料事業、農産物加工品事業、調理加工品、食品原材料事業、畜産事業と幅広い事業展開となっている。工作機械、化学品事業、エネルギー、鉄鋼。130年の歴史があり、ここで6ヵ年事業計画を発表。付加価値の獲得と規模拡大の追求で、今後とも発展的な事業計画を打ち出している。今期売上の伸び悩みも、株価の位置は安く、60円の高配当継続予定であり、この位置から株価はしっかり浮上して、年内は700円高も狙える、そして時価からの株価倍増も期待できる相場が数年でありそう。
8410 セブン銀行 東証1部
この押し目は徹底狙い。年内は100円高も期待できる。260円台の株の100円高はとても効率的。ファミリーマートにセブンATMが設置される。
セブンイレブンで必ず見かけるもの、それはセブン銀行のATM。店舗拡大と共に、ATM設置数が増え、新型コロナウイルスで電子決済の進展が見られて、入金にATM使用が増え、今後期待。新型コロナでの落ち込みは許容範囲であり、株価が安いことから、今後の期待から株価は260円台から今後は300-330円も期待。全体相場浮上となり、日経平均は来年には3万8915円の史上最高値更新見込みであり、その時にこのような低位株はしっかり浮上している可能性あり、株価倍増狙いとなる。つまり時価の倍増で500円も期待。銀行株は三菱UFJが本命であり、さらにしっかりした相場となりそうだが、セブン銀行は穴株的な存在であり、株価はここからしっかり浮上がありそう。今後はキャッシュレス決済サービスの伸びから、ATMプラットフォーム事業は成長期待が大きく、利用件数の増加と多角化、海外強化など期待がある。現在、ATM設置台数は2万5215台、提携金融機関数は612社、ATM年間送料件数(単体)849百万件、ATM稼働率99.98%(2020/03末)。株価は今年に入り215円から240円突破となっているが、さらにここから上向きとなりそう。安定度ある高配当株を狙う動きがあり、同社は今期売上伸び悩みも、11円配当維持の予想であり、これを受けてしっかりした浮上が見られそう。
3769 GMO-PG 東証1部
同社は主にEC向けにクレジットカードの決済代行サービスなどを展開。加盟店とカード会社をつなぎ、決済処理金額に応じた手数料が収益源。幅広い決済手段に対応し、国内有数の決済代行取扱高を有する。国内EC(電子商取引)市場は拡大で、EC化率はまだ6%台に留まっている。今後、物販のほか旅行予約や動画・音楽配信などのサービス分野においてもデジタル化の進展が期待できよう。主戦場である国内の消費者向けEC市場規模は、社会のデジタル化加速もフォローの風となり、同社は2025年に約45兆円まで拡大すると見込まれる。また、新型コロナウイルスがキャッシュレス決済のすそ野を広げるきっかけとなった。アフターコロナはビフォーコロナではなく、顕著な生活スタイルの変化は追い風となろう。三井住友カードが提供する決済プラットフォーム「stera(ステラ)」のオールインワン端末「steraterminal」に21年2月上旬より、歯科医院向け予約管理システム「Dentry(デントリー)byGMO」の「WEB予約管理機能」の提供を開始。歯科医院は自院の患者に対してキャッシュレス決済とWEB予約の仕組みを提供できる。こちらはオンライン診療シェアの窓口としても期待できよう。
5
47
10,687




Feb 12
The kernel isn't a static blob that stays under 50mg forever. it's dynamic. Slab caches alone can balloon quick, and basic stuff like dentry/inode caches start small but grow. 50 MB total for the kernel in practice? That's fantasy unless you're on a 486 with a 2.x kernel.
1
2
637

Feb 3
Day6 of "Learning and sharing about Linux"
Inodes & Metadata: How the kernel identifies files without names
In the eyes of Linux kernel filename is just a convenient alias for the humans. to the system a file is an inode.
an inode(index node) is a data structure that stores everything about a file except its name and the actual data content.
it contains,
- File type: (regular file, directory, symbolic link, etc...)
- permissions: (r, w, x)
- owner info:
- size
- timestamps: created, accessed, modified
- pointers: the physical address on the disk (blocks) where the data actually lives
Then how the kernel finds the data?
- Dentry lookup: the kernel looks at the directory entry(dentry). a directory is actually just a special file that maps a Filename to a inode number
- inode retreival: once the kernel has the inode number it looks at the inode table for that entry
- data access: inode tells the kernel where the data lives in the hardware in blocks for example 500, 502 and 505
this is why moving a file in the same partition is instantaneous because the file blocks doesn't move only the pointers change
some extra info:
- every file needs a inode so if you have millions of 1KB files you'll run out of inodes before your storage runs out
- a hard link is just two pointers to the same inode, the file is deleted only when the pointer counts reduces to zero
- when you delete a file kernel isn't actually deleting the data in those blocks it just marks the inode as free and the data blocks as available, so next time you write something the prev stale data gets overwritten.
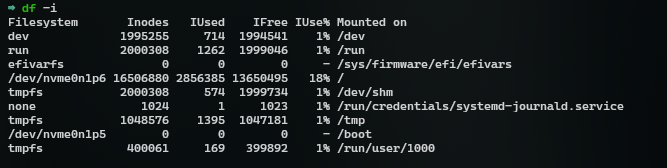
`df -i` shows you how many inodes are left on your disk
Here's a example of what a inode metadata actually looks like
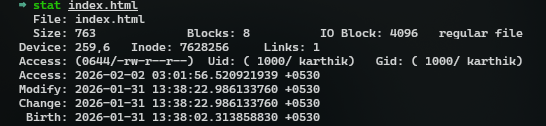
Feb 2

Day5 of "Learning and sharing about Linux"
in Linux everything is a file. It is a fundamental architectural principle that makes the operating system more powerful.
whether you're interacting with a text document, a hard drive, a keyboard, or even a network socket OS treats them all as a stream of bytes.
if this principle wasn't there engineers had to design 50 different API's for 50 different things keyboard, file, network, USB etc.. etc..
There are three standard streams also knows as file descriptors:
1. stdin 0
2. stdout 1
3. stderr 2
Redirection: changing the flow of these streams
with redirection you can direct the output or input to a location of your choice than the default.
1. output redirection:
- ls > files.txt overwrites files.txt with the list of files
- ls >> files.txt appends the list to the end without deleting the existing content.
1. error redirection:
- `grep "search" important.go 2> errors.log` redirects only the stderr to the errors.log
- `command > output.log 2>&1` first one tells redirects the stdout, second one tells the process to redirect the stderr(2) to where stdout(1) is going. (aka both stdout and stderr goes to output.log)
Piping:
i wrote about this yesterday, here's a brief
`ls | grep "main.go"`
bash spaws a child process for ls
ls outputs a massive list (stdout)
parent process waits for the child's output
`|` pipe grabs that output and passes it to grep
then again a child process is spawned for grep
I'm quoting a more detailed explanation about pipes here 👇
1
7
124

Jan 14
THEUNIT MIDWEST RECRUITMENT
TheGaulet College HS Showcase @MackD44OHS @MarcSutherland_ @Coachvon05 @BossHogAcad @18bstank @TheUCReport
2028 DL Mack Dentry 6'1 255lbs
Oxford High School, Michigan hudl.com/v/2TEZiZ @NMUCoachBright @drjedariusisaac @NMUCoachJanus @CoachWheat6 @CoachMtz125510 @CoachJasonMiran @CoachJ_Sweeney
5
12
1,129

Jan 12
There's in reality little difference between a filesystem and a database. A POSIX filesystem is essentially a lookup table between names and inodes, and then another lookup table between inodes and file segments. That's it. Those lookups are heavily cached in the Linux Kernel in structures called the dentry cache, and the inode cache.
The reason people view them as so different is that traditionally "databases" are far away things, where every lookup costs a lot. An entire directory transversal may do a lot of those lookups, and that "costs too much".
SQLite and Turso change that calculation of course because it is possible to just do those lookups locally. In fact, some modern filesystems will even use a SQLite file for these lookups.
From there to AgentFS, there's just another logical step: We believe it is advantageous for agents to be able to snapshot, fork, and rollback their entire state at once. Because of that, it is advantageous to keep everything - both data and metadata - in the same SQLite file.
Modern agent infrastructure needs that state to be *immediately* available to agents and have resumability, and we can achieve that with the Turso Cloud (which is backed by S3), or your own custom-made sync primitive.
That is in essence what AgentFS is (agentfs.ai).
Filesystems are of course heavily specialized for the workloads they have, and we'll be doing work in the near future to bring the performance inline with what you'd expect from a modern filesystem.
5
5
113
9,838


Jan 10
Exremely kind of you to think there is a root dentry at this point.
2
5
156

2 Dec 2025
The cache design of GreptimeDB has been continuously evolving.
Initially, it only included a read cache, then a write cache was introduced, and now it has become more nuanced with components like index cache and manifest cache. Of course, the memory aspect is even more complex.
This is somewhat similar to cache designs in operating systems, such as Page Cache, Inode Cache, Dentry Cache, and Write-back Cache etc., which all address the problem of I/O mismatches.
However, the focus of the operating system is on the interactions between applications, the kernel, and disk, while we concentrate on solving the matching issue between databases (DB) and object storage.
In the future, there will surely be more refined I/O scheduling, such as deciding which data block to prioritize for reading and how to implement prefetching.
1
8
1,208


7 Oct 2025
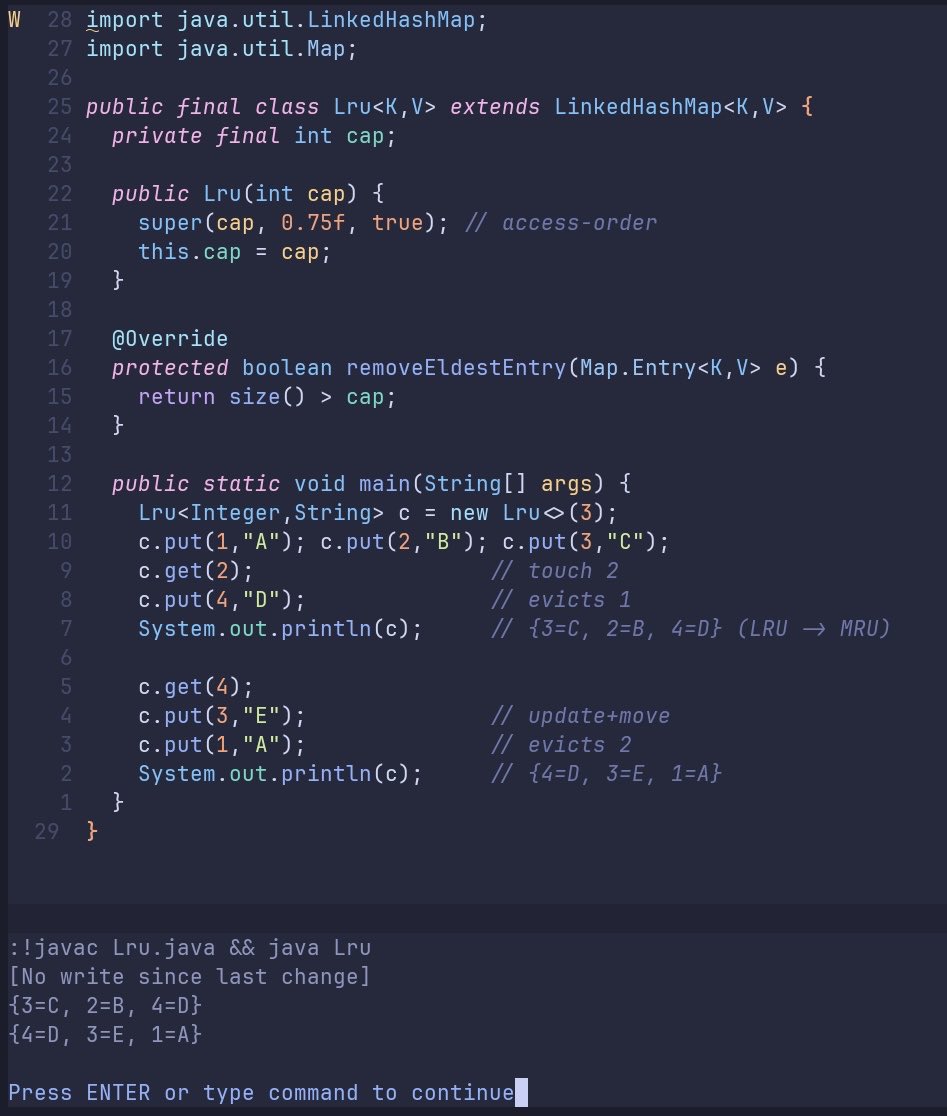
Linux uses LRU style caching almost everywhere. That’s how the os stays fast on old hardware. Its page cache, buffer cache, and dentry/inode caches are all LRU implementations in the kernel code.
- capacity=3, automatic LRU eviction, prints map from oldest to newest after each step. The cache automatically removes the least recently used entry when it exceeds capacity.
1
2
185

9 Sep 2025
Finance expert @mrmoneyjar & John Dentry chats with @avery_aston about student finances on #daytime next! Tune in on FM, on DAB or online gateway978.com/live
Photo by Colin Watts on Unsplash

2
2
147