
リサーチや研究開発向けの生成AIエージェント @snorbe_ai を作っています。 deskrex.ai @deskrex | 著書 かんき出版『知的生産でAIを使いこなす全技法』 amazon.co.jp/dp/4761278471
Joined January 2018
- Tweets 6,657
- Following 392
- Followers 2,063
- Likes 19,621
Photos and videos
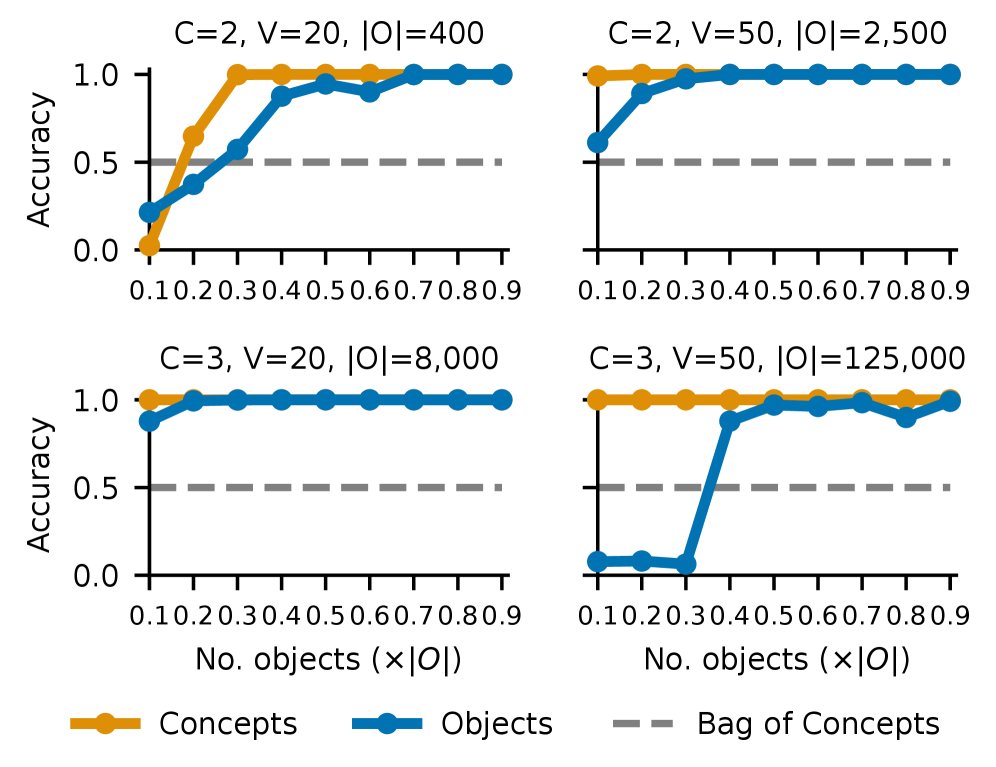
CLIPは「赤い四角と青い丸」があるシーンで「どちらが赤いか」を正しく言えないことが多い(https://arxiv[.]org/html/2605.31503v1)。「赤」も「四角」も個別には認識できるのに「どの色がどの形に属するか」の紐付けで失敗する。これが「概念結合(concept binding)」問題だ。
面白いのは、CLIPの内部には「情報がちゃんとある」という事実だ。マルチオブジェクトシーンの埋め込みベクトルは各オブジェクトの埋め込みの和で近似できる(テキスト R²≈0.92)。この加法的構造のおかげで、モダリティ内だけなら線形プローブ(埋め込みに直接学習させるシンプルな分類器)で物体情報を取り出せる。さらに「赤い四角+青い丸」の埋め込みから「赤い四角」成分を引いて別オブジェクトを足す算術編集でシーンを書き換えでき、CLIPはその結果を精度1.00で正しく検索した。
問題は「binding関数(概念から物体表現へのマッピング)の複雑度」にある。CLIPのマッピングは高複雑度で、見たことない組み合わせへの汎化に失敗する。大容量MLPで近似しても物体認識は17%どまり(概念認識の97%と対照的)。XGBoostやRandom Forestで試しても同様だった。
ではこれは根本的な限界なのか。そうじゃない。
スクラッチから訓練した制御済みTransformerでは、十分なデータがあれば汎化が自然に生まれる。汎化の鍵は「加法」でなく「乗法的相互作用(概念同士の積)」だ。積が各組み合わせに一意な表現を与え、未見の組み合わせへの汎化を可能にする。ピクセル画像入力のモデルでも同じ結果が確認された。
逆説的なスケール則もある。物体の種類が多いほど汎化に必要なデータ割合は逆に減る。コンセプトあたり20種類の値がある設定では、カバレッジ30%→40%で物体認識がほぼゼロから完璧へ急転換した。
CLIPの失敗は「構造的欠陥」ではなく「偶然高複雑度の結合関数を学習した結果」。乗法的相互作用を促す設計やデータが次の改善のカギになるかもしれない。
8
225
「AIは目で見られるのに、スキルはテキストで蓄積される」という矛盾を定量化した論文(https://arxiv[.]org/html/2606.01414v1)。
今のマルチモーダルエージェントは、経験から学んだ「スキル」をテキストの手順書として保存する。「ボタンAをクリックしてBに入力する」といった形式だ。論理推論やAPI操作には十分だが、GUIの操作(画面上の特定の要素を正確にクリックする)や密集した物体の数え上げなどの「視覚的なタスク」では根本的に情報が失われる。「そのアイコンのどの領域がクリック可能か」は文章では保存しきれない。
この論文はこの問題を「テキスト上の限界(Textual Bottleneck)」と定義した上で、Visual Skillというアプローチを提案する。テキストの手順書に3種類の「視覚的サポート(Visual Prior)」を組み合わせる設計だ。
・Static Prior(静的参照): GUIのヒットボックス(クリック有効領域)やレイアウトのプロトタイプなど、複数のタスクにわたって使い回せる視覚的ルール集
・Dynamic Prior(動的追跡): 物体カウント時に「どれを数えたか」を番号付きの座標アンカーとして画像上にリアルタイム描画し、次の推論に渡す視覚的ワーキングメモリ
・Interleaved(インターリーブ型): 手順の各ステップを、そのステップの根拠となるスクリーンショットや画像領域に紐付ける形式
実験数値が鋭い。GUIグラウンディング(画面上の要素を正確に操作できるか)のベンチマーク「ScreenSpot-v2」では、テキストのみスキルの92.3%に対してVisual Skillが95.1%に向上。クリック精度の指標Mean IoUは0.343から0.418まで改善した。
特に面白いのが密集した物体カウントの結果だ。「CountBenchQA」では、テキストのみスキルを追加すると直接指示より逆に精度が落ちる(94.24%→93.00%)。「丁寧に数えよう」という手順書だけ増えて、どこまで数えたかの空間的な記録がないと混乱を招く。Visual Skillでは座標アンカーが視覚メモとして機能し、97.12%まで到達、MAEも0.1612から0.0535に大幅改善した。
付録の失敗例も興味深く、Static Priorが「クリック可能な最小グリフ」を過度に強調してしまい、「カート内のアイテムをさらに表示」のような意味的に広い操作でかえって誤った領域をクリックするケースも報告されている。視覚的な先入観が意味解釈を上書きしてしまう問題だ。
自動生成パイプライン「AutoVisualSkill」でVisual Skillを生成できる仕組みもOSSで公開済み。知識の保存フォーマット自体を変えるというアプローチは、今後のエージェント設計に影響しそうかもしれない。

1
4
19
1,225
Itaru Tomita / 冨田到 retweeted

Agent Skillsが自動的に発動することを期待する場合、SKILLS .mdのYAMLフロントマターに記載するdescriptionをLLMに分かりやすく記述する必要があります。この記述を頼りに"いつこのスキルを使うべきか"を判断するので。

「スキルをパスに置けばエージェントが使ってくれる」は幻想かもしれない。オープンスキルエコシステムを初めて体系評価した論文がそう示した(https://arxiv[.]org/html/2605.23657v2)。
スキルとは、AIエージェントに「この手順でやれ」と渡す構造化テキストファイルのこと。Claude CodeのSKILL.mdがその代表例で、コミュニティには数千ものスキルが公開されている。
論文「OpenSkillEval」は、Claude Code・Codex・Gemini CLIなど10種のエージェントと30のスキルを、プレゼン生成・Webデザイン・ポスター・データ可視化・レポート生成の5カテゴリ677タスクで評価した。
デフォルト設定では、エージェントがスキルファイルを実際に読む割合は平均48%。Claude Opus 4.6はなんと約20%にとどまる。もっとも、これは「怠慢」ではなく「賢い選択」に見える。Opusはスキルを読む前に多くのステップでタスクを分析しており、分析系タスク(データ可視化・レポート生成)では読み込み率が50%を下回る一方、プレゼン生成では95%超という使い分けをしている。
「このスキルを使え」と明示指示すると読み込み率は94%に上がる。ただし指定手順のスキップや逆行はなくならず、スキルへの従い方は最終的にエージェントが自律的に決める。
スキル品質の格差も大きい。分析系タスクでは全体スコアの平均改善が0.04未満と限定的で、人気スキルがスキルなしを下回るケースも多い。一方で優秀なスキルは劇的に効く。101レイアウト・33チャートテンプレート・640アイコンを詰め込んだ「ppt-master」を使うと、Kimi K2.6のプレゼンスコアが3.9→4.3、Gemini 3.1が3.7→4.3へ上昇し、Claude Opusクラスに迫った。
コスト面では、スキルを使うとトークン消費が約3〜5倍に増える。paper-posterのような多段階スキルではClaude Sonnetの消費が約10倍近くに達したケースもあった。アセット(テンプレート・参照資料)が豊富なスキルほど性能向上も大きいが、コストも比例する。使うなら質の見極めが不可欠だ。

3
11
2,608
Itaru Tomita / 冨田到 retweeted

SKILLをちゃんと使わせたいなら、AGENT.md/Claude.md で明確に指示するのがベストなのかな
「スキルをパスに置けばエージェントが使ってくれる」は幻想かもしれない。オープンスキルエコシステムを初めて体系評価した論文がそう示した(https://arxiv[.]org/html/2605.23657v2)。
スキルとは、AIエージェントに「この手順でやれ」と渡す構造化テキストファイルのこと。Claude CodeのSKILL.mdがその代表例で、コミュニティには数千ものスキルが公開されている。
論文「OpenSkillEval」は、Claude Code・Codex・Gemini CLIなど10種のエージェントと30のスキルを、プレゼン生成・Webデザイン・ポスター・データ可視化・レポート生成の5カテゴリ677タスクで評価した。
デフォルト設定では、エージェントがスキルファイルを実際に読む割合は平均48%。Claude Opus 4.6はなんと約20%にとどまる。もっとも、これは「怠慢」ではなく「賢い選択」に見える。Opusはスキルを読む前に多くのステップでタスクを分析しており、分析系タスク(データ可視化・レポート生成)では読み込み率が50%を下回る一方、プレゼン生成では95%超という使い分けをしている。
「このスキルを使え」と明示指示すると読み込み率は94%に上がる。ただし指定手順のスキップや逆行はなくならず、スキルへの従い方は最終的にエージェントが自律的に決める。
スキル品質の格差も大きい。分析系タスクでは全体スコアの平均改善が0.04未満と限定的で、人気スキルがスキルなしを下回るケースも多い。一方で優秀なスキルは劇的に効く。101レイアウト・33チャートテンプレート・640アイコンを詰め込んだ「ppt-master」を使うと、Kimi K2.6のプレゼンスコアが3.9→4.3、Gemini 3.1が3.7→4.3へ上昇し、Claude Opusクラスに迫った。
コスト面では、スキルを使うとトークン消費が約3〜5倍に増える。paper-posterのような多段階スキルではClaude Sonnetの消費が約10倍近くに達したケースもあった。アセット(テンプレート・参照資料)が豊富なスキルほど性能向上も大きいが、コストも比例する。使うなら質の見極めが不可欠だ。
1
2
512
Itaru Tomita / 冨田到 retweeted

良いか悪いかは別にしてfable5は「思ってたタイミング」で読んでくれてたんだよな…
😢
「スキルをパスに置けばエージェントが使ってくれる」は幻想かもしれない。オープンスキルエコシステムを初めて体系評価した論文がそう示した(https://arxiv[.]org/html/2605.23657v2)。
スキルとは、AIエージェントに「この手順でやれ」と渡す構造化テキストファイルのこと。Claude CodeのSKILL.mdがその代表例で、コミュニティには数千ものスキルが公開されている。
論文「OpenSkillEval」は、Claude Code・Codex・Gemini CLIなど10種のエージェントと30のスキルを、プレゼン生成・Webデザイン・ポスター・データ可視化・レポート生成の5カテゴリ677タスクで評価した。
デフォルト設定では、エージェントがスキルファイルを実際に読む割合は平均48%。Claude Opus 4.6はなんと約20%にとどまる。もっとも、これは「怠慢」ではなく「賢い選択」に見える。Opusはスキルを読む前に多くのステップでタスクを分析しており、分析系タスク(データ可視化・レポート生成)では読み込み率が50%を下回る一方、プレゼン生成では95%超という使い分けをしている。
「このスキルを使え」と明示指示すると読み込み率は94%に上がる。ただし指定手順のスキップや逆行はなくならず、スキルへの従い方は最終的にエージェントが自律的に決める。
スキル品質の格差も大きい。分析系タスクでは全体スコアの平均改善が0.04未満と限定的で、人気スキルがスキルなしを下回るケースも多い。一方で優秀なスキルは劇的に効く。101レイアウト・33チャートテンプレート・640アイコンを詰め込んだ「ppt-master」を使うと、Kimi K2.6のプレゼンスコアが3.9→4.3、Gemini 3.1が3.7→4.3へ上昇し、Claude Opusクラスに迫った。
コスト面では、スキルを使うとトークン消費が約3〜5倍に増える。paper-posterのような多段階スキルではClaude Sonnetの消費が約10倍近くに達したケースもあった。アセット(テンプレート・参照資料)が豊富なスキルほど性能向上も大きいが、コストも比例する。使うなら質の見極めが不可欠だ。
1
1
157
動画説明AIが「どのフレームが重要か」を映像だけで判断できる軽量セレクターPEEK(https://arxiv[.]org/abs/2605.31029)が公開された。
VLM(視覚言語モデル)は動画を処理するとき、膨大な全フレームは受け取れず代表フレームだけを入力とする。広く使われる等間隔サンプリングはコンテンツを無視して均等に抜くため、「重要な瞬間が1秒に凝縮された動画」では外れが多い。論文の定性評価でも、バグパイプ演奏シーンのフレームを等間隔は見逃し、PEEKと正解キャプションを使うOracleは同じ瞬間を選べた。
PEEKは知識蒸留(強いモデルの判断を軽量モデルに転移する手法)の2段階構造で動く。訓練時だけSigLIP 2(画像とテキストの類似度を計算できるモデル)が各フレームと正解キャプションの一致度でランキングを作成。学習可能パラメータ170万の軽量Transformerがそのランキングを映像特徴だけで再現できるよう学習する。推論時はテキスト不要で、いわば「重要な映像シーンの勘」だけが残る仕組み。
ActivityNet Captions(動画説明文生成ベンチマーク)で16設定中14勝。「1フレームのみ」設定では4つのVLM全てで最高CIDEr(キャプション品質スコア)を記録し、別データセットMSR-VTTへのゼロショット転移(再学習なし汎化)でも1フレーム設定の全VLMで1位だった。選択処理は全17,505セグメントで1時間44分(1セグメント0.36秒)と高速で、CSTA(21時間58分)やMaxInfo(71時間4分)と比べ全体の推論時間増加は 5.2%に留まる。
MSR-VTTではSmolVLM2-2.2BのCIDErが4フレームで46.76とピークとなり、8フレームでは等間隔サンプリングで31.42まで急落した。Oracleも33.99まで同様に低下しており、VLMに「見せすぎ」ることが逆効果になりうることを数字で示している。

4
54
2,345
「スキルをパスに置けばエージェントが使ってくれる」は幻想かもしれない。オープンスキルエコシステムを初めて体系評価した論文がそう示した(https://arxiv[.]org/html/2605.23657v2)。
スキルとは、AIエージェントに「この手順でやれ」と渡す構造化テキストファイルのこと。Claude CodeのSKILL.mdがその代表例で、コミュニティには数千ものスキルが公開されている。
論文「OpenSkillEval」は、Claude Code・Codex・Gemini CLIなど10種のエージェントと30のスキルを、プレゼン生成・Webデザイン・ポスター・データ可視化・レポート生成の5カテゴリ677タスクで評価した。
デフォルト設定では、エージェントがスキルファイルを実際に読む割合は平均48%。Claude Opus 4.6はなんと約20%にとどまる。もっとも、これは「怠慢」ではなく「賢い選択」に見える。Opusはスキルを読む前に多くのステップでタスクを分析しており、分析系タスク(データ可視化・レポート生成)では読み込み率が50%を下回る一方、プレゼン生成では95%超という使い分けをしている。
「このスキルを使え」と明示指示すると読み込み率は94%に上がる。ただし指定手順のスキップや逆行はなくならず、スキルへの従い方は最終的にエージェントが自律的に決める。
スキル品質の格差も大きい。分析系タスクでは全体スコアの平均改善が0.04未満と限定的で、人気スキルがスキルなしを下回るケースも多い。一方で優秀なスキルは劇的に効く。101レイアウト・33チャートテンプレート・640アイコンを詰め込んだ「ppt-master」を使うと、Kimi K2.6のプレゼンスコアが3.9→4.3、Gemini 3.1が3.7→4.3へ上昇し、Claude Opusクラスに迫った。
コスト面では、スキルを使うとトークン消費が約3〜5倍に増える。paper-posterのような多段階スキルではClaude Sonnetの消費が約10倍近くに達したケースもあった。アセット(テンプレート・参照資料)が豊富なスキルほど性能向上も大きいが、コストも比例する。使うなら質の見極めが不可欠だ。
4
34
5,411
Itaru Tomita / 冨田到 retweeted

Jun 11
Meet Higgsfield Games.
For the first time, build and deploy multiplayer games from one prompt, in any genre, 2D or 3D, with best-in-class characters, props, and settings generated by Higgsfield MCP.
Powered by Claude Fable 5.
Try on Claude via MCP and on our Supercomputer.
253
295
2,104
868,593
AIの長期的な性能を決めるのはモデルの大きさだけじゃないという論文が出た(https://arxiv[.]org/html/2605.26112v1)。
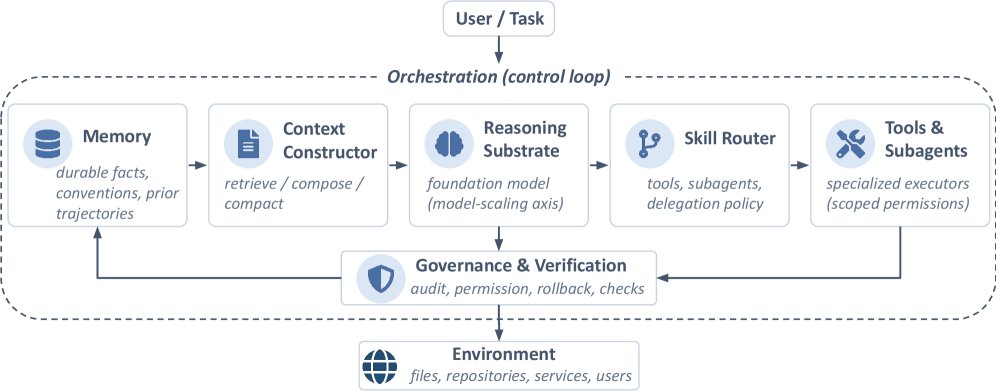
「ハーネス」という概念が核心になる。AIモデルの外側を覆う実行層のことで、コンテキスト構築(どんな情報を渡すか)・メモリ管理・ツール呼び出し・スキルルーティング(どの専門サブエージェントに任せるか)・検証・ガバナンスの6要素で構成される。モデルを大きくする「モデルスケーリング」ではなく、このハーネスを改善する「システムスケーリング」が次のボトルネックだという主張。モデル固定のままエージェントとコンピュータのインターフェースを設計し直すだけでSWE-benchのスコアが大幅に向上するという報告が、この見方を裏付けている。
Anthropicの内部実験(BrowseCompベース)が具体的で面白い。マルチエージェント構成(Claude Opus 4がリードエージェント、Claude Sonnet 4がサブエージェント)がシングルエージェント比で90.2%改善。トークン使用量だけで性能差の80%を説明でき、ツール呼び出し数とモデル選択を加えると95%まで上がる。「どのモデルか」より「どうリソースを使うか」が支配的という数字はかなり重い。
3つのボトルネックが具体的に指摘されている。
コンテキストガバナンス。コンテキストが長くなるほど注意が薄まり(attention dilution)、重要な情報が中間に埋もれやすくなる。問題は「何トークン入れられるか」ではなく「何を選ぶか」の意思決定にある。
信頼できるメモリ。「データローダーはutils/loader.pyにある」というメモが、リファクタ後も生き残って自信満々に参照され続けるのが最悪のパターン。論文ではこれを「stale-but-confident」と呼ぶ。古い情報でも検索でヒットし続けるため、エージェントが誤った前提で動き続ける。
動的スキルルーティング。スキルがあること自体より「今どのスキルをどの場面で使うか」の判断が難しい。サブエージェントが一見もっともらしい出力を返しても、下流で誰も検証しない「confident-but-unchecked」が典型的な失敗になる。
Claude Code・OpenClaw・CheetahClaws(v3.05.79、Python製のオープンソース参照実装)の3つを比較し、同じ基盤モデルでもハーネスの設計次第で性能が大きく変わることを示している。かもしれない。
17
84
5,378
Itaru Tomita / 冨田到 retweeted

中国のAIユーザーで一時話題になってたやつ、今は論文になったのね?
Jun 13
プロンプトに人を模倣させるより、その人の判断ルールをMarkdownにする方がよっぽど使える。COLLEAGUE[.]SKILLはその発想で作られた退職した同僚のノウハウ引き継ぎシステムで(https://arxiv[.]org/html/2605.31264v1)、GitHub 18.5kスター・165名が215スキルを公開中。
チャットログ・設計書・コードレビューコメントなどのトレース(その人が残した行動の痕跡)を入力すると、2種類のMarkdownファイルが自動生成される。
work.md(能力トラック)には専門知識・判断基準・レビューの優先順位が書き出される。論文に載っている具体例だと、「認証→入力バリデーション→レート制限→レスポンス構造→センシティブデータ露出、この順で高優先度の問題を先に潰してから細かい指摘に移る」という経験則がここに記述される形。
persona.md(行動トラック)にはコミュニケーションスタイル・指摘のタイミング・修正履歴が入る。
この2ファイルはClaude CodeやCodexなどのエージェントに直接インストールでき、「彼ならここで反論するはず」という自然言語フィードバックでパッチを生成しバージョン管理・ロールバックにも対応している。
ブラックボックスなプロンプトと違って中身を確認・修正・削除できるのがミソで、「その人を再現する」より「その人のノウハウを透明なファイルに蒸留する」という設計方針。同僚以外に著名人の思考モデル(公開情報ベース)や個人間の対話パターンのプリセットも実装済みで、後者は過剰な感情的依存リスクを明示した上で削除・ローカル保管を優先する設計になっている。

4
34
7,627
Itaru Tomita / 冨田到 retweeted

Kimi 2.7 ranked 2nd after Fable 5 and before GPT-5 xhigh
We have re-run our ErdosBench smoke test on 14 problems with Kimi 2.7, Qwen 3.7 Max, Grok 4.3 and compared it with the top performers from previous runs.
Kimi 2.7 is amazingly good. More below.

120
333
3,502
800,287
Itaru Tomita / 冨田到 retweeted

Jun 13
CloudflareのAgents SDKおもしろい。簡単にステートを保持、同期、休止できるのを書けるし(裏でDurable Objectsが動いてる)、Reactで使えるuseAgentあるし、なんならコマンドラインから値を更新できる
2
41
496
123,475

これが真のデジタル・ツインか?
Jun 13
プロンプトに人を模倣させるより、その人の判断ルールをMarkdownにする方がよっぽど使える。COLLEAGUE[.]SKILLはその発想で作られた退職した同僚のノウハウ引き継ぎシステムで(https://arxiv[.]org/html/2605.31264v1)、GitHub 18.5kスター・165名が215スキルを公開中。
チャットログ・設計書・コードレビューコメントなどのトレース(その人が残した行動の痕跡)を入力すると、2種類のMarkdownファイルが自動生成される。
work.md(能力トラック)には専門知識・判断基準・レビューの優先順位が書き出される。論文に載っている具体例だと、「認証→入力バリデーション→レート制限→レスポンス構造→センシティブデータ露出、この順で高優先度の問題を先に潰してから細かい指摘に移る」という経験則がここに記述される形。
persona.md(行動トラック)にはコミュニケーションスタイル・指摘のタイミング・修正履歴が入る。
この2ファイルはClaude CodeやCodexなどのエージェントに直接インストールでき、「彼ならここで反論するはず」という自然言語フィードバックでパッチを生成しバージョン管理・ロールバックにも対応している。
ブラックボックスなプロンプトと違って中身を確認・修正・削除できるのがミソで、「その人を再現する」より「その人のノウハウを透明なファイルに蒸留する」という設計方針。同僚以外に著名人の思考モデル(公開情報ベース)や個人間の対話パターンのプリセットも実装済みで、後者は過剰な感情的依存リスクを明示した上で削除・ローカル保管を優先する設計になっている。
1
1
621

Jun 13
GrepSeekが発表された(https://arxiv[.]org/html/2605.29307v1)。
RAGのベクトルインデックスを丸ごとなくして、grepコマンドでWikipedia 2100万文書を直接検索する手法「DCI(Direct Corpus Interaction)」を、9Bの小型モデルQwen3.5-9Bに学習させた研究。
まず前提を整理する。通常のRAG(検索拡張生成)はテキストをあらかじめベクトルに変換して事前インデックスを構築し、「意味的に近い」ドキュメントを返す。速いが固定チャンク単位に縛られ、「親会社と子会社の区別」「化学式の完全一致」のようなケースで混同しやすい。一方、DCIはインデックスを持たず、grep/rgコマンドで生テキストを直接検索するので任意粒度の文字列を精確に取り出せる。
先行DCIはClaude等の大型モデル依存で1クエリ最長1時間かかっていたが、GrepSeekは小型モデルに学習させることでこれを解決した。ただし直接RLをかけると「コマンドが広すぎてコンテキストが爆発する」崩壊が頻発し、1024GBのRAMでも枯渇したと報告されている。
そこで2段階学習を設計した。「正解を知るTutor」がgrep証拠チェーンを逆算構築し、「正解を知らないPlanner」がそれを正方向の推論軌跡に変換して合成データ1万件を作成。SFT後にGRPO(グループ相対ポリシー最適化)で200ステップ強化学習する。
学習が進む中の挙動変化が面白い。最初はコマンドを複数回独立発行するが、ステップが進むにつれてパイプ(|)で繋いだ複合コマンドへ進化し、発行コマンド数が平均3.06回から2.56回に減少。1回の検索でより多くの情報を取る方向に自律的に洗練されていく。
7ベンチマーク中4つで最高F1(マイクロ平均0.5691、最強比較手法Search-R1は0.5441)。HotpotQAでは0.6231対0.5591と差が顕著。アブレーション実験でSFTを除去するとマイクロ平均0.3314まで落ちることから、コールドスタートデータが精度の土台になっている。
弱点はアクセント付き固有名詞や表記ゆれ(PopQAで有意低下)。クエリ1件あたりの推論時間もベクトル検索より長い。ただし事前インデックス構築が完全不要で、ベクトル検索ではA100 GPUで数十時間かかるインデックス作成コストがかからない点は大きい。
grepで検索を学習することのポテンシャルと限界が、同時に見えてくる論文。

16
87
4,691
Jun 13
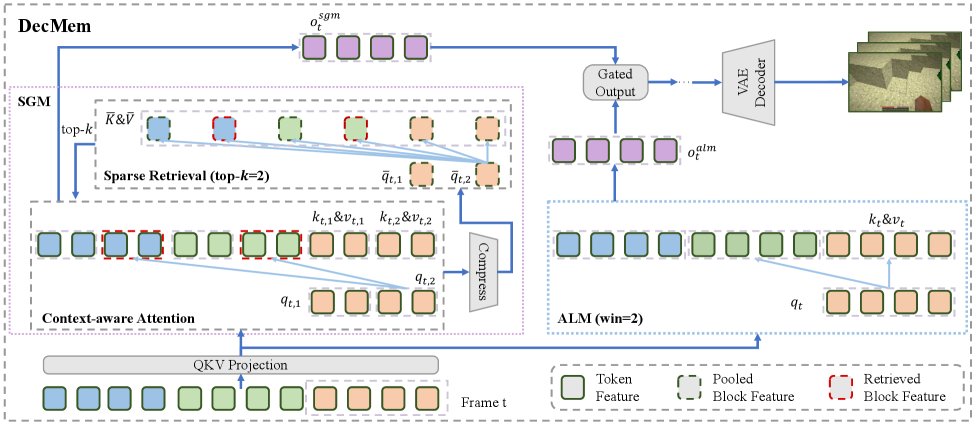
「Minecraftで1分以上探索しても、さっき通り過ぎた場所の見た目が崩れない」を実現したDecMem(https://arxiv[.]org/abs/2605.31336)。Kuaishouのkling teamによる、動画生成AIの長期記憶問題に正面から向き合った研究。
問題の根は「Attention Dispersion(注意の分散)」にある。動画生成が続くほど、関係のない過去トークンが少しずつattention weightを奪い続け、肝心な場面への注意が薄れていく。付録で定量分析すると、「重要でないトークンの割合」が推論中に単調増加し「重要なトークンの割合」が単調減少することが確認されている。遠いトークンを機械的に下げるtraining-free decayは短期品質を多少改善するが、長距離の記憶を切り捨てる副作用があり根本解決にならない。
DecMemはメモリを2系統に分離することで解決する。
Sparse Global Memory(SGM)は、過去の全フレームをブロック単位に分割・集約し、今のシーンと関連する上位80ブロックだけをスパース(まばら)に取得してから精細なattentionを行う。全履歴に均等に注意を向けるdense attentionと異なり、「探す→絞る→精読する」設計なので、生成が長くなっても計算コストがほぼ一定に保たれる。
Anchored Local Memory(ALM)は直近8フレームのスライドウィンドウに絞り、attention分布の錨として機能する。アブレーション実験では、ALMを外すと600フレーム超えで高周波ディテールが消えてシーン構造が崩壊し、FIDとLPIPS両方でdense attentionより悪化することが確認されている。
2つを学習可能なゲートで融合し、「以前訪れた場所の記憶(SGM)」と「今この瞬間の安定性(ALM)」を両立させる。
1Bパラメータのモデルを2段階で計50Kステップ・7日間学習。Oasis・MineWorld・WorldMemを複数指標で上回り、推論速度は最有力ベースラインの約2倍。産業規模モデルのMatrix-Game 2.0・WorldPlayと比べても視覚品質・操作性は同水準で、長期空間整合性は 5.14%上回る。
「遠くを見渡しながら足元を忘れない」設計が、ゲームAIの世界シミュレーションを1分スケールに押し上げた。
1
6
35
2,945
Itaru Tomita / 冨田到 retweeted

分類モデル的にどちらが近いか遠いかを推定させるより画像から深度マップ生成してマップから対象領域の深度を比較した方がこういうこと起きなさそうなイメージ
結局は学習データの多様性にもよりそうだけど
Jun 13
「遠い物体は画像上部に映る」という自然写真のクセを、AIがそのまま空間理解の手がかりとして使っている実態を暴いた論文(https://arxiv[.]org/html/2605.30161v1)。
VLM(画像とテキストを同時に扱うAIモデル)に「AとB、どちらが遠い?」と問うと、多くのモデルは物体の「縦位置」で答えていることが判明した。自然写真では遠い物体ほど画像上方に映る(透視投影の法則)。このパターンを過学習している。論文ではこれを「垂直距離もつれ(vertical-distance entanglement)」と呼ぶ。
衝撃の数字。Qwen2.5-VL(200万サンプルで追加学習)の正解率は、遠い物体が画像「上」にある通常パターンで60.9%。「下」にある逆パターンでは24.0%まで落下(差: 36.9ポイント)。モデルの種類・サイズ・追加学習量を問わず、全ケースでギャップが正値として現れる。
驚くのは「データを増やしても必ず改善しない」点。Qwenは200万サンプル追加しても距離の内部表現がほぼ変わらず反例精度が悪化するケースも。一方、2000万超のQAで訓練したRoboRefer-2Bはギャップが27.3ポイントに縮小。2350億パラメータのQwen3-VL-235Bは平均精度0.908・ギャップ0.068まで到達した。
内部の特徴ベクトルを解析すると、「奥行き軸の一貫性(距離コヒーレンス)」が高いモデルほど複数ベンチマークで安定した高性能を示すことも判明。RoboReferが0.649に対し、NVILA 2Mは0.241。ベンチマーク精度が似ていても内部表現の構造は全く異なる。
「精度が高い=空間を理解している」は安全な仮定ではない。どんな手がかりで答えているかを問うことが、空間AI評価の新たな軸になる。

1
1
314
Jun 13
プロンプトに人を模倣させるより、その人の判断ルールをMarkdownにする方がよっぽど使える。COLLEAGUE[.]SKILLはその発想で作られた退職した同僚のノウハウ引き継ぎシステムで(https://arxiv[.]org/html/2605.31264v1)、GitHub 18.5kスター・165名が215スキルを公開中。
チャットログ・設計書・コードレビューコメントなどのトレース(その人が残した行動の痕跡)を入力すると、2種類のMarkdownファイルが自動生成される。
work.md(能力トラック)には専門知識・判断基準・レビューの優先順位が書き出される。論文に載っている具体例だと、「認証→入力バリデーション→レート制限→レスポンス構造→センシティブデータ露出、この順で高優先度の問題を先に潰してから細かい指摘に移る」という経験則がここに記述される形。
persona.md(行動トラック)にはコミュニケーションスタイル・指摘のタイミング・修正履歴が入る。
この2ファイルはClaude CodeやCodexなどのエージェントに直接インストールでき、「彼ならここで反論するはず」という自然言語フィードバックでパッチを生成しバージョン管理・ロールバックにも対応している。
ブラックボックスなプロンプトと違って中身を確認・修正・削除できるのがミソで、「その人を再現する」より「その人のノウハウを透明なファイルに蒸留する」という設計方針。同僚以外に著名人の思考モデル(公開情報ベース)や個人間の対話パターンのプリセットも実装済みで、後者は過剰な感情的依存リスクを明示した上で削除・ローカル保管を優先する設計になっている。
1
13
91
11,400
Jun 13
「遠い物体は画像上部に映る」という自然写真のクセを、AIがそのまま空間理解の手がかりとして使っている実態を暴いた論文(https://arxiv[.]org/html/2605.30161v1)。
VLM(画像とテキストを同時に扱うAIモデル)に「AとB、どちらが遠い?」と問うと、多くのモデルは物体の「縦位置」で答えていることが判明した。自然写真では遠い物体ほど画像上方に映る(透視投影の法則)。このパターンを過学習している。論文ではこれを「垂直距離もつれ(vertical-distance entanglement)」と呼ぶ。
衝撃の数字。Qwen2.5-VL(200万サンプルで追加学習)の正解率は、遠い物体が画像「上」にある通常パターンで60.9%。「下」にある逆パターンでは24.0%まで落下(差: 36.9ポイント)。モデルの種類・サイズ・追加学習量を問わず、全ケースでギャップが正値として現れる。
驚くのは「データを増やしても必ず改善しない」点。Qwenは200万サンプル追加しても距離の内部表現がほぼ変わらず反例精度が悪化するケースも。一方、2000万超のQAで訓練したRoboRefer-2Bはギャップが27.3ポイントに縮小。2350億パラメータのQwen3-VL-235Bは平均精度0.908・ギャップ0.068まで到達した。
内部の特徴ベクトルを解析すると、「奥行き軸の一貫性(距離コヒーレンス)」が高いモデルほど複数ベンチマークで安定した高性能を示すことも判明。RoboReferが0.649に対し、NVILA 2Mは0.241。ベンチマーク精度が似ていても内部表現の構造は全く異なる。
「精度が高い=空間を理解している」は安全な仮定ではない。どんな手がかりで答えているかを問うことが、空間AI評価の新たな軸になる。
1
9
75
5,336
Itaru Tomita / 冨田到 retweeted

Jun 12
Beautiful paper from Google DeepMind.
Explains the pathways from AGI to ASI, and why that jump could happen through several routes.
The authors frame the AGI-to-ASI transition around 4 technical pathways:
- continued scaling of compute, model size, data, and test-time inference;
- algorithmic paradigm shifts beyond today’s transformer-based foundation-model stack;
- recursive self-improvement, where AI accelerates AI R&D and improves future systems; and
- multi-agent collective intelligence, where large populations of specialized agents coordinate into a superhuman group agent.
Scaling may work for a while, but it could hit limits in data, compute, energy, or weaker returns from making systems larger.
Recursive improvement is the most uncertain path, because AI could speed up AI research, but that loop may also slow if hard research problems need real-world testing, scarce hardware, or new ideas.
Multi-agent collectives may be the most underappreciated path, because a society of competent digital workers could outperform a brilliant individual model through specialization, speed, and coordination.
The big point is that ASI may not arrive as 1 sudden event, but as a chain of faster changes as AI helps create better AI and stronger scientific tools.
----
Link – arxiv. org/abs/2606.12683
Title: "From AGI to ASI"

33
163
813
46,245
Itaru Tomita / 冨田到 retweeted

Jun 12
A 25-year-old housewife in Chennai earns ₹250/hour ($3) just by doing her normal housework.
She wears a phone on her head and records herself making coffee, cutting fruit, folding laundry.
These first-person videos get sent to AI companies training humanoid robots to handle real-world tasks. She shoots 90 clips a day.
Her quote: "Who else will pay you ₹250/hour ($3) an hour just for doing housework?"
She's part of a growing gig economy in India where thousands are doing the same thing, filming everyday life to train the robots of tomorrow.
402
1,729
7,755
2,681,707