
UI作成のコーディングでClaudeに圧勝するAIがあるの知ってる?
「GLM-5V-Turbo」は画像からコードを生成する能力をはかる、Design2Codeベンチマークで94.8という圧倒的なスコアを出してる
(Claudeは77.3)
Figmaのデータやスクリーンショットの画像などから超高精度でコードを生成できる
高精度の秘密は画像はテキストに訳さず、そのまま理解できる仕組み
例えばあなたが友達にあるWebサイトのTOP画面のデザインを言葉だけで説明するところを想像してみてほしい
「一番上に青いヘッダーがあって、その下には綺麗な海の写真とxxxというキャッチコピーがあって...」
と伝えても、「青って具体的にどんな青?」「ヘッダーとキャッチコピーの間はどれぐらい空いてるの?」など、細かいニュアンスがどうしても抜け落ちてしまう
これまでのAIも全く同じで、テキストに翻訳する過程で細かい情報が欠欠けしまっていたが、GLM-5V-Turboは「CogViT」という専用のビジョンエンコーダーが、色・レイアウト・コンポーネントの重なり具合といった視覚データを、テキストに翻訳することなく、ダイレクトにAIに送り込む仕組みを持ってる
また、ClaudeCodeやOpenClawなどのエージェントとの連携能力も高い。こうしたエージェントから呼び出された際に、ブラウザなどを開いて自分で成果物を確認し、指示との相違を見つけて修正するような精度を上げるループを回してくれる
UI作成に関してはエンジニア本当に楽できる部分が増えてるので、これは絶対使ってみてほしい
x.com/Zai_org/status/2039371…
 Z.ai
Z.ai
1
2
1,610

May 29
Anyway is partnering with @Zai_org . 🤝
Now, users can access Z.ai's full suite of capabilities directly through the Anyway Super API:
⚡ GLM-5.1 Highspeed: up to 400 tokens/s output
💻 GLM-5.1: optimized for extended 8-hour coding sessions
🎨 GLM-5V Turbo: Design2Code that turns screenshots & mockups into production-ready frontend code in seconds
Keep shipping.
5
4
21
1,178

May 13
GLM-5V-Turboが発表された(https://arxiv[.]org/html/2604.26752v1)。
Zhipu AIが開発したマルチモーダルエージェント基盤モデル。多くの従来VLM(視覚言語モデル)が「テキストモデルに視覚を後付け」する設計なのに対し、視覚理解を推論・計画・実行の中枢として一体化しているのが核心。
実装が面白い。視覚エンコーダー「CogViT」は2段階の事前学習で構築。第1段階では「意味表現担当のSigLIP2」と「テクスチャ担当のDINOv3」の2つのTeacherモデルから知識を蒸留しながら、マスク率35%でMasked Image Modeling(画像の隠れた部分を復元するタスク)を実施。QK-Norm(クエリ・キーベクトルの正規化)でアテンションスコアの爆発を防ぐ工夫も入っている。第2段階では可変解像度入力に対応しながら、80億件の中英バイリンガルデータでコントラスト学習。
MMTP(マルチモーダル・マルチトークン予測)では「画像トークンをどうMTPヘッドに渡すか」という実装問題があった。3案を比較した結果、視覚埋め込みをそのまま渡す案は「MTPヘッドが軽量すぎて分布の異なる視覚表現を吸収しきれない」と判明。最終的に全画像トークンを特殊トークン「<|image|>」に置き換える案が0.5Bモデルの実験で最も安定した収束を示したため採用された。
RL訓練インフラも凝っている。参照モデルのパラメータはCPUに常駐させ、必要な直前にGPUへ非同期プリフェッチして即解放することでメモリ圧力を抑制。GPU通信経路から大型Pythonオブジェクトを外すことで通信バッファを約7GB削減している。
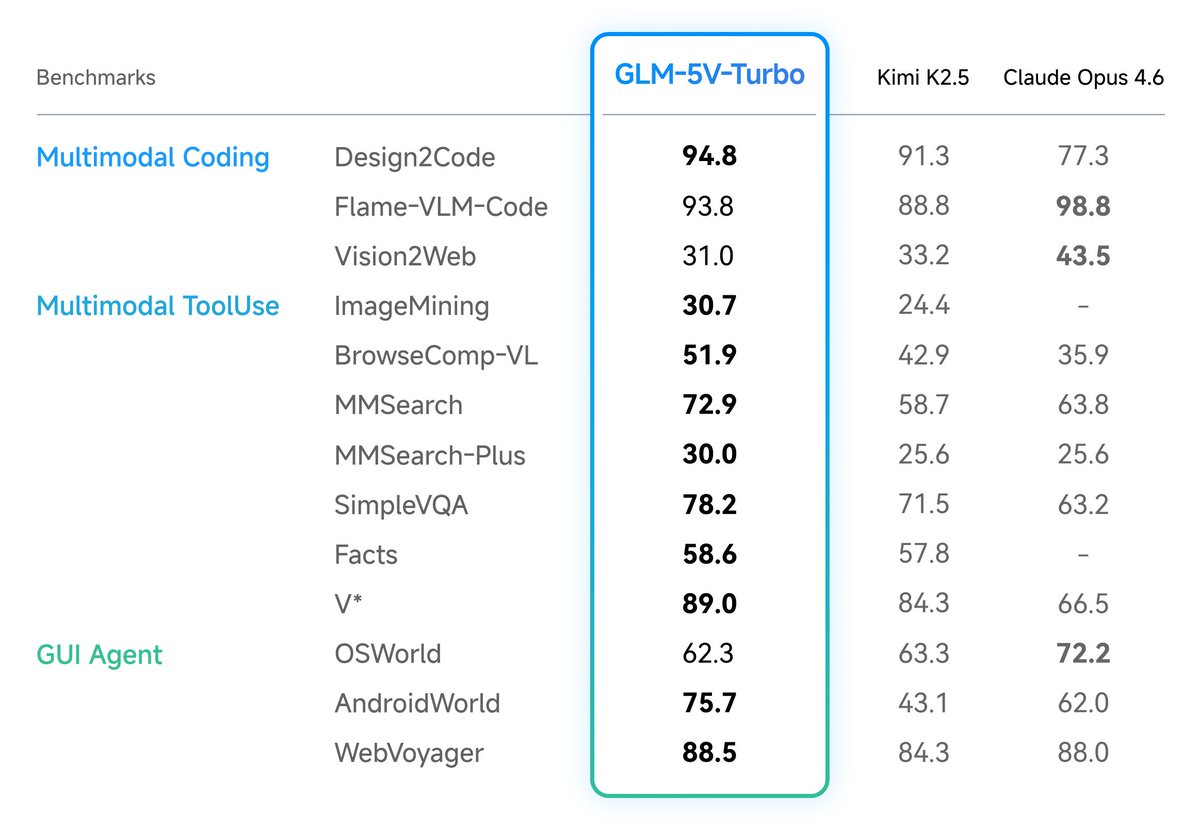
30以上のタスクカテゴリにまたがる多タスクRLの結果、SFT(教師ありファインチューニング)比でOSWorld 4.9%、CharXiv(グラフ理解) 7.7%、OCRBench 4.2%、MVBench(動画理解) 5.6%と横断改善。最終ベンチマークはDesign2Code 94.8(Claude Opus 4.6超え)、AndroidWorld 75.7、OSWorld 62.3。
論文が繰り返す洞察は「知覚(Perception)の精度が上位能力の上限を決める」こと。推論や計画のエラーに見えるものの多くが視覚環境の誤読から始まっている。見ることが正確でなければ考えることも正確にならない、という当たり前が最先端でもまだ難しい。
2
310

May 7
智谱发布了GLM-5V-Turbo。
不是又一个聊天模型——这个能"看图写代码"。
你给它一张UI设计稿,它直接生成前端代码。 Design2Code测试94.8分,超过所有竞品。
从"文字描述→代码"到"截图→代码",编程的门槛又降了一级。
以后产品经理画个原型图,AI直接生成可用代码。
前端工程师的价值正在从"实现设计稿"转向"设计交互逻辑"。
7
7
1,470

May 1
🔥 GLM-5V-Turbo: A native foundation model for multimodal agents — not a language model with a camera bolted on. Most AI agents still treat vision as an afterthought; this paper makes perception a core part of reasoning, planning, and execution.
Key innovations: CogViT (a vision encoder built for fine-grained understanding), Multimodal Multi-Token Prediction (efficiently handles images during training without exploding compute), and joint reinforcement learning over 30 task categories covering perception, reasoning, and agentic skills.
Results speak loud: 94.8 on Design2Code (beats Claude Opus 4.6), 75.7 on AndroidWorld, 62.3 on OSWorld, 51.9 on BrowseComp-VL. It also retains strong text-only coding — 22.8 on CC-Backend, 68.4 on CC-Frontend. The team released ImageMining, a new benchmark for vision-centric deep search.
Why it matters: Real-world agents need to see layouts, buttons, videos, and documents, not just read text. GLM-5V-Turbo shows that integrating vision natively unlocks a new tier of autonomous capability — from GUI automation to multimodal deep research. Perception isn't a low-level module; it's the ceiling for everything above it. The era of agents that truly see has arrived.
🔗 arxiv.org/abs/2604.26752

2
54

Micro SaaS idea of today:
design2code(.)co
Figma alternative exporting clean React and Tailwind code, enabling developers to skip handoff and build faster.
💵 MRR estimation: $15K in 1 year
💸 potential exit: $700k
.. .
Follow for more ideas: @micro_startups_ 👈
3
238

Apr 3
Mam wrażenie, że chińskie laby zaczęły bardzo celnie rozumieć gdzie mają szansę wygrać!😅
GLM-5V-Turbo od Zhipu AI nie stara się być najlepszym modelem ogólnym. Jest robiony w jednym celu!
Ma patrzeć na interfejs aplikacji (czyli to co widzisz na ekranie: przyciski, menu, formularze, całe layouty stron) i pisać kod, który odtworzy ten interfejs lub wejdzie z nim w interakcję🔥
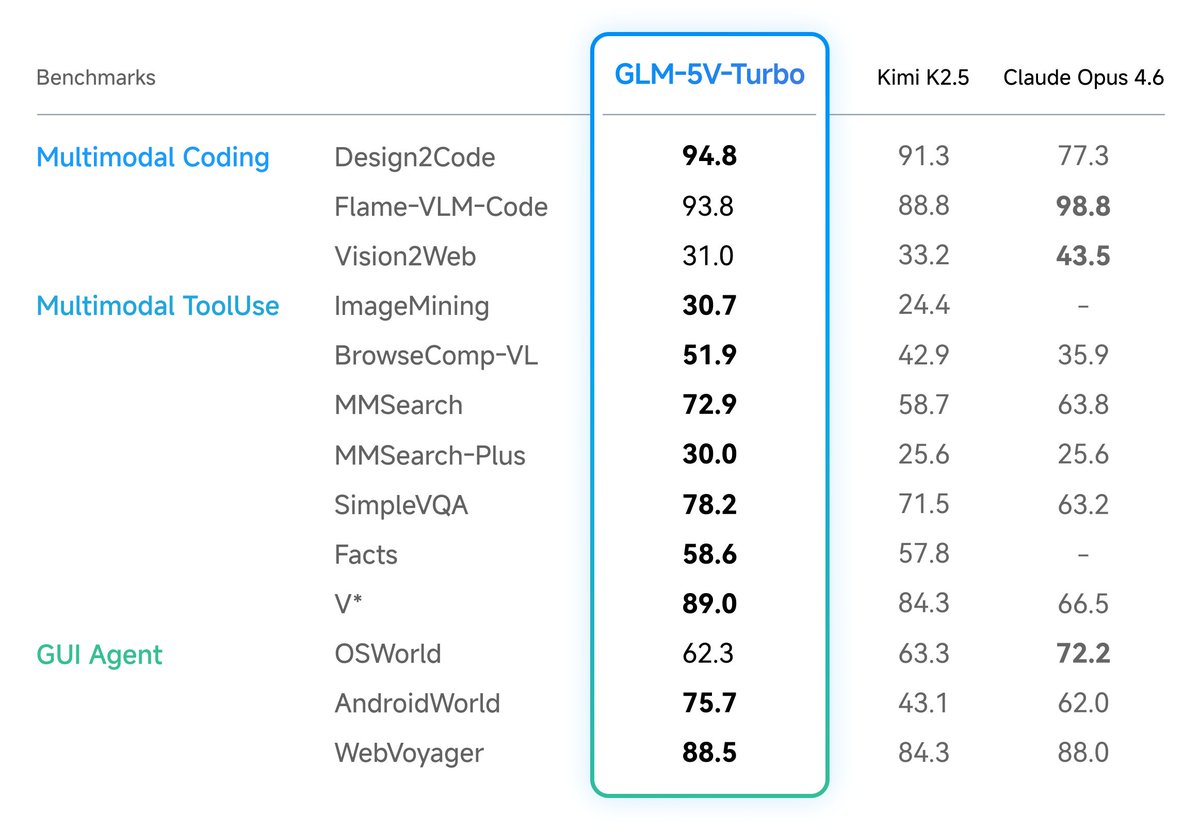
I tam gdzie ta specjalizacja ma znaczenie bije Claude Opus 4.6:👇
- Design2Code (94.8 vs 77.3)- pokazujesz mu screena dowolnej strony internetowej, a on pisze Ci gotowy, działający front-end. Różnica to aż 17 punktów!
- AndroidWorld (75.7 vs 62.0) - samodzielnie klika i nawiguje po apkach na Androidzie.
- BrowseComp-VL (51.9 vs 35.9) - rozumie co widzi w przeglądarce i potrafi z tego wyciągać informacje.
Reasumując! Tam gdzie agent AI musi „widzieć" ekran i na tej podstawie działać, tam GLM jest lepszy🔥
Natomiast Claude nie odpuszcza w OSWorld z wynikiem 72.2 vs 62.3.
I to jest benchmark na który warto zwrócić uwagę, gdyż tam model musi samodzielnie obsługiwać komputer jak normalny użytkownik (otwiera programy, zmienia ustawienia, przełącza się między oknami, wykonuje wieloetapowe zadania w realnych aplikacjach). Claude ogarnia to wyraźnie lepiej💁
Więc pytanie przy wyborze modelu do pracy z agentami nie brzmi już „który jest mądrzejszy" tylko „co dokładnie ma robić". Pisać kod z designu? GLM. Samodzielnie ogarniać komputer za Ciebie? Claude! 🍻
Jak wybieracie modele? Dobieracie pod konkretne zadanie czy macie jeden ulubiony i lecicie z nim na ślepo?🤠
5
7
56
8,526

Apr 3
Z.ai's GLM-5V-Turbo scores 94.8 on Design2Code vs Claude's 77.3. screenshot in, pixel-perfect code out. at $1.20/M tokens, that's 92% cheaper than Claude. #VisionCoding cc @Zai_org @addyosmani
3
75

これやばくないか。
中国で「画像をコードに変えてくれる開発AI」が登場してる。
できること:
・スクショからHTML/CSSを自動生成
・Figmaカンプからコンポーネント変換
・Claude Codeの中でモデルだけ差し替えて使える
・Design2Codeベンチで17ポイント以上Claudeを上回る
・月$10のLiteプラン、$30のProプランあり
優秀なプロダクトデザインを見つけたらそのままパクって即実装ができる。。。
Introducing GLM-5V-Turbo: Vision Coding Model
- Native Multimodal Coding: Natively understands multimodal inputs including images, videos, design drafts, and document layouts.
- Balanced Visual and Programming Capabilities: Achieves leading performance across core benchmarks for multimodal coding, tool use, and GUI Agents.
- Deep Adaptation for Claude Code and Claw Scenarios: Works in deep synergy with Agents like Claude Code and OpenClaw.
Try it now: chat.z.ai
API: docs.z.ai/guides/vlm/glm-5v-…
Coding Plan trial applications: docs.google.com/forms/d/e/1F…
4
61
9,469

中国AIのGLM-5V-Turbo、「UIデザイン→コード自動生成」の精度でClaude Opusを超えてきた
Design2Codeベンチマーク: 94.8 vs 77.3
智谱(Zhipu)って会社、DeepSeekの次に来ると思う
深掘りしたので共有する🧵👇
1
2
102

Here's what GLM-5V-Turbo actually wins.
-> Design2Code: 94.8 vs Claude's 77.3.
-> AndroidWorld: 75.7 vs Claude's 62.0.
-> WebVoyager: 88.5 vs Claude's 88.0.
Real wins.
Real benchmarks.
Real gap.
On visual coding tasks, GLM-5V-Turbo is genuinely ahead.
Nobody is disputing this.
1
5
650

Apr 2
🔥 智谱刚发布的 GLM-5V-Turbo,直接把多模态编程的桌子掀了。
1️⃣ 中间态 SaaS 的绞肉机
Design2Code(前端代码生成)跑到 94.8 分,把两个月前刚发的 Claude Opus 4.6(77.3分)和 Kimi K2.5(91.3分)都按在地上摩擦。
这意味着什么?
丢一张高保真设计图进去,像素级还原的可运行代码直接吐出来。那些靠“UI转译”或人工切图套利的 SaaS 创业团队,护城河一夜之间被强行填平,基础模型正在无情收编应用层的利润。
2️⃣ 原生融合的暴力美学
它扔掉了以前“视觉编码 语言模型”拼凑的传统管线。内部直接上了 CogViT 抓细节,外加 MTP(多Token预测)扛住长代码序列。人类对界面的“物理观察”和底层的“逻辑编写”,被粗暴地合并成了单一输入流。
3️⃣ 直插 Anthropic 腹地的定价战
官方文档特意点名深度适配 Claude Code 和 OpenClaw。结合 1.2元/百万Token 的白菜价(API免费期后),意图太明显了。
Anthropic 刚把 Opus 4.6 绑进企业级 IDE 圈高级开发者,智谱转手就用成本杠杆在“感知-规划-执行”的智能体闭环里抢份额。
Introducing GLM-5V-Turbo: Vision Coding Model
- Native Multimodal Coding: Natively understands multimodal inputs including images, videos, design drafts, and document layouts.
- Balanced Visual and Programming Capabilities: Achieves leading performance across core benchmarks for multimodal coding, tool use, and GUI Agents.
- Deep Adaptation for Claude Code and Claw Scenarios: Works in deep synergy with Agents like Claude Code and OpenClaw.
Try it now: chat.z.ai
API: docs.z.ai/guides/vlm/glm-5v-…
Coding Plan trial applications: docs.google.com/forms/d/e/1F…
14
4
49
28,629

Apr 1
💥 GLM-5V-Turbo just changed the game for vision-to-code AI
♠ and we tested it three ways — sketch, image, and video all turned into working code
🔹 94.8 on Design2Code — beats Kimi K2.5 and Claude Opus 4.6
🔹 Sketch to full crypto dashboard in a single prompt
🔹 Real app screenshot recreated as working HTML
🔹 Short video clip turned into a complete themed webpage
🔹 200K context, 128K output, native image and video input
🔹 Full OpenClaw integration — perception, planning, execution in one loop
1
2
44
2,856

Apr 1
Great to see GLM-5V-Turbo conquering our Design2Code benchmark. Nice work @Zai_org !!
GLM-5V-Turbo leads in benchmarks for design draft reconstruction, visual code generation, multimodal retrieval and QA, and visual exploration. It also performs exceptionally well on AndroidWorld and WebVoyager, which measure control capabilities in real GUI environments.
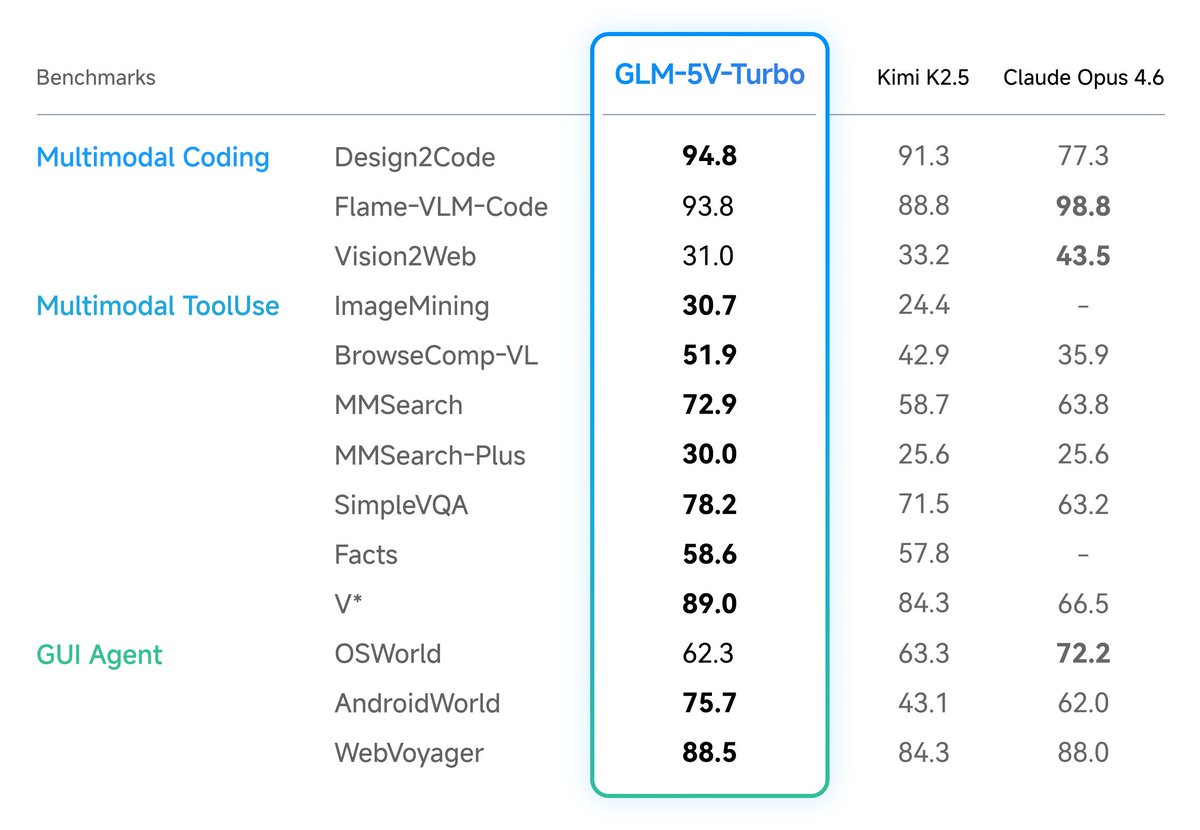
2
7
2,001

"เมื่อ AI ของจีน ใกล้เคียงกับ Opus 4.6 มากๆ แพ้เหลือแค่ GPT 5.4 xhigh และปัจจุบันไม่ได้แค่อ่านโค้ด แต่ 'มองเห็น' หน้าจอได้ด้วย ยุคของ Multimodal Coding Model จึงเริ่มต้นขึ้นจริงๆ"
Note: ผมมองว่าโลก AI ปัจจุบัน ตอนนี้เหลือแค่ OpenAI และ Anthropic ที่ยังสู้กับจีนได้ ที่เหลือแพ้หมดแล้วครับ มาดูกันว่าใครจะ AGI ก่อนกัน ระหว่าง US กับ จีน...
═══════════════════
ที่ผ่านมา โมเดล AI ที่เขียนโค้ดได้ส่วนใหญ่ทำงานกับ "ข้อความ" เป็นหลัก เราต้องอธิบายด้วยตัวอักษรว่าอยากได้หน้าเว็บแบบไหน ปุ่มอยู่ตรงไหน สีอะไร แต่ตอนนี้ Z . AI เปิดตัว GLM-5V-Turbo โมเดล Multimodal Coding รุ่นแรกของพวกเขา ที่ไม่ได้แค่อ่านข้อความ แต่ "มองเห็น" ภาพ วิดีโอ และไฟล์ได้โดยตรง แล้วเขียนโค้ดออกมาจากสิ่งที่เห็น
"เมื่อ AI ไม่ได้แค่อ่านโค้ด แต่ 'มองเห็น' หน้าจอได้ด้วย ยุคของ Multimodal Coding Model จึงเริ่มต้นขึ้นจริงๆ"
═══════════════════
🤖 GLM-5V-Turbo คืออะไร?
GLM-5V-Turbo เป็น Multimodal Coding Foundation Model ตัวแรกจาก Z.AI ที่ออกแบบมาเพื่องานเขียนโค้ดจากการมองเห็น (Vision-based Coding) โดยเฉพาะ
🔹 รับ input ได้หลายรูปแบบ ทั้งภาพ วิดีโอ ข้อความ และไฟล์
🔹 Context Length สูงถึง 200K tokens
🔹 Maximum Output Tokens ถึง 128K tokens
🔹 ถูกออกแบบมาให้ทำงานร่วมกับ Agent อย่าง Claude Code และ OpenClaw ได้อย่างลื่นไหล โดยครบวงจรตั้งแต่ "เข้าใจสภาพแวดล้อม → วางแผนการทำงาน → ลงมือทำ"
═══════════════════
🎯 ใช้ทำอะไรได้บ้าง?
1. สร้างหน้าเว็บจากภาพ Design (Frontend Recreation)
ส่งภาพ mockup หรือภาพอ้างอิงให้โมเดล มันจะเข้าใจ layout สี ลำดับชั้นของ component และ interaction logic แล้วสร้างโปรเจกต์ frontend ที่รันได้จริง สำหรับภาพ wireframe จะสร้างโครงสร้างและฟังก์ชันการทำงาน ส่วนภาพ high-fidelity จะพยายามทำให้ตรงกับ design ระดับ pixel
2. สำรวจเว็บไซต์แล้วสร้างโค้ดเอง (GUI Autonomous Exploration)
ทำงานร่วมกับ framework อย่าง Claude Code เพื่อเข้าไปสำรวจเว็บไซต์เป้าหมายด้วยตัวเอง จับภาพ รวบรวม visual asset และรายละเอียดการ interact ต่างๆ แล้วสร้างโค้ดจากผลการสำรวจโดยตรง ยกระดับจาก "สร้างจาก screenshot" เป็น "สร้างจากการสำรวจอัตโนมัติ"
3. แก้บัคจากภาพหน้าจอ (Code Debugging)
ส่ง screenshot ของหน้าเว็บที่มีปัญหา โมเดลจะระบุข้อผิดพลาดด้านการแสดงผลได้เอง เช่น layout เรียงไม่ตรง component ซ้อนทับกัน สีไม่ตรง แล้วสร้างโค้ดแก้ไขให้อัตโนมัติ
4. ทำงานร่วมกับ OpenClaw
เมื่อรวมกับ OpenClaw โมเดลจะช่วยให้ Agent เข้าใจ layout ของหน้าเว็บ องค์ประกอบ GUI และข้อมูลในกราฟ เพื่อรับมืองานที่ซับซ้อนในโลกจริงที่ต้องใช้ทั้งการรับรู้ วางแผน และลงมือทำพร้อมกัน
═══════════════════
📊 ผลการทดสอบ Benchmark
ในด้าน Multimodal Coding และ Agentic Tasks โมเดลนี้ทำคะแนนได้โดดเด่นหลายรายการเมื่อเทียบกับ Kimi K2.5 และ Claude Opus 4.6
🔹 Design2Code: GLM-5V-Turbo ทำได้ 94.8 เทียบกับ Kimi K2.5 ที่ 91.3 และ Claude Opus 4.6 ที่ 77.3
🔹 BrowseComp-VL: GLM-5V-Turbo นำที่ 51.9 ขณะที่ Kimi K2.5 ได้ 42.9 และ Claude Opus 4.6 ได้ 35.9
🔹 MMSearch: GLM-5V-Turbo ทำได้ 72.9 เทียบกับ Kimi K2.5 ที่ 58.7 และ Claude Opus 4.6 ที่ 63.8
🔹 SimpleVQA: GLM-5V-Turbo นำที่ 78.2 ส่วน Kimi K2.5 ได้ 71.5 และ Claude Opus 4.6 ได้ 63.2
🔹 ImageMining: GLM-5V-Turbo นำที่ 30.7 เทียบกับ Kimi K2.5 ที่ 24.4 (Claude Opus 4.6 ไม่มีข้อมูล)
🔹 MMSearch-Plus: GLM-5V-Turbo นำที่ 30.0 เทียบกับ Kimi K2.5 และ Claude Opus 4.6 ที่ได้เท่ากันคือ 25.6
🔹 Facts: GLM-5V-Turbo นำที่ 58.6 เทียบกับ Kimi K2.5 ที่ 57.8 (Claude Opus 4.6 ไม่มีข้อมูล)
ในด้าน GUI Agent ก็ทำได้ดีเช่นกัน
🔹 V*: ทำได้ 89.0 เทียบกับ Kimi K2.5 ที่ 84.3 และ Claude Opus 4.6 ที่ 66.5
🔹 AndroidWorld: ทำได้ 75.7 เทียบกับ Kimi K2.5 ที่ 43.1 และ Claude Opus 4.6 ที่ 62.0
🔹 WebVoyager: ทำได้ 88.5 เทียบกับ Kimi K2.5 ที่ 84.3 และ Claude Opus 4.6 ที่ 88.0
อย่างไรก็ตามในบาง benchmark อย่าง Flame-VLM-Code นั้น Claude Opus 4.6 นำด้วยคะแนน 98.8 เทียบกับ GLM-5V-Turbo ที่ 93.8
ส่วนในด้าน Pure-Text Coding ที่เป็นการเขียนโค้ดจากข้อความล้วน Claude Opus 4.6 ยังคงนำในหลายรายการ เช่น CC-Backend (26.9 vs 22.8), CC-Frontend (75.9 vs 68.4), CC-Repo-Exploration (74.4 vs 72.2) รวมถึง PinchBench, ClawEval และ ZClawBench
สิ่งที่น่าสนใจคือ แม้ GLM-5V-Turbo จะมีขนาดพารามิเตอร์ที่เล็กกว่า แต่ก็สามารถทำคะแนนนำได้ในงาน Multimodal หลายรายการ และการเพิ่มความสามารถด้านภาพเข้ามาก็ไม่ได้ทำให้ประสิทธิภาพด้านการเขียนโค้ดจากข้อความลดลง
═══════════════════
🔧 เบื้องหลังการพัฒนา: อัปเกรดทั้ง 4 ชั้น
Z.AI อธิบายว่าประสิทธิภาพของ GLM-5V-Turbo มาจากการอัปเกรดอย่างเป็นระบบใน 4 ด้าน
1. Native Multimodal Fusion
ตั้งแต่ขั้นตอน pretraining จนถึง post-training โมเดลถูกเสริมความแข็งแกร่งในการจับคู่ระหว่างภาพกับข้อความอย่างต่อเนื่อง ใช้ vision encoder ตัวใหม่ชื่อ CogViT ร่วมกับสถาปัตยกรรม MTP ที่เป็นมิตรกับการ inference เพื่อเพิ่มประสิทธิภาพการเข้าใจและการให้เหตุผลแบบ multimodal
2. Joint Reinforcement Learning กว่า 30 ประเภทงาน
ในขั้นตอน RL โมเดลถูก optimize ร่วมกันข้ามงานกว่า 30 ประเภท ครอบคลุมทั้ง STEM, grounding, วิดีโอ, GUI Agent และ Coding Agent ทำให้ได้ผลลัพธ์ที่แข็งแกร่งขึ้นในด้านการรับรู้ การให้เหตุผล และการทำงานแบบ Agent
3. การสร้างข้อมูลและงานสำหรับ Agent
เพื่อแก้ปัญหาข้อมูลสำหรับ Agent ที่มีน้อยและการตรวจสอบที่ยาก ทีมงานได้สร้างระบบข้อมูลหลายระดับที่ควบคุมได้และตรวจสอบได้ พร้อมฝัง "ความสามารถพื้นฐานแบบ Agent" เข้าไปตั้งแต่ขั้นตอน pretraining เพื่อเสริมการคาดเดาและลงมือทำ
4. ขยาย Multimodal Toolchain
เพิ่มเครื่องมือ multimodal เช่น การวาดกรอบ การจับภาพหน้าจอ และการอ่านหน้าเว็บ (รวมถึงการเข้าใจภาพ) ขยายความสามารถของ Agent จากข้อความล้วนไปสู่การ interact แบบภาพ รองรับวงจร "การรับรู้ → การวางแผน → การลงมือทำ" ที่สมบูรณ์ยิ่งขึ้น
═══════════════════
🧠 ทักษะอย่างเป็นทางการ (Official Skills)
นอกจากงานเขียนโค้ดจากภาพแล้ว GLM-5V-Turbo ยังมีชุดทักษะสำเร็จรูปสำหรับงานหลากหลาย
🔹 Image Captioning: วิเคราะห์เนื้อหาในภาพแล้วสร้างคำอธิบายเป็นภาษาธรรมชาติ เข้าใจทั้งวัตถุ ความสัมพันธ์ระหว่างวัตถุ บรรยากาศ และการกระทำ
🔹 Visual Grounding: ระบุตำแหน่งวัตถุในภาพจากคำอธิบาย โดยมาร์กตำแหน่งด้วย bounding box
🔹 Document-Grounded Writing: อ่านเอกสาร (เช่น PDF และ Word) แล้วสร้างข้อความในรูปแบบที่กำหนด เหมาะสำหรับการตีความเอกสาร สร้างรายงาน เขียนข่าว หรือร่างข้อเสนอ
🔹 Resume Screening: อ่านประวัติผู้สมัครแล้วเปรียบเทียบกับข้อกำหนดของตำแหน่งงานอัตโนมัติ ดึงข้อมูลสำคัญอย่างการศึกษา ประสบการณ์ทำงาน และทักษะ แล้วจัดลำดับหรือแนะนำผู้สมัครที่เหมาะสม
═══════════════════
💡 สรุป
GLM-5V-Turbo จาก Z . AI เป็นก้าวสำคัญของโมเดลที่เขียนโค้ดได้ เพราะมันไม่ได้แค่ "อ่าน" โค้ดหรือข้อความ แต่ยัง "เห็น" ภาพ เข้าใจหน้าจอ แล้วเขียนโค้ดออกมาได้โดยตรง ผลการทดสอบแสดงให้เห็นว่าแม้จะมีขนาดเล็กกว่า แต่ก็สู้กับโมเดลชั้นนำได้ โดยเฉพาะในงาน Multimodal Coding และ GUI Agent
การแข่งขันในวงการ AI Coding กำลังเข้าสู่ยุคที่ "ตา" สำคัญไม่แพ้ "สมอง"
สำหรับชาว Coding หรือ OpenClaw code ลดอยู่ที่นี่นะคร้าบบ z.ai/subscribe?ic=E7LHYSL0OO ราคามันถูกกว่า Claude โดยเฉลี่ย 3 เท่า แล้วยังใช้ได้มากกว่า 3 เท่า คือ รวมๆ 6 เท่าเลยอะครับ ถ้าคิดเป็น value
***แต่ระวังจะปิด Coding plan แบบ Qwen หรือเขาขึ้นราคาอีกเหมือนรอบที่แล้วนะครับ ถ้าจะสมัครรีบสมัครนะครับ***
Introducing GLM-5V-Turbo: Vision Coding Model
- Native Multimodal Coding: Natively understands multimodal inputs including images, videos, design drafts, and document layouts.
- Balanced Visual and Programming Capabilities: Achieves leading performance across core benchmarks for multimodal coding, tool use, and GUI Agents.
- Deep Adaptation for Claude Code and Claw Scenarios: Works in deep synergy with Agents like Claude Code and OpenClaw.
Try it now: chat.z.ai
API: docs.z.ai/guides/vlm/glm-5v-…
Coding Plan trial applications: docs.google.com/forms/d/e/1F…
1
2
4
793
Mar 19
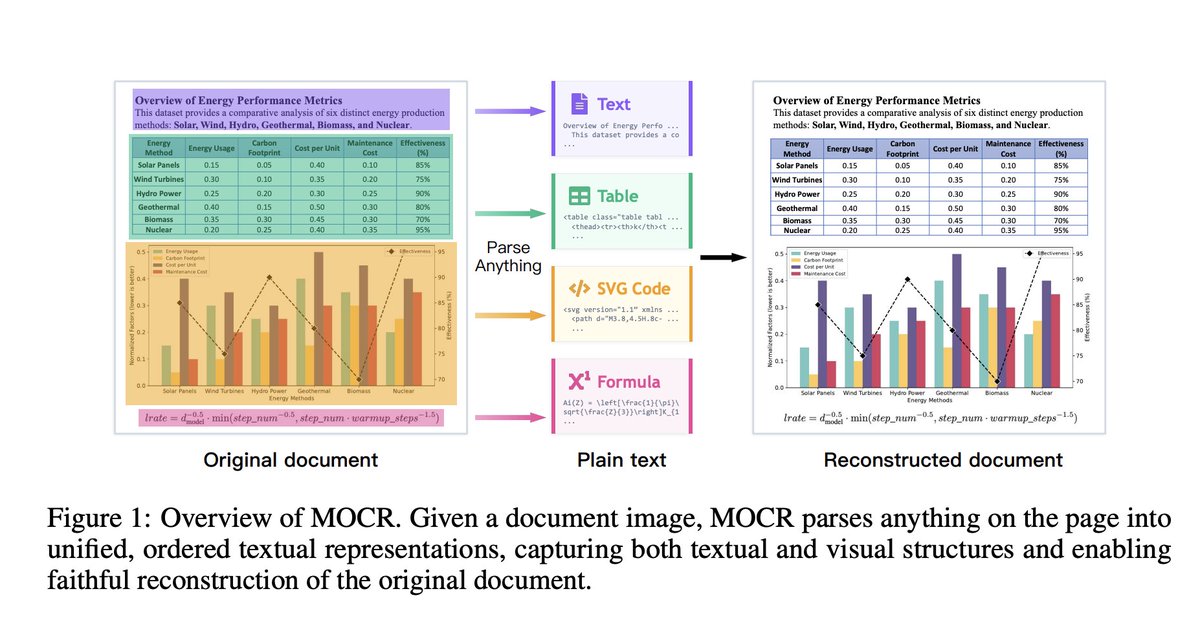
文書から「グラフ」「化学構造式」「UIデザイン」を読み取るOCRなんてない、と思っていた。
小紅書(RED)のAIチームが公開した dots.mocr はその前提を変えた。従来のOCRはチャートや図解を「ただのピクセル」として切り捨てていたけど、このモデルはSVGコードとして出力する。再描画できて編集可能な構造データになるから、後で加工できるし、次世代マルチモーダル学習の教師データとして再利用できる。
サイズは3B(1.2Bビジョンエンコーダ Qwen2.5-1.5B)。olmOCR Benchは83.9の新記録。ドキュメント解析EloはGemini 3 Proだけに負ける2位(オープンソースで1位)。そして画像→SVG変換はGemini 3 Proを超えていて、UniSVGスコアは0.902(OCRVerseは0.763)。ChartMimic・ChemDraw・Design2Codeでも上回っている。
「ドキュメントで情報密度が高いのはテキストよりビジュアルだ、でも今まで全部捨てていた」という認識の転換が論文の核心。膨大なPDFに眠るビジュアル情報を回収できるようになると、学習データの供給源がガラッと広がるかもしれない。
2
24
142
11,220


23 Dec 2025
And @Diyi_Yang worked with @ChengleiSi, @StevenyzZhang, and others on Design2Code, a new benchmark for the effectiveness of multimodal code generation for automated front-end engineering
aclanthology.org/2025.naacl-…

1
6
1,250

design2code, heard that one before @ChengleiSi @Diyi_Yang

Turn design into code with Claude Code @figma.
Through MCP, Claude sees your mockup at the data level—component hierarchies, design tokens, auto-layout rules—and translates it into production-ready code.
3
24
15,070

17 Aug 2025
Perhaps a Qwen-Coder-VL, that excels in design2code benchmark.
2
169